- The paper introduces a dual-stage pipeline achieving cross-embodiment alignment via implicit 2D feature distillation and explicit 3D geometry canonicalization.
- It reduces required robot demonstration data by up to 80% while maintaining high manipulation success across diverse tasks.
- Methodology ablation confirms the necessity of staged feature and geometric alignment for robust, out-of-distribution performance.
LIDEA: Implicit Feature Distillation and Explicit Geometry Alignment for Human-to-Robot Imitation
Problem Statement and Motivation
Robust, generalizable visuomotor policies for robot manipulation are fundamentally constrained by the substantial cost and limited diversity of obtaining robot demonstration data. Conversely, human demonstration videos are abundant and diverse, but leveraging this data for direct policy transfer remains a challenge due to the "embodiment gap": discrepancies in appearance, 3D geometry, and semantics between humans and robots. Previous visual editing techniques or unified representation approaches fall short due to artifacts, kinematic incongruities, or reliance on fragile state estimation. LIDEA introduces a rigorous framework that enables human-to-robot imitation learning by integrating both implicit 2D feature distillation and explicit 3D geometric alignment, systematically bridging this gap.
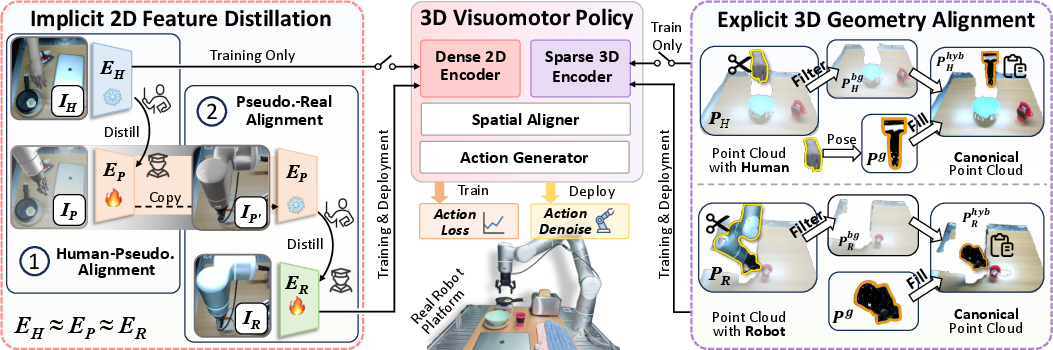
LIDEA Framework Overview
LIDEA decomposes the cross-embodiment gap into two complementary domains: 2D visual representation and 3D geometric observation. The framework consists of:
Implicit 2D Feature Distillation
A two-stage transitive distillation pipeline aligns features for cross-embodiment equivalence:
- Human to Pseudo-Robot: Using HPP-5M, a dataset of ∼5M paired frames where human hands are replaced with robot proxies, the representation space is aligned with DINOv3-based visual encoders using specialized Region-of-Interaction cropping to emphasize manipulation over background context.
- Pseudo-Robot to Real-Robot: A smaller paired dataset aligns photometric variations between rendered and real robot imagery, completing the bridge. The resultant latent space is numerically aligned across all domains (EH≈EP≈ER).
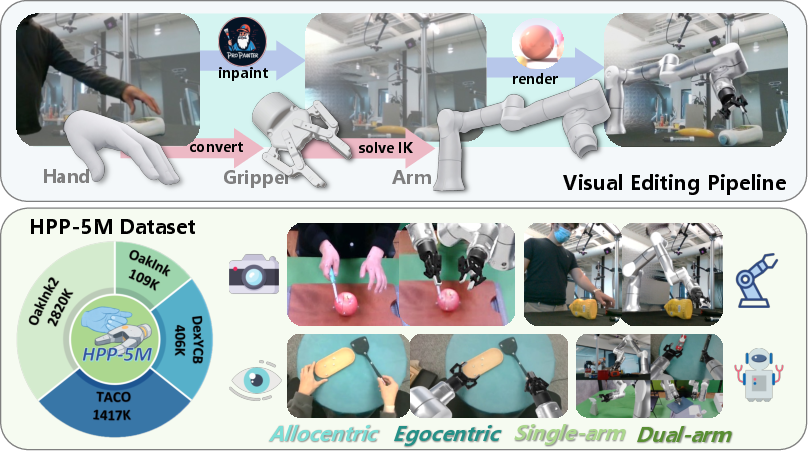
Figure 2: HPP-5M dataset enables large-scale human-pseudo-robot alignment, supporting robust feature distillation across semantic interaction equivalence.
Explicit 3D Geometric Alignment
LIDEA enforces a strictly embodiment-agnostic geometric representation:
- All agent-specific point cloud data are filtered—via visual segmentation for humans and proprioceptive-based occupancy for robots.
- A canonical gripper geometry is inserted, parameterized by pose and opening state, ensuring spatial and structural symmetry across observations.
This canonicalization is critical for depth-aware policy learning, particularly when object-centric interactions or precise spatial reasoning is required.
Experimental Evaluation
Manipulation Tasks
Evaluations span four real-world manipulation tasks of increasing complexity and heterogeneity:
- Close Laptop (articulated-object)
- Stack (6 DoF pick-and-place)
- Fold Towel (deformable-object)
- Prepare Bread (long-horizon, multi-stage)
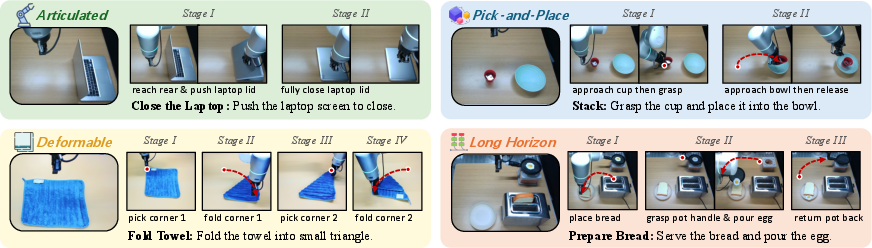
Figure 3: Benchmark tasks encompass articulated, rigid, deformable, and long-horizon manipulation challenges.
Data Efficiency and Comparative Results
LIDEA achieves substantial reductions in robot demonstration requirements, substituting up to 80% of robot data with human demonstration videos while matching or surpassing baseline policy performance. Policies trained with human data and minimal robot supervision retained high manipulation success rates across all tasks.
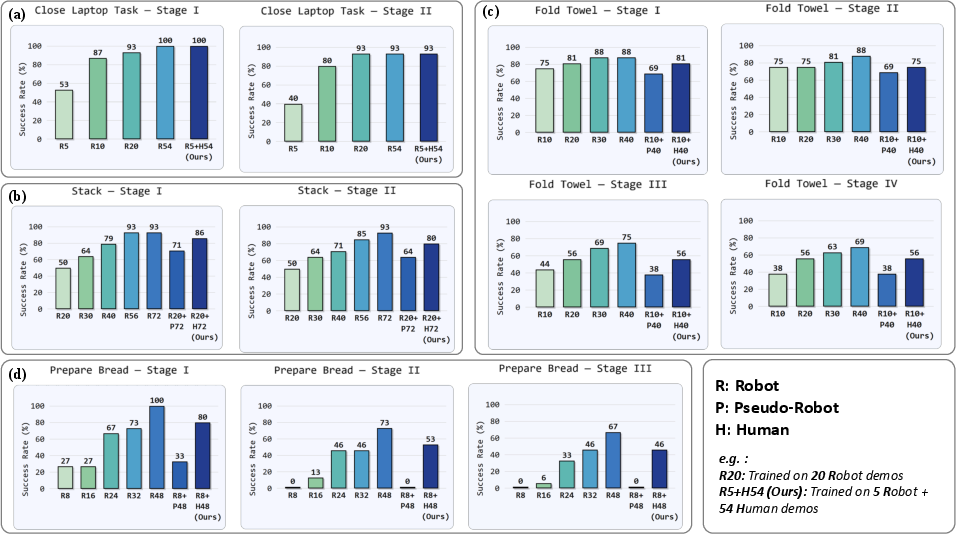
Figure 4: Data efficiency evaluation reveals that mixing human and robot demonstrations produces significantly higher success rates compared to pseudo-robot and robot-only baselines.
Comparisons to explicit visual editing baselines reveal degradation in tasks requiring precise 3D perception, notably in environments with deformable objects or across long-horizon sequences. LIDEA's canonical 3D observation avoids these pitfalls.
Out-of-Distribution Generalization
On folding tasks with OOD appearance—novel towels and distractors—LIDEA-trained policies incorporating human videos consistently outperformed those trained solely on in-domain robot data. The policy reliably attended to functional targets, demonstrating strong transfer of robustness to visual variation.
Ablations
Ablations on the Stack task highlight:
- Dual-stage distillation is essential: Removing either feature alignment stage or using off-the-shelf representations (e.g., vanilla DINOv3) without cross-embodiment alignment leads to severe performance drops.
- Scene-specific and large-scale internet pretraining provides crucial priors for deployment generalization.
- Strict geometric filtering and canonical gripper filling are indispensable; their absence yields negative transfer or deployment mismatch.
Empirical Analysis of Feature Space
Sequence-level similarity analysis and PCA visualization demonstrate that the aligned encoders collapse feature distributions for human and robot observations, preserving temporal structure and consistent attention to the interaction region.
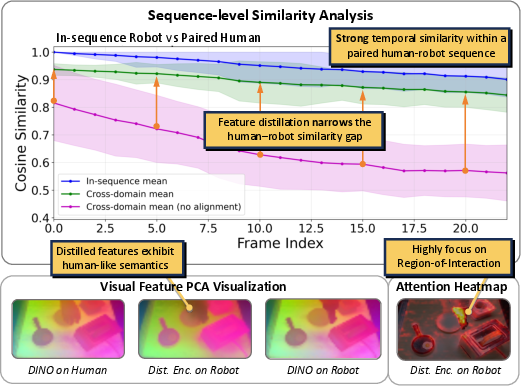
Figure 5: Sequence similarity trends and PCA embedding show that feature distillation aligns human and robot demonstration trajectories, focusing attention on manipulation-centric semantics.
Implications and Future Directions
LIDEA's principled separation and alignment of feature and geometric domains present a scalable path for cross-embodiment policy transfer. Mixing robot and human data substantially improves data efficiency and generalization, enabling robust policies with minimal teleoperation.
The framework's explicit geometric alignment presently targets standard two-finger grippers. Future directions include extension to dexterous manipulation with multi-fingered hands and integrating aligned visual encoders into VLA/video-action learning frameworks for scalable imitation from unconstrained human demonstration corpora.
Conclusion
LIDEA establishes a powerful, data-efficient pipeline for human-to-robot imitation learning that avoids the limitations of prior visual editing or unified representation methods. By jointly leveraging implicit feature distillation and explicit geometric canonicalization, LIDEA bridges the embodiment gap, facilitating robust and generalizable manipulation policies that capitalize on the richness of human activity video data.