- The paper presents a framework that models episodic memories with structured temporal, spatial, and event details to evaluate recall and reasoning in LLMs.
- It employs synthetic narrative data via skewed event sampling to generate uncontaminated episodic benchmarks for robust testing of memory functions.
- Results reveal that even advanced LLMs like GPT-4 struggle with complex temporal-spatial tasks, indicating the need for tailored training methods.
Episodic Memories Generation and Evaluation Benchmark for LLMs
Introduction
The paper "Episodic Memories Generation and Evaluation Benchmark for LLMs" (2501.13121) tackles a significant challenge in enhancing LLMs by integrating episodic memory capabilities. Unlike semantic memory, which involves general world knowledge, episodic memory relates to recalling specific events in time and space, a crucial cognitive function in humans. Current LLMs, despite their advanced capabilities, lack robust episodic memory, leading to issues like hallucinations and limited recall capabilities beyond a certain context length. This paper introduces a framework to evaluate and model episodic memories in LLMs, aiming to bridge the gap towards human-like cognition by developing benchmarks that assess episodic memory functions such as recall and reasoning tasks with defined spatial-temporal contexts and entities.
Framework for Episodic Memory Benchmarking
The authors propose a framework inspired by human cognitive processes, where episodic memories are characterized by sets of events described by temporal, spatial, and content-related contexts including entities involved. To facilitate a structured assessment, they introduce an uncontaminated episodic memory benchmark along with datasets and open-source code for evaluating various LLMs, including popular models like GPT-4 and Claude variants. The model and evaluate processes pivot on synthetic data generation — narratives anchored to specific times and locations composed of episodic events to evaluate reasoning and recall performance in models.

Figure 1: Book generation: skewed event sampling ensures varied event frequency, critical for testing episodic memory.
Generation of Episodic Memories
The approach models episodic memories as events within a narrative, structured to represent the temporal and spatial context, involved entities, and event details. The benchmark synthesizes a diverse set of episodic data free from training contamination, allowing for precise control over generated narratives and ground truth answers. Critical to this methodology is skewed event sampling, promoting variance in event frequency essential for evaluating memory recall (Figure 1). This underpins the benchmark’s robustness, allowing models to be tested across a spectrum of memory-related tasks with increasing complexity.
Evaluation of LLMs
Using the generated benchmark, the paper evaluates various state-of-the-art LLMs, illustrating that even advanced models like GPT-4 struggle with episodic tasks, especially with multiple related events or complex temporal-spatial scenarios. The evaluation employs multiple strategies, including in-context learning with in-context memory, retrieval-augmented generation, and fine-tuning. Results indicate significant performance degradation when models face overloaded cues, highlighting deficits in current architectures and training paradigms.
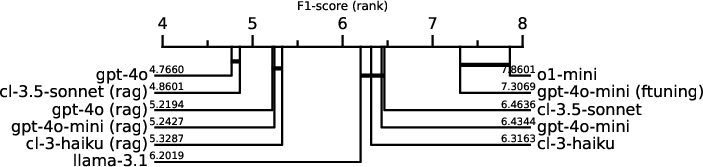
Figure 2: Overall performance comparison: Critical distance plot ranking all LLM models and memory combinations (instances not tied by a horizontal bar are statistically different).
Significance and Future Work
The introduction of this benchmark marks a critical step toward improving LLMs' episodic memory capabilities, with implications for enhancing reasoning and factual accuracy in AI applications. The authors emphasize the inadequacy of current fine-tuning methodologies for embedding episodic knowledge into models, pointing to the need for novel training methodologies tailored to episodic memory integration. This research opens pathways for developing AI systems capable of human-like episodic reasoning, benefiting applications ranging from narrative generation to decision-making systems.
Conclusion
The research provides a comprehensive framework for evaluating and modeling episodic memory in LLMs, highlighting deficiencies in current models and suggesting pathways for advancement. The benchmark developed serves as a foundational tool for future investigations into enhancing AI with robust episodic memory capabilities, a critical step towards achieving more nuanced and context-aware AI systems.
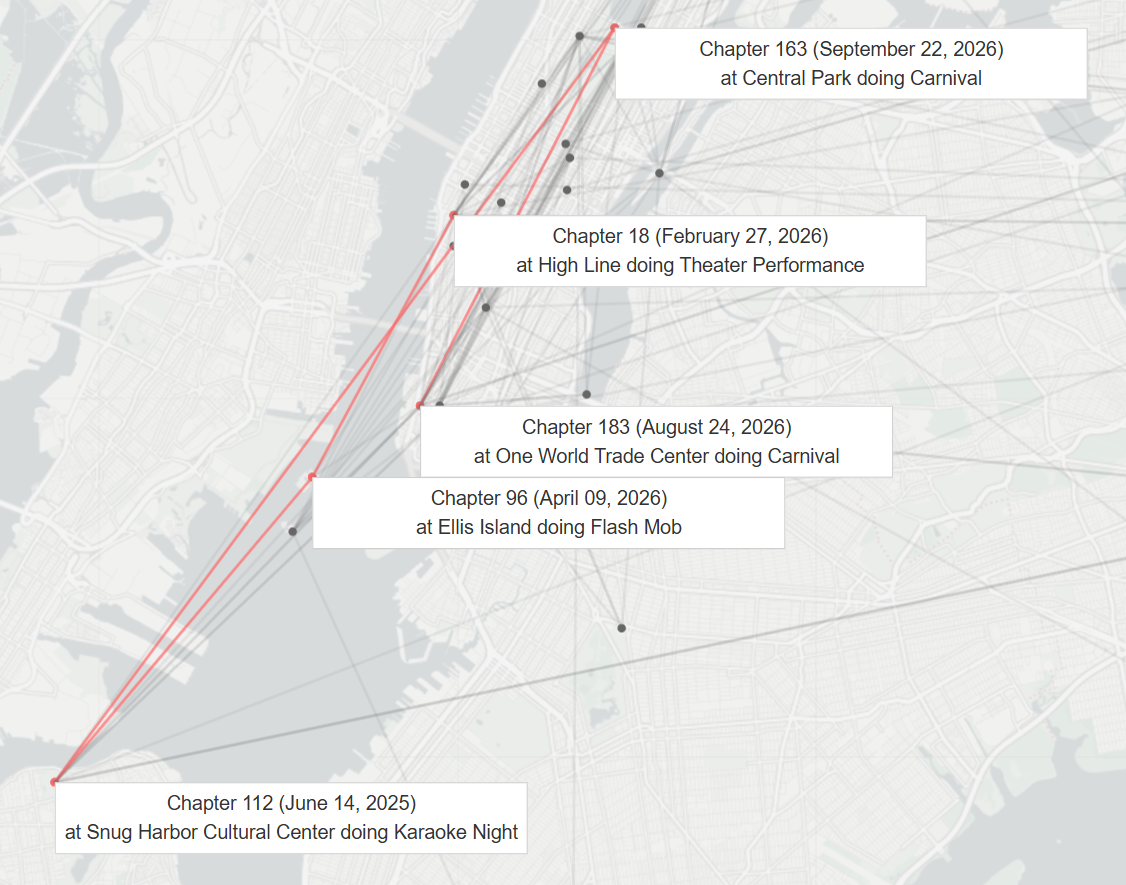
Figure 3: Tracking of a single entity (specifically, Jackson Ramos) throughout the long book.
In conclusion, this research lays critical groundwork for understanding and improving how LLMs can handle and utilize episodic memory, moving toward more sophisticated and human-like cognitive abilities in AI systems.

