- The paper proposes a novel reward-aware trajectory shaping (RATS) framework that dynamically modulates teacher-student knowledge transfer using reward signals.
- It employs multi-horizon sigma-aligned trajectory matching with EMA teacher updates to ensure structural consistency via cosine and Frobenius norms.
- Empirical results reveal that RATS significantly improves image and video synthesis quality, enabling student models to exceed teacher performance under extreme step constraints.
Reward-Aware Trajectory Shaping for Few-step Visual Generation
Introduction
The paper "Reward-Aware Trajectory Shaping for Few-step Visual Generation" (2604.14910) addresses the core limitation in the current paradigm of few-step generative modeling: the rigid coupling of student model performance to that of high-step teachers under a distillation framework. Recent advances in few-step diffusion and flow matching generative models demonstrate high-fidelity synthesis with extremely compressed denoising trajectories, but these methods optimize for imitation of multi-step teachers, establishing an upper bound on quality and reducing flexibility in preference alignment and reward-based fine-tuning. This work identifies the teacher performance ceiling and advocates reframing few-step generation as reward-driven trajectory-level optimization, introducing a novel training framework that integrates trajectory-level knowledge transfer with dynamic, reward-aware gating.
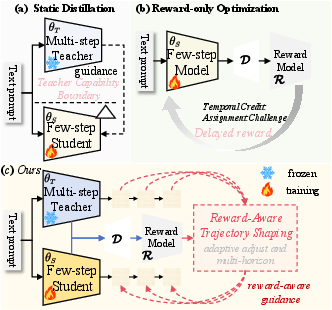
Figure 1: Comparison of the proposed Reward-Aware Trajectory Shaping (RATS) with conventional few-step generation and reward optimization paradigms, highlighting the main conceptual shift.
Methodology
Reward-Aware Trajectory Shaping (RATS)
The proposed Reward-Aware Trajectory Shaping (RATS) framework fundamentally rethinks the knowledge transfer mechanism between a strong multi-step teacher and an efficient few-step student. Rather than unconditional teacher-student matching, RATS adaptively modulates intermediate denoising trajectory supervision using a scalar reward gate dependent on the reward model comparison between the student and teacher outputs.
Key architectural elements include:
- Multi-Stage Sigma-Aligned Trajectory Matching: Teacher and student denoising trajectories are aligned at multiple horizons in sigma (noise) space, enforcing structural and magnitude consistency via cosine and Frobenius norms.
- EMA Teacher Design: The teacher model is updated via exponential moving average (EMA) after each student update, maintaining stability while gradually tracking student improvements.
- Reward-Gated Shaping Loss: The shaping loss is weighted by a sigmoid gate conditioned on the reward difference between teacher and student. The student receives strong guidance only if its decoded outputs are empirically suboptimal with respect to the reward model; otherwise, this guidance fades, freeing the student to further optimize for the reward.
- Optimization Objective: The overall loss integrates the reward term and the reward-gated shaping term, ensuring harmonization between reward maximization and knowledge transfer.
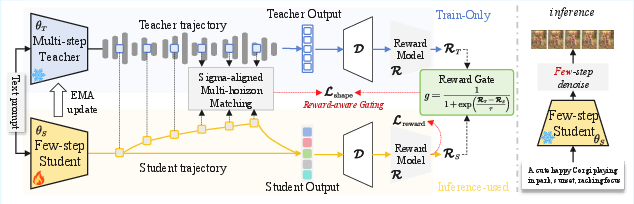
Figure 2: Overview of RATS. During training, both student and EMA teacher are rolled out from identical noise and prompt, with multi-horizon denoising predictions aligned and dynamically modulated by relative reward performance.
Empirical Results
Image Generation
Experiments on the FLUX1.0-dev model demonstrate that RATS significantly increases quality across various step budgets. The improvements are especially pronounced at extreme compression (e.g., 3-5 noise function evaluations, NFEs).
- At 3 NFEs, HPS is improved by over 13 points and ImageReward by over 1.4, relative to the baseline.
- The method consistently matches or surpasses 50-step baselines under 5 or 8 NFE inference.
- Outperforms strong few-step methods such as Hyper-SD and SenseFlow in broad quantitative metrics, not only the reward-aligned HPS but also out-of-domain metrics like PickScore and ImageReward.

Figure 3: Qualitative few-step image generation results on Flux, demonstrating the superiority of RATS outputs (right) in detail and semantic faithfulness compared to Hyper-Flux (left) and SenseFlow (center).

Figure 4: 8-NFE image generation: RATS displays improved compositional understanding and cleaner details versus Hyper-Flux and SenseFlow.

Figure 5: 5-NFE image generation: RATS continues to outperform in structural correctness and visual fidelity.

Figure 6: 3-NFE image generation: RATS maintains plausible object structures and fine details under severe step constraints.
Video Generation
Extensive evaluation on the Wan2.1-T2V-1.3B-480P video backbone validates the transferability of the framework to the spatiotemporal domain:
- At 5 and 8 NFE, RATS achieves substantially higher quality, semantic, and consistency metrics than the baseline, and at 8 NFEs, already surpasses Wan at 50 NFEs.
- Detailed VBench decomposition reveals gains in semantic categories (Multiple Objects, Object Class, Human Action), confirming improved compositionality and global consistency.
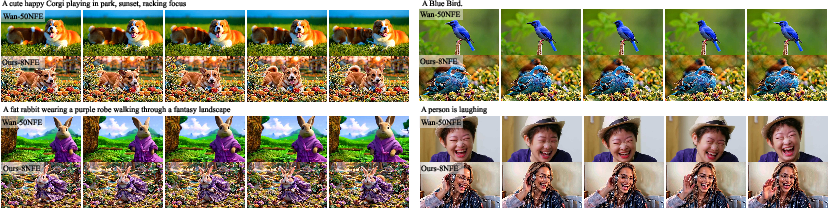
Figure 7: RATS (8-NFE) delivers more coherent motion and sharper semantic alignment in video synthesis compared to Wan-50NFE.

Figure 8: Additional 8-NFE video samples show consistent improvements in scene composition and frame-level quality.
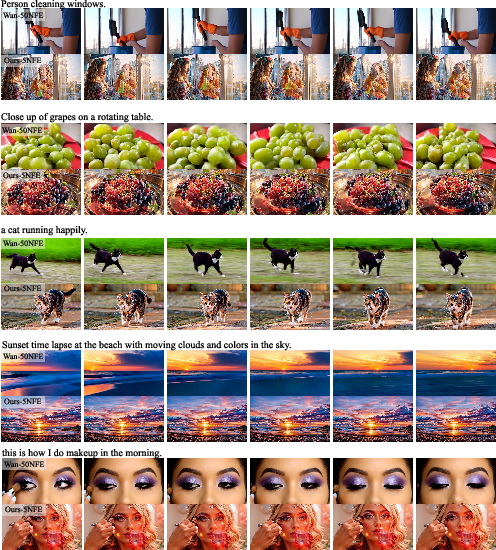
Figure 9: Similar qualitative gains are maintained at 5 NFEs, with RATS mitigating typical temporal artifacts and structural errors observed in the baseline.
Surpassing the Teacher
A central empirical finding is that the student model, when trained with RATS, consistently overtakes the teacher in terms of reward-optimized quality. The reward gap between student and teacher grows during training, especially under aggressive step constraints.

Figure 10: First-frame quality evolution during training, with the few-step student overtaking the multi-step teacher.
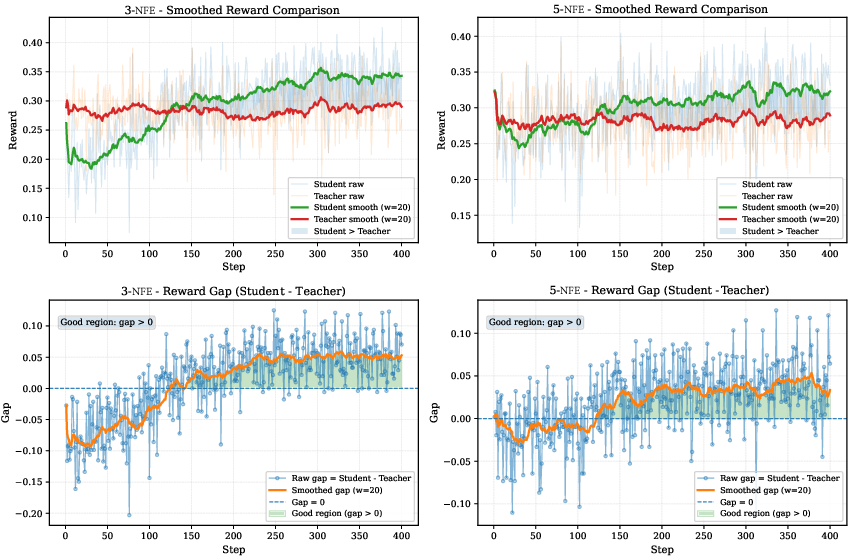
Figure 11: Smoothed reward and gap analysis demonstrates persistent student superiority at 3- and 5-step budgets.
Efficiency
- RATS achieves state-of-the-art efficiency: it converges in under one hour without external data, surpassing methods such as SenseFlow and DanceGRPO in both total wall time and the number of optimization steps required.
- Deployment cost is identical to vanilla few-step models, as the teacher is discarded after training.
Ablation and Analysis
Analysis demonstrates that neither standalone reward-based optimization nor plain distillation suffices for high few-step quality; RATS’s reward-gated shaping mechanism is essential, particularly in low-step regimes. The multi-horizon, nonuniform allocation of shaping loss outperforms single-point or uniform-weight variants. The choice of the shaping coefficient α is robust in a moderate range, but appropriate balancing is required for optimal transfer.
Theoretical and Practical Implications
This framework challenges the long-standing premise that student generators in compressed-generation must be upper-bounded by teacher performance. Through dynamic reward-aware alignment, it enables student generators to outperform their teachers on target reward metrics even with extreme step constraints. This shifts the focus of few-step generation from mere trajectory compression to preference-driven alignment, opening a pathway for efficient, deployment-grade models to fully benefit from online reward optimization techniques, and allows for stronger integration with human-in-the-loop feedback (e.g., DPO/GRPO).
Practically, RATS provides a lightweight, easily integrated training strategy compatible with any flow-matching or diffusion backbone and supports large-scale application without prohibitive computational or data requirements. The strong improvements under low-NFE settings are particularly valuable for applications constrained by hardware or latency, such as real-time media synthesis.
Future Directions
Research avenues include extending RATS to multi-objective reward schedules with dynamic preference weights, handling domain shift in reward modeling, investigating the limits of teacher parameterization (e.g., non-EMA or external teachers), and combining with reinforcement learning frameworks for interactive and sequential human preference alignment. The interplay between trajectory-level knowledge transfer and hierarchical reward signals also remains an open field for theoretical development.
Conclusion
Reward-Aware Trajectory Shaping (RATS) provides a principled solution to the long-standing performance ceiling in few-step generator distillation, combining multi-horizon knowledge transfer with dynamic, reward-driven modulation. Empirical evidence demonstrates that high-fidelity, preference-aligned synthesis can be achieved with minimal computational cost and, critically, that student models can demonstrably outperform their teachers in the constrained regime. This work redefines the landscape for efficient generative modeling and offers a strong foundation for future research in scalable, human-aligned visual generation.

