- The paper introduces ECHO, which augments standard RL by incorporating a cross-entropy loss on terminal feedback to exploit dense supervision.
- ECHO significantly improves performance, nearly doubling pass@1 rates and accelerating convergence with up to 2.3x faster training on CLI tasks.
- The approach reduces dependence on costly expert demonstrations while enabling verifier-free adaptation through robust terminal-response modeling.
ECHO: Terminal Agents Learn World Models for Free
Problem Setting and Motivation
Language-model (LM) agents operating in Command-Line Interface (CLI) environments interact by emitting commands, receiving terminal feedback, and iteratively updating their internal state. However, standard reinforcement learning (RL) paradigms for such agents, particularly GRPO (Group-Relative Policy Optimization), only leverage sparse, outcome-level rewards—typically binary episode feedback (success/failure)—while ignoring the rich, dense supervision inherent in the streams of terminal responses generated during rollouts. This discarding of terminal feedback as a training signal restricts the learning potential of agents, especially in environments where only a small minority of trajectories lead to positive reward, and most interactions contain valuable evidence regarding environment dynamics.
ECHO: The Hybrid Objective
ECHO (Environment Cross-entropy Hybrid Objective) is introduced to rectify this inefficiency. It augments the standard policy-gradient loss on action tokens with a supervised cross-entropy loss targeting the terminal-output tokens produced by the environment after each action.
ECHO is constructed as:
LECHO(θ)=LGRPO(θ;A)+λLEnv(θ;O′)
where A indexes action-token positions (for GRPO), and O′ addresses environment-token positions (excluding warnings). The environment loss is a length-normalized cross-entropy, leveraging the same actor forward pass and logits as the policy-gradient loss, without additional rollouts or teacher models. This architecture ensures that every terminal observation becomes a dense training target, transforming even failed rollouts into sources of supervision.
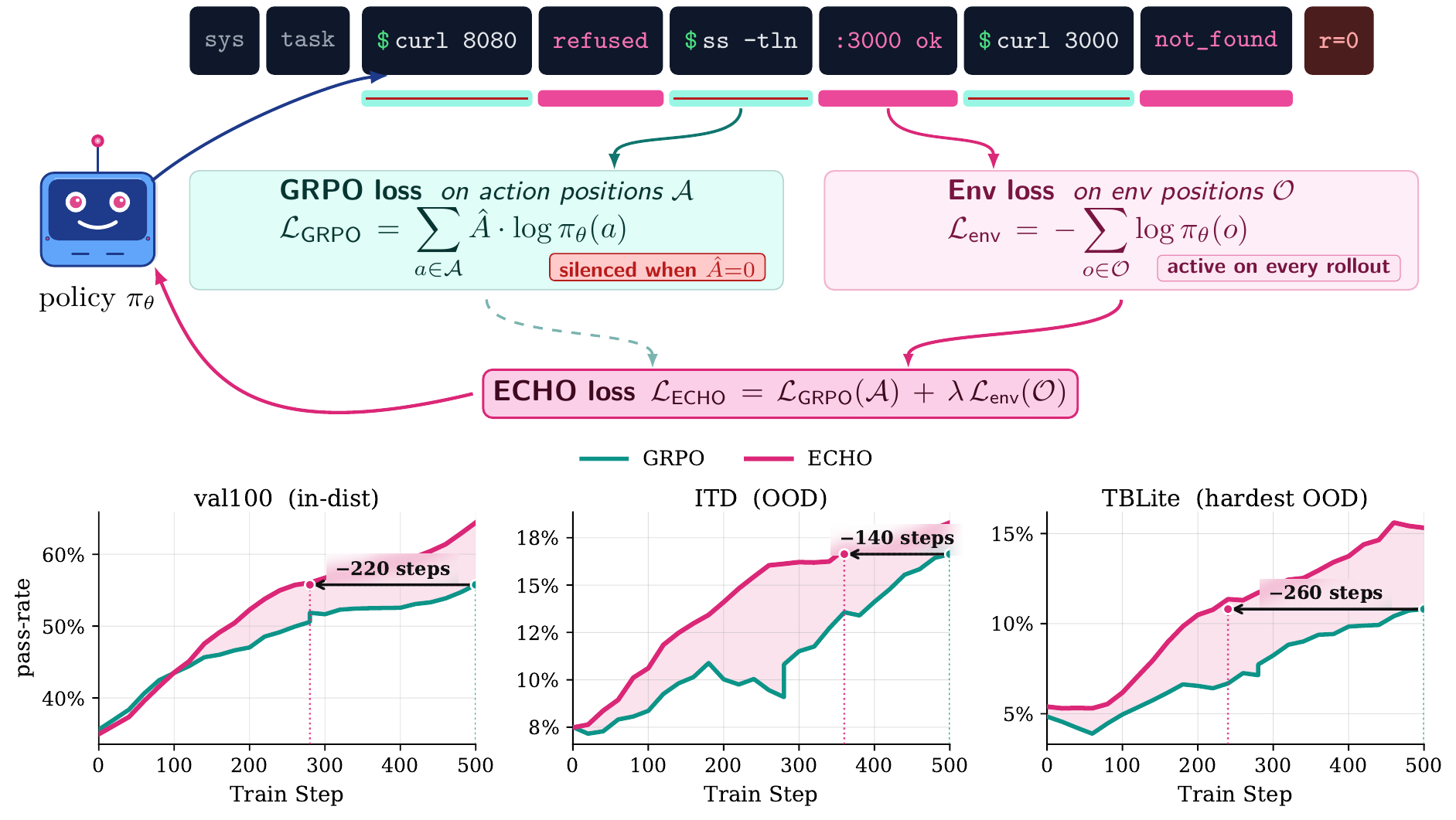
Figure 1: ECHO turns terminal feedback into dense supervision by attaching cross-entropy loss to environment-observation tokens in agent RL rollouts, while standard GRPO only rewards action tokens.
Experimental Design
Training is conducted on curated and synthetic terminal tasks drawn from datasets such as Endless Terminals and OpenThoughts-Agent-v1-RL, filtered for domains with interpretable feedback. Evaluation tasks include held-out (val100), internal-dev (ITD), OpenThoughts-TBLite (TBLite), and TerminalBench-2.0 (TB2). Models include Qwen3-8B, Qwen3-14B, and OT-SFT (OpenThinker-Agent-v1-SFT). RL is performed using GRPO, with ECHO introduced via a loss mask for environment tokens and tuned loss weight (λ) between 0.01 and 0.05.
Empirical Results
ECHO consistently improves performance across all models and benchmarks. Most notably, pass@1 rates on the challenging TerminalBench-2.0 nearly double:
- Qwen3-8B: 2.70% (GRPO) → 5.17% (ECHO)
- Qwen3-14B: 5.17% (GRPO) → 10.79% (ECHO)
ECHO also accelerates learning, reaching GRPO's peak performance in 1.5–2.3x fewer training steps for 8B models, and halves per-task timeout rates and completion tokens during inference for Qwen3-8B and OT-SFT.
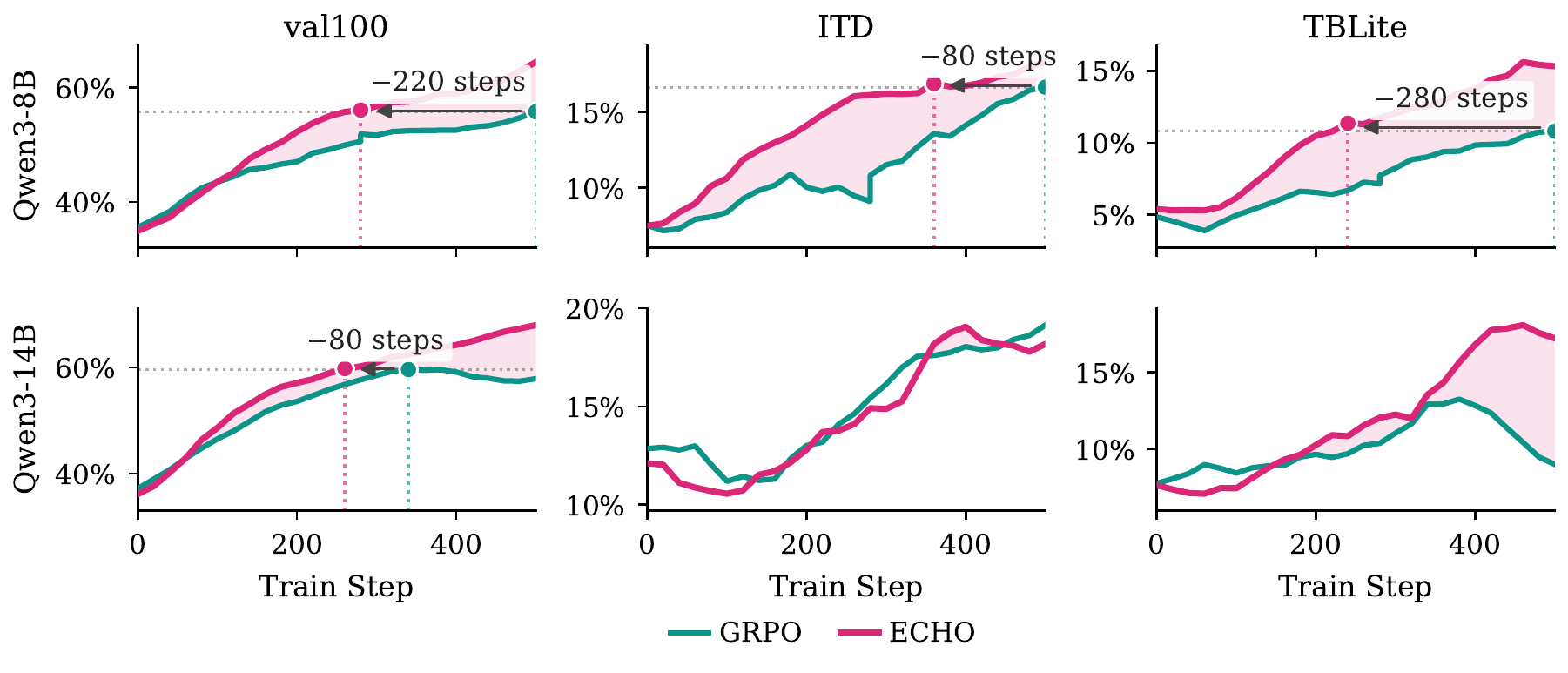
Figure 2: Training curves for Qwen3-8B and Qwen3-14B, where ECHO consistently outperforms GRPO, with shaded regions marking ECHO's advantage, across in-distribution and OOD benchmarks.
World-Modeling and Terminal Dynamics
To validate that ECHO induces predictive world modeling, environment-token cross-entropy losses are measured on off-policy trajectories generated by a stronger model (Qwen3-32B). ECHO-trained policies demonstrate substantial reductions in environment-token cross-entropy compared to both pre-RL and GRPO-only policies. This shows that ECHO-trained agents acquire a more transferrable and accurate model of terminal-response dynamics.
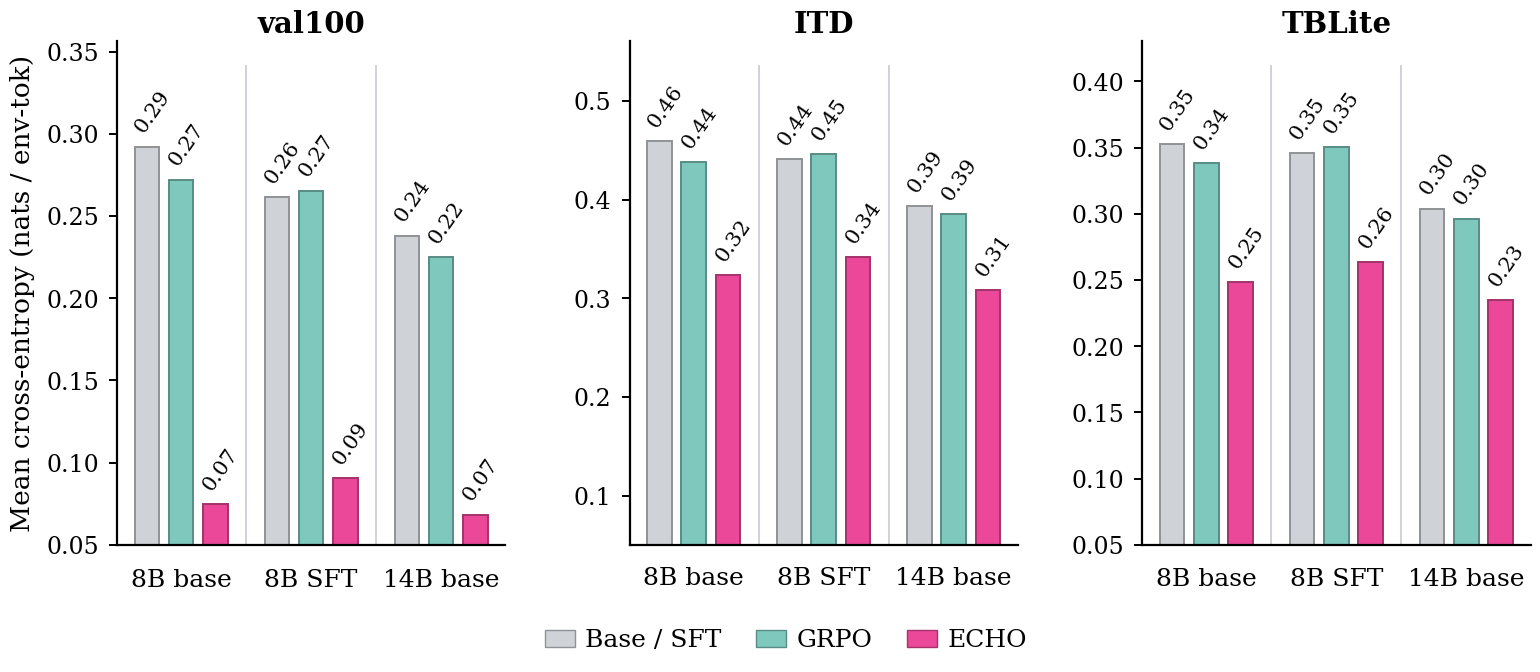
Figure 3: Per-token cross-entropy for terminal-output tokens—ECHO sharply lowers prediction error across all models and evaluation slices compared to GRPO, validating improved terminal dynamics modeling.
Reduced Reliance on Expert Demonstrations
ECHO reduces the necessity for costly expert SFT initialization. With base Qwen3-8B, ECHO matches or surpasses the performance uplift gained from OT-SFT+GRPO on internal benchmarks, recovering ~50% of the gap on TB2 without using any expert demonstrations.
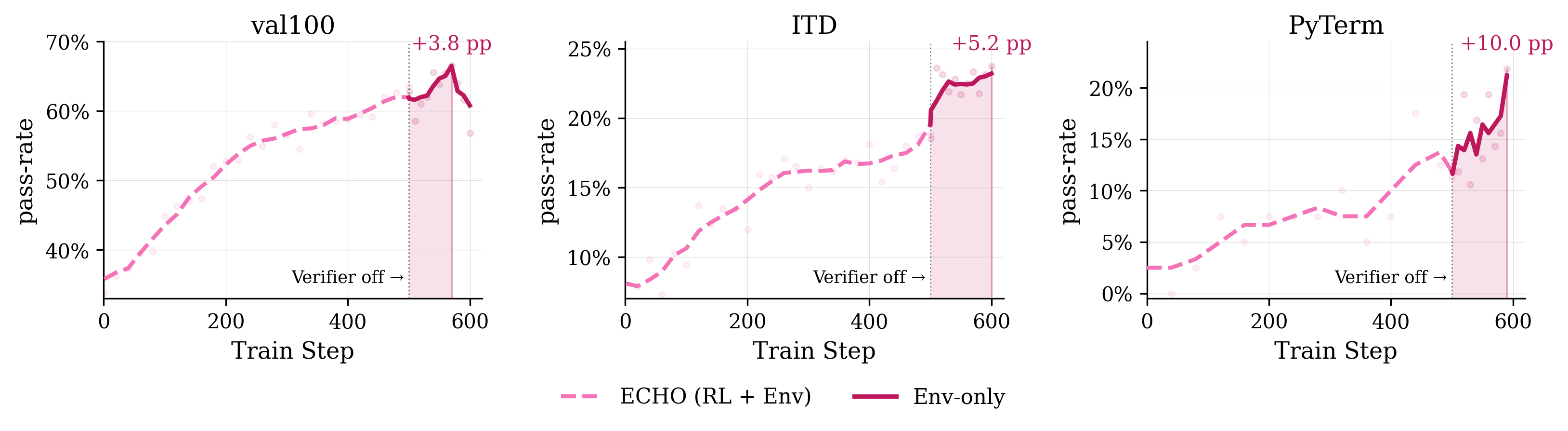
Figure 4: ECHO recovers most of the expert-SFT initialization benefit for internal evaluations and half the gap for TB2, evidencing efficient interaction-prior acquisition.
Training and Inference Efficiency
ECHO improves both training convergence speed and inference efficiency. On Qwen3-8B, ECHO reaches peak validation scores nearly twice as fast as GRPO alone. Inference statistics show substantial reductions in timeouts, turns, and completion tokens, maximizing practical utility of agent deployments.
Verifier-Free Adaptation
Remarkably, environment prediction loss alone—sans policy-gradient or unit-test rewards—enables verifier-free self-improvement. An ECHO checkpoint, trained further using only environment-token cross-entropy, improves task solve rates on unseen in-distribution and challenging OOD tasks, particularly when trajectories are filtered for clean tool-call usage. This supports that dense environment feedback, even without outcome supervision, is sufficient for continued agent improvement in certain domains.
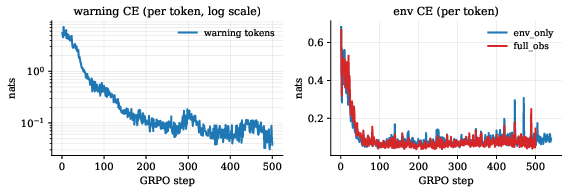
Figure 5: Verifier-free adaptation leads to gains in unseen tasks by optimizing only environment-token prediction, particularly for feedback-rich domains.
Auxiliary Loss Dynamics and Target Selection
The warning-token cross-entropy loss rapidly drops to near-zero within ~60 steps, highlighting the importance of selecting terminal-output (env) tokens rather than low-entropy warnings for sustained informative gradient. The terminal-output tokens maintain a non-trivial cross-entropy plateau, continuing to shape agent representations throughout RL.
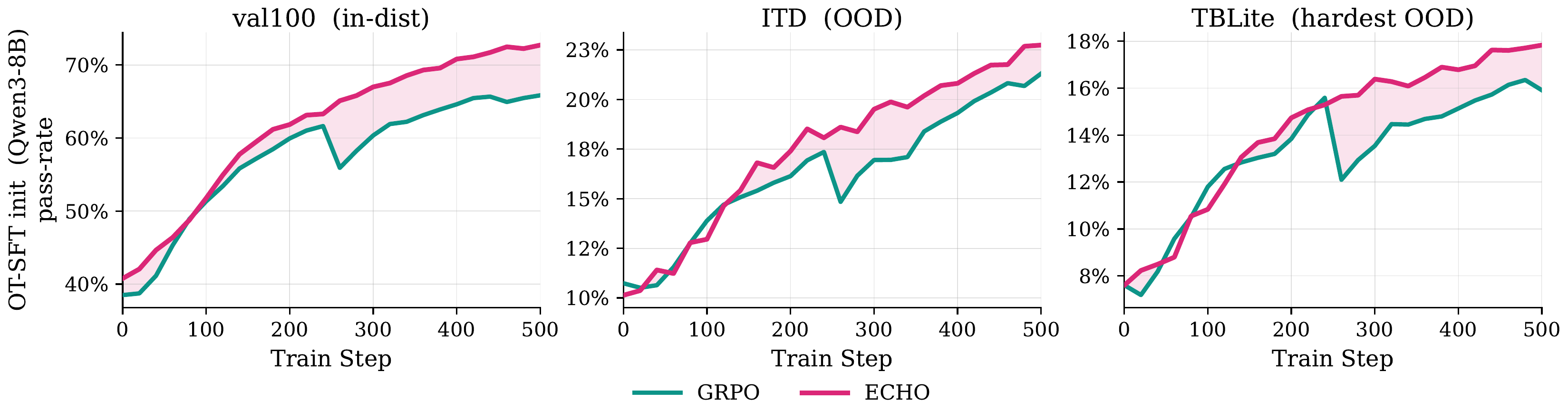
Figure 6: Cross-entropy dynamics: warning tokens are memorized quickly, while terminal-output tokens provide sustained training signal.
Theoretical and Practical Implications
ECHO demonstrates that environment observations in agentic rollouts encode a dense, on-policy supervision signal, which is underutilized in standard RL. This auxiliary prediction paradigm enables accelerated and more robust learning, transfer of terminal dynamics, reduction in reliance on expensive expert data, and efficient adaptation without explicit reward signals. The approach is compatible with existing stabilization methods (KL regularization, trajectory filtering) and is architecturally agnostic, requiring only adjustment in the loss mask.
Practically, ECHO expands the toolkit for terminal agents—enabling efficient learning from interaction itself and unlocking a richer supervision regime. Theoretically, this raises the prospect that next-token prediction on environment feedback may yield much of the world model needed for competent agent behavior—a claim echoed by prior LM theory.
Future Directions
- Long-horizon generalization: Extending ECHO to environments with deeper latent state and partially observable dynamics beyond terminal output.
- Automated filtering and curriculum learning: Leveraging the auxiliary loss for adaptive trajectory selection and automated curriculum.
- Integration with imitation learning and language feedback: Combining environment-token prediction with richer forms of textual supervision (planner hints, critiques) and expert learning.
- Scaling and application to other embodied agent domains: Systematic exploration in robotics and interactive web navigation where high-dimensional textual or sensory feedback can be harnessed similarly.
Conclusion
ECHO unlocks the cryptic supervision within terminal responses, transforming every action's consequence into a training target. By leveraging environment prediction loss alongside policy optimization, ECHO accelerates agent learning, improves task performance, reduces reliance on demonstrations, and facilitates verifier-free adaptation. These results suggest that dense interaction signals—already present in every agent rollout—constitute a powerful and scalable supervision source for agentic RL and world modeling in CLI environments (2605.24517).

