SD3.5-Flash: Distribution-Guided Distillation of Generative Flows
Abstract: We present SD3.5-Flash, an efficient few-step distillation framework that brings high-quality image generation to accessible consumer devices. Our approach distills computationally prohibitive rectified flow models through a reformulated distribution matching objective tailored specifically for few-step generation. We introduce two key innovations: "timestep sharing" to reduce gradient noise and "split-timestep fine-tuning" to improve prompt alignment. Combined with comprehensive pipeline optimizations like text encoder restructuring and specialized quantization, our system enables both rapid generation and memory-efficient deployment across different hardware configurations. This democratizes access across the full spectrum of devices, from mobile phones to desktop computers. Through extensive evaluation including large-scale user studies, we demonstrate that SD3.5-Flash consistently outperforms existing few-step methods, making advanced generative AI truly accessible for practical deployment.






Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Brief Overview
This paper introduces SD3.5-Flash, a fast image-generation system that can run on everyday devices like phones, tablets, and regular PCs. It takes a powerful but slow “teacher” model and trains a smaller “student” model to make high-quality images in just a few steps. The goal is to make advanced AI art tools quick, affordable, and easy to use without big servers.
Key Objectives
The researchers set out to:
- Create a model that can generate sharp, well-aligned images in only 2–4 steps (instead of 25+ steps).
- Keep the images faithful to the text prompts (so the picture truly matches what you asked for).
- Make the system fast and light enough to work on consumer devices with limited memory.
- Improve training stability so the small model learns well without “falling apart” or becoming unreliable.
Methods and Approach
To explain their approach, think of it like teaching a student artist to paint very quickly while still following instructions perfectly. Here’s how they did it:
Teacher–Student Training (Distillation)
- The big, slow “teacher” model makes great images but needs many steps.
- The small “student” model learns to imitate the teacher’s results in far fewer steps (like learning shortcuts without losing quality).
- This process is called distillation—teaching the student to match the teacher’s behavior.
Trajectory Guidance (Learning the Path)
- Imagine image generation like walking from noise (a messy scribble) to a finished picture.
- The student first learns the teacher’s path by practicing key checkpoints (the “trajectory”) so it can make similar progress in fewer steps.
Distribution Matching with Timestep Sharing (Stable Learning)
- Distribution matching is like making sure the student’s overall “style and variety” of images feels like the teacher’s.
- Instead of adding random noise at random times (which can confuse the student), the student reuses the exact moments (timesteps) it already visits during generation. This “timestep sharing” avoids messy feedback and keeps training stable.
Split-Timestep Fine-Tuning (Boosting Prompt Alignment)
- The model is temporarily split into two branches. One branch focuses on the early part of generation; the other focuses on the later part.
- Each branch gets really good at its part, then they are blended back together.
- This helps the final model follow prompts more accurately while keeping image quality high.
Adversarial Training (A Helpful Referee)
- A lightweight “referee” (a discriminator) checks whether images look real and match what the teacher would produce.
- The student uses this feedback to sharpen details and reduce artifacts, like a coach correcting a young artist’s mistakes.
Pipeline Optimizations and Quantization (Making It Fit on Phones)
- Text encoders (the parts that read your prompt) were reorganized to remove the biggest, slowest pieces when possible (like dropping T5-XXL if you need extra speed).
- The model’s numbers were “quantized” (stored with fewer bits, e.g., 8-bit or 6-bit) to save memory and speed up processing.
- Special tweaks were added for Apple devices (like rewriting certain operations) so it runs efficiently on the Neural Engine.
Main Findings
Here’s what the researchers discovered and why it matters:
- The 4-step model consistently makes high-quality, detailed images that match prompts well—better than many other fast methods.
- The 2-step model is even faster and still good, though the 4-step model has stronger fidelity and fewer artifacts.
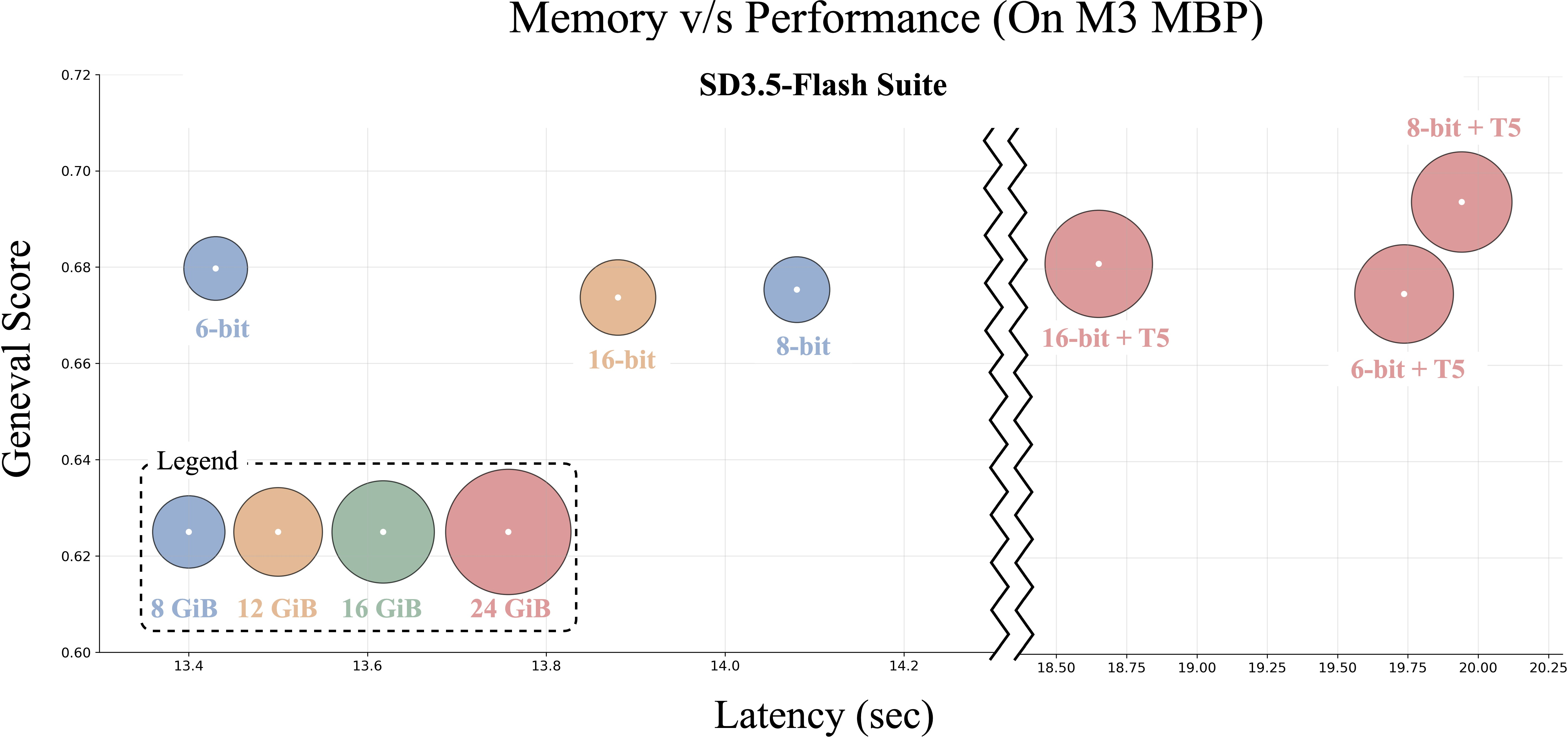
- The system runs on an iPhone or iPad in under 10 seconds for typical resolutions, and on GPUs with around 8 GB of memory—much more accessible than the 16–18 GB many models need.
- Large user studies show people prefer SD3.5-Flash’s images over other few-step methods, and sometimes even over the teacher model’s results.
- By using timestep sharing and split-timestep fine-tuning, training is more stable and prompt alignment is improved without slowing things down.
Implications and Impact
SD3.5-Flash makes advanced image generation practical outside of datacenters. This means:
- More people can use high-quality AI art tools on regular devices.
- Apps can offer fast, responsive image creation without big hardware costs.
- Schools, hobbyists, and small creators can access powerful AI art without expensive GPUs.
- The approach (stable few-step distillation + smart pipeline optimizations) could be reused to speed up other generative AI tools.
In short, the paper shows how to teach a smaller model to paint fast and well, then shrink and streamline it so it fits in your pocket—bringing top-tier AI image generation to everyone.
Knowledge Gaps
Unresolved Knowledge Gaps, Limitations, and Open Questions
Below is a concise, actionable list of what remains missing, uncertain, or unexplored in the paper.
- Theoretical grounding of timestep sharing: derive conditions under which evaluating the KL-gradient only at student timesteps preserves distributional fidelity and does not bias gradients toward the student’s limited support.
- Quantify the bias/variance trade-off in timestep sharing versus random-t renoising for flow models; measure gradient noise reduction and its effect on convergence and mode coverage.
- Formalize how DMD gradients translate to rectified flow settings (velocity fields vs. scores); clarify when “score-like” terms used here are consistent estimators for flows and how errors propagate.
- Reliability of the proxy student (v_fake): provide quantitative diagnostics of how well the proxy tracks the actual student distribution across training, and bounds on the induced error in DMD gradients.
- Curriculum choice for training on x_{t_{i-1}} vs. x_{t_i}: develop an automatic schedule based on gradient variance or validation loss to decide when to switch, and test generality across models and step counts.
- Split-timestep fine-tuning design space: systematically explore number of branches, timestep partitioning strategies, EMA decay, and interpolation ratios; provide criteria to select these hyperparameters for different step regimes.
- Generality of split-timestep fine-tuning to 2-step and 1-step models: assess whether capacity branching benefits extreme low-step distillation and quantify trade-offs.
- Diversity assessment: report precision/recall, intra-FID, MS-SSIM across seeds, and object/scene diversity metrics to verify that adversarial training and timestep sharing do not reduce diversity or cause mode collapse.
- Robustness to prompt complexity without T5: perform a stratified evaluation across long, compositional, multilingual, arithmetic, and relational prompts to map the degradation profile when substituting T5-XXL with null embeddings.
- Language coverage: evaluate non-English prompts and code-mixed inputs to quantify the impact of removing T5 on multilingual semantic fidelity.
- Guidance behavior: characterize how the distilled model responds to varying CFG scales at inference; report stability ranges and optimal CFG for few-step flows.
- Safety and bias: analyze the effect of training exclusively on synthetic teacher outputs on societal biases, toxicity, and unsafe content generation; propose mitigation/stewardship mechanisms.
- Real-data integration: study whether mixing synthetic and real datasets improves realism (FID) and reduces teacher biases, and how this interacts with adversarial objectives.
- High-resolution scaling: benchmark latency/quality at ≥2048 px and examine whether timestep sharing and quantization degrade fine-grained detail or introduce tiling/aliasing artifacts.
- Energy and thermal constraints on edge devices: measure power draw, thermal throttling, and battery impact, and identify quantization/throughput sweet spots for sustained mobile use.
- Cross-platform deployment: extend 6-bit quantization beyond Apple Silicon (e.g., Android NPUs, Qualcomm/MediaTek, NVIDIA TensorRT) and quantify quality/latency trade-offs under each stack.
- 6-bit quality impact: report automated and human metrics for the 6-bit model (not just latency) to establish the fidelity loss relative to 8/16-bit variants.
- Encoder restructuring details: document how encoder dropout pretraining enables T5 removal, including dropout schedules, null embedding construction, and robustness limits; provide ablations.
- Compositional and relational grounding: go beyond GenEval’s object-centric checks to evaluate relational accuracy (e.g., spatial relations, counts, negation) with benchmarks like TIFA or custom relational suites.
- Text rendering and fine-grained attributes: test legibility, numerical accuracy, small objects, and fine textures to detect failure modes specific to few-step distillation.
- Discriminator design choices: compare training in flow-latent versus image space, assess alternative feature extractors (teacher vs. proxy vs. CLIP/DINO), and study stability regularizers (e.g., spectral norm, gradient penalties).
- Discriminator refresh strategy: move beyond periodic re-initialization; explore adaptive refresh criteria (e.g., overfitting monitors, feature drift) and their impact on stability and quality.
- Generalization across teachers: validate the method when distilling other rectified-flow or score-based teachers (e.g., SANA, EMU/Flux), and identify teacher properties that affect success.
- One-step generation: investigate whether the proposed distribution-guided distillation (with timestep sharing and split-timestep fine-tuning) can achieve competitive single-step quality; identify failure points.
- Editing and conditioning tasks: evaluate image editing, inpainting, and extra conditionings (ControlNet, LoRAs) to test whether few-step flows preserve controllability under the distilled pipeline.
- Robustness to out-of-distribution prompts: stress-test rare scenes, abstract concepts, and adversarial prompts; quantify failure rates and define guardrails.
- Statistical rigor in user studies: provide significance testing, inter-annotator agreement, and analyses of annotator/device effects to substantiate ELO and preference claims.
- Reproducibility: release full training details (batch size, optimizer, LR schedules, augmentation, seed management), compute budgets, and code for the proxy/discriminator to enable faithful replication.
- Evaluation metric gaps: reconcile FID degradation with other metrics; add distributional realism checks (e.g., kernel inception distance, FDD) and analysis linking metric changes to architectural/algorithmic choices.
- Memory-performance trade-offs: map VRAM/unified memory vs. latency vs. quality curves across quantization levels and resolutions to guide practitioners in device-specific deployments.
Practical Applications
Overview
SD3.5-Flash introduces a practical, few-step (2–4) rectified-flow image generator that runs efficiently on consumer hardware, including mobile devices. Key innovations—timestep sharing (stable distribution matching for few-step flows), split-timestep fine-tuning (preserves prompt alignment under compressed capacity), and pipeline optimizations (encoder restructuring and 16→8→6-bit quantization, with CoreML/ANE kernels)—enable latency and memory footprints suitable for phones, tablets, and mainstream GPUs, while maintaining high aesthetics and competitive prompt adherence.
Below are actionable, sector-linked applications with feasibility notes.
Immediate Applications
The following applications can be deployed now using the released techniques and performance envelopes described (e.g., ≤10s on iPhone/iPad for 512–768px; sub-second on high-end GPUs for 512–768px).
- Consumer creativity apps (stickers, wallpapers, avatars, filters)
- Sector: Consumer software, social media
- What to build: On-device “Generate Image” features in camera/photo apps; personal avatar and sticker generators; offline style transfer and prompt-to-wallpaper creators.
- Workflow: Use 6-bit CoreML model for mobile; toggle T5-XXL off for low memory, on for complex prompts; cache negative/positive prompts; 4-step default; 2-step for fast drafts.
- Assumptions/dependencies: Apple Silicon/ANE path is production-ready; Android requires equivalent INT6/INT8 kernels (e.g., NNAPI/Qualcomm SDK). Without T5-XXL, text alignment for complex prompts drops.
- Design and marketing pipelines (fast ideation and iteration)
- Sector: Advertising, media, e-commerce
- What to build: Plugins for Adobe/Canva/Figma to produce mood boards, product variants, ad creatives with rapid local inference; per-campaign A/B asset generation.
- Workflow: 8-bit desktop variant (w/o T5) for quick ideation; enable T5-XXL for final assets needing fine-grained composition; batch rendering on 10–16 GB GPUs.
- Assumptions/dependencies: Brand safety and style control may need LoRA or prompt-engineering; T5-XXL increases VRAM/latency.
- E-commerce product imagery and personalization at scale
- Sector: Retail, marketplaces
- What to build: Automatic background replacement, seasonal variants, size/color composites; per-user tailored creatives rendered on edge workstations or in-browser via WebGPU fallback to local GPU.
- Workflow: 4-step 8-bit pipeline with prompt templates; enforce safety filters; pre-approve style libraries.
- Assumptions/dependencies: Content policy/compliance tooling required; complex compositions likely benefit from T5-XXL or curated prompts.
- Game development and UGC
- Sector: Gaming, XR
- What to build: Unity/Unreal plugins for concept art, textures, decals; client-side UGC creation (skins, posters) with offline rendering.
- Workflow: 512–768px outputs in-editor on client GPUs; 4-step as default; 2-step for previews; add in-app style libraries.
- Assumptions/dependencies: Texture/material pipelines may need post-processing (tiling, normal map derivation); copyright filters for UGC.
- Education and publishing (illustrations on demand)
- Sector: Education, publishing, NGOs
- What to build: Offline lesson-illustration tools; quick diagrams and visual aids in low-connectivity classrooms; custom storybooks.
- Workflow: 6-bit mobile/8-bit laptop models; curated prompt banks; educator-facing safety guardrails.
- Assumptions/dependencies: On-device moderation needed; domain-specific style packs help reduce prompt complexity (works better without T5).
- Privacy-sensitive content creation
- Sector: Healthcare communications, legal, finance (non-clinical visuals)
- What to build: Internal-only image generation for presentations, patient education leaflets, or client briefings without sending text to cloud.
- Workflow: 8-bit desktop model; local policy filters; option to disable T5 to reduce memory and surface only safe prompt templates.
- Assumptions/dependencies: Not for diagnostic use; institutional approvals and content governance required.
- Edge digital signage and kiosks
- Sector: Retail, events, hospitality
- What to build: On-site generative backgrounds and seasonal content refreshed periodically without internet; interactive kiosks with on-device generation.
- Workflow: Small form-factor PCs running 8-bit models; scheduled batch generation off-hours.
- Assumptions/dependencies: Asset vetting pipeline; automated prompt sets; minimal compute onsite.
- Synthetic data for computer vision
- Sector: Robotics, autonomous systems, manufacturing QA
- What to build: Lightweight generators for scene diversifications, rare edge cases, and domain randomization where bandwidth to cloud is limited.
- Workflow: Headless 8-bit pipeline for batch renders; prompt grammars for controlled variability.
- Assumptions/dependencies: Domain gaps remain; prefer pairing with simple renderers or post-processing for photometric realism; licensing of training teachers may constrain redistribution.
- Cost-optimized cloud image platforms
- Sector: SaaS, creative tools
- What to build: Replace 25–50 step backends with 2–4 step 8-bit variants to lower GPU-hours per image; provide quality “turbo” and “detailed” modes (toggle T5, steps).
- Workflow: Autoscale with 8–12 GB GPUs; route complex prompts to T5-enabled pool; cache text embeddings.
- Assumptions/dependencies: Slight drop in prompt fidelity without T5; add fallback to high-step teacher for critical tasks.
- Research replication and extension (flows and distillation)
- Sector: Academia, R&D labs
- What to build: Baselines for few-step flow distillation using timestep sharing; experiments on adversarial heads with periodic refresh; evaluation via GenEval/ImageReward.
- Workflow: Use teacher SD3.5M/Large; synthetic-teacher data; apply split-timestep fine-tuning for capacity-constrained students.
- Assumptions/dependencies: Access to teacher weights and compute; licensing compliance for derivative datasets.
Long-Term Applications
These will benefit from additional research, engineering, or ecosystem support (e.g., broader hardware kernels, multi-modal extensions, stronger safety/watermarking).
- On-device video and animation generation/editing
- Sector: Media, social, advertising
- Potential: Extend timestep sharing and split-timestep fine-tuning to video flows/consistency models for on-device short clips, cinemagraphs, or video style transfer.
- Dependencies: Temporal consistency objectives, memory scheduling for sequence models, mobile-optimized attention kernels.
- Personalized/private models on device
- Sector: Consumer, prosumer, enterprise
- Potential: Small-footprint, user-style adapters (LoRA/peft) fused into few-step flows; private brand/style generators for agencies.
- Dependencies: Efficient on-device fine-tuning (Q-LoRA-like), safety filters, adapter management; policy for IP protection.
- Multimodal expansion: audio, 3D, and AR assets
- Sector: XR, gaming, design
- Potential: Adapt rectified-flow distillation to audio TTS/noise2audio flows, quick 3D proxies via SDS-like pipelines, and AR asset generation on headsets.
- Dependencies: Teacher models for each modality, low-precision kernels for device NPUs/GPUs, evaluation standards for multimodal quality.
- Federated and edge training loops
- Sector: Edge AI, privacy tech
- Potential: Use distribution-guided distillation to push small updates to on-device students (personalization) without sharing user data.
- Dependencies: Robust on-device optimization, federated aggregation, differential privacy guarantees.
- Safety, provenance, and governance for on-device GenAI
- Sector: Policy, platforms
- Potential: Standardized on-device safety filters and red-teaming packs; watermarking compatible with low-step flows; app store compliance checklists for generative features.
- Dependencies: Watermarking schemes resilient to quantization and few-step paths; shared safety benchmarks for mobile models.
- Cross-vendor low-precision standardization (6–8 bit)
- Sector: Semiconductor, ML systems
- Potential: Generalize RMSNorm/attention kernels for Android NPUs, discrete GPUs, and CPUs; standardized INT6/FP8 calibration for generative flows.
- Dependencies: Vendor toolchains (NNAPI, CoreML, CUDA, ROCm); open-sourced quantization recipes and accuracy audits.
- Simulation and robotics training at the edge
- Sector: Robotics, autonomous systems
- Potential: Procedural imagery for rare events or texture randomization on robots/drones without uplink; rapid updates in the field.
- Dependencies: Domain adaptation pipelines, task-specific realism metrics, safety constraints for operational environments.
- Enterprise “brand-safe” generators under compliance
- Sector: Finance, healthcare comms, government
- Potential: Locked-down, auditable generators with local logs, prompt whitelists, and policy enforcement; offline creative support under strict data residency.
- Dependencies: Policy tooling, audit trails, on-device moderation, and periodic model review/recertification.
- Tooling ecosystem: SDKs and workflows
- Sector: Developer tools
- Potential: SD3.5-Flash SDKs for iOS/macOS/Windows/Linux, CoreML/ONNX export with validated kernels, distillation toolkits (“teacher → few-step student”) for model owners.
- Dependencies: Stable APIs, licensing clarity for teacher/student redistribution; reproducible training recipes and eval suites.
Notes on Feasibility and Risks
- Quality–efficiency trade-offs: 2–4 step students remain an approximation; complex compositional prompts benefit from T5-XXL and/or higher resolution and may still lag the multi-step teacher.
- Hardware coverage: Apple CoreML/ANE path is demonstrated; Android NPUs and non-Apple NPUs need equivalent low-precision kernels (RMSNorm, attention) and calibration.
- Data and licensing: Training leveraged synthetic data from SD3.5 teachers; downstream redistribution and commercial uses should respect teacher/model licenses and content policies.
- Safety and compliance: On-device generation reduces data exfiltration risk but increases the need for robust, local safety filters, content provenance, and UGC governance.
- Generalization: Encoder-dropout-based T5 removal is specific to SD3.5 pretraining; portability to other model families may require re-training.
- Metrics: Human-preference metrics (IR/AeS) improved; FID differences vs. prior teachers highlight metric sensitivity—don’t over-index on a single metric for deployment gates.
These applications leverage the paper’s practical contributions—timestep sharing for stable few-step training, split-timestep fine-tuning for prompt alignment under compression, and an end-to-end pipeline (encoder restructuring + 6–8-bit quantization + CoreML kernels)—to make high-quality, private, and low-latency image generation feasible across consumer devices and modest desktops today, with clear paths to richer multimodal and safety-critical deployments over time.
Glossary
- Adversarial Objective: A training strategy involving generator and discriminator networks where the generator creates data to fool the discriminator, improving generation quality. "Removing the adversarial objective destabilises training, resulting in poor generation quality."
- Aesthetic Score: A metric that quantifies the aesthetic quality of generated images to reflect human preferences. "Metrics like ImageReward (IR) and Aesthetic Score (AeS) are human preference metrics."
- Argmax: An operation that finds the input value corresponding to the maximum output value of a function. "We demonstrate that SD3.5-Flash consistently outperforms existing few-step methods, making advanced generative AI truly accessible for practical deployment."
- Consistency Distillation: A process for refining a multi-step model into a streamlined single or few-step model, improving efficiency and consistency. "Consistency trajectory models: Learning probability flow ODE trajectory of diffusion."
- Distribution Matching Distillation (DMD): A distillation method matching the distribution of a few-step student model with a multi-step teacher model using Kullback-Leibler divergence. "We refine our pre-trained student using the DMD objective."
- Few-Step Distillation: A model compression technique reducing the inference steps of diffusion models to improve speed while maintaining quality. "In few-step regimes, this problem becomes particularly pronounced as errors cannot be corrected through subsequent iterations."
- Flow Matching: A generative modeling method that directly learns an ODE-based mapping without SDE, defining a velocity field for trajectory sampling. "Flow matching models define a separate class of generative methods that directly learn an ODE-based mapping."
- GenEval: A metric for evaluating text-to-image alignment by detecting depicted objects in generated images. "We also include comparisons on the GenEval score where images of specific objects are generated in different settings."
- Kullback-Leibler (KL) Divergence: A statistical measure quantifying how one probability distribution diverges from a second expected probability distribution. "DMD computes the gradient for the KL-divergence between teacher and student distributions."
- Null Embeddings: Replacements of model weights (like text encoders) with zero or default values to reduce computational requirements without significant loss in accuracy. "We leverage encoder dropout pre-training and substitute T5-XXL with null embeddings."
- ODE (Ordinary Differential Equation): An equation involving derivatives of a function, used to model the continuous change in phenomena. "This trajectory from noise to data is typically modelled as the solution to a Stochastic Differential Equation (SDE)."
- Prompt-Image Alignment: The fidelity with which an image generation model turns text prompts into accurate and corresponding images. "SD3.5-Flash outperforms other few-step models and the teacher in image quality."
- Rectified Flow: A generative modeling pathway where data is transported from a noise to a target distribution using simplified noise addition techniques. "In rectified flow pipelines, samples are noised following a straight path between the data distribution."
- Score Function: In diffusion models, it represents the gradient of the log probability density of data, guiding the denoising process. "Diffusion models in score-based generative frameworks learn a score function."
- Split-Timestep Fine-Tuning: A technique expanding model capacity during training by temporally adjusting parameters, aiding in complex task resolution. "Split-timestep fine-tuning resolves the capacity-quality tradeoff during distillation."
- Stable Gradient Signals: Well-behaved and predictable gradient flows during model training, ensuring reliable learning updates. "This provides stable gradient signals for known noise levels and reliable flow predictions."
- Stochastic Differential Equation (SDE): An equation involving a stochastic process that describes the evolution of systems over time, incorporating elements of randomness. "This trajectory from noise to data is typically modelled as the solution to a Stochastic Differential Equation (SDE)."
- Timestep Distillation: A reduction process in advanced modeling where the model's timestep count is minimized for efficient computation. "Timestep distillation often weakens the correspondence between text prompts and generated outputs."
- Trajectory Guidance: An objective in training that aligns the learning trajectory of a student model with a teacher model to smooth training paths. "We pre-train the student generator with a trajectory guidance objective."
- VRAM (Video Random Access Memory): Memory used in GPUs to store graphical data, affecting the capacity and speed of image rendering and processing. "Their computational demands -- 25+ steps, 16GB+ VRAM, 30+ seconds per image -- make them inaccessible."
Collections
Sign up for free to add this paper to one or more collections.