Simulating Human Memory with Language Models
Abstract: LLMs are increasingly being deployed as user simulators, but their memory is far more reliable than that of real users. To measure this gap, we run a series of classic memory experiments from psychology on both humans and LLMs. Across tasks, we find that out-of-the-box LLMs exhibit better memory than humans, even when prompted to imitate human behavior. We then show that better prompting strategies and the use of a compactor can cause LLMs to forget content in a more human-like way. Using these methods, we show preliminary evidence that LLMs with human-like memory constraints can function as more effective user simulators in a downstream education task. Finally, we release human reference data and benchmarks to support future work on simulating human memory with LLMs.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Simulating Human Memory with LLMs — A Simple Explanation
Overview
This paper studies how well AI LLMs can pretend to have human-like memory. The authors compare how people and AI remember information in classic memory tests. They find that most AI models remember far better than humans, which makes them bad “user simulators” for tasks like teaching. Then they test ways to make AI forget in a more human-like way, and show that doing this can make the AI more useful for simulating how real people learn.
Key Questions
The paper asks three main questions:
- How different is AI memory from human memory on well-known psychology tests?
- Can we make AI “forget” more like humans do, just by giving it better instructions (prompts)?
- If we force the AI to use a small, human-like working memory, does it become a more realistic stand-in for a human in practical tasks, like choosing the best study materials?
Methods and Approach
Here’s how the researchers tested their ideas:
- They built a set of 10 memory tasks used in psychology. Examples include:
- Digit span: remember a growing list of numbers (like 3, then 5, then 7 numbers).
- Reverse digit span: remember the numbers, but say them backwards.
- N-back: check whether the current letter matches the one from 1, 2, or 3 steps earlier.
- Story tasks: read a short passage, then answer questions or retell the story.
- Map task: study a map, then answer questions about routes after the map disappears.
- Craft task: learn simple “recipes” for making items from parts, then answer questions after the recipes are hidden.
- They collected human results from 50 people and compared them to nine different LLMs.
- They tried three types of instructions (prompts) for the AI:
- Task Prompt: just do the task.
- Human Prompt: pretend you are a human in a psychology experiment.
- Memory Prompt: pretend you are a human and remember that humans sometimes forget.
- They also built a small “memory tool” for the AI called Compactor:
- Think of it like a backpack with only four pockets. The AI must cram what it thinks is most important into four labeled chunks (like “characters,” “events,” “key facts,” “rules”).
- After packing, the AI must answer questions using only what’s in those four pockets.
- This imitates human “working memory,” which is often described as holding about four “chunks” of information.
- To measure how human-like the AI’s memory was, they used a similarity score. You can think of it like comparing two piles of sand (the humans’ scores vs. the AI’s scores) and asking: how much sand would you need to move to make the piles look the same? Smaller differences mean more human-like behavior.
Main Findings
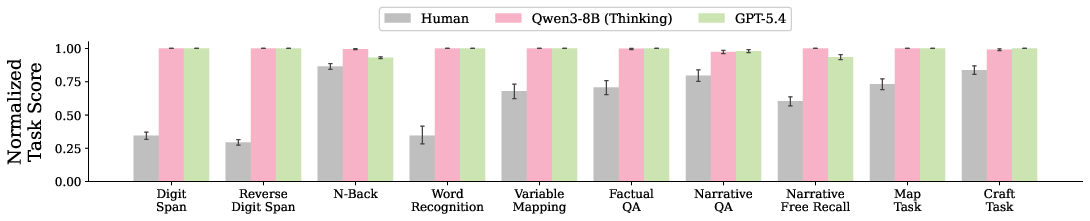
- Out-of-the-box AI remembers too well: On all ten tasks, AIs scored near perfect, while humans made normal memory mistakes (for example, humans can usually recall around 7 digits, AIs handled 20 easily).
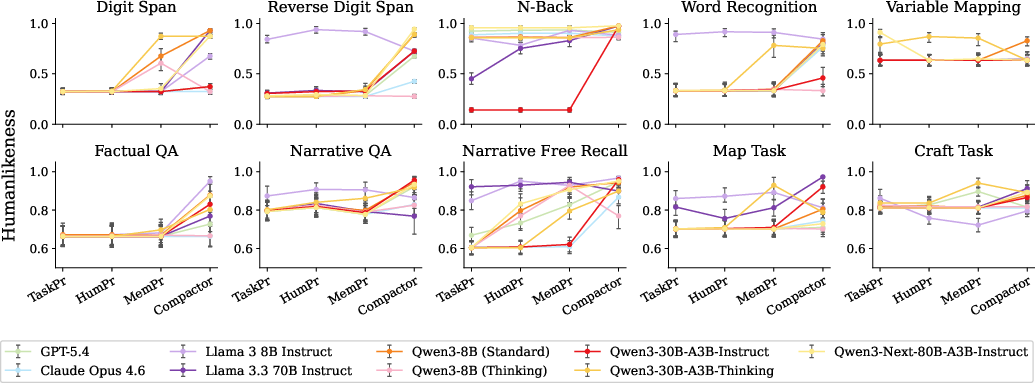
- Just telling AI to “act human” doesn’t fix it: Prompts that say “simulate a human” or “humans forget” didn’t reliably make the AI behave more like people across tasks.
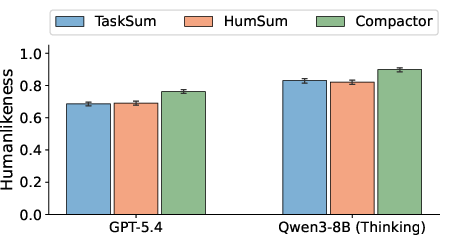
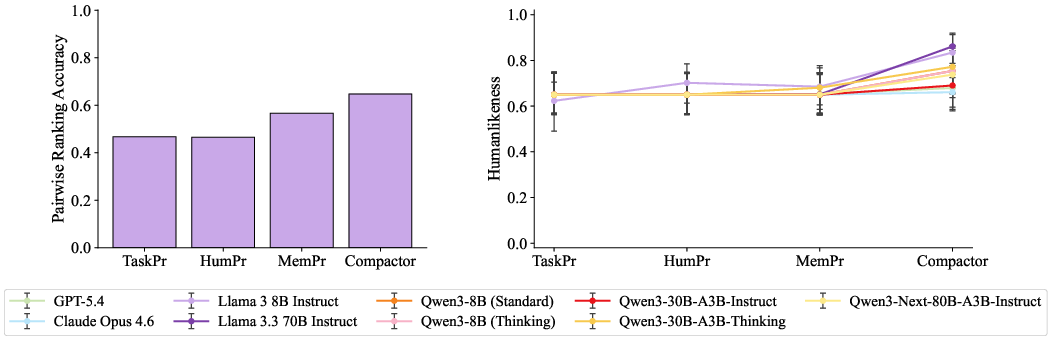
- Limiting AI’s working memory helps: Using the Compactor (the four-pocket memory) made AI scores much closer to human scores, especially on the short-term memory tasks like digit span, reverse digit span, N-back, and word recognition.
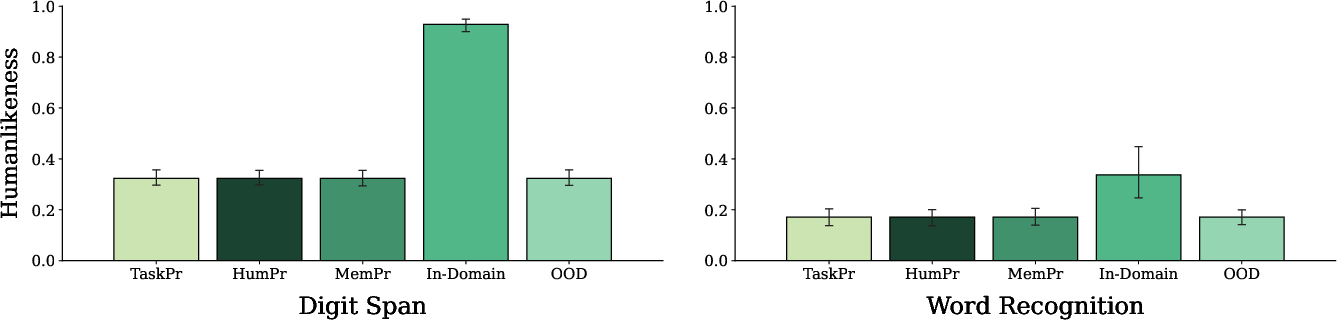
- Example-based training is task-specific: Showing the AI real examples of human performance helped only when the examples matched the same task. Examples from a different task didn’t transfer well.
- AI and humans forget differently: Even when the AI made mistakes, the types of mistakes weren’t the same as humans’. For instance, AIs often reproduced nearly the whole sequence with one wrong digit in the middle, while humans showed different error patterns.
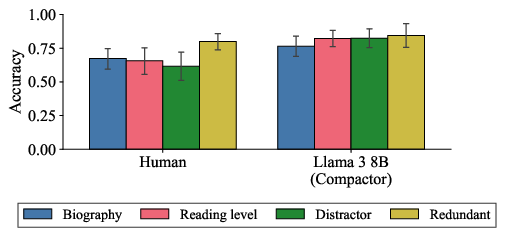
- Practical test in education: In a small teaching experiment, the human-like memory AI (with Compactor) was better at predicting which version of a reading passage people would remember best. It wasn’t perfect, but it was clearly more useful than the standard models.
Why It Matters
If we want to use AI to design lessons, train professionals, or test policies, the AI should behave like real people—including having realistic limits on memory. This paper shows:
- Today’s AIs are too good at remembering compared to humans, which can mislead designers and teachers.
- Simple memory limits (like forcing the AI to keep only four chunks) can make the AI a better stand-in for humans.
- More work is needed to match not just how much AIs forget, but the way they forget, so their mistakes look human too.
In short, building AIs with human-like memory can make them more trustworthy and useful when they’re used to simulate real users, especially in education and training.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, formulated to guide actionable future research.
- Benchmark coverage: No tasks directly assess semantic memory, false memories (e.g., DRM paradigm), prospective memory, or visual/spatial memory beyond the map task; extending the suite to these domains is needed to claim broader “human memory” coverage.
- Modality constraint: All tasks are “text in, text out”; auditory presentation (canonical for digit span) and mixed-modality encoding/retrieval were not examined, limiting ecological validity and comparability to classic human results.
- Time/attention constraints: LLMs were not subjected to timing, attentional load, or dual-task interference comparable to humans (e.g., presentation rate, enforced delays, distractors), which are central to human forgetting; effects of such constraints on model behavior remain unexplored.
- Retention interval and consolidation: No tests of delayed recall or multi-session retention (minutes/hours/days) were included; human forgetting curves and consolidation dynamics (e.g., sleep effects) are unaddressed.
- Serial position effects: The benchmark does not analyze whether models reproduce human primacy/recency or transposition gradients in list recall; methods to induce and measure these effects in LLMs are missing.
- Interference phenomena: Proactive/retroactive interference and similarity-based confusions (core to human memory) were not systematically probed; tasks that manipulate item similarity or update frequency are needed.
- Error typologies: Although the paper notes LLM error patterns differ from humans (e.g., truncated vs mid-sequence substitution), there is no systematic taxonomy or cross-task analysis of error types to target specific mechanisms.
- Individual variability: The approach compares aggregate distributions; it does not model individual differences (e.g., variance across participants, age, cognitive ability) or whether LLMs can simulate distinct “personas” with different memory capacities.
- Calibration and metacognition: No assessment of confidence, calibration, or metacognitive judgments (e.g., feel-of-knowing, judgments of learning) was included, despite their importance for user simulation in education.
- Metric limitations: Humanlikeness is defined via 1D Wasserstein distance on normalized task scores, which ignores within-task structure (e.g., serial position curves, item-wise confusions) and may compress rich patterns into a single scalar.
- LLM distributional sampling: It is unclear how LLM score “distributions” were obtained (number of seeds, temperature, sampling strategies); within-model variability and stochasticity were not systematically analyzed.
- Embedding-based free recall scoring: Narrative recall was evaluated with BLEU and a single embedding model; sensitivity to scoring method (e.g., ROUGE-L, BERTScore, event-based scoring, human grading) and potential embedding biases remains untested.
- Few-shot ICL generalization: In-domain examples help but fail to transfer across tasks; the paper leaves open whether larger or structured ICL corpora, meta-prompts, or task-agnostic “memory-style” schemas could enable cross-task generalization.
- Prompt dependence and compliance: The effect of different instruction framings, refusal tendencies, verbosity constraints, and decoding settings (temperature/top-p) on memory-like behavior was not explored.
- Model coverage: Evaluation focuses on transformer LLMs; architectures with explicit recurrence or state (e.g., RWKV, Mamba), or memory-augmented models, were not compared to test whether native inductive biases yield more human-like memory.
- Compactor capacity K: The memory slot capacity is fixed at K=4 (motivated by Cowan), but no ablation probes optimal K, adaptive K per task, or individual/persona-conditioned K; sensitivity to K and slot management policies is unknown.
- Chunking strategy and content: Compactor’s chunking is unconstrained and not validated against human chunking behavior (e.g., event segmentation, semantic clustering); how to induce human-typical chunk boundaries and content remains open.
- Memory operations: Compactor only supports write/overwrite/delete; there is no mechanism for graded decay, interference-based degradation, retrieval latency, rehearsal, or priority-based retention, all central to human memory.
- Generalization beyond summarization: The paper ablates against a single free-form summary but does not test other bottlenecks (e.g., event schemas, scripts, graph-structured memory, compressed rehearsal traces) or learning the compaction policy end-to-end.
- Long-horizon interaction: Tasks are single-session and mostly single-turn; whether human-like memory constraints improve fidelity in multi-turn, long-horizon dialogues and agent settings is not evaluated.
- Education application scope: The reranking proof-of-concept uses 10 biographies and multiple-choice questions; effects may not transfer to authentic curricula, open-ended responses, or real learning outcomes (delayed tests, transfer tasks).
- Baseline comparisons for reranking: The study lacks comparisons to simple heuristics (e.g., readability metrics, length, redundancy counts) or classical cognitive models (e.g., ACT-R–style memory predictions) for document selection.
- Cross-linguistic and cross-cultural generality: All human participants were U.S.-based native English speakers; memory simulation across languages, scripts, reading directions, and cultural familiarity is untested.
- Population diversity: Effects of age, working-memory capacity, neurodiversity, language proficiency, and domain expertise on alignment are not examined; simulators that capture population heterogeneity remain to be developed.
- Task realism and content familiarity: Some materials are LLM-generated; how prior knowledge, schema consistency, and real-world familiarity modulate human–LLM alignment is unmeasured.
- Fairness and robustness: The paper does not examine whether memory simulation quality varies with content domain, demographic references, or sensitive attributes.
- Data sufficiency and power: Human sample sizes (N=50 for benchmark; N=100 for application) may be underpowered for fine-grained distributional analyses and subgroup effects; replication with larger, stratified cohorts is needed.
- Training vs prompting: No attempt was made to fine-tune or reinforcement-learn models to match human memory distributions or error types; whether learning from human traces yields better cross-task alignment remains open.
- Mechanistic alignment: The work evaluates external behavior but does not probe whether internal model dynamics (activations/attention patterns) mirror cognitive mechanisms (e.g., gating, maintenance, interference).
- Transfer to other downstream tasks: Beyond reranking texts, it is unknown whether human-like memory constraints improve user simulation in tutoring, programming assistance, health counseling, or policy simulations.
- Safety implications: The trade-off between making models forgetful for realism and potentially losing critical safety-relevant recall is not analyzed; mechanisms for task-conditional memory constraints are needed.
- Reproducibility details: Tool-call specifications, prompt templates, and seed control are provided in appendices, but complete protocols for sampling-based evaluations (e.g., number of runs per task/model) are not fully standardized for exact replication.
- Open question on optimality: The paper shows no consistent benefit of “frontier” models in memory simulation; it remains unknown which capabilities (e.g., longer context, better reasoning) actually hinder or help human-like forgetting and why.
Practical Applications
Immediate Applications
Below are deployable use cases that build directly on the paper’s methods (Compactor memory bottleneck, prompts, benchmark, and evaluation) and findings (LLMs over-remember; human-like memory improves user simulation and document reranking).
Education and Training
- Memory-aware user simulators for content selection in LMSs and tutoring systems
- Sector: Education/EdTech
- What: Use the Compactor agent (4-slot key–value memory) to predict which reading variant (easier, redundant, distractor) students will best recall; rerank or adapt materials accordingly.
- Tools/workflow: Wrap existing LLMs with Compactor’s encode→recall flow; batch-score content variants; deploy as a reranking API before lesson delivery.
- Assumptions/dependencies: Access to tool-calling LLMs; content is text; four-chunk capacity generalizes; student cohort resembles benchmark population.
- Curriculum design assistants that enforce memory-friendly scaffolding
- Sector: Education/Instructional Design
- What: Authoring assistants that “lint” lessons for cognitive load, recommending chunking, redundancy, and removal of distractors to match human memory limits.
- Tools/workflow: Content linting plugin using the benchmark’s tasks as heuristics; Compactor-based “student persona” to spot overload.
- Assumptions/dependencies: Domain calibration required; authoring teams accept automated edits; evaluation based on Wasserstein similarity metric.
- Realistic mock students for teacher training and assessment
- Sector: Education/Teacher Prep
- What: Simulated students that forget in human-like ways, making practice exams, Socratic dialogues, and feedback sessions more authentic.
- Tools/workflow: Compactor personas for varied working-memory capacity; scenario scripts that limit recall access to key–value memories only.
- Assumptions/dependencies: Prompt libraries for domains; oversight to avoid reinforcing incorrect pedagogy.
Software, AI, and Product UX
- “Memory-constrained” user simulators for product research and A/B testing
- Sector: Software/Product Research
- What: Evaluate UI copy, onboarding flows, and help docs with simulated users that miss or forget steps like real users do.
- Tools/workflow: Instrumented tasks (e.g., multi-step signup) with Compactor users; compare completion and error patterns; iterate on UX microcopy.
- Assumptions/dependencies: Text-first tasks; mapping from benchmark tasks (digit span, word recognition) to product flows is valid.
- Middleware for memory-aware agents
- Sector: AI Platforms/Developer Tools
- What: Package the Compactor agent as a drop-in wrapper (K=4 key–value store) to optionally enforce human-like memory in any LLM workflow.
- Tools/workflow: OpenAI-style tool-calling functions write_memory/delete_key; recall-only answers; configurable K for personas.
- Assumptions/dependencies: Model/tool-calling support; governance to prevent misuse (e.g., faking incompetence).
- Evaluation and model selection using the Human Memory Simulation Benchmark
- Sector: AI Evaluation/ML Ops
- What: Integrate the released human data, tasks, and Wasserstein-based humanlikeness metric into model eval dashboards to pick simulators that match target users.
- Tools/workflow: CI pipelines that run the 10 tasks; report humanlikeness scores alongside accuracy.
- Assumptions/dependencies: Benchmark relevance to domain; licensing of benchmark assets.
Customer Support and Enterprise Enablement
- Script and knowledge-base optimization for recall under load
- Sector: CX/Customer Support/Enterprise Docs
- What: Rewrite support scripts and KB articles with redundancy and chunking tuned to human memory constraints; evaluate with Compactor user simulators.
- Tools/workflow: Pre/post A/B via simulator reranking; memory-linting for long docs; add “recap inserts” aligned to four slots.
- Assumptions/dependencies: Textual channels (chat, email); stable mapping between simulator preferences and human outcomes.
- Compliance and safety training with realistic “forgetting”
- Sector: Enterprise L&D/Compliance
- What: Simulated trainees that miss steps or forget policy details at human-like rates to stress-test training materials and assessments.
- Tools/workflow: Compactor trainees; reporting on missed/retained items; targeted remediation content generation.
- Assumptions/dependencies: Domain adaption needed; legal validation for training equivalence.
Healthcare Communication and Patient Education (non-diagnostic)
- Memory-informed patient education materials
- Sector: Healthcare/Patient Education
- What: Rerank or rewrite discharge instructions and medication guides to maximize recall; insert critical redundancy, limit distractors.
- Tools/workflow: Compactor-based pretesting of materials; “must-remember” facts highlighted and duplicated.
- Assumptions/dependencies: Not a clinical decision tool; requires clinician review; text-only applicability.
Research and Academia
- Cognitive modeling baselines for experiments
- Sector: Cognitive Science/Psycholinguistics
- What: Use the benchmark and Compactor to set “human-likeness” baselines, generate hypotheses, and design stimuli with controlled memory load.
- Tools/workflow: Wasserstein similarity for model–human fits; task scripts for replication.
- Assumptions/dependencies: IRB constraints; generalization beyond U.S.-based English speakers.
Long-Term Applications
These require further research, validation, scaling, or domain-specific integration to be reliable and safe.
Education and Workforce Development
- Personalized memory-aware tutoring agents at scale
- Sector: Education/EdTech
- What: Tutors that estimate individual working-memory profiles, adapt chunking, pacing, and redundancy over time, and predict retention trajectories.
- Dependencies: Longitudinal calibration; privacy-preserving learner models; alignment of forgetting patterns (beyond current Compactor) to real human errors.
- Automated curriculum optimization via simulator-in-the-loop training
- Sector: EdTech/Content Platforms
- What: Reinforcement learning with memory-constrained simulators as reward models to evolve lesson sequences and assessments.
- Dependencies: Proven correlation between simulator rewards and student outcomes; guardrails against gaming.
Healthcare and Clinical Settings
- Preclinical testing of digital therapeutics and cognitive interventions
- Sector: Digital Health/Neuropsychology
- What: Use increasingly human-like memory simulators to screen cognitive training regimens or medication adherence aids before clinical trials.
- Dependencies: Regulatory acceptance; diverse, clinically validated memory models (beyond text tasks); multimodal stimuli.
- Synthetic patients for clinician training with realistic memory variability
- Sector: Medical Education/Simulation
- What: Simulated patients who forget timelines, misremember doses, or confabulate details consistent with human error distributions.
- Dependencies: Domain-grounded error taxonomies; integration with standardized patient protocols; rigorous bias and safety reviews.
Policy, Communication, and Public Health
- Population-level simulations incorporating memory constraints
- Sector: Public Policy/Public Health
- What: Forecast uptake/retention of guidance (e.g., emergency instructions, health campaigns) under realistic forgetting; optimize message design.
- Dependencies: Demographic calibration (age, education, language); multilingual and multimodal memory modeling; ethical governance.
- Misinformation resilience modeling
- Sector: Policy/Platform Safety
- What: Simulate how people retain or forget corrections vs. falsehoods; test interventions (repetition, spacing, salience) before deployment.
- Dependencies: Empirically matched forgetting patterns; longitudinal dynamics; platform integration.
Robotics and Human–Robot Interaction
- HRI policies that respect human memory limits
- Sector: Robotics/Industrial Operations
- What: Robots and cobots that pace instructions, repeat critical steps, and chunk directions anticipating human recall failures.
- Dependencies: Embedding text-based memory models into multimodal HRI; real-world validation in safety-critical environments.
Software Engineering and Knowledge Work
- “Human-memory-calibrated” coding assistants and documentation copilots
- Sector: Software/DevTools
- What: Assistants that avoid overloading users, schedule reiterations of key API details, and predict which context snippets a developer will forget.
- Dependencies: Mapping from psych tasks to developer workflows; IDE telemetry and privacy-safe personalization; validated benefit in productivity studies.
- Organizational knowledge retention simulators
- Sector: Enterprise/Knowledge Management
- What: Simulate how teams forget process steps after handoffs; design SOPs with redundancy and recap triggers.
- Dependencies: Domain adaptation; change-management buy-in; measurement of downstream error reduction.
AI Systems and Alignment
- Training assistants with human-like cognitive resource constraints
- Sector: AI Alignment/Agent Design
- What: Bake in bounded memory as an architectural prior to produce assistants that collaborate more naturally with humans.
- Dependencies: Better models of forgetting types (not just capacity); task-generalization beyond few-shot; benchmarks extended beyond text-only memory.
- Standardized “humanlikeness” metrics in AI model cards
- Sector: AI Governance/Evaluation
- What: Report memory humanlikeness alongside accuracy and safety for downstream selection in user-facing apps.
- Dependencies: Community adoption; broader benchmarks (semantic/visual memory); consensus on acceptable ranges.
Notes on Assumptions and Dependencies
- Human memory capacity proxy: The Compactor enforces “chunks” based on Cowan (2001); domain- and population-specific variability may require tuning.
- Modality constraints: The benchmark is text-in/text-out; extending to audio, vision, or mixed modalities will require new tasks and validation.
- Population generalization: Human data comes from N≈50 U.S.-based native English speakers; broader demographics are needed for policy/healthcare use.
- Error pattern mismatch: Current methods improve score distributions but still diverge in error types from humans; applications depending on fine-grained error realism need further R&D.
- Tooling requirements: Best results rely on tool/function-calling LLMs and controllable agent frameworks; some closed models or environments may limit this.
- Ethics and safety: Simulating cognitive limitations can be misused; governance is required to prevent manipulative practices and to ensure accessibility and fairness.
Glossary
- ablation: An experimental analysis technique where components of a system are removed or modified to assess their contribution. "We ablate Compactor in Appendix~\ref{app:ablation}, comparing it to an unstructured summarizer agent that receives the same input but produces a single free-form prose summary instead of keyed chunks."
- BLEU score: A metric for evaluating text generation by comparing n-gram overlap between candidate and reference texts. "evaluated by a BLEU score and an embedding-based similarity score computed using sentence-transformers/all-MiniLM-L6-v2."
- bootstrapped confidence intervals: Uncertainty estimates computed by resampling data with replacement to form confidence intervals. "Error bars indicate bootstrapped 95\% confidence intervals."
- chain-of-thought reasoning: A prompting or reasoning approach where models generate explicit step-by-step reasoning. "regardless of model size or whether the model uses chain-of-thought reasoning."
- cognitive map formation: The process of building an internal representation of spatial environments and relations. "This task relates to cognitive map formation and spatial relational memory."
- Compactor: The paper’s agent that enforces a human-like working memory bottleneck using a fixed-size key–value store. "we construct an agent \cite{yao2023react,sumers2024cognitive} that we refer to as Compactor."
- computational psycholinguistics: The study of language processing using computational models and methods. "Computational psycholinguistics."
- context window: The span of tokens a LLM can attend to at once; effectively its short-term memory during inference. "Longer context windows do not guarantee reliable memory use"
- directed acyclic graph (DAG): A directed graph with no cycles, often used to represent dependencies or workflows. "that form a directed acyclic graph (DAG), and then answer questions about how items combine after the rules are removed."
- embedding similarity: A measure of closeness between texts using vector representations in an embedding space. "Performance is evaluated using embedding similarity."
- empirical CDF: The empirical cumulative distribution function, which summarizes the distribution of observed data. "the empirical CDFs of humans and LLMs."
- episodic memory: Memory for specific events or experiences, including when and where they occurred. "This task can be viewed as a form of episodic memory assessment"
- executive function: Cognitive processes that control and regulate other abilities and behaviors (e.g., updating, inhibition, task-switching). "This is a widely used paradigm for studying cognitive control and executive function, including working memory processes."
- few-shot prompting: Supplying a model with a small number of examples in the prompt to guide its behavior on a task. "This suggests that the benefit of few-shot prompting is not attributable to exposure to generic human-like mistakes, but rather to elements of task-specific structure."
- hippocampal indexing theory: A neurobiological theory proposing that the hippocampus indexes distributed cortical representations to enable episodic memory retrieval. "inspired by the neurobiological hippocampal indexing theory"
- humanlikeness (similarity measure): The paper’s metric for how closely model performance matches humans, defined as 1 minus the normalized Wasserstein distance. "Finally, we convert into a similarity measure , where larger values indicate closer human--model alignment."
- in-context learning (ICL): A model’s ability to infer task behavior from examples provided in its input, without parameter updates. "These results highlight a key limitation of in-context learning (ICL) for human simulation"
- key–value memory module: A structured memory mechanism storing compressed information as key–value pairs with fixed capacity. "This agent explicitly implements a human-like working memory bottleneck via a key-value memory module."
- multi-hop QA: Question answering that requires combining information across multiple pieces of evidence or reasoning steps. "improve performance on multi-hop QA benchmarks"
- N-back: A working-memory task where one decides if the current item matches the one shown n steps earlier. "N-back. Participants see a sequence of letters and must identify whether each letter matches the one shown steps earlier (1-back, 2-back, 3-back)."
- OpenAI tool-calling format: A standardized interface for LLMs to invoke external tools or functions by structured calls. "two tool-use functions in the OpenAI tool-calling format"
- pairwise reranking accuracy: An evaluation metric measuring how often a system correctly prefers the same item as humans when comparing pairs. "We also compute pairwise reranking accuracy, as follows."
- persona-conditioned prompting: Prompting that conditions a model’s responses on a specified persona to induce diverse or human-like behavior. "techniques like verbalized sampling \citep{zhang2025verbalized} or persona-conditioned prompting \citep{park2023generative}"
- positional interpolation: A method to extend or modify positional encodings so models can handle longer contexts than trained on. "such as positional interpolation \cite{chen2023extending} and rotary embeddings \cite{su2024roformer}."
- retrieval augmented generation: Systems that fetch external information at inference time to augment the model’s generation. "retrieval augmented generation systems inspired by the neurobiological hippocampal indexing theory"
- rotary embeddings: A positional encoding technique that applies rotations in embedding space to encode token positions. "such as positional interpolation \cite{chen2023extending} and rotary embeddings \cite{su2024roformer}."
- sparse embedding lookups: Memory mechanisms that retrieve information using sparse indexing into embedding stores rather than dense attention alone. "sparse embedding lookups \cite{cheng2026conditional,lin2025sparsememory}"
- verbalized sampling: A technique where models explicitly articulate sampled choices or uncertainties to produce diverse outputs. "verbalized sampling \citep{zhang2025verbalized}"
- Wasserstein distance (earth mover's distance): A distance between probability distributions measuring the minimal “work” to transform one into the other. "we use the Wasserstein distance, or earth mover's distance, between the distributions of human and LLM performance on the task"
- working memory capacity: The limited number of items or chunks that can be actively maintained and manipulated in mind. "Humans are typically understood to have a working memory capacity of about four chunks, each of which can consist of a compressed, complex concept \cite{cowan2001}."
- working memory updating paradigms: Experimental tasks that require maintaining bindings while replacing outdated information with new inputs. "working memory updating paradigms, which require maintaining and dynamically updating arbitrary bindings while discarding outdated information"
Collections
Sign up for free to add this paper to one or more collections.

