The Collaboration Gap
Abstract: The trajectory of AI development suggests that we will increasingly rely on agent-based systems composed of independently developed agents with different information, privileges, and tools. The success of these systems will critically depend on effective collaboration among these heterogeneous agents, even under partial observability. Despite intense interest, few empirical studies have evaluated such agent-agent collaboration at scale. We propose a collaborative maze-solving benchmark that (i) isolates collaborative capabilities, (ii) modulates problem complexity, (iii) enables scalable automated grading, and (iv) imposes no output-format constraints, preserving ecological plausibility. Using this framework, we evaluate 32 leading open- and closed-source models in solo, homogeneous, and heterogeneous pairings. Our results reveal a "collaboration gap": models that perform well solo often degrade substantially when required to collaborate. Collaboration can break down dramatically; for instance, small distilled models that solve mazes well alone may fail almost completely in certain pairings. We find that starting with the stronger agent often improves outcomes, motivating a "relay inference" approach where the stronger agent leads before handing off to the weaker one, closing much of the gap. Our findings argue for (1) collaboration-aware evaluation, (2) training strategies developed to enhance collaborative capabilities, and (3) interaction design that reliably elicits agents' latent skills, guidance that applies to AI-AI and human-AI collaboration.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
The Collaboration Gap — A simple explanation
What is this paper about?
This paper looks at how well AI “agents” work together. An AI agent here is a computer program that reads and writes in natural language (like a chat) and tries to solve tasks. The authors show that many AIs that do great on their own often struggle a lot when they have to team up with another AI. They call this the “collaboration gap.”
What questions were the researchers asking?
To keep things clear and testable, the researchers focused on teamwork in a maze puzzle. They asked:
- Do AIs that solve mazes well on their own still do well when they must cooperate?
- What makes AI–AI teamwork fail or succeed?
- Does it matter which AI speaks first in a team?
- Can a stronger AI “set things up” and then let a weaker AI finish the job successfully?
How did they test this?
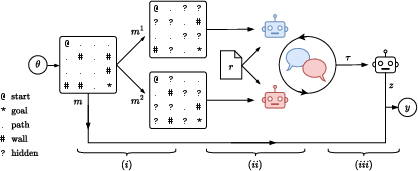
They created a maze challenge that makes teamwork necessary. Imagine two students trying to solve the same maze, but each can only see half of it. Neither can solve it alone—they must talk and agree on each move to get from start to finish.
Here’s how it worked:
- Each pair of AIs got two “partial maps.” Half of the maze cells were hidden for one AI and the other half were hidden for the other AI. Together, their maps add up to the full maze.
- The AIs had to chat, share what they see, and agree on every move.
- There were no strict rules about how to talk—no fixed script—so the AIs had to figure out how to communicate clearly on their own.
- A separate “grader” AI acted like a referee: it read the chat, figured out the path they agreed on, and checked whether it was a correct solution. This made it possible to test lots of AIs quickly and fairly.
- They tested 32 leading AI models in three modes: solo (alone), homogeneous pairs (two copies of the same AI), and heterogeneous pairs (two different AIs).
A key teamwork challenge is “grounding,” which means reaching the same understanding. For example, if one AI says “(1,2)” meaning “row 1, column 2,” but the other AI reads that as “column 1, row 2,” they’ll immediately disagree and get lost—like two friends using different coordinate systems on a map without realizing it.
What did they find?
Here are the main results and why they matter:
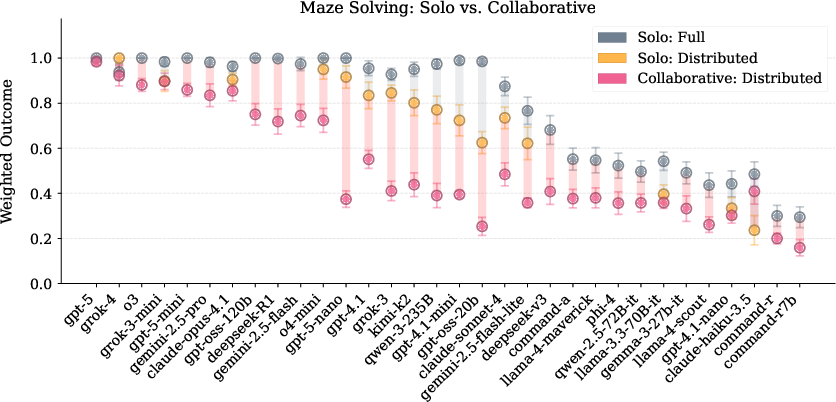
- The collaboration gap: Many AIs that solve mazes very well alone do much worse when they must work with another AI, even if the partner is an identical copy. This shows that “being smart” alone doesn’t guarantee “being good at teamwork.”
- Smaller or distilled models struggle more: “Distilled” models are smaller, cheaper versions trained to imitate bigger ones. These often dropped the most in performance when collaborating. That suggests current training methods don’t teach collaboration well.
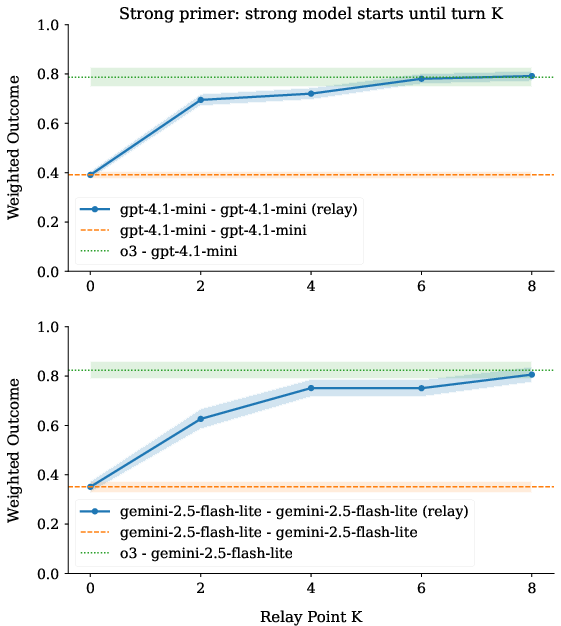
- Who talks first matters: In mixed pairs (a stronger AI with a weaker one), having the stronger AI start the conversation usually leads to better results. When the weaker AI starts, the stronger one sometimes imitates the weaker AI’s poor communication style, which can pull performance down.
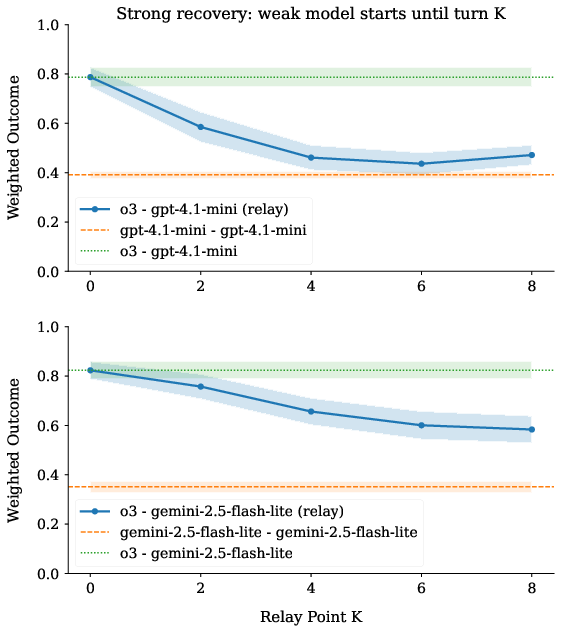
- Relay inference helps: The authors tried a “relay race” approach. The stronger AI begins the conversation for a few turns to set good ground rules and a clear plan, then hands off to the weaker AI to finish. This simple trick raised teamwork performance a lot. But trying to “fix” a messy conversation later is harder—early turns matter most.
- Not all AIs behave the same: Some AIs were especially good at correcting misunderstandings and guiding the conversation back on track. Others were too agreeable and failed to challenge wrong moves suggested by a partner.
Why does this matter?
AI systems in the future will often be made of many different agents created by different companies, with different abilities and information. If these agents can’t collaborate well, the whole system may fail—even if each part is strong on its own. The study suggests three big takeaways:
- We need tests that measure collaboration, not just solo skill.
- We should train AIs specifically to collaborate—current methods aren’t enough.
- We should design interactions (like who speaks first and how ground rules are set) to bring out good teamwork, both for AI–AI and human–AI teams.
In short, teamwork is its own skill. It’s not something we can just assume will “emerge” from solo intelligence. Like good sports teams or group projects, successful AI teams need shared understanding, clear communication, and smart leadership.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, framed to guide future research.
- External validity: Do the observed “collaboration gap” and ordering effects persist in tasks beyond mazes (e.g., software engineering, tool use, multi-hop retrieval, embodied planning) where representations, goals, and actions are less neatly verifiable?
- Modality generalization: How do results change with multimodal inputs/outputs (images, diagrams, GUIs) or action APIs, rather than text-only communication?
- Scale and complexity: Does the gap widen on larger or more complex instances (e.g., bigger mazes, long-horizon tasks, hierarchical subgoals), and what are the scaling laws of collaboration performance vs. model size and task complexity?
- Beyond two agents: How do findings extend to teams of 3+ heterogeneous agents, including role assignment, leadership emergence, coalition formation, and subgroup coordination?
- Communication constraints: What is the impact of realistic constraints (bounded message length, latency, asynchronous turns, dropped messages, noisy channels) on collaboration outcomes?
- Protocol structure vs. flexibility: What is the trade-off between free-form communication (as used here) and light-weight structured protocols (e.g., shared scratchpads, schema negotiation slots) in reducing grounding failures without overfitting to rigid formats?
- Grounding mechanisms: Which specific grounding failures (coordinate frames, symbol agreements, action semantics) account for most errors, and can targeted schema-negotiation steps reliably prevent them?
- Causal role of ordering: What mechanisms drive the strong “who goes first” effect (e.g., priming, imitation, deference, discourse planning), and can we causally isolate them via controlled first-message templates and counterfactual swaps?
- Imitation vs. leadership: Why do stronger models adopt weaker partners’ styles, and can we elicit robust leadership without harming cooperation (e.g., via calibrated assertiveness or meta-instructions)?
- Distillation degradation: Which aspects of distillation pipelines (teacher data selection, RLHF objectives, loss design) damage collaborative skills, and can distillation preserving multi-agent competencies be designed and validated?
- Collaboration-aware training: Does self-play, population-based training, or supervised fine-tuning on collaborative dialogues close the gap, and what data and curricula are most effective?
- Theory of Mind and partner modeling: Can models infer a partner’s capability and adapt strategy (defer, explain, or lead) online, and which signals (error rates, hesitations, contradictions) are predictive?
- Misaligned/erroneous partners: How robust are agents to partners that are noisy, uncertain, deceptive, or partially adversarial, and what safeguards improve resilience?
- Partial observability design: How do different obfuscation regimes (ratios ≠ 50%, structured occlusion, correlated missingness, contradictory maps, injected noise) affect collaboration difficulty and error modes?
- Relay inference generality: Do relay benefits hold across other model families and tasks, and how should one choose the handoff point K adaptively (e.g., using confidence signals or conversation features) to optimize cost–performance?
- Recovery limits: Why do strong models struggle to recover after weak models lead for several turns, and can explicit “reset”/re-grounding phases or tool-assisted reconciliation salvage failing collaborations?
- Cost/latency trade-offs: What are the compute and time costs of different collaboration strategies (priming, recovery, structured protocols), and how do they change under practical budgets and SLAs?
- Evaluation metrics: Beyond weighted outcome, which process metrics (grounding time, conflict-resolution steps, miscommunication rate, leadership stability, turn efficiency) most strongly predict success and are generalizable?
- Grader dependence: Despite checks, how sensitive are results to grader choice or drift over time, and can non-LLM or hybrid graders reduce bias and schema-mismatch errors?
- Reproducibility over time: Given API model updates and non-determinism, how stable are results longitudinally, and what protocols (pinning versions, periodic re-evaluation) are needed for durable comparisons?
- Language/culture robustness: Do cross-lingual collaborations or differences in discourse conventions exacerbate grounding failures, and can bilingual or meta-linguistic scaffolds help?
- Privacy and tool use: How do privacy constraints and tool-mediated actions (shared maps, planners, verification tools) alter collaboration dynamics and eliminate specific failure modes?
- Safety vs. effectiveness: Does RLHF toward “helpfulness/harmlessness” inadvertently increase deference or agreeableness that harms leadership and error correction in AI–AI collaboration?
- Optimal heterogeneity: When does pairing across families help or hurt, and can we predict “affinity” between models (architectural traits, decoding styles) to form effective teams?
- Error taxonomy and dataset: A systematic, labeled taxonomy of failure types (grounding, planning, deference, hallucinated consensus) and release of annotated transcripts would enable targeted interventions and benchmarking.
Practical Applications
Immediate Applications
Below are actionable uses that can be piloted now by adapting the paper’s benchmark, findings, and “relay inference” orchestration pattern.
- Collaboration-aware model selection and procurement (industry, government, academia)
- Use case: Add a “collaboration fitness” test to pre-deployment evaluations of multi-agent systems (customer support bots, coding agents, analytics co-pilots, AIOps responders).
- Tools/workflows: Integrate maze-style distributed-information tests and auto-grading into CI/CD or MLOps gates; report weighted outcomes and ordering effects.
- Assumptions/dependencies: Benchmark domain adaptation; reliable LLM-based auto-grading; repeated runs to handle non-determinism; data access/privacy constraints for agent-to-agent communication.
- Relay inference to cut cost while raising reliability (software, customer support, operations)
- Use case: Let the strongest (costlier) model send the first 1–3 messages to establish grounding and a schema, then hand off to a cheaper model to execute.
- Tools/workflows: Orchestrators (e.g., LangGraph/Custom FSMs) implementing “K-turn priming” and agent swapping mid-dialogue; cost-aware routing policies.
- Assumptions/dependencies: Access to at least one stronger model; orchestration that preserves shared memory/state; domain schemas exist or can be induced.
- Lead-agent selection and ordering policy (software, robotics, finance ops)
- Use case: Always initiate multi-agent tasks with the most capable agent (or a “grounding specialist”) to reduce miscoordination.
- Tools/workflows: Capability scoring + policy that picks the initiator; health checks on early turns to confirm shared representation alignment.
- Assumptions/dependencies: Reliable capability estimates; permissioning that lets the lead agent view necessary context.
- Grounding-first prompts and interaction design (human–AI and AI–AI)
- Use case: Insert a “schema negotiation” turn before task execution (define coordinate frames, naming, action semantics, tie-breakers, conflict resolution).
- Tools/workflows: Prompt templates/checklists (e.g., “Define terms, coordinate origin, units, allowed actions; confirm mutual understanding; then propose first step.”).
- Assumptions/dependencies: Teams adopt shared templates; organizational buy-in to trade one extra turn for higher success.
- Collaboration gap auditing for distilled models (model ops, procurement)
- Use case: Test small/distilled models for collaboration degradation before replacing larger models in agent teams.
- Tools/workflows: A/B tests comparing solo vs. homo-/heterogeneous pairings; scorecards for degradation.
- Assumptions/dependencies: Access to base and distilled variants; matched prompts; consistent evaluation seeds.
- Auto-grading of unstructured agent transcripts (education, QA, DevEx)
- Use case: Use a grader LLM plus schema normalization to extract outcomes from unstructured multi-agent chats (code diffs, plans, routes, checklists).
- Tools/workflows: “Grader” microservice with multi-scheme normalization; confidence reporting; sampling-based re-grading.
- Assumptions/dependencies: Grader stability; careful prompt design to reduce bias; domain-specific normalizers.
- Risk controls for multi-agent failure modes (safety, compliance)
- Use case: Early-turn monitors to detect coordinate/representation mismatches and perceptual conflicts; enforce escalation or re-grounding.
- Tools/workflows: Meta-agent “referee” that checks for: mixed schemas, inconsistent coordinates, unverified assumptions; triggers re-alignment step.
- Assumptions/dependencies: Logging and observability of agent exchanges; governance to permit automated intervention.
- Team-of-agents patterns in software engineering (software)
- Use case: “Architect leads, implementer follows” pairing; senior agent seeds structure/tests, junior agent fills in code.
- Tools/workflows: Relay inference with K-turn priming; PR-level auto-grading (tests pass/fail) as outcome metric.
- Assumptions/dependencies: Repo access; CI runners; test coverage as ground truth.
- Tiered customer support automation (customer service)
- Use case: Expert triage agent defines problem schema and next steps, hands off to cheaper resolution agent; escalates back only if needed.
- Tools/workflows: Conversation templates with explicit agreement gates; transcript grader to verify resolution steps.
- Assumptions/dependencies: Integration with ticketing/CRM; data minimization to respect privacy when sharing context between agents.
- Human-AI collaboration primers (daily life, education)
- Use case: Individuals prompt assistants to “propose a shared schema and confirm assumptions before proceeding” in group tasks or planning.
- Tools/workflows: Saved prompt snippets for grounding (“Before we start, define terms, units, and success criteria; confirm we agree.”).
- Assumptions/dependencies: Users adopt best-practice prompts; assistants follow instruction reliably.
- Vendor RFP and evaluation rubric updates (policy, procurement)
- Use case: Require collaboration metrics (solo vs. team, ordering effects, relay performance) in RFPs for AI agent solutions.
- Tools/workflows: Standardized test suite and reporting templates; minimum thresholds for heterogeneous collaboration.
- Assumptions/dependencies: Vendor participation; shared evaluation seeds; disclosure of model versions.
Long-Term Applications
These require further research, scaling, or standardization but are natural extensions of the paper’s findings.
- Collaboration-aware training and distillation (academia, model labs)
- Use case: Fine-tune or reinforce models on grounding, schema negotiation, conflict resolution, and ToM-like inference; “distill with collaboration in the loop.”
- Tools/products: Multi-agent RLHF/RLAIF datasets that penalize imitation of weak schemas and reward successful grounding; synthetic partial-observability corpora.
- Assumptions/dependencies: High-quality curated multi-agent data; reproducible multi-agent rollouts; reliable reward modeling for collaboration quality.
- Dynamic grounding standards beyond rigid protocols (standards bodies, industry consortia)
- Use case: Define a minimal “grounding handshake” (units, frames, action vocabularies, conflict resolution) that interoperates across vendor agents.
- Tools/products: Lightweight, negotiable schemas layered atop MCP/A2A/ACP; certification test suites modeled after this benchmark.
- Assumptions/dependencies: Cross-vendor buy-in; versioning and backward compatibility; privacy-preserving schema negotiation.
- Interoperability labels and marketplaces for agent ecosystems (industry platforms)
- Use case: Marketplaces that rate agents on heterogeneous collaboration, ordering robustness, and relay performance with other families.
- Tools/products: “CollabScore” badges; compatibility matrices; routing engines that pick agents based on pairwise performance.
- Assumptions/dependencies: Public benchmarks; shared telemetry; incentives for truthful reporting.
- Early-phase oversight and safety guarantees (regulators, safety teams)
- Use case: Require “early-turn control points” in safety-critical deployments (healthcare, finance, autonomous systems) where a strong agent or human must seed/approve grounding.
- Tools/products: Policy templates mandating relay inference or grounding checks; audits of partial-observability interactions; failure-mode libraries.
- Assumptions/dependencies: Regulatory frameworks; compliance tooling; domain-specific ground truths.
- Multi-robot and robot–cloud coordination under partial observability (robotics, disaster response)
- Use case: Scout robot (or cloud planner) primes task schema and shared map; local robot continues execution; strong-recovery limited to early turns.
- Tools/products: Onboard “grounding” modules; bandwidth-aware schema exchange; embedded graders that verify path consistency.
- Assumptions/dependencies: Robust perception-to-schema translation; constrained comms; safety validation in the loop.
- Care-team AI orchestration (healthcare)
- Use case: Triage AI establishes shared case representation and consent/constraints; specialist AI continues; escalations triggered by conflict detection.
- Tools/products: EHR-integrated orchestrators with grounding checklists; transcript graders for care-plan consistency.
- Assumptions/dependencies: HIPAA/GDPR compliance; audit trails; clinical validation and liability frameworks.
- Collaboration-aware curriculum and digital literacy (education, workforce)
- Use case: Teach grounding-first collaboration with AI, ordering effects, and handoff strategies; assess group work with auto-grading of process and outcome.
- Tools/products: Classroom simulations of partial observability; rubrics for schema negotiation; instructor dashboards.
- Assumptions/dependencies: Age-appropriate design; access to reliable graders; institutional adoption.
- End-to-end collaboration benchmarks for real tasks (software, data, ops)
- Use case: Extend maze paradigm to domain analogs (e.g., partially observed data pipelines, fragmented codebases, distributed incident timelines).
- Tools/products: Synthetic environments with programmatic ground truth; task-specific graders (tests, SLAs, KPIs).
- Assumptions/dependencies: Domain modeling; scalable auto-grading; guardrails against data leakage.
- Formal methods for collaboration properties (academia, safety)
- Use case: Specify and verify properties like “agreement before action,” convergence to shared schema, and bounded imitation risk.
- Tools/products: Protocol verifiers; runtime monitors; model-checking for collaborative policies.
- Assumptions/dependencies: Formalizable abstractions of agent dialogs; tractable verification at scale.
- Compute-optimized orchestration (platforms, finance)
- Use case: Learn the optimal K for relay inference per domain/task to minimize spend while achieving target reliability.
- Tools/products: Bandit/AutoML over K-turn priming; telemetry to learn success–cost frontiers.
- Assumptions/dependencies: Cost and quality signals; stable model behavior across versions.
- Human-in-the-loop collaboration governance (policy, enterprises)
- Use case: Policies that position humans as initial “grounding leaders” or final verifiers in high-stakes tasks; measure when to defer to/away from agents.
- Tools/products: Playbooks for escalation; governance dashboards showing ordering effects and collaboration KPIs.
- Assumptions/dependencies: Organizational readiness; change management; calibrated trust in agents.
- Domain-specific “grounding negotiator” services (platforms, vendors)
- Use case: A specialized microservice that enters first, negotiates schema and semantics, then exits before execution.
- Tools/products: Pluggable negotiator agent; adapters for sector schemas (units in energy, ICD/SNOMED in healthcare, GAAP in finance).
- Assumptions/dependencies: High-quality domain ontologies; secure context brokering; vendor-agnostic APIs.
These applications leverage three core insights from the paper: (1) collaboration ability is a distinct axis of capability that current training often misses; (2) ordering matters—letting the stronger agent lead narrows the gap; and (3) minimal “relay inference” priming can deliver large gains at low cost. Together, they suggest concrete engineering patterns, evaluation protocols, and governance practices for building reliable multi-agent systems in real settings.
Glossary
- Action grounding: Agreeing on the meaning of proposed actions to ensure both parties interpret a move the same way. "the condition that both agents need to agree on each move necessitates action grounding"
- Agent Communication Protocol (ACP): A proposed standard for inter-agent messaging and interoperability on the internet. "“ACP”"
- Agent-based systems: Architectures composed of independent agents with distinct capabilities and knowledge. "agent-based systems composed of independently developed agents with different information, privileges, and tools."
- Agent-to-Agent Protocol (A2A): A protocol for direct communication between AI agents to enable interoperability. "“A2A”"
- Agentic AI: AI systems designed to act autonomously and coordinate across tasks or with other agents. "Collaborative Models Are the Future of Agentic AI"
- Auto-grading: Using an AI grader to automatically extract and evaluate outcomes from unstructured transcripts. "the ability to use auto-grading allows us to massively scale our experiments."
- Centrally orchestrated architectures: Systems where a central controller coordinates multiple agents or components. "or centrally orchestrated architectures"
- Collaboration gap: The performance drop observed when capable models work together compared to solo performance. "Our results reveal a “collaboration gap”: models that perform well solo often degrade substantially when required to collaborate."
- Collaboration‑aware evaluation: Assessment methods that explicitly measure and account for collaborative capabilities. "collaboration‑aware evaluation"
- Cross-family pairings: Collaborative settings where agents come from different model providers or families. "selected “cross-family” pairings."
- Distillation strategies: Methods for compressing larger models into smaller ones, often at the cost of capabilities. "our current distillation strategies lose more than just information from the “tail end” of a base model’s knowledge distribution"
- Distilled models: Smaller models derived from larger ones through distillation, typically with reduced capacity. "Distilled models further appear disproportionally affected"
- Distributed information: Splitting task-relevant data across multiple views so no single agent has the full picture. "we “distribute” the information over two map copies"
- Frontier models: The most capable, often latest-generation AI models available commercially. "most commercially available frontier models"
- Grounding: Establishing mutual understanding about references, representations, and intentions during communication. "the concept of “grounding”, the process by which participants attempt to establish mutual understanding"
- Heterogeneous agents: Agents that differ in capabilities, context, tools, or underlying models. "effective collaboration among these heterogeneous agents"
- Heterogeneous collaboration: Collaboration between agents powered by different models or with differing strengths. "Results for selected heterogeneous collaborations are shown"
- Homogeneous collaboration: Collaboration between agents powered by identical copies of the same underlying model. "Homogeneous Collaboration"
- In-context learning: A model’s ability to adapt behavior based on examples or instructions provided within the prompt. "“in-context learning”, or simply “prompting”"
- Long-horizon: Tasks requiring extended sequences of coordinated steps or reasoning over many turns. "long-horizon, multi-agent collaboration"
- Model Context Protocol (MCP): A protocol for providing models with tools, data, and structured context for interaction. "“MCP”"
- Multi-agent collaboration: Multiple agents coordinating to solve tasks jointly. "multi-agent collaboration in partially observed environments"
- Multi-turn dialogue: An interactive, iterative exchange where agents communicate across many turns to complete a task. "The agents then engage in a multi-turn dialogue"
- Non-determinism: The property that repeated runs can produce different outputs due to stochasticity or variability. "Most models accessible over APIs are not deterministic"
- Ordering effects: Outcome differences caused by which agent speaks or acts first in a collaboration. "We observe significant ordering and cross-family effects."
- Open-world integration: Deploying agents in unconstrained environments requiring flexible, ad-hoc communication. "open-world integration of AI agents will likely require flexible, on-the-fly communication"
- Partially observed environments: Settings where each agent has only incomplete or partial information about the task state. "partially observed environments"
- Perceptual conflicts: Disagreements stemming from agents’ differing observations of the environment or state. "they might encounter perceptual conflicts where they disagree on the contents of a specific cell"
- Priming: Using an initial message or structure to seed more effective collaboration and shared understanding. "the potential of priming to improve collaboration in weaker models"
- Prompt engineering: Crafting inputs and instructions to elicit desired behaviors and better outputs from models. "focused on “prompt engineering” to improve model outputs"
- Relay inference: A collaborative strategy where a stronger agent seeds initial steps before handing off to a weaker agent. "we propose “relay inference,” a new collaborative strategy where a more capable model “seeds” the initial steps of a task for a weaker one."
- Reinforcement learning (RL): A framework for learning policies through trial-and-error interactions and rewards. "reinforcement learning (RL)"
- Rollouts: Executions of full interaction sequences used to evaluate behavior or performance. "We perform at least 100 rollouts per agent"
- Shared mental model: A common internal representation of the task or environment built through communication. "The first challenge is to build a shared mental model of the maze itself."
- Small LLMs (SLMs): Compact LLMs intended to be efficient yet capable for many agentic tasks. "“small” LLMs (SLMs) to lead the agentic age."
- Specialist librarian problem: The need for an agent to iteratively clarify a user’s true information needs before solving them. "specialist librarian problem"
- Weighted outcome: A continuous performance metric defined via distance-to-go relative to the optimal path length. "a “weighted outcome”, which is defined as the ratio between (a) the distance from the last valid position on a path to the goal state and (b) the optimal solution from the start state"
Collections
Sign up for free to add this paper to one or more collections.

