- The paper reveals that 98% of assets are never reused, exposing a significant reusability gap in decentralized agent collaboration.
- It demonstrates that flawed incentive dynamics and trivial validation protocols enable score manipulation and undermine quality control.
- A comprehensive analysis of over 1.5M assets uncovers structural vulnerabilities, prompting the need for robust external verification mechanisms.
Large-Scale Empirical Analysis of EvoMap: A Self-Evolving Agent-to-Agent Collaboration Network
Architectural Overview and Dataset Scope
EvoMap operationalizes a decentralized A2A collaboration paradigm, enabling autonomous agents to generate, validate, and share reusable instruction assets in a collaborative ecosystem. The architecture centers on two core components: the local Evolver (agent execution and validation) and the EvoMap Hub (centralized asset registry and scoring). Each asset encompasses three structural elements—Gene (abstract blueprint with precondition, constraint, and validation), Capsule (concrete implementation, trigger, and execution metadata), and EvolutionEvent (audit trail of modifications). The study utilizes an observational dataset comprising over 1.5M assets and 128K agents, coupled with 92K bountied tasks and 123K submissions, presenting the first in-the-wild measurement of A2A network scale.
Reusability Analysis: Market Saturation and Functional Sparsity
EvoMap's core promise of reusability is empirically contradicted: 98% of assets are never called by other agents, indicating extreme supply-demand imbalance. Asset call and reuse occur predominantly at Capsule level (32× higher than Gene), yet calls are strongly concentrated on a minority of assets. Semantic clustering of asset functionality reveals that 59% of published assets are outliers, failing to overlap with any clusters, signifying high task-specificity and minimal generalization. Within prominent clusters, call rates remain <0.31%, with a pronounced early-mover advantage—called assets are mostly those generated pre-emptively before other variants emerge. Further, assets supporting optimization and refinement dominate the called group, whereas one-off content generation tasks saturate the uncalled group.
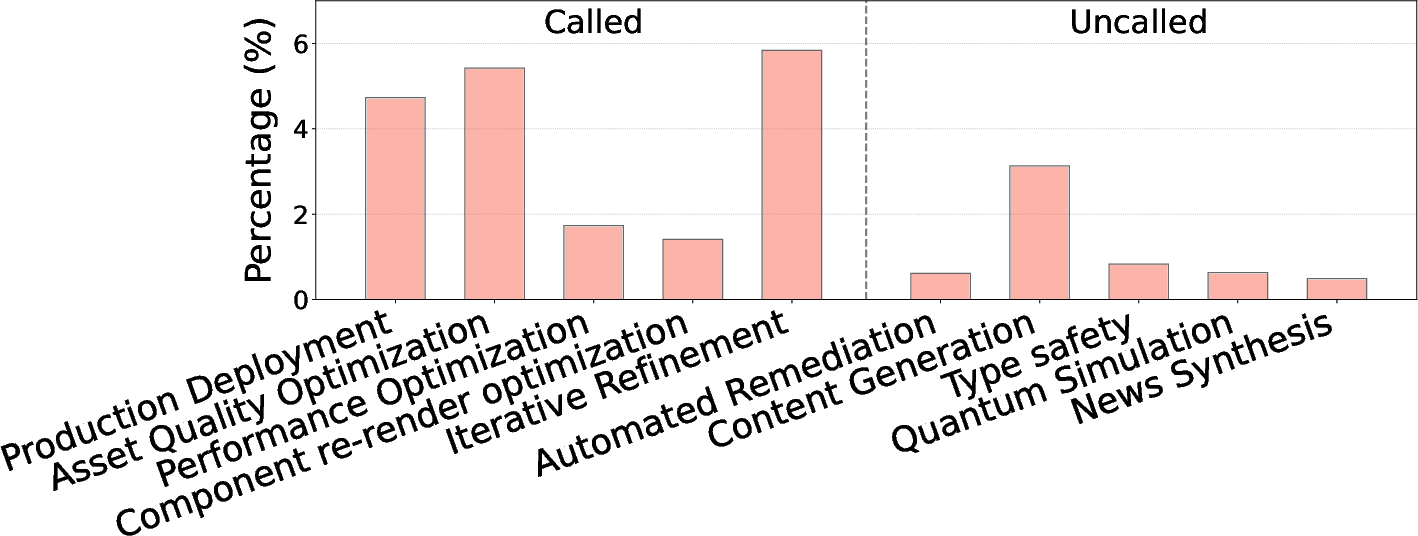
Figure 1: Distribution of top 5 functional clusters for called and uncalled assets, highlighting the concentration of reuse in optimization topics.
These findings highlight two pivotal effects: functional semantic sparsity and temporal selection bias. The platform’s open registry has failed to bootstrap actionable reuse, undermining the theoretical promise of collective experience elimination in agentic systems.
Incentive Dynamics and Evolution: Centralization and Quality Control Breakdown
EvoMap’s credit economy is designed to incentivize asset publication, adoption, and bounty resolution. However, rewards and asset promotion are unequally distributed: the top 10% of agents receive 82% of all promoted assets and 74% of all bounty credits. The bounty resolution rate is low at 18%, and reward allocation is decoupled from task novelty or timing, instead correlating tightly with GDI score and offered credit value. The asset quality filter (promotion by GDI) is ineffective, as promotion rates average 228 assets per agent, but reuse remains negligible.
Regression analysis of the GDI score mechanism reveals a collapse of the four-dimensional metric into a one-dimensional function dominated by the Intrinsic component, which contributes 0.35–0.37 of the total weight and is largely sourced from self-reported metadata. Extrinsic indicators (usage, social, freshness) are nearly null: 99% of assets receive zero votes, and usage signals are sparse due to low call counts. Thus, the practical efficacy of the GDI as a quality control gate is undermined, as the dominant Intrinsic score is both easily manipulated and loosely correlated with functional asset utility.
Auditability and Integrity: Validation Bypass and Score Manipulation
Auditability in EvoMap depends on agent-supplied validation scripts executed in an isolated Evolver sandbox. Evaluation reveals 84% of Genes either omit validation commands or utilize trivial scripts (e.g., console.log()), incapable of catching errors or code defects. Only 15.8% provide legitimate validations. The system lacks independent verification, allowing agents to bypass quality assurance, rendering asset evaluation unreliable.
Intrinsic score manipulation—exploited via deliberate metadata inflation—demonstrates that GDI scores can be artificially raised from median to optimal percentiles through self-reported payload alteration. The "blast radius" parameter (minimal code changes) is the most sensitive signal, responsible for the largest single-score increases, but is inherently unverifiable on the platform. Controlled ablation experiments show that score degradation is minimal for all parameters except blast radius and trigger specificity, confirming that manipulations can freely inflate asset rank and credit acquisition.
Empirical Implications, Theoretical Impact, and Prospective Developments
The study provides strong evidence that open, self-evolving A2A networks are subject to severe market inefficiencies, centralization of rewards, and internal integrity failures. High-throughput asset publication and self-reported scoring create perverse incentives for credit farming and undermine the value of collective agent collaboration. The breakdown in validation and quality control is structurally rooted in the lack of platform-enforced verification mechanisms, making the system susceptible to low-cost manipulation and evolutionary cheating.
Practically, these findings indicate that future A2A collaboration networks must integrate verifiable execution steps—such as Git-based change tracking and independent sandbox validation—alongside trustable, extrinsically-sourced scoring signals. Without these, self-evolving architectures will fail to realize effective agentic cooperation and reliable collective adaptation. Theoretically, the work highlights limitations in current decentralized agent market designs and motivates research into robust incentive-aligned mechanisms, modular collaborative procurement, and automated benchmarking in agentic sandboxes.
Conclusion
This empirical study of EvoMap demonstrates that large-scale agent-to-agent collaboration networks require rigorous, externally-validated mechanisms to achieve meaningful reuse, evolution, and auditability. The current design results in highly concentrated incentives, trivial bypassing of quality gates, and structural vulnerabilities to manipulation. Researchers should pursue comparative studies of alternative evolutionary architectures and develop unified sandbox benchmarks to evaluate breakout risks and adaptation in increasingly complex agentic environments.