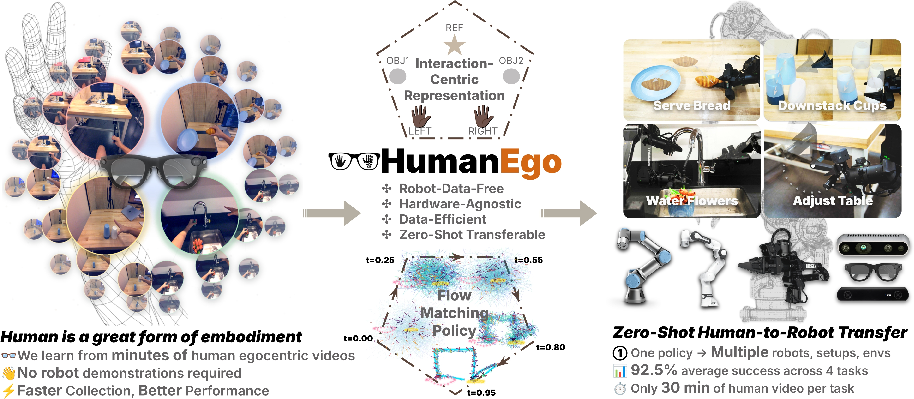
HumanEgo: Zero-Shot Robot Learning from Minutes of Human Egocentric Videos
Abstract: Human egocentric video captures rich manipulation demonstrations without any robot hardware, yet transferring these skills to robots remains challenging due to the embodiment gap between human and robot in both visual appearance and kinematics. We present HumanEgo, a framework that bridges the embodiment gap by lifting each human demonstration to an entity-level representation of hand-object interaction, and training a flow matching policy with dense auxiliary objectives that amplify supervision from every trajectory. HumanEgo is robot-data-free, hardware-agnostic, data-efficient, and zero-shot human-to-robot transferable. With only 30 minutes of human videos per task, HumanEgo achieves 92.5% average success across four real-world tasks (75% with just 15 minutes), outperforms matched-time robot teleoperation by 41%, and robustly transfers zero-shot across novel robots, cameras, and environments.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “HumanEgo: Zero‑Shot Robot Learning from Minutes of Human Egocentric Videos”
Overview: What is this paper about?
This paper shows a new way for robots to learn how to do tasks by simply watching short, first‑person videos of a human doing them. The videos are recorded with smart glasses. The big idea is that a robot can copy useful skills without collecting any robot‑specific training data, and without huge internet‑scale training. The authors call their approach HumanEgo.
Goals: What questions are the researchers asking?
The paper focuses on four simple questions:
- Can a robot learn directly from minutes of human first‑person videos, with no robot training data?
- How can we overcome the “embodiment gap” (the differences between human hands and robot grippers, and how they move)?
- How can we learn well from very little data?
- Will the learned skills work on different robots, cameras, and in different places without retraining?
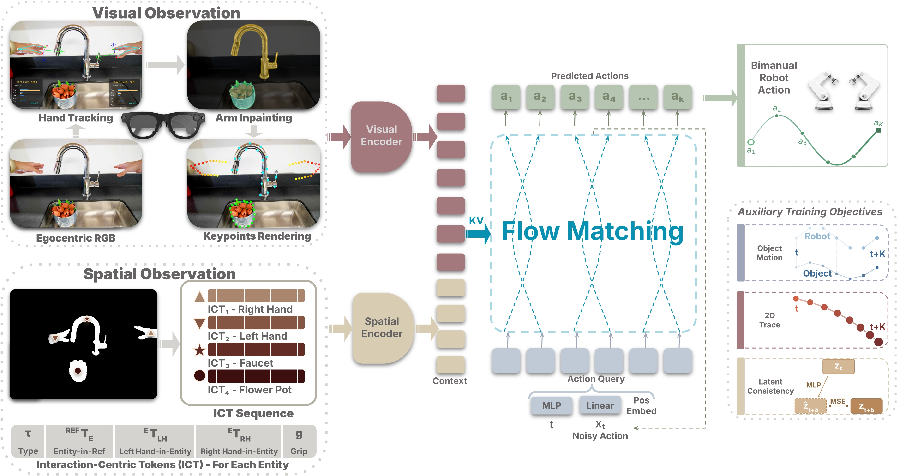
Methods: How does HumanEgo work (in everyday terms)?
The method has four parts. Here’s the idea in friendly language:
- Record simple how‑to videos A person wears smart glasses (with cameras) and records themselves doing a task, like placing bread on a plate or unstacking cups. This gives close‑up, first‑person video that’s quick and easy to collect.
- Clean up the visuals so robots aren’t confused
- The system digitally “erases” the human arm from each video frame (this is called inpainting—think of it like Photoshop cleanup).
- It then draws a simple virtual robot gripper in the image, along with key points on the object. Why? So the robot doesn’t get distracted by seeing a human hand shape; it sees a simple “robot‑like” view instead.
- Describe the scene with “interaction‑centric tokens”
- The system tracks where each hand and object is in 3D and how each one is oriented (this is “6‑DoF”: where it is + which way it’s facing).
- It turns this into compact “Interaction‑Centric Tokens” (ICTs)—like small info cards for each thing in the scene.
- Each token says: what the thing is (hand or object), where it is, and how the hands are positioned relative to that object.
- Everything is described relative to each other rather than to the camera. Why is this smart?
- It focuses on the relationship between hand and object—the heart of manipulation (approach, grasp, move, release).
- Because it’s relative, it works even if the camera angle, lighting, or robot body changes.
- Teach the robot to act using a fast generative model
- The robot learns a policy (a rule for what to do next) that outputs a short sequence of “actions” for both arms: where to move and whether to open/close the gripper.
- The learning uses “flow matching,” which you can think of as a fast way to turn a rough guess into the right action plan. It’s like mapping foggy ideas into a clear path efficiently.
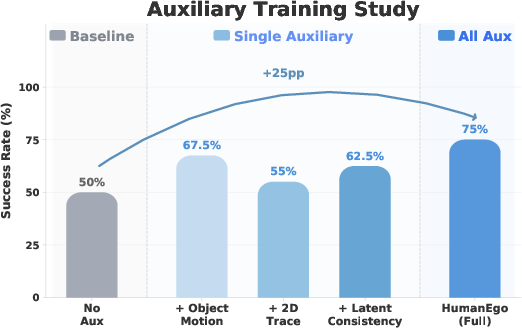
- To learn more from each short video, the system adds three extra “homework tasks” during training (called auxiliary objectives):
- Predict the object’s future 3D motion (so it understands how objects move when pushed/grasped)
- Predict 2D future traces on the image (so it stays grounded in what it sees)
- Predict future ICT states (so it learns how interactions evolve over time)
- These extra tasks make the model learn richer cause‑and‑effect from every video, which is very helpful when data is limited.
Findings: What did they observe, and why does it matter?
Note: The paper flags that some figures and data points are still being finalized. The summary below reflects the authors’ reported results and may be updated.
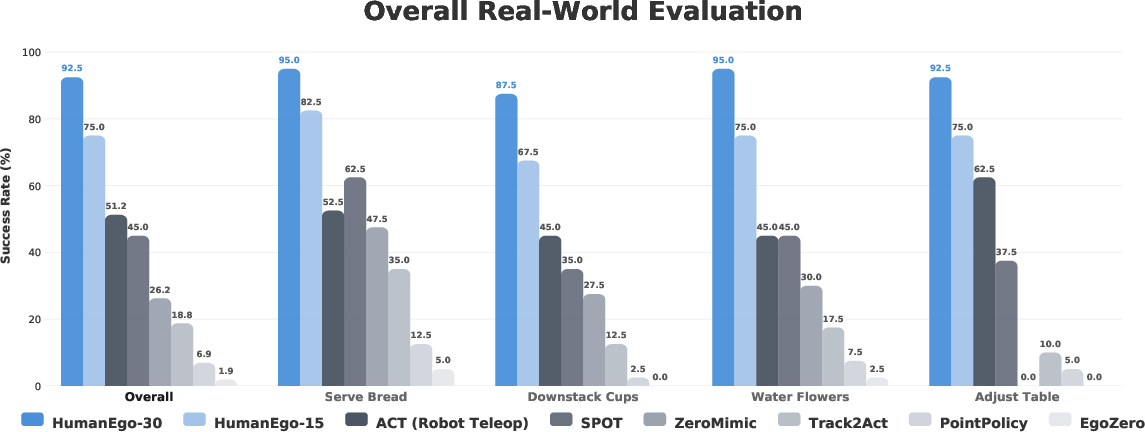
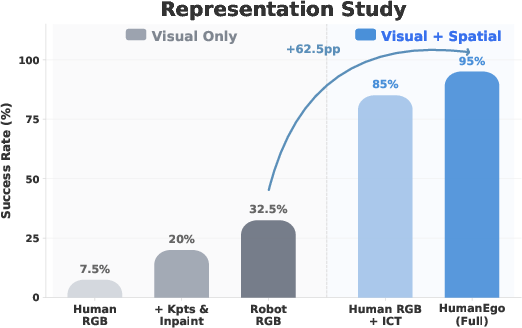
- With only about 30 minutes of human video per task, the method reportedly reached around 92.5% average success across four real‑world tasks (like placing bread on a plate, unstacking cups, watering a plant with two hands, and turning a table crank). With 15 minutes, it reportedly reached about 75%.
- It reportedly beat a common robot training baseline that used the same amount of collection time with robot teleoperation (by about 41%). In other words, minutes of human video can be more useful than minutes of robot joystick demonstrations.
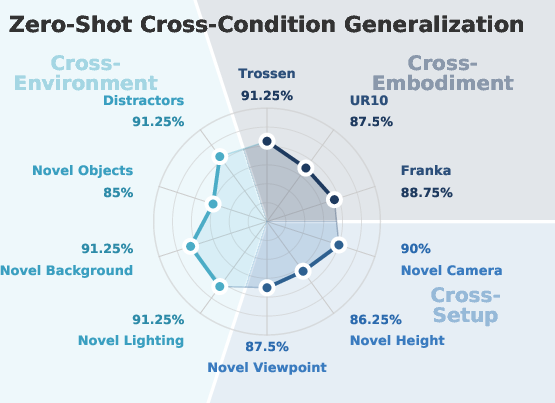
- It reportedly worked “zero‑shot” on different robots, cameras, rooms, lighting, and even with new object instances, without any extra training.
- Key reasons for the gains:
- The interaction‑centric tokens give the robot the “right” kind of information—how hands and objects relate—rather than just raw pixels.
- “Flow matching” produces quick, multi‑choice plans for the robot to act, which helps when tasks can be done in different valid ways.
- The extra training tasks force the model to really understand how the scene changes, not just memorize motions.
Why is this important? If these results hold, it means:
- Robots can learn faster and cheaper—no need for lots of robot‑specific data.
- Learning can happen in everyday places with simple human recordings.
- The learned skills can move across different robots and setups more easily.
Implications: What could this lead to, and what are the limits?
If methods like HumanEgo keep improving:
- Anyone could teach a home or school robot by wearing smart glasses and showing tasks for a few minutes.
- Companies could prototype robot skills without expensive robot data collection.
- Robots might adapt better to new homes or workplaces because the learned representation focuses on interactions, not camera angles or hand shapes.
Current limitations the authors note:
- The system depends on good hand and object tracking; when tracking is weaker (e.g., with a single camera), performance drops.
- Some parts of the perception pipeline can fail and cause errors to cascade.
- Precision seems to plateau around ~1 cm; for very fine control, extra learning methods (like reinforcement learning) may be needed.
- Some reported experiments are still being finalized, so results may change.
Overall, the core message is simple and exciting: show a robot what to do from your point of view, and it can learn good, transferable skills surprisingly fast—by focusing on how hands and objects interact rather than on surface appearance.
Knowledge Gaps
Below is a concise, actionable list of the paper’s unresolved knowledge gaps, limitations, and open questions to guide future work.
- Experimental results are not finalized: several key figures (overall evaluation, auxiliary objectives study, generalization) are marked as placeholders; final numbers, variance, and statistical significance are missing.
- Dependence on Aria’s stereo hand tracking for training: how well does the approach work with commodity monocular cameras, smartphones, or weaker hand pose estimators, and what robustness methods can compensate for noisier inputs?
- Sensitivity of the pipeline to perception errors: the method chains Grounding DINO, SAM2, CoTracker, SLAM, and Orient-Anything; failure cascades and their impact on policy quality are not quantified or mitigated.
- Object pose estimation under heavy occlusion and dynamics: reliance on per-frame detection plus triangulation and “kinematic latching” leaves open how to track objects robustly during in-hand manipulation, fast motions, or cluttered scenes.
- Kinematic latching heuristic: how to handle slip, non-rigid contacts, partial grasps, or multi-contact events where rigid hand–object coupling is invalid?
- Scalability of Interaction-Centric Tokens (ICT) to many entities: inference and training complexity as the number of objects and distractors grows, and strategies for entity selection, tracking, and pruning are untested.
- ICT robustness to entity misclassification: impact of detection errors, ambiguous categories, small or reflective objects, and how to correct tokens when entity type or pose is wrong.
- Generalization beyond rigid objects: orientation estimation and tokenization are tailored to rigid bodies; deformable or articulated objects and tool-use affordances remain unaddressed.
- Action space limitations: policies output 6-DoF poses with binary grasps only; force/impedance control, torque limits, and tactile feedback for contact-rich manipulation are not modeled.
- Precision plateau (~1 cm): methods to push to sub-centimeter accuracy (e.g., RL fine-tuning, trajectory optimization, model-predictive control, closed-loop refinement) are not explored.
- Role of RGB channel vs. tokens: the necessity and marginal utility of arm inpainting and gripper/keypoint rendering at training and inference time are not fully disentangled from token-only policies.
- Visual preprocessing artifacts and compute: effect of inpainting/rendering artifacts on learning and the computational burden for large-scale training are unmeasured.
- Multi-demonstrator and cross-collector robustness: all human data appears to come from a single (or few) person(s); performance under different demonstrators, handedness, hand sizes, camera placements, and collection devices is unevaluated.
- Category-level generalization: the paper shows transfer to novel instances but not to unseen object categories or broader task families with different affordances.
- Long-horizon and branching tasks: scalability to complex, multi-stage tasks with optional branches, subgoal failures, and re-planning is not demonstrated.
- Flow matching design choices: numerical stability of Euler integration, step size, and comparisons to rectified flows, higher-order ODE solvers, or diffusion at similar compute are missing.
- Hyperparameter sensitivity: no analysis of sensitivity to weights in the flow loss (wp, wr, wg), the auxiliary losses (λOM, λ2D, λLC), or horizon length K.
- Real-time performance: inference latency, control frequency, and hardware requirements on the robot are not reported; feasibility on low-cost CPUs/edge devices is unknown.
- Calibration and frame robustness: the method assumes accurate intrinsics/extrinsics/SLAM; robustness to calibration errors, SLAM drift, and camera movement is not assessed.
- Safety and failure recovery: there is no analysis of failure modes, safe recovery strategies, or online detection of misgrasp/near-collision to trigger re-planning.
- Baseline parity and reproducibility: details on training budgets, hyperparameter tuning, and adaptation of competing methods to the tasks are limited; a standardized protocol would clarify fairness.
- Dataset and code availability: it is unclear whether the egocentric videos, annotations (if any), and code will be released to enable replication and benchmarking.
- Training from in-the-wild monocular videos: automatic segmentation of usable clips, action labeling, and robustness to motion blur/low light are open for broader applicability.
- Dexterous and non-parallel-jaw effectors: the thumb–index mapping suits parallel-jaw grippers; extending to multi-fingered hands and diverse grasp taxonomies remains open.
- Continual and multi-task learning: scaling the shared encoder across many tasks, preventing catastrophic forgetting, and leveraging cross-task transfer are unexplored.
- Dynamic, moving environments: tracking and planning with moving objects/people and non-static backgrounds in real-time is not addressed.
- Language- or goal-conditioned behaviors: integrating textual task specification (e.g., LLMs) for new tasks beyond those demonstrated is not explored.
- End-to-end perception–policy training: replacing the chained, fixed perception stack with jointly trained or differentiable modules to reduce error cascades is untested.
- Theoretical grounding of ICT: formal analysis of the invariances and sufficiency of ICT (e.g., under viewpoint/embodiment changes) and comparisons to alternative relational encodings are absent.
Practical Applications
Immediate Applications
The following opportunities can be piloted now by leveraging the paper’s core contributions—interaction-centric tokens (ICT), hardware-agnostic visual preprocessing (arm inpainting + virtual gripper rendering), and a flow-matching policy with dense auxiliary objectives—within the constraints and limitations described.
- Rapid, robot-data-free skill onboarding for industrial and SME manipulators
- Sector: manufacturing, logistics, retail, food service
- Use case: Teach pick-and-place, de-nesting/unstacking, shelf restocking, basic assembly steps, valve/knob turning, and fixture adjustments from a few minutes of onsite human demonstrations.
- Workflow/product: Operator wears smart glasses (e.g., Aria) to record 15–30 minutes of task demonstrations; backend runs HumanEgo pipeline to produce a deployable policy; robot executes zero-shot across heterogeneous arms and cameras.
- Assumptions/dependencies: Accurate egocentric SLAM and 3D hand pose (Aria MPS or equivalent), objects detectable/trackable with off-the-shelf vision (GroundingDINO, SAM2, CoTracker), tasks within ~1 cm precision and moderate dynamics; safety interlocks for deployment; some experimental results in the paper are marked “in progress,” so field performance may vary.
- Teleoperation-free data collection to reduce robot teaching cost
- Sector: robotics (vendors, integrators), academia
- Use case: Replace time-consuming teleoperation demos with minutes of human egocentric video for each new task.
- Tools/workflow: HumanEgo as a data engine integrated with ROS/MoveIt; batch training in the cloud; policy artifacts versioned per task.
- Assumptions/dependencies: Stable perception stack; compute for training; controlled task spaces.
- Cross-robot, cross-camera skill deployment in heterogeneous fleets
- Sector: robotics platforms and system integrators
- Use case: Train once from human video and deploy on Trossen/Franka/UR-class arms with RealSense/ZED cameras without retraining.
- Tools/workflow: Fleet skill library; ICT-based observation interface for different robots; per-robot kinematics adapters.
- Assumptions/dependencies: Kinematic retargeting of end-effector trajectories; robot reachability; consistent safety envelopes.
- Facilities and building operations: routine manipulation tasks
- Sector: facilities management, utilities, hospitality
- Use case: Adjusting cranks/knobs, opening/closing valves, watering plants, simple cleaning actions that mirror “Adjust Table” and “Water Flowers.”
- Tools/workflow: Onsite staff demonstrate; scheduled autonomous execution by service robots.
- Assumptions/dependencies: Repeatable object geometry and access; environmental robustness to lighting and background (supported by paper), but still requires reliable detection/pose estimation.
- Warehouse and e-commerce operations
- Sector: warehousing, retail fulfillment
- Use case: Picking irregular items (e.g., bread-to-plate analog), de-nesting cups/containers, bin-to-bin transfers.
- Tools/workflow: Shift supervisor records exemplars on the floor; deploy to multiple workcells.
- Assumptions/dependencies: Object visibility and segmentation quality; allowable tolerance for placement; minimal in-hand regrasping.
- Rapid prototyping and teaching in robotics courses and labs
- Sector: education, research labs
- Use case: Students and researchers quickly prototype manipulation skills without robot teleop rigs or large robot datasets.
- Tools/workflow: Course kits bundling Aria-compatible capture, ICT extraction, flow-matching training scripts, and ROS demos.
- Assumptions/dependencies: Access to smart glasses or stereo headsets; GPU for training.
- Embodiment-agnostic video preprocessing as a plug-in for other pipelines
- Sector: software tools for robotics perception
- Use case: Improve cross-domain training data by arm inpainting and virtual gripper rendering; serve as a front-end to existing visual policy learners.
- Tools/workflow: A preprocessing SDK wrapping SAM2 + LaMa and gripper overlay; dataset conversion service.
- Assumptions/dependencies: Requires calibrated camera poses and 3D hand/object estimates; success sensitive to segmentation quality.
- Interaction-centric analytics of human procedures
- Sector: operations excellence, ergonomics, training
- Use case: Extract ICT to analyze how skilled operators approach/grasp/transport objects; generate process documentation or training content.
- Tools/workflow: Batch extraction of ICT from egocentric logs; dashboards for spatial relationship trajectories.
- Assumptions/dependencies: Privacy and consent compliance for egocentric recording; accurate hand/object pose estimation.
- Benchmark and dataset creation from egocentric demos
- Sector: academia, open-source communities
- Use case: Curate small, high-SNR per-task datasets with dense auxiliary labels (2D traces, object motion, ICT predictions) for reproducible evaluation of manipulation methods.
- Tools/workflow: Public release of preprocessed tokens and auxiliary targets; leaderboards focused on zero-shot transfer.
- Assumptions/dependencies: Rights to share egocentric data; standardized capture protocols.
- Policy distillation bootstrap for generalist models
- Sector: software/AI for robotics
- Use case: Use HumanEgo-trained policies as small, high-quality seeds for larger generalist policy training or fine-tuning, reducing teleop reliance.
- Tools/workflow: Aggregate multiple task policies and demonstrations; distill into multi-task models.
- Assumptions/dependencies: Consistent token interfaces across tasks; careful balancing to retain zero-shot robustness.
Long-Term Applications
These opportunities require further research, scaling, or systems integration beyond the current evidence, and/or rely on overcoming stated limitations (e.g., monocular hand tracking, real-time object tracking, precision beyond ~1 cm).
- Consumer home robots taught by owners via everyday headsets or phones
- Sector: consumer robotics, smart home
- Use case: Users demonstrate daily tasks (load dishwasher, tidy objects, water plants) with AR glasses or phones; robot learns and repeats.
- Dependencies: Reliable monocular 3D hand pose and SLAM (stronger than current); safety certification for home use; robust on-device or private-cloud training.
- High-precision assembly and in-hand manipulation
- Sector: advanced manufacturing, electronics
- Use case: Tasks exceeding ~1 cm precision or requiring dexterous regrasping and tight tolerances.
- Dependencies: Integrate RL/fine-tuning, tactile feedback, and real-time object/hand tracking; higher-fidelity perception to surpass current precision plateau.
- Real-time, on-site skill acquisition in minutes
- Sector: field service, construction, disaster response
- Use case: Live streaming from AR glasses to robot for just-in-time training and execution in novel environments.
- Dependencies: Low-latency perception and training on edge devices; robust real-time trackers; connectivity and safety governance.
- Federated and privacy-preserving learning from egocentric data
- Sector: healthcare, enterprise, government
- Use case: Sites keep data local while sharing model updates; skills improve across organizations without sharing raw video.
- Dependencies: On-device training, secure aggregation, differential privacy; clear data governance frameworks.
- Skill marketplaces and cross-fleet distribution
- Sector: robotics platforms, systems integrators
- Use case: Publish/buy robot skills distilled from human videos; deploy across fleets with minimal integration.
- Dependencies: Standardization of ICT formats and interfaces; licensing and liability models; automated validation/simulation sandboxes.
- Hospital logistics and assistive care
- Sector: healthcare
- Use case: Restocking, preparing kits, opening dispensers, simple patient-assist tasks (non-critical).
- Dependencies: Sterile, compliant data capture; rigorous safety certification; robust perception under clinical variability.
- Agriculture and horticulture beyond watering
- Sector: agriculture
- Use case: Pruning, gentle harvesting, trellising, packaging learned from farm workers’ demonstrations.
- Dependencies: Outdoor SLAM robustness, occlusion handling, diverse crop geometry; weather resilience.
- Energy and process industries (plants, refineries)
- Sector: energy, utilities
- Use case: Valve operations, gauge reading with light manipulation, tool usage in constrained spaces.
- Dependencies: Intrinsically safe hardware, ruggedized perception; operator acceptance and safety oversight; precise actuation and verification.
- Integration with language-conditioned VLA models
- Sector: software/AI for robotics
- Use case: Combine human video demos with language goals to generalize across task variants (e.g., “put the croissant on any plate”).
- Dependencies: Multi-modal training at scale; consistent grounding between ICT and language tokens; compute budgets.
- Standardized demonstration and evaluation protocols
- Sector: standards bodies, consortia
- Use case: Common formats and benchmarks for human-to-robot transfer using egocentric video and ICT, enabling cross-lab comparability.
- Dependencies: Community consensus; dataset curation and maintenance; open tooling.
- Workforce training, ergonomics, and compliance analytics
- Sector: enterprise operations, policy
- Use case: Use interaction-centric traces to identify awkward motions, codify best practices, and inform safety training.
- Dependencies: Privacy/consent frameworks; anonymization; alignment with labor regulations.
- Regulatory and liability frameworks for human-video-taught robots
- Sector: public policy, legal
- Use case: Define consent, data retention, and responsibility when robot behavior is derived from human egocentric recordings.
- Dependencies: Multi-stakeholder processes; incident reporting standards; alignment with data protection laws.
- Multi-robot coordination learned from multi-human demonstrations
- Sector: logistics, manufacturing
- Use case: Learn coordinated tasks (e.g., team lifts, synchronized assembly) from bimanual/multi-actor videos.
- Dependencies: Extensions of ICT to multi-agent settings; timing/synchronization modeling; safety interlocks for coordinated motion.
- Robust monocular alternatives to Aria MPS
- Sector: perception vendors, open-source vision
- Use case: Commodity phones/AR glasses replace stereo/marker-based systems while retaining reliable 6-DoF hand/object estimation.
- Dependencies: Advances in monocular hand pose, depth, and SLAM; temporal consistency; domain robustness.
Notes on Feasibility and Dependencies Across Applications
- Core technical dependencies:
- Accurate egocentric SLAM and 3D hand pose (paper relies on Aria MPS; monocular substitutes currently reduce performance).
- Reliable object detection/segmentation/tracking (GroundingDINO, SAM2, CoTracker) and orientation estimation.
- Compute for training flow-matching policies; ROS-compatible deployment.
- Safety measures for zero-shot execution (workspace limits, force thresholds).
- Method limitations to consider:
- Precision plateaus at ~1 cm without additional fine-tuning or tactile/RL augmentation.
- Real-time tracking of occluded/dynamic objects is not yet integrated; per-frame detection can fail in fast motions.
- Pipeline chains multiple perception modules—failures can cascade; robustness engineering is required.
- Some reported experiments are noted as “in progress,” so performance ranges may evolve.
Collectively, HumanEgo’s data efficiency and hardware-agnostic transfer enable immediate cost-saving workflows in robot skill creation and deployment, while its interaction-centric representation points to longer-term pathways for personalized, privacy-preserving, and highly generalizable robot learning ecosystems.
Glossary
- 2D trace: An auxiliary learning target that predicts future 2D projections of entity trajectories in the image. "we design three dense auxiliary objectives: 2D trace, object motion, and latent consistency."
- 6-DoF: Six degrees of freedom describing a rigid body's 3D position and orientation. "recover each entity's 6-DoF pose, then encode their relative relations into Interaction-Centric Tokens."
- 6D rotation representation: A continuous rotation parameterization using six numbers to avoid discontinuities of Euler angles or quaternions during learning. "We flatten each SE(3) transform to a 9D vector by concatenating the normalized translation with a 6D rotation representation"
- Auxiliary objectives: Additional training losses used to provide extra supervision and improve data efficiency. "a flow matching policy with dense auxiliary objectives learns bimanual robot actions from minutes-scale human data."
- Bimanual: Involving two hands or two robotic arms acting together. "a flow matching policy with dense auxiliary objectives learns bimanual robot actions from minutes-scale human data."
- Co-training methods: Approaches that jointly train on human and robot datasets to improve imitation learning. "Co-training methods~\citep{kareer2024egomimic,punamiya2025egobridge} supplement robot data with human video"
- Diffusion-based methods: Generative models that iteratively denoise samples to model complex distributions. "Diffusion-based methods~\citep{chi2023diffusionpolicy} capture this distribution but need many denoising steps"
- Egocentric video: Video captured from a first-person, head-mounted perspective. "Human egocentric video offers a much cheaper and more accessible alternative"
- Embodiment gap: The mismatch between human and robot in appearance and kinematics that hinders direct skill transfer. "transferring these skills to robots remains challenging due to the embodiment gap between human and robot in both visual appearance and kinematics."
- Euler solver: A simple numerical method for integrating ordinary differential equations. "At inference, we integrate the learned ODE with a fixed-step Euler solver."
- Exponential moving average (EMA): A smoothing technique that exponentially decays past observations. "and an exponential moving average (EMA) on rotations."
- Flow matching: A generative modeling approach that learns a velocity field to transport a simple prior to target data. "training a flow matching policy with dense auxiliary objectives that amplify supervision from every trajectory."
- Gaussian prior: A normal distribution used as the starting distribution for generative sampling. " is a Gaussian prior sample;"
- Gram–Schmidt frame: An orthonormal basis constructed via the Gram–Schmidt process, here used to define hand orientation. "we build a Gram--Schmidt frame on the metacarpophalangeal (MCP) joints"
- Grounding DINO: A text-conditioned, open-set object detector used to localize task-relevant objects. "We detect each object with text-prompted Grounding DINO"
- Interaction-Centric Tokens (ICT): Compact tokens encoding each entity’s pose and its relative spatial relationship to both hands. "Interaction-Centric Tokens~(ICT), a compact entity-level representation of hand--object interaction invariant to embodiment, viewpoint, and environment."
- Kinematic latching: Temporarily constraining an object’s pose to the hand’s pose during grasp-induced occlusion. "we apply kinematic latching—rigidly tying the object pose to the hand from the grasp onset"
- LaMa inpainting: A deep learning method for removing regions from images and plausibly filling them in. "and remove them via LaMa inpainting~\citep{suvorov2022lama}, eliminating the visual embodiment gap."
- Latent consistency: An auxiliary objective that predicts future latent state (ICT) to enforce temporal coherence. "(3)~Latent consistency ($\mathcal{L}_{\text{LC}$): we predict the ICT state steps ahead"
- Machine Perception Services (MPS): On-device services from Aria glasses providing calibrated tracking and hand pose. "their Machine Perception Services (MPS) provide high-quality 6-DoF SLAM tracking, calibrated 3D hand pose estimation, and synchronized egocentric RGB streams"
- Object-centric approaches: Methods focusing primarily on objects rather than full hand–object interaction. "object-centric approaches~\citep{xu2024im2flow2act,jain2024vid2robot} track only the manipulated object, losing critical information about how the hand approaches, grasps, and releases it."
- Orient-Anything V2: A model used to estimate an object’s 3D orientation from visual input. "and estimate orientation $R_{\text{obj}$ with Orient-Anything V2~\citep{wu2025orientanything}."
- SAM2: A segmentation model for images and videos used to obtain object and hand masks. "we segment the human hand and arm with SAM2"
- Savitzky–Golay: A polynomial smoothing filter for time series denoising. "and smooth them with Savitzky--Golay on positions"
- SE(3): The Lie group of 3D rigid transformations (rotation and translation). "extracting an end-effector pose $T_{\text{ee}$ and a scalar grasp ."
- SLAM: Simultaneous Localization and Mapping; estimating camera pose and building a map from sensor data. "their Machine Perception Services (MPS) provide high-quality 6-DoF SLAM tracking"
- Structure-from-motion: A method to reconstruct 3D structure and camera motion from 2D videos. "ZeroMimic~\citep{he2024zeromimic} distills 3D wrist trajectories from web videos via structure-from-motion"
- Teleoperation: Controlling a robot remotely by a human operator to collect demonstrations. "outperforms matched-time robot teleoperation by 41%"
- Transformer decoder: The autoregressive component of a transformer used here to parameterize the flow’s velocity field. "we parameterize a velocity field with a transformer decoder conditioned on "
- Triangulate: Recovering 3D points from multi-view 2D keypoint correspondences and camera poses. "$\mathbf{p}_n = \mathrm{Triangulate}(\mathbf{u}_n,\, K,\, T_{\text{SLAM})$"
- Velocity field: A vector field indicating the instantaneous direction and rate of change used in flow matching. "we parameterize a velocity field with a transformer decoder"
- Zero-shot: Deploying a model to new conditions or embodiments without any additional training. "robot-data-free, hardware-agnostic, data-efficient, and zero-shot human-to-robot transferable."
Collections
Sign up for free to add this paper to one or more collections.