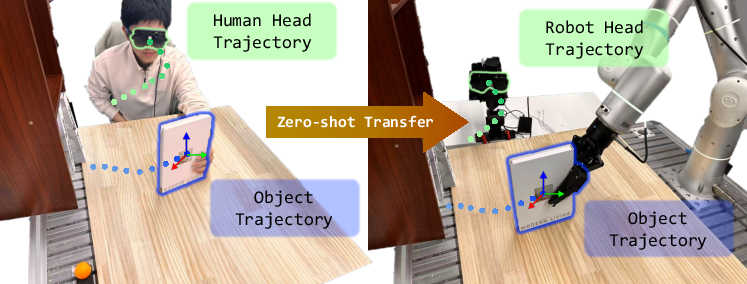
ActiveGlasses: Learning Manipulation with Active Vision from Ego-centric Human Demonstration
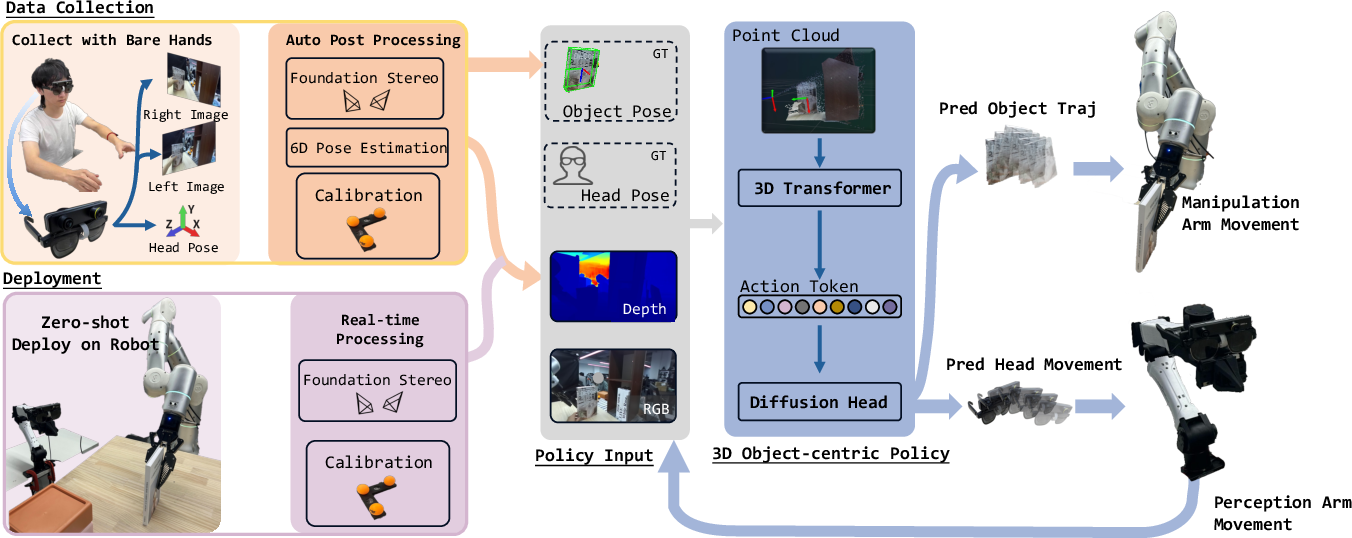
Abstract: Large-scale real-world robot data collection is a prerequisite for bringing robots into everyday deployment. However, existing pipelines often rely on specialized handheld devices to bridge the embodiment gap, which not only increases operator burden and limits scalability, but also makes it difficult to capture the naturally coordinated perception-manipulation behaviors of human daily interaction. This challenge calls for a more natural system that can faithfully capture human manipulation and perception behaviors while enabling zero-shot transfer to robotic platforms. We introduce ActiveGlasses, a system for learning robot manipulation from ego-centric human demonstrations with active vision. A stereo camera mounted on smart glasses serves as the sole perception device for both data collection and policy inference: the operator wears it during bare-hand demonstrations, and the same camera is mounted on a 6-DoF perception arm during deployment to reproduce human active vision. To enable zero-transfer, we extract object trajectories from demonstrations and use an object-centric point-cloud policy to jointly predict manipulation and head movement. Across several challenging tasks involving occlusion and precise interaction, ActiveGlasses achieves zero-shot transfer with active vision, consistently outperforms strong baselines under the same hardware setup, and generalizes across two robot platforms.

Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
The paper introduces ActiveGlasses, a new way to teach robots how to use their hands by watching people do tasks from a first-person view. A person wears lightweight “smart glasses” with a small 3D camera and performs tasks with bare hands. Later, a robot uses the same kind of camera mounted on a small “head” arm to move its view like a human would—turning, leaning, and getting closer when needed. This helps the robot see around obstacles and handle precise jobs, without needing lots of extra training.
What questions are the researchers trying to answer?
- How can we collect lots of useful training data for robots without bulky gear, complicated setups, or tiring teleoperation?
- Can a robot learn not just hand movements, but also when and how to move its “head” (camera) to see better—like a person does?
- If the robot learns “what the object should do next” instead of copying human hand motions, can it work on different robot arms without extra tuning?
- Does this “active vision” approach make robots more successful at tricky tasks with occlusions (things blocking the view) and precise placement?
How does ActiveGlasses work? (In simple terms)
Think of ActiveGlasses as teaching a robot by showing it what you see and how you move your head.
- The person wears smart glasses with a small stereo camera. “Stereo” means there are two lenses, like our two eyes, so the system can sense depth and build a 3D picture of the scene.
- While the person completes a task (like putting a book on a shelf), the system:
- Records the video and tracks the head’s 3D movements (up/down/left/right/forward/backward plus rotations—this is called 6-DoF).
- Builds a “point cloud”—a 3D map made of many dots—so the scene is understood in 3D, not just as flat images.
- Finds the important object (like the book) and figures out where it is and how it’s moving in 3D.
- Ignores the person’s hands in the video so the robot focuses on the object, not the human fingers.
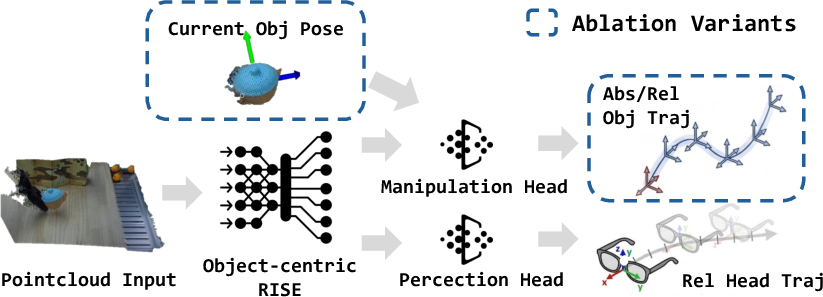
Instead of teaching the robot to copy the person’s exact arm and finger motions, the system teaches the robot the object’s path: where the object needs to go and how it should be oriented at each moment. This is called an “object-centric” approach.
When the robot runs the learned policy (its decision-making “brain”):
- One robot arm does the manipulation (grabbing and moving the object).
- A second small arm holds the camera and acts like a head, moving to get better views (active vision).
- The learned policy predicts two things at once: how the object should move next, and how the “head” should move to see better.
A few friendly analogies:
- Point cloud: like a 3D constellation of dots showing where surfaces are.
- Active vision: like a curious person leaning in and craning their neck to look around a corner.
- Object-centric: instead of copying how you move your fingers, the robot learns the “goal path” of the object in space.
What did they test, and what did they find?
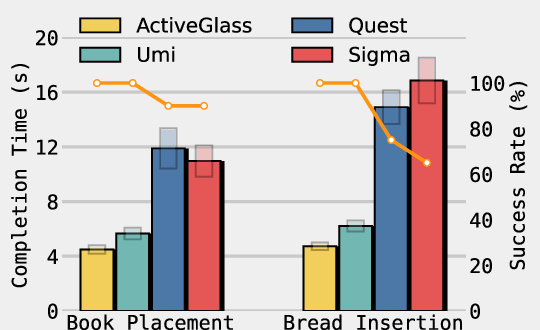
They tried three real-world tasks that are hard to see and require precision:
- Book placement: put a book into a specific slot on a shelf with side walls that block the view.
- Bread insertion: insert a slice of bread into the first slot of a toaster (the slot isn’t visible at first).
- Occluded distant water pouring: carry a teapot past a screen and pour into a cup that’s initially hidden.
Key findings:
- Active vision helped a lot. When the camera could move like a human head to peek around obstacles, success rates were much higher than with a fixed camera.
- Compared to strong baselines using similar hardware, ActiveGlasses improved final success rates by about 35% (book), 25% (bread), and 30% (pouring).
- Using 3D point clouds made learning more stable than using only 2D images, because the view can change a lot as the “head” moves.
- Predicting the object’s path in absolute 3D space worked better than predicting only changes relative to the current pose. It also avoided extra errors from constantly tracking the object frame-by-frame.
- The robot could use what it learned right away on different robot arms (“zero-shot transfer”), because it learned the object’s motion, not specific arm motions. It worked on both a Flexiv Rizon 4 and a UR5, with small differences due to arm reach limits.
- Data collection was faster and less tiring for people. Wearing light glasses and using bare hands was easier than holding heavy devices or using teleoperation controllers for long periods.
Why does this matter?
- Collecting good robot training data is usually slow and expensive. This approach makes it easier: people can just wear glasses, use their hands naturally, and record useful 3D demonstrations.
- Teaching robots to move their “head” like humans do makes them better at real-life tasks where things are often hidden or hard to see.
- Learning “what the object should do” instead of copying human arm motions means the same data can train many different robots, saving time and money.
- This could help robots work better in homes, kitchens, warehouses, and stores—places where viewpoints change, things get in the way, and precision matters.
In short, ActiveGlasses shows a practical way to teach robots by capturing human know-how and human-like seeing, then transferring it directly to robots without extra retraining.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of unresolved issues and concrete open questions that future work could address.
- Real-time performance and latency: End-to-end inference requires stereo depth (FoundationStereo), segmentation (SAM2/Grounded-SAM), pose estimation (FoundationPose), point-cloud processing, and diffusion policy rollout. The paper reports no timing budget, control rate, or hardware specs. What is the achievable closed-loop frequency, and how does latency affect manipulation and active camera motion?
- Dependence on third-party perception modules: The pipeline assumes reliable depth, segmentation, and 6D pose. There is no sensitivity analysis to errors or degradation (e.g., poor lighting, motion blur, reflective/textureless surfaces). How robust is the system to noise and failure modes of FoundationStereo/SAM2/FoundationPose?
- Object mesh requirement: Pose estimation is aided by object CAD meshes. How does the method handle novel objects without meshes, deformable items, or mesh inaccuracies? Can the policy be trained or adapted to mesh-free or category-level pose estimators?
- Label noise in trajectory extraction: Ground-truth object trajectories come from monocular segmentation + stereo depth + 6D pose tracking, which can drift or fail. The paper lacks quantitative error analysis of labels and their impact on policy learning. Can the policy be made robust to noisy trajectories (e.g., via noise-aware loss, data filtering, or confidence weighting)?
- Calibration and world-frame setup: The world frame is defined using three tabletop spheres in the first frame, then propagated via head pose. This requires scene instrumentation and assumes spheres remain visible initially. How can the method avoid such props in the wild (e.g., self-calibration, SLAM-based world frame) and mitigate drift over long horizons?
- Head–camera extrinsics and drift: ArUco-based hand–eye calibration was reported unstable; the alternative relies on head-pose propagation. There is no quantitative evaluation of extrinsic accuracy, temporal drift, or time-sync errors between XREAL pose and ZED frames. How sensitive is performance to calibration errors, and can online extrinsic refinement be incorporated?
- Active vision policy objective: Head motion is imitation-learned from human demonstrations without an explicit information-seeking objective. Does the learned policy generalize to occlusions not seen in training? Can an auxiliary reward (e.g., visibility/uncertainty reduction) or critic help produce more robust active perception?
- Coordination and safety between two arms: The perception arm moves independently of the manipulation arm, with no explicit joint planning or collision avoidance described. How to ensure safe, coordinated dual-arm motion, especially in clutter or near humans? Can joint optimization of perception/manipulation trajectories reduce interference?
- Workspace and kinematic constraints: Object-centric actions still require feasible IK for different robots. The UR5 showed more failures near workspace limits. How can the policy adapt actions to embodiment constraints (e.g., feasibility-aware action heads, reactive re-planning) to improve cross-platform robustness?
- Generalization scope: Experiments cover three tabletop tasks and limited object/scene variations. How well does the approach scale to:
- Diverse object categories, textures, and sizes (including small/transparent/reflective)?
- Non-tabletop and mobile manipulation scenarios?
- Highly cluttered, dynamic scenes with moving distractors or humans?
- Data scale and diversity: Training used 100–200 demos per task collected by (presumably) few operators. There is no study of cross-operator variability, style differences, or required dataset size for robust generalization. How many operators/demos are needed, and does multi-operator data improve robustness?
- Removal of wrist cameras: The system relies solely on a head camera. Many precise tasks benefit from end-effector visual servoing or tactile feedback. What are the failure modes when fine local feedback is needed? Can sparse tactile/proprioceptive cues or lightweight wrist sensing be integrated without sacrificing the active-vision benefits?
- Grasping assumptions: Pre-grasp uses AnyGrasp or a fixed strategy, but robustness with partial/occluded point clouds from a head camera is not analyzed. How reliable is grasp detection under common failure conditions, and can grasp selection be co-optimized with active viewpoint planning?
- Termination modeling: The termination label is defined as the last five frames of each episode. This heuristic may mislabel partial successes/failures and encourage premature stopping. Can learned success classifiers, self-supervised progress signals, or task-specific criteria improve reliability?
- Action representation trade-offs: The paper finds absolute object trajectories work best without conditioning on current object pose. This risks reduced closed-loop responsiveness. Under what conditions does excluding current pose hurt recovery from perturbations? Can hybrid representations retain responsiveness while avoiding shortcut learning?
- Robustness to base motion and SLAM drift: The perception arm is on a wheeled table with small base randomization. How does larger base motion or long-horizon drift affect performance? Can online map/pose correction or visual-inertial SLAM be integrated to preserve a stable world frame?
- Ergonomics and user study: Scalability claims are supported by completion time and device weights for two tasks, but lack formal user studies, long-duration fatigue analysis, or statistical tests. How does comfort and data quality evolve over hours/days of use and across different demographics?
- Privacy and sensor substitution: XREAL disallows direct camera access, so the ZED Mini is mounted on the glasses. This introduces a mismatch between the operator’s eye FOV and camera FOV (the authors added a UI indicator). How much does this mismatch degrade natural gaze/head coordination, and can eye-tracking or gaze estimation help?
- Compute footprint and deployment hardware: There is no report on GPU/CPU memory and power requirements for onboard vs offboard processing. Can the full stack run on embedded compute at the required control frequency? What optimizations are needed for field deployment?
- Failure analysis: The paper reports success rates but lacks a systematic diagnosis of failure cases (e.g., pose-estimation drift, occlusion not resolved, IK failure, collision). A taxonomy of failures and targeted mitigations would guide future improvements.
- Comparison to other active vision baselines: Ablations compare to a fixed single camera and Pi0.5, but not to other 6-DoF active perception methods (e.g., ViA, EgoMi) or 2-DoF pan-tilt heads. How much of the gain is due to 6-DoF camera placement versus the policy design?
- In-the-wild calibration and setup overhead: The need for initial sphere-based world-frame setup and per-episode mask initialization is unclear for real homes/offices. What is the minimal operator overhead for unscripted environments, and can automatic object discovery/tracking reduce setup?
- Liquids and deformables: The water-pouring task is evaluated via success/failure without measuring pour accuracy (volume, spillage). Bread insertion involves mild deformability. How does the approach handle genuinely deformable objects or precise liquid control with feedback?
- Sensor/actuator variability: Only one stereo camera and two robot arms are tested. How does performance transfer to other cameras (baseline/quality), mono depth, structured-light sensors, different grippers/hands, or mobile bases?
- Reproducibility and release: The paper does not state whether code, models, or datasets will be released. Without this, it is hard to validate and extend the framework.
- Safety under occlusion-seeking motions: Aggressive head movements may improve visibility but risk collisions or violate human-robot safety zones. How to enforce visibility-aware yet safety-constrained active perception?
- Long-horizon and multi-step tasks: The evaluation covers single-skill sequences with three stages. How does the method compose multiple subtasks, handle re-grasps, or maintain state over extended horizons without external memory or language guidance?
- Learning beyond imitation: The method strictly imitates demonstrated head and object trajectories. Can it improve by mining failures (self-correction), leveraging exploration (RL), or learning information-gain heuristics for unseen occlusions and scene changes?
Practical Applications
Immediate Applications
Below is a set of concrete, deployable use cases that leverage the paper’s findings and system design. Each item indicates the sector, a potential tool/product/workflow, and key assumptions or dependencies that affect feasibility.
- Active occlusion-robust shelf stocking and bin-picking in constrained spaces
- Sector: Warehousing and logistics; retail operations
- Tool/Product/Workflow: “ActiveGlasses Kit” for demonstration-based robot task programming; retrofit of existing manipulators with a 6-DoF perception arm and head-mounted stereo camera; object-centric point-cloud policy for zero-shot deployment across arms
- Assumptions/Dependencies: Reliable stereo depth and segmentation (FoundationStereo, SAM2/Grounded-SAM); availability of a 6-DoF perception arm; stable calibration (e.g., fiducials or the tabletop sphere method); tasks fit object-centric trajectory prediction; sufficient compute for inference
- Rapid in-the-wild data collection for manipulation tasks without teleoperation burden
- Sector: Robotics R&D; manufacturing engineering; robotics integrators
- Tool/Product/Workflow: Bare-hand demo capture via smart glasses + ZED Mini; Unity-based UI with ROS synchronization and gesture/audio cues; automatic pipeline for depth/segmentation/pose estimation; AnyGrasp for pre-grasp stage
- Assumptions/Dependencies: Operators can wear smart glasses safely on the floor; privacy policies for head-mounted cameras are in place; availability of object meshes (optional but boosts FoundationPose robustness); consistent SLAM from the glasses IMU
- Programming robots to perform precise, occluded tabletop tasks (e.g., toaster insertion, pouring)
- Sector: Food service automation; hospitality; household robotics; lab automation
- Tool/Product/Workflow: Dual-arm deployment where the “perception arm” reproduces human head motion; object-centric 6-DoF trajectory prediction for the manipulated item; termination flag for “done” detection
- Assumptions/Dependencies: Workspace permits perception arm motion without IK failure; high-quality egocentric inputs; tasks resemble those demonstrated (bread insertion, occluded pouring); reliable grasp generation (AnyGrasp or fixed strategies)
- Cross-embodiment transfer of learned policies across robot arms
- Sector: Robotics platforms and integrators; OEMs
- Tool/Product/Workflow: Embodiment-agnostic object trajectory prediction to enable zero-shot policy reuse on different arms (e.g., Flexiv and UR5); camera-to-EE transforms computed via calibration (SPOT-style)
- Assumptions/Dependencies: Robot workspace and kinematics don’t violate planned object trajectories; consistent camera mounting; compatible grippers and end-effectors
- Reduced camera infrastructure in production cells
- Sector: Industrial automation; facilities engineering
- Tool/Product/Workflow: Replace multi-camera fixed setups with a single active-vision head camera on a 6-DoF arm; dynamic viewpoint control to mitigate occlusions and distant targets
- Assumptions/Dependencies: Mechanical integration of perception arm near workpiece; safety fencing or collaborative robot certification for moving sensors; maintainable calibration routine
- University coursework and research on active vision and object-centric imitation
- Sector: Academia; education
- Tool/Product/Workflow: Teaching labs adopt the ActiveGlasses stack to explore active perception, head–hand joint distributions, and point-cloud policies; creation of small datasets for reproducible benchmarks
- Assumptions/Dependencies: Access to smart glasses, stereo camera, and at least one manipulator + 6-DoF perception arm; institutional review for recording policies
- Quality assurance and inspection with adaptive viewpoints
- Sector: Manufacturing QA; electronics assembly; biotech
- Tool/Product/Workflow: Perception arm repositions head camera to inspect features partially hidden by fixtures; learned policies guide viewpoint motions for consistent coverage
- Assumptions/Dependencies: Adequate lighting and texture for segmentation; safety procedures for close camera motion; mapping from object-centric goals to inspection trajectories
- Lightweight alternative to heavy handheld teleoperation devices
- Sector: Robotics deployment; human–robot interaction
- Tool/Product/Workflow: Replace devices >600g with head-mounted capture to demonstrate tasks; reduce operator fatigue; faster demo turnaround for new workflows
- Assumptions/Dependencies: Smart glasses fit and comfort; stable tracking; site policies allow head-mounted recording; data pipeline tuned to the environment
Long-Term Applications
Below are forward-looking use cases that require further research, scaling, engineering integration, or regulatory work before broad deployment.
- Crowdsourced egocentric datasets for general-purpose manipulation
- Sector: Software/data platforms; VLA model training; consumer robotics
- Tool/Product/Workflow: At-scale collection via consumer smart glasses (privacy-preserving pipelines); standardized object-centric datasets that capture active vision signals; integration with large vision-language-action (VLA) models
- Assumptions/Dependencies: Consent, privacy, and data governance frameworks; robust zero-shot generalization to diverse homes/factories; automated annotation and de-identification
- Mobile manipulation with integrated head/torso-like active vision
- Sector: Service robotics; healthcare assistance; eldercare; hospitality
- Tool/Product/Workflow: Embedded, lightweight 6-DoF “robot head” modules with stereo cameras and SLAM; object-centric control policies that coordinate base, torso, and arm motion to manage occlusions and tight spaces
- Assumptions/Dependencies: Hardware miniaturization and power management; collision-free motion planning; clinically safe and certifiable behavior; reliable depth/segmentation in clutter
- Dexterous and bimanual tasks learned from bare-hand egocentric demos
- Sector: Advanced manufacturing; surgical robotics; lab automation
- Tool/Product/Workflow: Extend object-centric policy to multi-object, multi-contact, dexterous manipulation; combine with exoskeleton or glove systems for fine grained demonstrations; hybrid grasp + trajectory prediction
- Assumptions/Dependencies: High-fidelity tracking of fingers without heavy devices; better contact modeling; robust point-cloud policies under fast, complex hand motions
- Standardized policy APIs and MLOps for object-centric robot learning
- Sector: Robotics software; platforms; systems integration
- Tool/Product/Workflow: APIs for object-trajectory prediction, calibration services, and active vision motion planning; CI/CD pipelines for dataset curation, training, deployment, monitoring, and rollback
- Assumptions/Dependencies: Cross-vendor calibration tooling; shared benchmarks; GPU/accelerator access for training and inference
- Safety and regulatory frameworks for moving sensor arms and head-mounted capture
- Sector: Policy and regulation; workplace safety; privacy compliance
- Tool/Product/Workflow: Standards for active perception hardware near people; guidelines for recording with smart glasses (data retention, consent, masking human hands in point clouds)
- Assumptions/Dependencies: Participation by regulators and industry groups; demonstrable safety cases; tooling for privacy-preserving processing (e.g., automatic hand point-cloud removal)
- Autonomous retail shelf management and planogram compliance
- Sector: Retail tech
- Tool/Product/Workflow: Robots learn stocking/arrangement from staff demos; active vision resolves occlusions in crowded shelves; object-centric policies accommodate varied fixtures and SKUs
- Assumptions/Dependencies: SKU recognition integration; robust segmentation across packaging variants; store safety policies; nighttime operation scheduling
- Maintenance, inspection, and repair in cluttered industrial environments
- Sector: Energy; utilities; manufacturing; refinery operations
- Tool/Product/Workflow: Active vision to navigate around pipes, cabinets, and shields; object-centric task planning for valve operation or connector alignment; human demonstrations capture tacit procedures
- Assumptions/Dependencies: Environmental robustness (dust, vibration, heat); reliable depth perception on metallic/reflective surfaces; job-specific tool/end-effector compatibility
- Real-time, on-device adaptation from user demonstrations
- Sector: Consumer/home robotics; prosumer tools
- Tool/Product/Workflow: Incremental learning where home users teach robots new tasks via glasses; on-device inference and updates; privacy-preserving local storage
- Assumptions/Dependencies: Efficient edge training or rapid fine-tuning; robust calibration in changing home layouts; user-friendly UIs and recovery from failures
- Multi-robot collaboration with coordinated active vision
- Sector: Smart factories; logistics
- Tool/Product/Workflow: Shared scene models and viewpoint scheduling across multiple perception arms; object-centric goals broadcast to manipulators; collaborative occlusion management
- Assumptions/Dependencies: Low-latency networking; shared calibration and time-sync; collision avoidance among multiple moving sensors
Notes on Feasibility and Dependencies (Cross-Cutting)
- Sensing robustness: Success depends on depth quality (stereo), accurate segmentation (SAM2/Grounded-SAM), and stable 6-DoF pose tracking (FoundationPose + optional meshes).
- Hardware availability: The approach presumes access to a 6-DoF perception arm, a head-mounted stereo camera, and a compatible manipulator; workspace and IK constraints can limit success.
- Calibration: The paper’s three-sphere world-frame method reduces per-frame overhead but requires initial visibility; alternative fiducials or self-calibration methods may be needed for production.
- Task fit: Object-centric representation works best for tasks where the manipulated item’s 6-DoF trajectory defines success; highly deformable or multi-contact tasks may require extended modeling.
- Safety and privacy: Head-mounted recording and moving perception arms need clear SOPs, fencing/collaboration certification, and privacy-preserving data handling (e.g., automatic removal of human-hand points).
- Compute and software stack: ROS integration, Unity UI, and diffusion-policy inference require reliable middleware and compute resources; MLOps (data curation, monitoring) will be critical at scale.
Glossary
- 2-DoF: Two degrees of freedom, typically rotational, allowing motion about two axes. "a camera mounted on a 2-DoF gimbal"
- 6-DoF: Six degrees of freedom, allowing 3D position and orientation control (x, y, z, roll, pitch, yaw). "a 6-DoF robotic arm"
- active vision: Goal-directed sensing where the observer moves to acquire better information. "ActiveGlasses achieves zero-shot transfer with active vision"
- AnyGrasp: A grasp synthesis method/system for detecting and executing feasible grasps. "we use AnyGrasp to perform the grasping action"
- Aruco markers: Fiducial markers used for camera calibration and pose estimation. "the commonly used calibration approach with Aruco markers is prone to be unstable"
- behavior cloning: Imitation learning that maps observations to actions by supervised learning on demonstrations. "through behavior cloning or reinforcement learning"
- bimanual manipulation: Coordinated manipulation involving two effectors/arms. "similar to bimanual manipulation."
- cross-embodiment: Designed to work across different bodies or hardware morphologies. "cross-embodiment deployment"
- diffusion head: A diffusion-model-based output head that predicts actions or trajectories. "we adopt two diffusion heads"
- ego-centric: First-person perspective aligned with the observer’s viewpoint. "from ego-centric human demonstrations"
- end-effector: The tool or gripper at the end of a robot arm that interacts with the environment. "to the end-effector pose"
- FoundationPose: A model for unified 6D object pose estimation and tracking. "we estimate the pose of the manipulated object using FoundationPose"
- FoundationStereo: A zero-shot stereo matching method for depth estimation from stereo images. "we first estimate the depth map d_i using FoundationStereo"
- Grounded-SAM: A segmentation approach combining grounding with Segment Anything for diverse visual tasks. "we segment the operator’s hands using Grounded-SAM"
- IMU: Inertial Measurement Unit; sensors measuring acceleration and angular velocity for motion tracking. "the ZED Mini also provides an IMU for motion tracking"
- inverse kinematics (IK): Computing joint configurations that achieve a desired end-effector pose. "inverse kinematics(IK) failure"
- morphological gap: The mismatch between human and robot bodies that complicates direct action transfer. "the morphological gap"
- object-centric: Representations or policies focused on objects’ states/trajectories rather than agent kinematics. "an object-centric, 3D point-cloud policy"
- object mesh: A 3D geometric model of an object used as a prior for pose estimation or planning. "the object mesh"
- Pi0.5: A baseline vision-language-action policy referenced for comparative evaluation. "For Pi0.5 , we train the policy"
- point cloud: A set of 3D points representing a scene, often reconstructed from depth. "takes point cloud in the world frame as input"
- proprioception: Internal sensing of an agent’s own joint states and motions. "through proprioception."
- reinforcement learning: Learning to act via trial-and-error based on rewards. "through behavior cloning or reinforcement learning"
- RISE: A 3D perception-based imitation learning framework used as a policy backbone. "modified from RISE"
- ROS: Robot Operating System; a middleware for robot software integration and message passing. "Data timestamps is aligned by ROS."
- SAM2: A next-generation Segment Anything model for image/video segmentation. "using SAM2"
- SLAM: Simultaneous Localization and Mapping; estimating a sensor’s pose while building a map. "the SLAM localization features of commercial AR glasses"
- teleoperation: Controlling a robot remotely by a human operator. "collecting data via teleoperation"
- wrist-mounted cameras: Cameras attached to a robot’s wrist/end-effector for local perception. "wrist-mounted cameras for perception"
- zero-shot transfer: Deploying a policy to new hardware/tasks without additional fine-tuning. "enabling zero-shot transfer to robotic platforms"
Collections
Sign up for free to add this paper to one or more collections.