- The paper demonstrates that few-step distillation using progressive distribution matching within SNR subintervals improves both generative diversity and dynamic fidelity.
- The method introduces a Mixture-of-Experts architecture with LoRA-based expert initialization to efficiently bridge distribution gaps in score-based models.
- Empirical results confirm that Phased DMD outperforms traditional DMD methods in preserving motion dynamics and compositional details in image and video tasks.
Phased DMD: Few-step Distribution Matching Distillation via Score Matching within Subintervals
Overview and Motivation
Phased DMD introduces a principled framework for few-step distillation of score-based generative models, specifically targeting the limitations of one-step Distribution Matching Distillation (DMD) in high-capacity, complex generative tasks such as text-to-video and text-to-image synthesis. The method leverages progressive distribution matching and score matching within SNR subintervals, enabling the construction of Mixture-of-Experts (MoE) generators that incrementally refine sample quality and diversity. This approach addresses the instability and diversity collapse observed in prior multi-step distillation strategies, particularly those employing stochastic gradient truncation (SGTS).
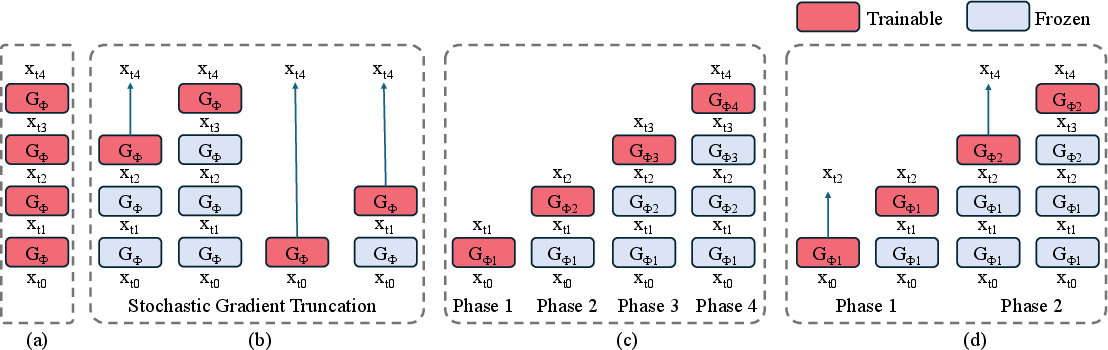
Figure 1: Schematic diagram contrasting Few-step DMD, Few-step DMD with SGTS, Phased DMD, and Phased DMD with SGTS, highlighting the progressive, phase-wise distillation and MoE structure.
Theoretical Foundations
Phased DMD builds upon the continuous-time Gaussian diffusion process, parameterized by signal-to-noise ratio (SNR) schedules. The framework exploits the Markovian property of diffusion, allowing for the decomposition of the denoising trajectory into subintervals. Each phase corresponds to a distinct SNR range, with a dedicated expert network responsible for mapping the distribution from one intermediate timestep to the next. The generator optimization objective in each phase is derived from the reverse KL divergence between the generated and real data distributions, with the fake score estimator trained via a rigorously derived score matching objective within the corresponding subinterval.
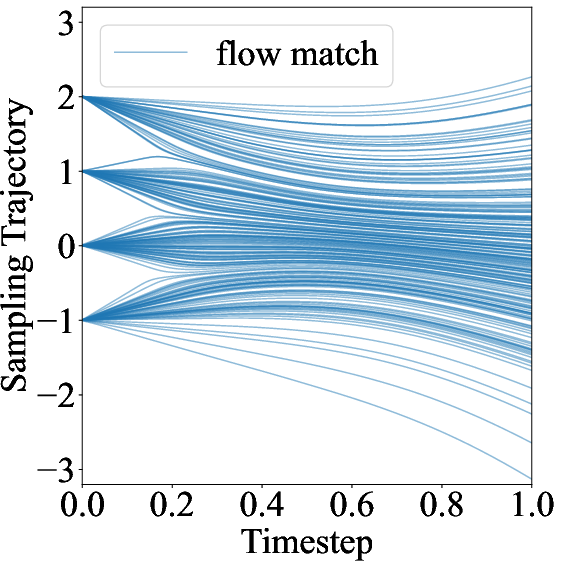
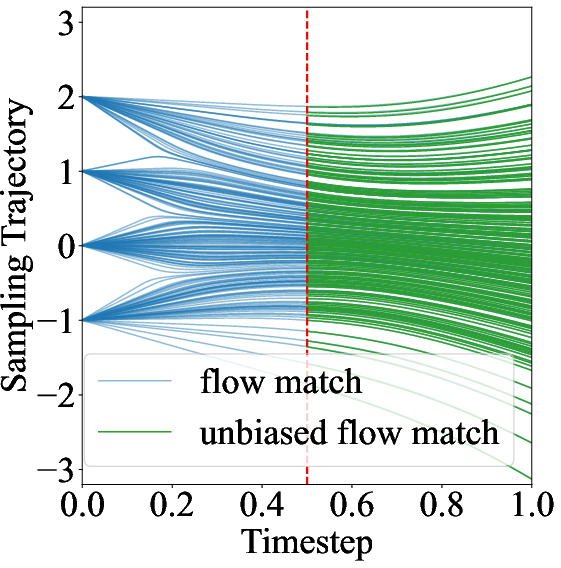
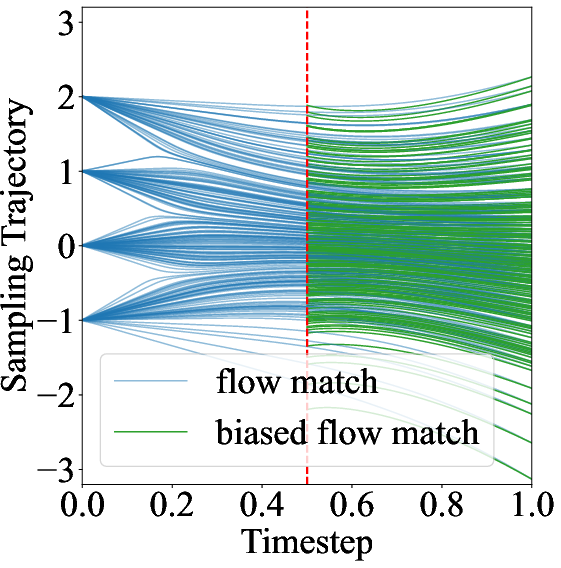
Figure 2: Flow Match objective and its unbiased/bias variants within subintervals, demonstrating the necessity of correct score matching for unbiased trajectory estimation.
The score matching objective for the fake diffusion model in phase k is:
Jflow(θ)=Exs∼p(xs),ϵ∼N,t∼T(t;s,1),xt=αt∣sxs+σt∣sϵ[clamp(σt∣s21)∥σt∣sψθ(xt)−(αs2αs2σt+αtσs2ϵ−αsσt∣sxs)∥2]
This formulation ensures unbiased score estimation within each subinterval, avoiding the singularity issues that arise as σt∣s→0.
Implementation Details
Phased DMD is implemented as a multi-phase distillation pipeline, where each phase consists of:
- Expert Initialization: Each expert is initialized from the pretrained teacher model, with LoRA used for parameter-efficient adaptation.
- Progressive Distillation: The SNR range is partitioned into reverse-nested intervals, with each expert trained to map the distribution from tk−1 to tk.
- Score Matching: The fake score estimator is trained using the subinterval score matching objective, ensuring accurate guidance for generator updates.
- MoE Structure: Experts share a common backbone, with LoRA weights switched per phase, minimizing memory overhead.
The framework supports integration with SGTS, allowing for further reduction in computational graph depth and memory usage during training and inference.
Empirical Results
Phased DMD is validated on large-scale image and video generation models, including Qwen-Image (20B) and Wan2.2 (28B). The method consistently outperforms vanilla DMD and DMD with SGTS in preserving generative diversity and retaining key capabilities of the base models.
- Generative Diversity: Quantitative metrics (DINOv3 cosine similarity, LPIPS) show that Phased DMD achieves lower feature similarity and higher perceptual distance, indicating superior diversity preservation.



Figure 3: Examples generated by Qwen-Image distilled with Phased DMD, demonstrating high-fidelity text rendering and compositional diversity.
- Motion Dynamics and Camera Control: In text-to-video and image-to-video tasks, Phased DMD retains the base model's motion intensity and dynamic degree, as measured by optical flow and VBench metrics, outperforming SGTS-based distillation.

Figure 4: Comparison of video frames generated by Wan2.2-T2V-A14B base and distilled models, illustrating preservation of dynamic motion and camera instructions.

Figure 5: Additional video frame comparisons, highlighting compositional and temporal fidelity across distillation methods.
- Ablation on Subinterval Strategies: Empirical studies confirm that reverse-nested SNR intervals and high-noise-level injection are critical for convergence and quality. Disjoint intervals or low-noise injection lead to degraded results.


Figure 6: The effect of noise injection intervals, showing the superiority of reverse-nested intervals for stable training and realistic outputs.


Figure 7: The effect of noise injection timestep, demonstrating that exclusive low-noise injection fails to converge.
Practical Implications and Limitations
Phased DMD enables efficient few-step generation with high fidelity and diversity, making it suitable for deployment in resource-constrained environments and real-time applications. The MoE structure allows for scalable adaptation to increasingly complex generative tasks without prohibitive memory or computational costs. However, the diversity improvement is less pronounced for base models with inherently low output diversity, such as Qwen-Image. The framework is generalizable to other divergence objectives (e.g., Fisher divergence in SiD), though this remains an open area for future research.
Future Directions
Potential extensions include:
- Generalization to alternative score-based objectives and consistency models.
- Integration of trajectory data for further enhancement of diversity and dynamics, with consideration for maintaining the data-free paradigm.
- Exploration of more granular phase partitioning and expert specialization for ultra-high-resolution or long-horizon generation tasks.
Conclusion
Phased DMD provides a theoretically grounded, practically efficient framework for few-step distillation of score-based generative models. By leveraging progressive distribution matching and subinterval score matching, it achieves superior diversity and fidelity preservation, particularly in complex image and video generation tasks. The MoE architecture and phase-wise training paradigm offer a scalable solution for accelerating diffusion model sampling while retaining the essential capabilities of large base models.

