Your Agents Are Aging Too: Agent Lifespan Engineering for Deployed Systems
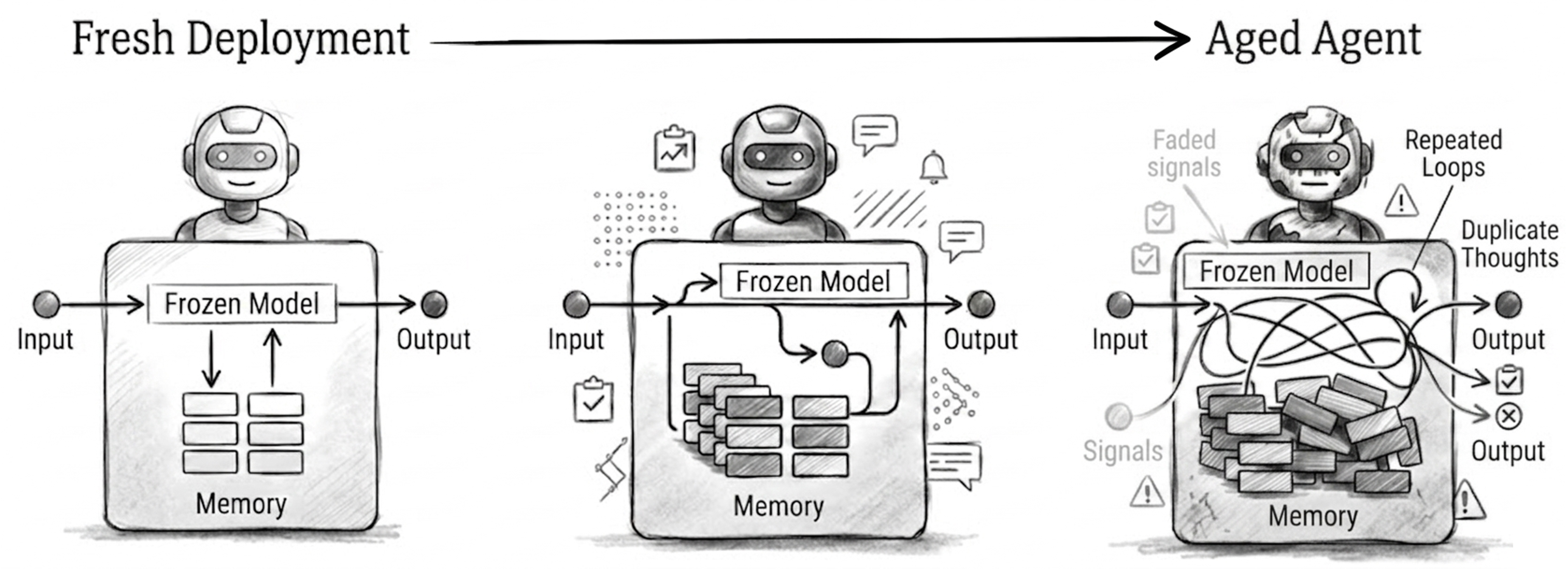
Abstract: Long-lived AI agents are increasingly deployed as persistent operational systems, yet they are still evaluated like freshly initialized models. Day-one benchmarks miss a basic systems question: how long does an agent remain reliable after deployment? Even when model weights are frozen, an agent's effective state keeps changing as it compresses interaction history, retrieves from a growing memory store, revises facts after updates, and undergoes routine maintenance. Reliability therefore becomes a lifespan property of the full agent harness, not only a snapshot property of the base model. We introduce AgingBench, a longitudinal reliability benchmark for agent lifespan engineering: measuring not only whether deployed agents degrade, but what form the degradation takes and where repair should target. AgingBench organizes agent aging into four mechanisms: compression aging, interference aging, revision aging, and maintenance aging. To diagnose these failures, AgingBench uses temporal dependency graphs and paired counterfactual probes that produce diagnostic profiles for the write, retrieval, and utilization stages of the memory pipeline. Across 7 scenarios, 14 models, multiple memory policies, and both runner-controlled and autonomous agents, over ~400 runs spanning 8 - 200 sessions show that agent aging is not one-dimensional: behavioral tests can remain clean while factual precision decays; derived-state tracking can collapse sharply within a single model; and the same wrong answer can require different repairs depending on what the diagnostic profile points to. These results suggest that reliable agent deployment requires lifespan evaluation, mechanism-level diagnosis, and stage-targeted repair, not only stronger day-one models.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper looks at a simple question that most tests for AI don’t ask: if you keep an AI helper running for weeks or months—remembering things, updating facts, and organizing its own notes—how long does it stay reliable? The authors call this problem “agent aging.” They build a new test suite, called AgingBench, to measure how AI helpers (agents) slowly lose reliability over time and to figure out exactly why that happens and how to fix it.
What questions the researchers asked
They set out to answer three kid-simple questions:
- How long can an AI helper stay trustworthy after it’s deployed?
- In what ways does it get worse with time?
- Where, inside its “memory system,” should we fix things when it goes wrong?
How they tested it (in everyday language)
Think of an AI agent like a very organized student:
- It writes notes after each class (write/summary).
- It stores those notes in folders (memory store).
- It looks up notes when answering homework (retrieve).
- It actually uses those notes to write answers (utilize).
Even if the student’s brain doesn’t change, their behavior will change based on what notes they kept, how they filed them, how well they find them later, and whether they actually use them.
The authors say agents “age” through four common problems:
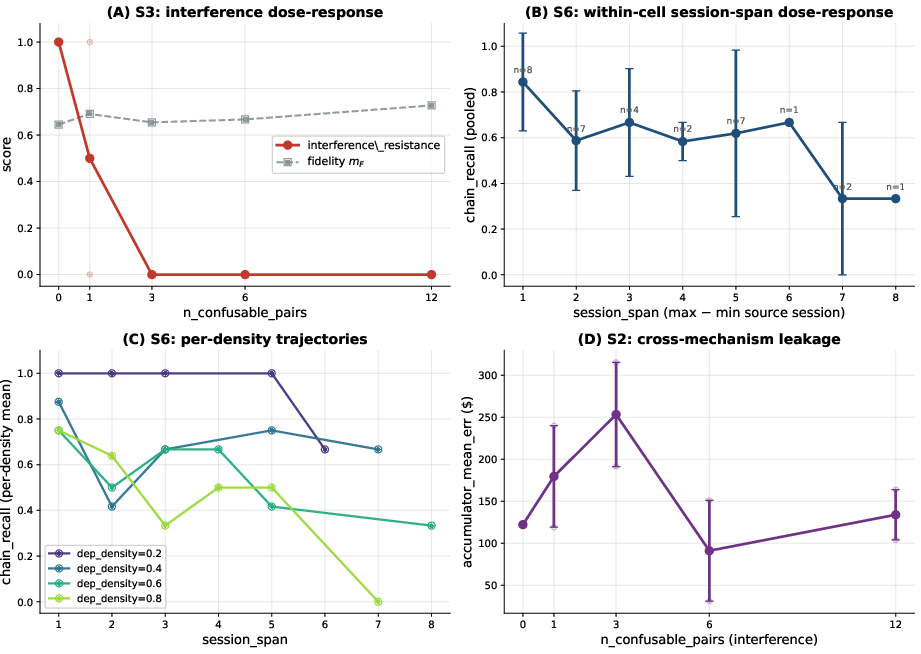
- Compression aging: When the agent summarizes past chats or files to save space, it accidentally drops details (like exact numbers, names, or dates) that matter later.
- Interference aging: When many similar notes pile up, the agent grabs the wrong one—like mixing up John Smith and John Smyth, or two budgets for different projects.
- Revision aging: When facts change (like a new password or a budget update), the agent doesn’t update or recompute its “derived” info correctly, so it keeps using stale values.
- Maintenance aging: Regular housekeeping (like reorganizing files, flushing old logs, or changing prompts) accidentally breaks things that used to work.
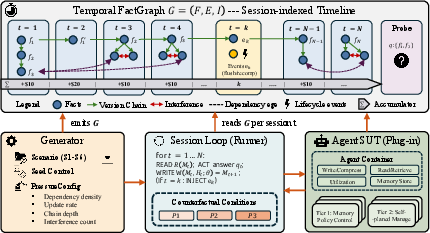
To study this carefully, the team built AgingBench, which provides:
- Long “lifespans” of tasks spread across many sessions, not just one.
- A temporal map (think of it as a timeline graph) that records how facts depend on earlier facts, when facts get updated, and where confusingly similar items show up.
- Programmed “what-if” tests that let them localize problems to a specific step in the memory pipeline.
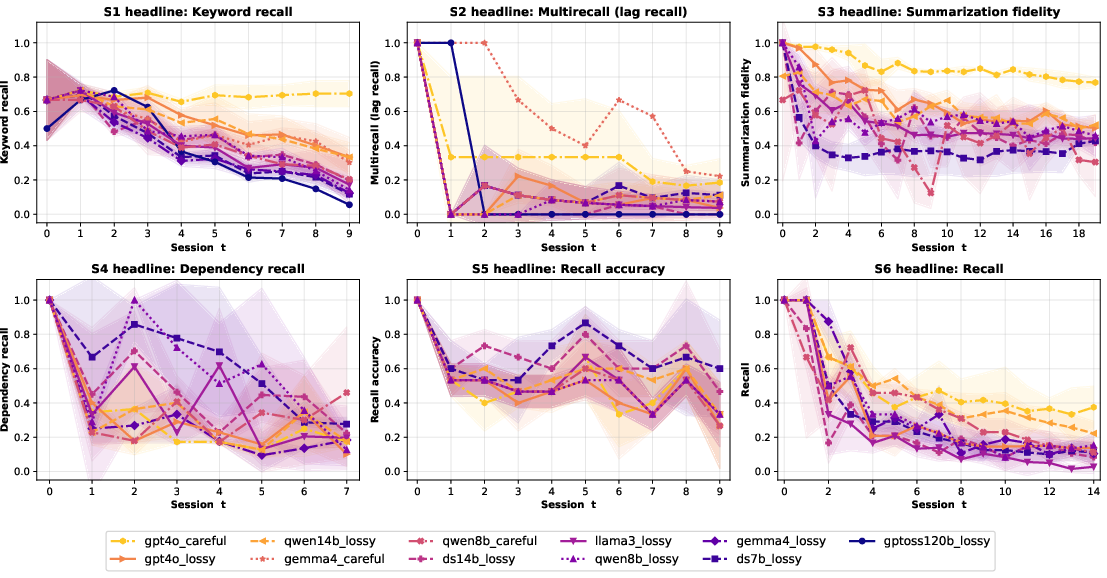
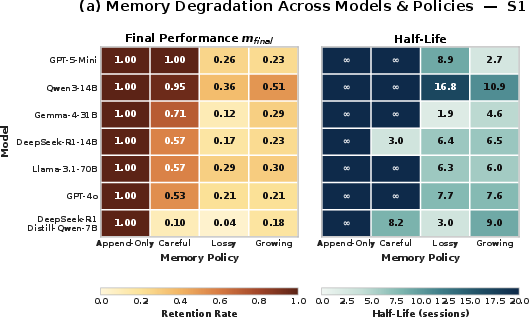
They run 7 realistic scenarios (like a research assistant, lifestyle planner, project knowledge base, coding planner, and agents that manage their own files), across 14 different models and multiple memory strategies, over 8–200 sessions. They then plot “aging curves” that show how performance drops as sessions go by, and compute simple stats like the “half-life” (how many sessions until performance falls by half).
The “what-if” (counterfactual) tests
To figure out where things break, they try three controlled test modes on the same questions:
- P1: Baseline. Let the agent do everything itself (write, retrieve, use notes).
- P2: Oracle retrieval. Keep the agent’s notes as-is, but give it perfect retrieval (the right notes are handed to it). If performance jumps here, retrieval was the problem.
- P3: Oracle context. Give the agent the exact gold facts it needs, right in the prompt. If it still fails, the issue is in how it uses information (utilization), not how it stores or fetches it.
This ladder of tests helps point the repair to the right stage: writing, retrieval, using the info, or the maintenance process.
What they found and why it matters
Here are the most important, easy-to-grasp results:
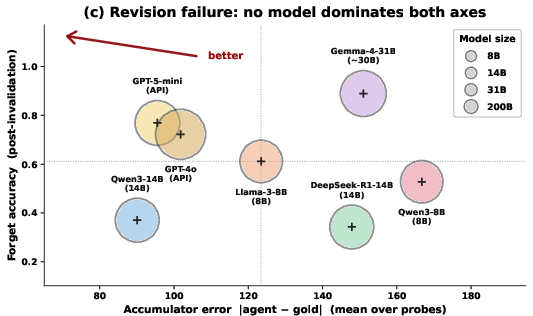
1) Aging isn’t one-dimensional
No single model stayed best as time went on. An AI might be good at keeping the right facts (write stage) but bad at pulling the right ones when many are similar (retrieval), or vice versa. Another might store and fetch fine but fail to actually use the info when answering. This means a single “memory score” hides what you really need to know to fix the agent.
Why this matters: If you only look at one overall score, you might try the wrong fix (like “give it more memory”) when the real problem is in retrieval, prompting, or maintenance.
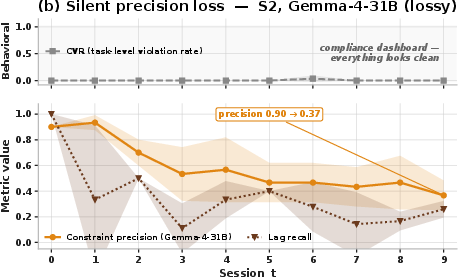
2) The agent can sound right while being factually wrong
In a lifestyle assistant scenario, the agent kept following the “style” of the conversation correctly (no obvious behavior violations), but it lost factual precision (like exact budgets or constraints) as the sessions went on. It looked confident and tidy but had drifted from the truth.
Why this matters: Monitoring “does it behave nicely?” isn’t enough. You also need tests that check factual correctness over time.
3) Failing to track changing/derived facts is about representation, not just size
When facts change repeatedly (like updating budgets), the agent often fails to keep a correct running total, even if you switch to a bigger or stronger model. That suggests the issue is how the agent represents and updates derived values—not just how big its memory or model is.
Why this matters: You may need explicit state-tracking or periodic recomputation, not just a larger model or a looser summary.
4) When agents manage their own files, the gap is often in using the info
In agent-run coding setups, files were often saved correctly and even re-opened later, but the agent still didn’t use enough of the right information before answering. The fix isn’t merely “write better files,” but “retrieve and integrate more of the needed info before responding.”
Why this matters: Adding storage isn’t enough if the agent doesn’t pull and use what it already saved.
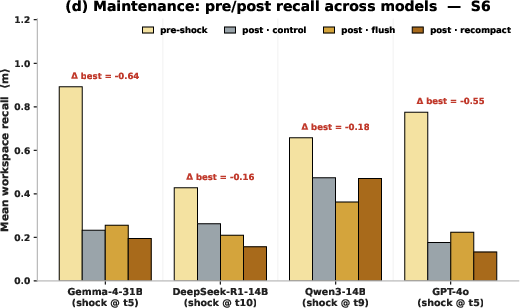
5) Routine maintenance can cause sudden regressions
Things like re-compacting memory, flushing history, changing prompts, or migrating files sometimes caused sudden drops in performance after the event, even if everything looked fine before.
Why this matters: You should test before-and-after any maintenance, just like software teams run regression tests after updates.
6) The same wrong answer can need different fixes
Two agents might both answer a question incorrectly for totally different reasons—one because it lost the fact when summarizing (write), another because it pulled the wrong memory (retrieve), and a third because it ignored the correct context (utilize). The what-if tests (P1/P2/P3) help you tell which is which.
Why this matters: It saves time and effort by targeting the fix to the actual source of the problem.
What this means going forward
This work says that to deploy reliable, long-lived AI helpers, we need:
- Lifespan evaluation: Measure performance over many sessions, not just day one.
- Mechanism-level diagnosis: Track which aging mechanism (compression, interference, revision, or maintenance) is causing problems.
- Stage-targeted repair: Fix the specific step (write, retrieve, utilize, or maintain) that’s responsible.
In short, stronger models alone won’t guarantee stable agents. We also need better “agent lifespan engineering”: building, testing, and maintaining agents so they remember the right things, update them correctly, and don’t break during routine maintenance. AgingBench provides a practical toolkit to do exactly that.
Knowledge Gaps
Below is a single, consolidated list of concrete knowledge gaps, limitations, and open questions that AgingBench leaves unresolved. Each item is phrased to be actionable for future research.
- External validity of synthetic generators: The programmatic, seed-reproducible generators are explicitly “not meant to model the full distribution of real user behavior,” leaving open how well findings transfer to production logs and heterogeneous, noisy user interactions. Collecting and evaluating on long-lived, anonymized deployment traces would test generalizability.
- Scenario/domain coverage: The seven scenarios are text-centric and narrowly scoped (e.g., research summaries, budgets, project decisions, code planning). Missing are multimodal agents (vision/audio), embodied/robotic agents, speech-based assistants, non-English/multilingual settings, and multi-user/shared-memory deployments with conflicting updates.
- Longitudinal scale limits: Runs span 8–200 sessions; real systems run for thousands of sessions across months. It is unknown whether observed half-lives, decay slopes, and hazard proxies extrapolate to longer horizons with multiple maintenance cycles and bulk memory migrations.
- Statistical rigor and uncertainty: The paper reports trends and some aggregates but provides limited treatment of variance, confidence intervals, and significance testing across seeds and models. Robust statistical analyses (e.g., bootstrap CIs, formal survival models) are needed to ensure conclusions hold under run-to-run variability and API nondeterminism.
- Diagnostic identifiability: The P1/P2/P3 counterfactual ladder provides a “repair-oriented” profile but is not a unique causal decomposition. Write/retrieval/utilization errors can interact or mask each other (e.g., prompt-length effects at P3). Formal identifiability conditions, additional probes (e.g., write-time audits, retrieval logs, forced re-reads), or interventional designs are needed to disambiguate stage attributions.
- Oracle feasibility gap: Diagnostic probes assume oracle knowledge of “gold facts” and exact fact-to-probe mappings from the temporal DAG—signals that are unavailable in production. Research is needed on deployable approximations (e.g., shadow memories, property-based tests, back-to-back retrieval audits) that preserve diagnostic value without oracles.
- Metric fidelity and scoring robustness: Several scores rely on keyword/version exactness and DAG-aligned probes. Paraphrase tolerance, partial credit, and semantic equivalence are underexplored. Human validation and semantic scoring (e.g., entailment metrics) could calibrate metric sensitivity and reduce false positives/negatives.
- Maintenance event realism: Benchmarked lifecycle shocks include history flush, recompaction, budget reduction, and migration; many real events are untested (e.g., indexing re-builds, chunking/tokenizer changes, embedding model swaps, schema evolutions, tool upgrades, model rotations, write-ahead log replay). Wider event taxonomies and injection protocols would broaden coverage.
- Attribution of maintenance vs write failures: The temporal differencing around shocks may still confound gradual drift with shock-induced regressions. Randomized event timing, A/B splits, repeated shocks, and replication across seeds are needed to isolate maintenance aging effects.
- Memory architecture breadth: Experiments primarily target compaction-based summarization with limited policy variants. Underexplored are tiered/hierarchical stores, hybrid vector+symbolic KBs, learned retrievers/rerankers, graph stores, externalized tool state, and policies that support reversible compression or provenance-preserving writes.
- Retrieval algorithm diversity: Systematic comparison of retrieval strategies (e.g., MMR, RRF, learned rerankers, query expansion, disambiguation prompts) and embedding/backbone choices is limited. How interference aging shifts under stronger retrievers remains open.
- Utilization-stage operators: The benchmark diagnoses utilization failures but does not evaluate operators that enforce or improve use of retrieved context (e.g., selective reading plans, chain-of-note, answer-with-citations, rationale-verification loops). Which operators most reduce utilization error is unknown.
- Revision/derived-state handling: Findings suggest revision aging is representational, not simply capacity-limited. There is no systematic evaluation of explicit state maintenance (typed variables, CRDTs, ledgers), periodic recomputation, or invariant checks for accumulators. Designing and validating such mechanisms remains an open avenue.
- Repair strategy efficacy: The paper motivates “stage-targeted repair” but does not implement and compare concrete interventions end-to-end (e.g., value-preserving write prompts, anti-interference retrieval, utilization forcing, lifecycle regression tests). A controlled study demonstrating improved aging curves per mechanism is missing.
- Cost/latency–reliability trade-offs: AgingBench does not quantify the compute, latency, and storage overheads of alternative memory policies, retrieval budgets, or diagnostic probes over long horizons. Practical deployment requires characterizing cost-reliability Pareto frontiers.
- Closed-model reproducibility: Several results rely on closed, frequently updated APIs (e.g., GPT/Claude). The paper does not analyze reproducibility drift across API revisions or provide pinning/recording practices to ensure longitudinal comparability.
- Autonomy framework generality: Tier-2 focuses on OpenHands and Claude Code. It is unknown whether the observed write–read–utilization gaps hold for other planners/executors (e.g., AutoGen, LangGraph, CrewAI, SWE-bench agents), or for multi-agent settings with shared memory and coordination.
- Calibration and detectability: Aging can be “silent” (behavioral compliance remains high while factual precision falls). The benchmark does not evaluate confidence calibration, self-knowledge of uncertainty, or runtime detectability signals (e.g., hypothesis tests, abstention policies) that could surface silent degradation.
- Interference structure realism: Interference pairs are programmatically injected; real confusion often arises from richer entity clusters, aliasing, multilingual homographs, and domain-specific schemas. More realistic interference generators and negative sets are needed.
- Non-stationary external world: Revision is modeled via explicit updates within the agent’s memory; concept drift in external knowledge sources (APIs, web, codebases) and distribution shifts in task types are not modeled. Integrating evolving external corpora/tools is an open extension.
- Concurrency and multi-tenant memory: The benchmark tests a single-agent, single-tenant memory store. Real deployments face concurrent sessions, locks, conflicts, rollbacks, and access control—all likely to affect aging, especially revision and maintenance.
- Security/privacy constraints: The interaction between compression policies and privacy (PII minimization, retention windows, redaction) is not addressed. How privacy-preserving memory affects aging (e.g., increased omissions) remains unknown.
- Language and cultural variance: All scenarios appear English-centric. Interference and compression behavior may differ under morphology-rich or low-resource languages. Cross-lingual and code-switching benchmarks could reveal new aging profiles.
- Extremely long memory horizons: It remains unclear how memory stores behave when they exceed embedding limits or when stores require sharding/federation. Benchmarks that stress multi-million-token memories and cross-shard retrieval could expose new failure modes.
- DAG generator expressiveness: Current DAGs encode version chains, accumulators, and simple dependencies. More complex temporal logic (e.g., conditional updates, exceptions, periodicity, soft constraints), non-tree dependencies, and contradictory evidence are not modeled.
- Alignment with user-valued outcomes: The benchmark optimizes for factual metrics but does not link aging to user satisfaction, task success rates, or business KPIs. Establishing correlations between mechanism-specific degradation and user outcomes is an open question.
- Interaction with model updates/fine-tuning: All main claims assume frozen weights. Many deployments patch/update models. How model updates interact with stored memory (e.g., embedding drift, retrieval mismatch) and aging curves is untested.
- Tooling for production deployment: While the benchmark offers a diagnostic vocabulary, it does not prescribe operational playbooks (e.g., regression suites, canaries, memory A/Bs, scheduled recomputation, shock drills) needed to manage agent lifespan in production.
- Governance and evaluation policies: No guidance is provided on when to retire memory, compact aggressively, or reset state. Formal policies for “end-of-life,” data retention, and compliance-aware memory aging remain to be designed and validated.
Practical Applications
Immediate Applications
The paper’s taxonomy (compression, interference, revision, maintenance) and its diagnostic method (oracle-based P1–P2–P3 probes over write/retrieval/utilization) enable concrete, deployable practices for building, monitoring, and repairing long-lived agents. The following applications can be implemented with current tooling (ReAct/OpenHands/Claude Code agents, vector stores, observability stacks).
- Agent Health Dashboard for Lifespan Reliability (cross-industry)
- What: Add “aging curves” to MLOps dashboards (per-session metrics, half-life t1/2, decay slopes) with mechanism-specific panels (compression, interference, revision, maintenance) and stage-targeted error shares (write/read/utilize) computed via the P1–P3 probes.
- How: Instrument agents to log write artifacts, retrieval results, and answers; run scheduled probe suites backed by a temporal dependency DAG; compute per-session metrics and post-shock deltas.
- Tools/workflows: Grafana/Prometheus panels; nightly P1–P3 probe runs; alerting on t1/2 breaches; experiment tracking for memory-policy changes.
- Assumptions/dependencies: Access to memory store artifacts and logs; ability to inject oracle contexts; benchmark generators or curated probe sets that reflect your domain.
- Mechanism-aware Regression Testing and Gating (software, enterprise IT, customer support)
- What: Pre-/post-release “lifecycle shock” tests (e.g., memory recompaction, history flush, budget changes) to gate deployments; fail the rollout if post-shock performance drops beyond thresholds on mechanism-specific metrics.
- How: Add a CI stage that replays a subset of production-like sessions and compares performance across shocks.
- Tools/workflows: “Lifecycle Shock Harness” in CI/CD; canary + rollback policies; automated comparison of Δ before/after maintenance windows.
- Assumptions/dependencies: Capacity to snapshot/restore agent state; deterministic seeds for reproducible checks.
- Stage-targeted Triage and Fixes (“same wrong answer, different repair”) (platform teams, LLMOps)
- What: Use P1–P3 diagnostics to decide whether to fix write (compaction prompt/value-preservation), retrieval (querying and scoring), or utilization (force re-reads/context-use).
- How: Embed a triage SOP: if P2 ≫ P1 → retrieval fix; if P3 ≫ P2 → write fix; if P3 is low → utilization fix (prompt/tool-use changes).
- Tools/workflows: Playbooks for compaction prompt edits (e.g., preserve numerics, IDs), retrieval budget controllers, and “forced re-read” steps at probe time.
- Assumptions/dependencies: Ability to swap retrieval with an oracle and to inject gold facts for P3.
- Memory Policy Tuning and Prompts for Value Preservation (finance, healthcare, ERP/CRM)
- What: Adjust compaction policies to preserve exact quantities and identifiers that frequently drop under compression aging.
- How: Introduce typed slots in summaries (e.g., amount, dosage, plan-tier); highlight low-frequency but high-stakes fields in prompts.
- Tools/workflows: “Value-Preservation Compaction Prompt”; unit tests verifying that critical fields survive summarization.
- Assumptions/dependencies: Clear schema for critical fields; willingness to trade some brevity for fidelity.
- Interference Guardrails and Retrieval Budget Controllers (enterprise knowledge bases, multi-tenant support)
- What: Reduce confusion among similar entities as memory grows; dynamically adjust retrieval breadth before answering.
- How: Add entity disambiguation (IDs, cross-links); run “interference probes”; increase top-k or add targeted sub-queries when ambiguity is detected.
- Tools/workflows: “Interference Scanner” that pairs confusable entities; query-expansion templates; retrieval budget controller tied to confidence.
- Assumptions/dependencies: Stable entity identifiers; access to retrieval knobs (top-k, similarity thresholds).
- Derived-State Ledgers for Running Totals (revision aging) (personal finance, procurement, inventory)
- What: Maintain a separate, append-only ledger for accumulators (budgets, balances) and recompute the current value at query time to avoid drift.
- How: Store deltas with provenance; recompute or verify at each session; reconcile with compressed summaries.
- Tools/workflows: “Derived-State Ledger” microservice; periodic recomputation job; mismatch alerts.
- Assumptions/dependencies: Ability to store event-sourced deltas; consistent time-stamping; guardrails against tampering.
- Sector-specific quick wins
- Healthcare assistants (clinical ops, patient support)
- Immediate actions: Post-maintenance medication/dosage probes; strict value-preserving compaction; utilization checks that enforce use of retrieved medication facts in answers.
- Dependencies: HIPAA-compliant storage; gold-checklists for high-risk fields.
- Finance and budgeting agents (retail banking, FP&A)
- Immediate actions: Derived-state ledger for budgets; probes for stale-plan/use of wrong account; interference checks across clients/projects.
- Dependencies: Proper access control and multi-tenant partitioning.
- Software engineering agents (DevTools, internal tooling)
- Immediate actions: Knowledge-base interference scans across similar services; re-index regression tests; write-stage quality gates for summaries/PR notes.
- Dependencies: Repository event hooks; CI integration.
- Customer support/CRM assistants (BPOs, SaaS)
- Immediate actions: Enforce client disambiguation; pre-answer re-reads for customer-specific data; maintenance-shock testing after CRM schema changes.
- Dependencies: Stable customer IDs; API access to retrieve authoritative records.
- Education/tutoring (edtech)
- Immediate actions: Probes for evolving student profiles; utilization checks to ensure retrieved profiles influence feedback.
- Dependencies: Consent and privacy controls; minimal PII in summaries.
- Daily-life personal assistants
- Immediate actions: “Memory check-up” routine (monthly probes correcting stale preferences/constraints); simple user-facing memory diff for review.
- Dependencies: Opt-in consent; simple UI for confirmation and corrections.
- Procurement and Vendor Evaluation Checklists (policy, enterprise IT)
- What: Require per-mechanism aging curves, half-life estimates, and post-shock deltas in RFPs; request P1–P3 diagnostic evidence for proposed agents.
- How: Include lifespan SLOs (e.g., minimum t1/2 for critical facts) and maintenance testing protocols in contracts.
- Assumptions/dependencies: Vendor cooperation; shared testing harness or mutually agreed probe suites.
- Academic evaluation and reproducible research
- What: Adopt the four-mechanism taxonomy, DAG-based generators, and P1–P3 attribution in studies of long-lived agents.
- How: Release seeds, generators, temporal DAGs, and logs; report mechanism-specific curves and stage contributions.
- Assumptions/dependencies: Availability of open tasks; compute budget for longitudinal runs.
Long-Term Applications
These opportunities require further research, scaling, standardization, or integration with vendor platforms, but are directly motivated by the paper’s findings and methods.
- Standards and Certification for Agent Lifespan Reliability (policy, industry consortia)
- What: Define conformance tests (aging curves, t1/2, mechanism-specific thresholds; mandatory post-maintenance testing) and publish certification marks.
- Impact: Safer deployment in high-stakes sectors; comparable, mechanism-aware procurement.
- Dependencies: Industry consensus, test suites tailored to sectors (healthcare, finance, gov).
- Typed, Versioned Memory Architectures with Temporal DAGs (platforms, DB vendors)
- What: Memory stores that natively support version chains, interference tagging, and derived-state accumulators; first-class fact graphs with provenance.
- Impact: Lower compression/interference/revision failure rates; explainability and auditable trails.
- Dependencies: Integration with vector/graph databases; schema design; storage overhead trade-offs.
- Self-healing, Mechanism-aware Agent Controllers (agent frameworks)
- What: Controllers that detect mechanism signatures online and act: trigger re-summarization (write), widen retrieval (read), or force-context-use/plan re-reads (utilize).
- Impact: Reduced runtime error without human intervention; graceful aging curves.
- Dependencies: Reliable online diagnostics; low-latency P1–P3 approximations; budgeted compute.
- Maintenance-aware SRE for Agents (Ops/DevOps)
- What: Adopt “AI SRE” practices: change calendars for agent memory, canaries, automated post-shock benchmarking, rollback protocols, and incident postmortems framed by the four mechanisms.
- Impact: Fewer surprise regressions; faster root-cause isolation.
- Dependencies: Organizational process and observability investment; cross-team coordination.
- Retrieval-Utilization Co-design and Model Training Objectives (AI research)
- What: Train or fine-tune models with losses that reward correct use of retrieved facts (to address utilization gaps highlighted by P3 residuals); benchmark during training on mechanism-specific probes.
- Impact: Reduced revision aging; better grounding in retrieved context.
- Dependencies: Access to model weights or adapters; high-quality retrieval-context supervision.
- Privacy- and Compliance-aware Lifespan Evaluation (governance, legal, healthcare/finance)
- What: Lifespan benchmarks that operate on sensitive domains with privacy-preserving logging and redaction; compliance checks for memory retention/forgetting policies alongside reliability.
- Impact: Safe adoption in regulated environments; defensible audits.
- Dependencies: Differential privacy/redaction tooling; regulator-approved test corpora.
- Cross-vendor Telemetry and Oracles for Diagnostics (ecosystem)
- What: Standardized APIs to extract write artifacts, retrieval traces, and to inject oracle contexts across proprietary agent platforms.
- Impact: Comparable, portable diagnostics; vendor-agnostic MLOps.
- Dependencies: Platform buy-in; security/privacy safeguards.
- Lifespan SLAs and Insurance Products (risk management)
- What: Contracts and insurance that price risk based on aging curves (e.g., t1/2 for critical facts), with penalties for post-shock regressions.
- Impact: Risk-aware adoption; incentives to maintain reliability over time.
- Dependencies: Mature, audited measurements; actuarial models.
- Robotics and Edge Agents with Aging-aware Memory (robotics, IoT)
- What: Deploy DAG-backed, versioned memory on-device; plan maintenance windows with post-event validation; interference controls for place/object identities.
- Impact: Robust long-term autonomy; fewer catastrophic regressions after updates.
- Dependencies: Resource-constrained implementations; synchronization across edge/cloud.
- User-facing Explainability of Memory Aging (UX, consumer products)
- What: Interfaces that summarize what the agent “remembers,” what changed after maintenance, and confidence/decay indicators; allow user confirmation/correction.
- Impact: Trust, transparency, and human-in-the-loop correction of drift.
- Dependencies: Summarization UX; safe exposure of memory contents.
- Expanded Benchmarks and Realistic Scenario Libraries (academia, industry)
- What: Public libraries of sector-specific temporal DAGs and pressure dials (dependency density, update rate, confusables) grounded in real traces.
- Impact: Better external validity and shared baselines for ALE research.
- Dependencies: Data sharing agreements; anonymization.
Notes on Assumptions and Dependencies Across Applications
- Access and instrumentation: Many applications assume access to the agent’s memory store, retrieval traces, and the ability to run oracle probes (P2/P3). Closed APIs may limit this and require vendor cooperation.
- Ground truth and DAGs: Reliable probes need gold facts and temporal structure; organizations will need either programmatic generators tailored to their workflows or curated internal testbeds.
- Cost and compute: Longitudinal evaluation (8–200 sessions in the paper) incurs compute and latency; scheduling (nightly/weekly runs) and sampling can manage cost.
- Security and privacy: Logging memory and injecting oracles must respect data protection regulations; apply redaction/differential privacy when needed.
- Generalization: Synthetic generators approximate deployment pressures; calibrate and validate probes against production telemetry to avoid overfitting to synthetic patterns.
These applications turn the paper’s core insight into practice: reliability for long-lived agents is a lifespan property of the entire harness, not just a day-one model score. Implementing mechanism-aware evaluation and stage-targeted repair yields immediate gains today and lays groundwork for standards, architectures, and controls that help agents age gracefully.
Glossary
- accumulator error: An error metric quantifying divergence in a running derived value by comparing the agent’s accumulated state to the gold accumulation over updates. Example: "the scorer computes $\mathrm{accumulator\_error}(t) = |v_{\mathrm{agent} - v_{\mathrm{gold}|$ from the full delta history, detecting compounding errors that keyword recall would miss."
- aging curve: The per-session trajectory of reliability scores over an agent’s operational lifetime. Example: "The resulting score sequence is the aging curve, from which we compute half-life (sessions until 50\% capability loss), decay slope (OLS fit), and hazard proxy (per-session failure probability)."
- AgingBench: A longitudinal benchmark designed to measure, diagnose, and analyze reliability degradation (“aging”) in long-lived agents. Example: "We introduce AgingBench, a longitudinal reliability benchmark for agent lifespan engineering: measuring not only whether deployed agents degrade, but what form the degradation takes and where repair should target."
- Agent Lifespan Engineering (ALE): The practice of measuring, diagnosing, and repairing time-dependent reliability degradation in deployed agents. Example: "We refer to this problem space as Agent Lifespan Engineering (ALE): methods for measuring, diagnosing, and repairing degradation in long-running agent systems."
- chain depth: The maximum dependency distance from a probe back to the underlying facts it relies on in the temporal graph. Example: "Dependency edges link probes to facts from multiple prior sessions with chain depth ;"
- compression aging: Degradation caused by lossy write-time summarization that omits future-relevant details. Example: "compression aging, where write-time summarization drops future-relevant details;"
- counterfactual probes: Diagnostic evaluations that replace parts of the memory pipeline with oracle components to localize failures. Example: "We build paired counterfactual probes into the evaluation harness: replacing retrieval with an oracle over the agent-written memory, and replacing both write and retrieval with gold context."
- derived state: Information computed from underlying facts (e.g., totals or balances) that must be maintained and updated over time. Example: "revision aging, where changed or derived state is not updated correctly;"
- half-life (): Sessions required for an agent’s capability (on a given metric) to drop by 50% along the aging curve. Example: "we compute half-life (sessions until 50\% capability loss)"
- hazard proxy: An estimate of the per-session failure probability used to summarize degradation risk over time. Example: "hazard proxy (per-session failure probability)"
- interference aging: Degradation where accumulated similar memories crowd out the correct fact during retrieval. Example: "interference aging, where accumulated similar memories crowd out the target fact;"
- latent-state accumulator: A derived variable maintained by applying a sequence of updates (deltas) over time. Example: "For latent-state accumulators (e.g., budget initial deltas), the scorer computes ..."
- lifecycle event: An operational change to the agent or memory (e.g., flush, recompaction, migration) that can alter behavior. Example: "lifecycle events such as flushing or recompaction trigger regressions."
- maintenance aging: Degradation triggered by routine operational events affecting the memory store or configuration. Example: "maintenance aging, where lifecycle events such as flushing or recompaction trigger regression."
- memory pipeline: The end-to-end flow that writes, stores, retrieves, and uses information to produce answers. Example: "diagnostic profiles for the write, retrieval, and utilization stages of the memory pipeline."
- memory policy: The configured strategy and parameters governing how interactions are summarized or stored. Example: "where is the memory policy's compaction function and its parameters (compaction prompt, word budget)."
- memory recompaction: A maintenance operation that re-summarizes or compresses stored memory, potentially altering behavior. Example: "maintenance aging occurs when routine operational events (memory recompaction, prompt updates, log cleanup) silently alter the agent's behavior"
- oracle context: Gold, exact information injected directly into the prompt to remove write and retrieval errors during diagnosis. Example: "P3 replaces both write and retrieval with oracle context: the gold facts required for the probe are injected directly into the prompt"
- oracle retriever: An idealized retrieval mechanism that fetches exactly the needed facts from the agent’s store. Example: "P2 replaces the agent's retrieval procedure with an oracle retriever while keeping the agent-written memory store fixed."
- programmatic generator: A controlled, seedable generator that creates long-horizon task streams and dependency structures at scale. Example: "Each scenario in Table~\ref{tab:scenarios} is backed by a programmatic generator that, given a target session count and a random seed, produces the full task stream, fact registry, and temporal dependency DAG."
- revision aging: Degradation from failing to correctly update changed, retracted, or derived state. Example: "revision aging, where changed, retracted, or derived state is not updated correctly;"
- stage-targeted repair: Interventions aimed at the specific failing stage (write, retrieval, utilization, or lifecycle) identified by diagnostics. Example: "These results suggest that reliable agent deployment requires lifespan evaluation, mechanism-level diagnosis, and stage-targeted repair, not only stronger day-one models."
- temporal dependency DAG: A directed acyclic graph encoding cross-session dependencies, updates, and interference relationships among facts and probes. Example: "AgingBench uses a temporal dependency DAG that encodes the cross-session structure of deployment"
- utilization logic: The model’s reasoning and planning process that decides when and how to retrieve and how to use retrieved context to answer. Example: "Utilization Logic () is the LLM model's core reasoning and planning loop that decides when to retrieve (i.e., planning), what to query (i.e., query generation) and how much context to request (i.e., budget)."
- version chain: A sequence tracking how a fact is superseded by later versions over time. Example: "Version chains track fact supersession within : when a fact is updated, creates a chain ..."
- write-before-query barrier: The structural challenge that memory must be compressed at write time without knowing future queries, risking loss of needed details. Example: "Compression aging arises from the write-before-query barrier: memory systems must decide what to preserve at write time, but which facts matter depends on future queries that have not yet arrived"
Collections
Sign up for free to add this paper to one or more collections.

