Continuous-Time Distribution Matching for Few-Step Diffusion Distillation
Abstract: Step distillation has become a leading technique for accelerating diffusion models, among which Distribution Matching Distillation (DMD) and Consistency Distillation are two representative paradigms. While consistency methods enforce self-consistency along the full PF-ODE trajectory to steer it toward the clean data manifold, vanilla DMD relies on sparse supervision at a few predefined discrete timesteps. This restricted discrete-time formulation and mode-seeking nature of the reverse KL divergence tends to exhibit visual artifacts and over-smoothed outputs, often necessitating complex auxiliary modules -- such as GANs or reward models -- to restore visual fidelity. In this work, we introduce Continuous-Time Distribution Matching (CDM), migrating the DMD framework from discrete anchoring to continuous optimization for the first time. CDM achieves this through two continuous-time designs. First, we replace the fixed discrete schedule with a dynamic continuous schedule of random length, so that distribution matching is enforced at arbitrary points along sampling trajectories rather than only at a few fixed anchors. Second, we propose a continuous-time alignment objective that performs active off-trajectory matching on latents extrapolated via the student's velocity field, improving generalization and preserving fine visual details. Extensive experiments on different architectures, including SD3-Medium and Longcat-Image, demonstrate that CDM provides highly competitive visual fidelity for few-step image generation without relying on complex auxiliary objectives. Code is available at https://github.com/byliutao/cdm.







Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about
This paper is about making text-to-image generators much faster without making the pictures look worse. The authors focus on diffusion models, a popular kind of image generator that normally needs dozens or even hundreds of tiny steps to turn random noise into a clean picture. That’s slow. They propose a new training method, called Continuous-Time Distribution Matching (CDM), that teaches a fast “student” model to make high-quality images in just a few steps.
The big questions the paper asks
- Can we train a fast image model that needs only a handful of steps (like 4) while keeping sharp details and good text matching?
- Do we really need to train only at a few fixed “time points” (the usual way), or is it better to train across any time point?
- How can we fix the common problem where fast models make overly smooth or blurry images?
How their method works (in everyday terms)
First, a quick picture of how diffusion models work:
- Imagine an image hidden under fog. A “teacher” model removes the fog very slowly—tiny wipe after tiny wipe—until the picture is clear. This gives great results but takes a long time.
- We want a “student” that clears the fog in just a few big wipes. That’s faster but risky: big wipes can push you off the best cleaning path and blur details.
CDM uses two simple but powerful ideas to teach the student:
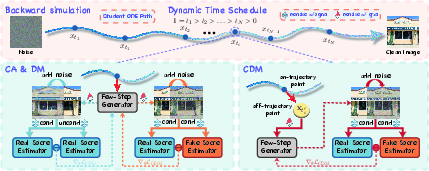
- Practice at any time, not just at fixed moments
- Old methods pick a few fixed times (like “clean at 80%, 60%, 40% fog…”) and train only there. That’s like practicing a song by only rehearsing three bars.
- CDM randomly picks any time along the fog-to-image timeline on every training step. This means the student practices everywhere, not just at a few anchors. It learns a smoother, more reliable way to clean up images.
- Train on “off-path” points to fix big-step mistakes
- Taking few big steps can make the student drift off the ideal path, causing blur or lost details.
- CDM predicts the “direction” the image should move next (think of a small arrow showing which way to clean). Then it takes a tiny step in that direction to a nearby off-path point and checks the teacher there. If the student is drifting, it gets corrected.
- This “off-trajectory” check teaches the student to self-correct during big steps and keep sharp textures.
A note on guidance:
- Some systems add an extra push called classifier-free guidance (CFG) to better match the text prompt.
- The paper shows the “distribution matching” part of training doesn’t just stabilize learning—it actively makes the student match the teacher’s unguided outputs. That’s a useful insight into what this loss is really doing.
What they found and why it matters
- Better image quality in few steps: With just 4 steps, their student model makes sharper images with richer details than competing fast methods. It avoids the common “over-smoothed” look.
- No extra trickery needed: They don’t need extra modules like GANs or reward models to fix quality—CDM alone is enough.
- Works across different backbones: They show strong results on SD3-Medium and Longcat-Image (both 1024×1024 models).
- Training at random times beats fixed schedules: Practicing at any time point leads to better scores and cleaner pictures than sticking to a few fixed anchors.
- Off-path corrections help: The “step along the arrow and check” trick reduces errors from taking big steps, preserving fine details like textures, edges, and reflections.
- Metrics back it up: On benchmarks like HPSv3, Aesthetic Score, DPGBench, and PickScore, CDM at 4 steps matches or beats strong baselines and sometimes comes close to (or surpasses) the 100-step teacher on certain metrics.
Why this is important
- Faster, cheaper generation: Making high-quality images in a few steps means less computing time, lower cost, and quicker results—useful for phones, tablets, and real-time apps.
- Simpler training: Since CDM doesn’t rely on adversarial tricks or reward models, it’s easier to train and more stable.
- A new training perspective: The paper shows we don’t need to chain training to a few fixed time points. Training across continuous time and correcting off-path errors can be a better way to build fast, high-fidelity generators.
- Future impact: These ideas could improve not just image generation but also video, 3D, and other generative tasks that need speed and high detail.
In short
CDM teaches a fast image model by practicing everywhere along the noise-to-image timeline and by actively correcting big-step mistakes. The result is quick, sharp, and detailed image generation—without extra complicated add-ons.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, focused list of what the paper leaves missing, uncertain, or unexplored, phrased to guide concrete follow-up work.
- Lack of theory for schedule independence: No formal proof or convergence guarantee that optimizing with uniformly sampled continuous timesteps (decoupled from inference anchors) yields equivalent or superior solutions compared to fixed schedules; conditions under which decoupling harms/stabilizes learning remain unknown.
- Limited error analysis: The paper cites an Euler local error term of order O() but does not quantify how the CDM loss reduces this bound in practice across NFE, timesteps, or solvers; no empirical error-vs-step-size curves.
- Extrapolation step-size design is under-specified: The distribution and bounds on are not reported; sensitivity to large strides, clipping strategies, or two-sided stepping (toward noisier vs. cleaner states) is not analyzed.
- Confirmation bias in off-trajectory targets: Off-trajectory supervision is anchored to the student’s own local prediction ; risk of self-reinforcing errors is not quantified, nor are alternatives (e.g., teacher-anchored targets, short teacher rollouts, or ensemble targets).
- Choice of t-sampling distribution: All timesteps are sampled uniformly in , but many diffusion/flow schedules are nonlinear in SNR; the impact of SNR-aware, data-adaptive, or curriculum timestep sampling on stability and quality is unexplored.
- Weighting stability of : The inverse-magnitude weighting can explode when teacher–student differences are small; no discussion of clipping, normalization, or robustness of this weighting across training phases.
- Role and design of the “fake teacher” : The paper does not detail architecture, update rule (e.g., EMA vs. separate training), or sensitivity to lag; ablations on removing or altering are missing.
- Diversity and mode coverage remain unassessed: Claims about reducing mode-seeking are not supported by coverage/diversity metrics (e.g., precision/recall, density/coverage, intra-prompt diversity); potential trade-offs between sharpness and diversity are unknown.
- Generality across solvers: CDM is evaluated with few-step Euler-like integration; effects with higher-order or stabilized ODE solvers (Heun, RK4, LMS) and whether CDM complements or obviates them are not studied.
- Scaling to 1–2 NFE: Results focus on 4 NFE; it is unclear whether CDM maintains benefits at 1–2 steps (where truncation errors are largest) or how performance degrades with fewer steps.
- Robustness near extreme timesteps: Uniform sampling includes and , but stability and gradient signal quality at very low/high noise are not evaluated.
- Interplay between CA and DM/CDM remains heuristic: While ablations show synergy, there is no analysis of gradient interference or optimal weighting schedules between CA and (C)DM, especially for prompts requiring high guidance.
- Targeting guided teacher distributions: The paper argues DM aligns to the teacher’s CFG-free distribution; it remains open whether directly matching a guided teacher distribution (e.g., via learned or scheduled guidance) can reduce reliance on CA or improve alignment.
- Generalization beyond the tested backbones: Experiments cover SD3-Medium and Longcat-Image; applicability to other architectures (e.g., SDXL, EDMs, DiTs) and modalities (video, 3D, audio) is not demonstrated.
- Conditional variants are untested: Performance with image-conditional tasks (inpainting, outpainting), controllable generation (ControlNet), or multi-conditional inputs is not explored.
- Resolution scaling: Results are at 1024×1024; behavior at higher resolutions (e.g., 2K–4K), including memory, stability, and quality, remains untested.
- Cross-architecture distillation: Distilling from one backbone to a structurally different student (e.g., UNet→DiT) is not evaluated; robustness to teacher–student architectural mismatch is unknown.
- Compute and memory overhead: CDM requires extra forward passes (off-trajectory evaluation, teacher calls); training-time cost, memory footprint, and wall-clock comparisons to baselines are deferred or absent.
- Sensitivity to seed and prompt distribution: Robustness across seeds, long/rare-language prompts, compositional complexity beyond DPG-Bench, and out-of-distribution prompts is not extensively analyzed.
- Human evaluation and reward hacking: Gains are reported on learned reward metrics (HPSv3, PickScore); human preference studies and checks for reward overfitting/hacking are missing.
- Safety and bias considerations: Effects on harmful content generation, bias amplification, and negative prompt handling are not reported; compatibility with safety mechanisms remains open.
- Dependence on teacher quality: CDM sometimes surpasses the teacher in proxy metrics; it is unclear when/why this happens, whether it generalizes, and how CDM behaves with weak or misaligned teachers.
- Interaction with adversarial/RL refinement: The paper positions CDM as avoiding GANs/reward models; whether CDM compounds or conflicts with adversarial/RL post-training (or can replace them) is untested.
- Parameter efficiency: The student capacity is fixed; trade-offs between model size, NFE, and quality (e.g., smaller students with CDM) are not explored.
- Multi-step schedule coupling: Dynamic training length is used, but the optimal relationship between training-length distribution and target inference NFE remains undetermined.
- Stochastic vs. deterministic trajectories: CDM is framed around PF-ODE/flow settings; adaptation to stochastic SDE teachers and whether off-trajectory supervision should include stochastic perturbations is not examined.
- Failure modes: Cases where off-trajectory supervision degrades quality (e.g., large extrapolations, stiff dynamics, highly non-linear flows) are not characterized; safeguards are not specified.
Practical Applications
Below are practical, real-world applications that follow from the paper’s findings and innovations—namely, continuous-time scheduling for distillation and off-trajectory alignment (CDM) that delivers high-fidelity, few-step diffusion generation without GANs or reward models.
Immediate Applications
- Low-latency text-to-image generation in creative tools
- Sector: media/advertising/software
- What: Replace multi-step T2I backends with 4-step CDM students to cut latency for prompt-to-preview workflows in design suites, slideware, and web UIs.
- Tools/products/workflows: “Few-Step T2I API” endpoints; Adobe/Blender/Figma plugins that call CDM-distilled models; batch render queues for agencies.
- Assumptions/dependencies: Access to a licensed teacher model (e.g., SD3, Longcat-Image); distillation compute; result quality inherits teacher biases; prompt safety filters remain necessary.
- API cost and energy reduction for image generation services
- Sector: cloud/AI services/energy
- What: Swap high-NFE teachers for CDM students in production to reduce GPU hours and energy per image while maintaining or improving user-perceived quality.
- Tools/products/workflows: Autoscaling inference clusters sized for 4-NFE throughput; “GreenGen” dashboards reporting energy-per-image and cost-per-creative KPIs.
- Assumptions/dependencies: Ops capacity to redeploy/monitor new models; reliable benchmarks (e.g., HPSv3, PickScore) for QoS; adherence to model licensing.
- On-device and edge generative features
- Sector: mobile/AR/IoT
- What: Enable near-real-time generation for camera filters, stickers, avatars, and AR effects on phones or wearables by reducing network evaluations.
- Tools/products/workflows: “EdgeGen SDK” with CDM-students + quantization; offline generation modes; caching and partial reuse across frames.
- Assumptions/dependencies: Memory/compute budgets on edge hardware; further compression may be required; device-side safety and watermarking.
- Real-time ideation and interactive prototyping
- Sector: product design/gaming/UX
- What: Rapid iteration for storyboarding, character exploration, and asset prototyping where sub-second updates matter.
- Tools/products/workflows: In-app prompt sliders with live updates; A/B image panels; design systems that pipe CDM outputs into version control.
- Assumptions/dependencies: Stable prompt alignment across quick updates; content policy enforcement for user-generated prompts.
- Scalable marketing and e-commerce asset generation
- Sector: retail/marketing
- What: Generate thousands of product shots, dynamic ads, and localized creatives with reduced server costs and faster turnaround.
- Tools/products/workflows: Template-driven batch pipelines; dynamic creative optimization; image variant testing at scale.
- Assumptions/dependencies: Compliance with brand guidelines; human-in-the-loop review; prompt/evaluation templates tuned per vertical.
- Data augmentation for ML training
- Sector: ML/academia
- What: Cost-effective synthetic dataset generation for training or stress-testing downstream models (e.g., classification, detection).
- Tools/products/workflows: CDM-based synthetic data generators; curriculum schedule that mixes real and synthetic; automated labelers for simple prompts.
- Assumptions/dependencies: Careful domain shift and bias auditing; labels may be noisy; governance on data provenance.
- Simpler, more stable distillation pipelines
- Sector: ML engineering/MLOps
- What: Remove adversarial discriminators or reward models, relying on CDM’s continuous-time DM and off-trajectory correction for stability and fidelity.
- Tools/products/workflows: “CDM Distiller” training library; decoupled CA/DM/CDM loss knobs; reproducible ablations for R&D.
- Assumptions/dependencies: Teacher access; sound hyperparameter choices (e.g., extrapolation step size); logging/monitoring for failure modes.
- Sustainability reporting and procurement
- Sector: policy/ESG/enterprise IT
- What: Report and optimize energy-per-image and CO2e for generative workloads by deploying few-step students.
- Tools/products/workflows: Emissions dashboards; procurement criteria emphasizing “images per kWh”; internal sustainability scorecards.
- Assumptions/dependencies: Standardized measurement methods; third-party audits; consistent workload definitions.
- Education and accessibility content
- Sector: education
- What: Generate diagrams, illustrations, and localized visuals quickly for tutors and courseware.
- Tools/products/workflows: LMS plugins with CDM-based “illustrate concept” buttons; accessibility features generating alt-visuals on demand.
- Assumptions/dependencies: Strong guardrails for factuality; teacher model content filters; review loops for sensitive topics.
Long-Term Applications
- Few-step video and audio generation
- Sector: media/entertainment
- What: Extend CDM’s continuous-time and off-trajectory principles to temporal models for real-time or near-real-time video/audio synthesis.
- Tools/products/workflows: Low-NFE video backend for trailers, ads, and social loops; interactive “scrub-to-generate” timelines.
- Assumptions/dependencies: Adapting off-trajectory supervision to temporal dimensions; availability of strong teacher video/audio models; memory optimization.
- Accelerated text-to-3D and 3D asset creation
- Sector: gaming/VFX/AR
- What: Use CDM-like distillation for 3D pipelines (building on score distillation lineage) to reduce turnaround for mesh/textured assets.
- Tools/products/workflows: “Few-step 3D generator” integrated with DCC tools; live text-to-3D previews; automated retopology and export.
- Assumptions/dependencies: Teacher 3D diffusion/flow models; robust evaluation metrics for geometry and texture fidelity.
- Fast diffusion for inverse problems in imaging
- Sector: healthcare/science/photography
- What: Apply few-step distilled students to accelerate diffusion-based MRI/CT reconstruction, microscopy denoising, super-resolution, and deblurring.
- Tools/products/workflows: PACS-integrated reconstruction modules; microscopy pipelines with CDM-accelerated denoisers.
- Assumptions/dependencies: Rigorous clinical validation and regulatory clearance; domain-specific teachers; uncertainty quantification and QA.
- Synthetic environments for robotics and autonomy
- Sector: robotics/automotive
- What: Quickly generate diverse, high-fidelity scenes for perception training and sim-to-real experiments.
- Tools/products/workflows: Procedural scenario generators coupled to CDM students; “corner-case” scene generation at scale.
- Assumptions/dependencies: Bridging domain gap; scenario coverage metrics; safety and privacy compliance for real-world deployment.
- Wearables and AR glasses with live scene editing
- Sector: consumer hardware/AR
- What: On-device, low-NFE generative augmentation (e.g., stylization, object insertion) for live views.
- Tools/products/workflows: Edge runtimes with thermal-aware schedulers; incremental updates exploiting frame-to-frame coherence.
- Assumptions/dependencies: Specialized accelerators; robust power/thermal envelopes; ultra-low-latency pipelines.
- Federated/on-device distillation for personalization
- Sector: privacy-first AI
- What: Distill personalized few-step students on-device/federated networks without sharing raw data.
- Tools/products/workflows: Federated CDM training with secure aggregation; per-user style adapters; differential privacy budgets.
- Assumptions/dependencies: Communication-efficient training; privacy-preserving telemetry; device variability.
- Multimodal, structured-conditional generation
- Sector: software/design/education
- What: Extend continuous-time distillation to models conditioned on layouts, sketches, scene graphs, or programmatic prompts.
- Tools/products/workflows: “Layout+Text→Image” few-step generators; IDE plugins for UI mockups from component trees.
- Assumptions/dependencies: Strong multimodal teacher models; datasets with structured annotations; alignment metrics beyond CLIP.
- Content supply-chain automation with feedback loops
- Sector: advertising/media ops
- What: Near-real-time creatives tailored per user segment, with closed-loop optimization using engagement signals.
- Tools/products/workflows: Streaming generators tied to experimentation frameworks; continuous prompt tuning.
- Assumptions/dependencies: Privacy law compliance; robust guardrails; scalable observability for quality and drift.
- Standards and policy for energy-per-output and provenance
- Sector: policy/standards bodies/public sector
- What: Define benchmarks, reporting norms, and procurement rules based on energy-per-image and content provenance as few-step generation proliferates.
- Tools/products/workflows: Emission labels per asset; C2PA-compatible watermarking integrated into fast pipelines.
- Assumptions/dependencies: Cross-industry coordination; measurement protocols; non-repudiable provenance systems.
- Hardware–software co-design for few-step inference
- Sector: semiconductors/systems software
- What: Kernels and compilers optimized for short, high-throughput diffusion traces; scheduling tuned for continuous-time sampling.
- Tools/products/workflows: TensorRT/TVM backends with “CDM-aware” fusion; asynchronous pipelines reducing kernel-launch overhead.
- Assumptions/dependencies: Vendor support for new fusion patterns; profiling data from production workloads.
Notes on feasibility and dependencies across applications
- CDM is a distillation method: it typically requires a strong, licensed teacher and significant one-time training compute; student quality and bias inherit from the teacher.
- The paper’s improvements hinge on continuous-time training and off-trajectory supervision; stability depends on properly tuned extrapolation and schedules.
- Safety, compliance, and IP constraints remain: faster generation increases throughput and potential misuse, heightening the need for filtering, watermarking, and auditing.
- Generalization to modalities beyond images (video, 3D, medical) will require domain-specific teachers, losses, and rigorous validation.
Glossary
- Adversarial distillation methods: Distillation approaches that train with a discriminator to align generated and real data distributions. "Alternatively, adversarial distillation methods leverage a discriminator to align the few-step student's output directly with the real data distribution."
- Adversarial losses: Training objectives derived from adversarial (GAN-style) setups to improve generator realism. "with DMD2 further improving stability via adversarial losses."
- Aesthetic Score (AES): An automatic metric estimating the visual appeal of images. "we employ Aesthetic Score (AES) on 2K prompts"
- Backward simulation: Training-time integration run in reverse along a sampling trajectory to mimic inference steps. "we employ a backward simulation strategy to construct the sampling trajectory."
- CFG Augmentation (CA): A loss term that injects classifier-free guidance signals during distillation to enhance text-image alignment. "we introduce a dynamic weighting factor ... The CA loss is then defined as:"
- CFG-free distribution: The distribution of images generated by the teacher without classifier-free guidance. "the teacher's CFG-free distribution."
- Classifier-free guidance (CFG): A technique that guides generation using differences between conditional and unconditional model predictions. "teacher models ... with and without CFG"
- CLIP Score (ViT-H-14): A text-image alignment metric computed using a CLIP ViT-H-14 model. "and CLIP Score (ViT-H-14) on 2K prompts"
- Continuous-Time Distribution Matching (CDM): The proposed framework that performs distribution matching over continuous time with on- and off-trajectory supervision. "We introduce Continuous-Time Distribution Matching (CDM)"
- Consistency Distillation: A paradigm that enforces a self-consistency mapping along ODE trajectories for few-step generation. "Consistency Distillation are two representative paradigms."
- Data manifold: The underlying set of valid data points (e.g., natural images) in high-dimensional space. "to the trajectory's origin on the data manifold"
- Distribution Matching (DM) loss: A loss that aligns the student's generated distribution with the teacher/real distribution via score or KL-based objectives. "Distribution Matching (DM) loss"
- Distribution Matching Distillation (DMD): A distillation framework that matches the student's and teacher's distributions for faster sampling. "Distribution Matching Distillation (DMD)"
- DMD2: An improved variant of DMD with stabilization techniques. "We compare our Continuous-Time Distribution Matching (CDM) against DMD2"
- DPG-Bench (DPG): A benchmark for fine-grained prompt adherence in text-to-image models. "We additionally report fine-grained prompt adherence on DPG-Bench (DPG)"
- Dynamic continuous schedule: Randomized, continuous-time timesteps used during training instead of fixed discrete anchors. "we replace the fixed discrete schedule with a dynamic continuous schedule of random length"
- Fake teacher: An online-updated model that approximates the student's distribution for real–fake matching in the DM/CDM losses. "an online-updated fake teacher"
- Few-step generation: Producing images in very few integration steps, trading step count for speed. "few-step generation inevitably introduces severe numerical truncation errors"
- First-order Euler extrapolation: A linear step using the current velocity to estimate an off-trajectory latent at another time. "perform a first-order Euler extrapolation"
- Flow-matching models: Generative models that learn vector fields (flows) mapping noise to data. "diffusion and flow-matching models"
- GANs: Generative Adversarial Networks, often used for adversarial refinement of image quality. "GANs or reward models"
- HPSv3: A human preference score metric evaluating perceived quality and alignment. "a higher HPSv3 score"
- KL divergence: A measure of difference between probability distributions used for aligning student and teacher distributions. "minimizing the KL divergence"
- Latent: A representation (often noisy) in the model’s internal space from which images are generated or denoised. "the noisy latent"
- Marginal distribution: The distribution of variables at a given noise level/time, integrating out other variables. "the marginal distribution of the real data at a continuous noise level"
- Mode-seeking: A tendency of certain objectives (e.g., reverse KL) to focus on high-density modes while ignoring diversity. "mode-seeking nature of the reverse KL divergence"
- NFE: Number of Function Evaluations; the count of model forward passes during sampling. "evaluated at 4 NFE"
- Numerical truncation errors: Errors arising from large integration steps that deviate from the ideal continuous trajectory. "few-step generation inevitably introduces severe numerical truncation errors"
- Off-trajectory latents: Latent points away from the main sampling path, used to improve robustness to integration drift. "off-trajectory latents"
- On-trajectory supervision: Applying loss at points that lie on the simulated sampling trajectory. "flexible on-trajectory supervision"
- PickScore: A learned metric predicting human preferences for generated images given prompts. "PickScore on 2K prompts"
- Probability flow ODE (PF-ODE): An ODE describing the deterministic trajectory of samples in certain diffusion/flow models. "PF-ODE trajectory"
- Re-noise: The operation of adding noise back to a clean estimate to a specified noise level for supervision. "re-noise it to a continuous time"
- Reverse KL divergence: KL computed as KL(p_student || p_teacher), often mode-seeking in practice. "reverse KL divergence"
- Schedule decoupling: Training without tying timesteps to the fixed inference schedule, allowing continuous-time sampling. "Empirical evidence of schedule decoupling."
- Score-based distribution matching: Matching distributions via their score (gradient of log-density), used for distillation. "score-based distribution matching"
- Self-consistency property: The constraint that mappings along an ODE trajectory collapse consistently to the data manifold. "enforcing a self-consistency property"
- Stop-gradient operator: An operator that prevents gradient flow through certain terms during backpropagation. "the stop-gradient operator"
- Tweedie’s formula: A relation linking denoised estimates to scores/gradients of log-densities under Gaussian noise. "by applying Tweedie's formula"
- Velocity-driven extrapolation: Creating off-trajectory points by stepping along the model’s predicted velocity. "a velocity-driven extrapolation mechanism"
- Velocity field: The vector field predicting the instantaneous direction of movement in latent space over time. "predict the velocity field"
Collections
Sign up for free to add this paper to one or more collections.