- The paper introduces Echo, which decouples trajectory sampling from policy updates to enhance scalability and hardware utilization.
- It employs sequential and asynchronous synchronization mechanisms to balance statistical accuracy and device efficiency in RL tasks.
- Experiments on Sokoban, mathematical reasoning, and logic puzzles demonstrate Echo’s advantages over traditional co-located systems using decentralized hardware.
Echo: Decoupling Inference and Training for Large-Scale RL Alignment on Heterogeneous Swarms
The paper "Echo: Decoupling Inference and Training for Large-Scale RL Alignment on Heterogeneous Swarms" presents a novel framework designed to address the limitations imposed by co-locating trajectory sampling and policy optimization on the same GPU cluster. This approach violates the SPMD assumption in distributed training systems. Echo introduces a system that decouples these two phases using heterogeneous swarms, improving scalability and hardware utilization.
System Overview
The Echo framework separates trajectory generation and policy updates across distinct swarms: an inference swarm for sampling trajectories, and a training swarm for policy optimization. This design choice alleviates the issues tied to single-cluster systems and allows each swarm to optimize according to its specific workload, enhancing task efficiency.
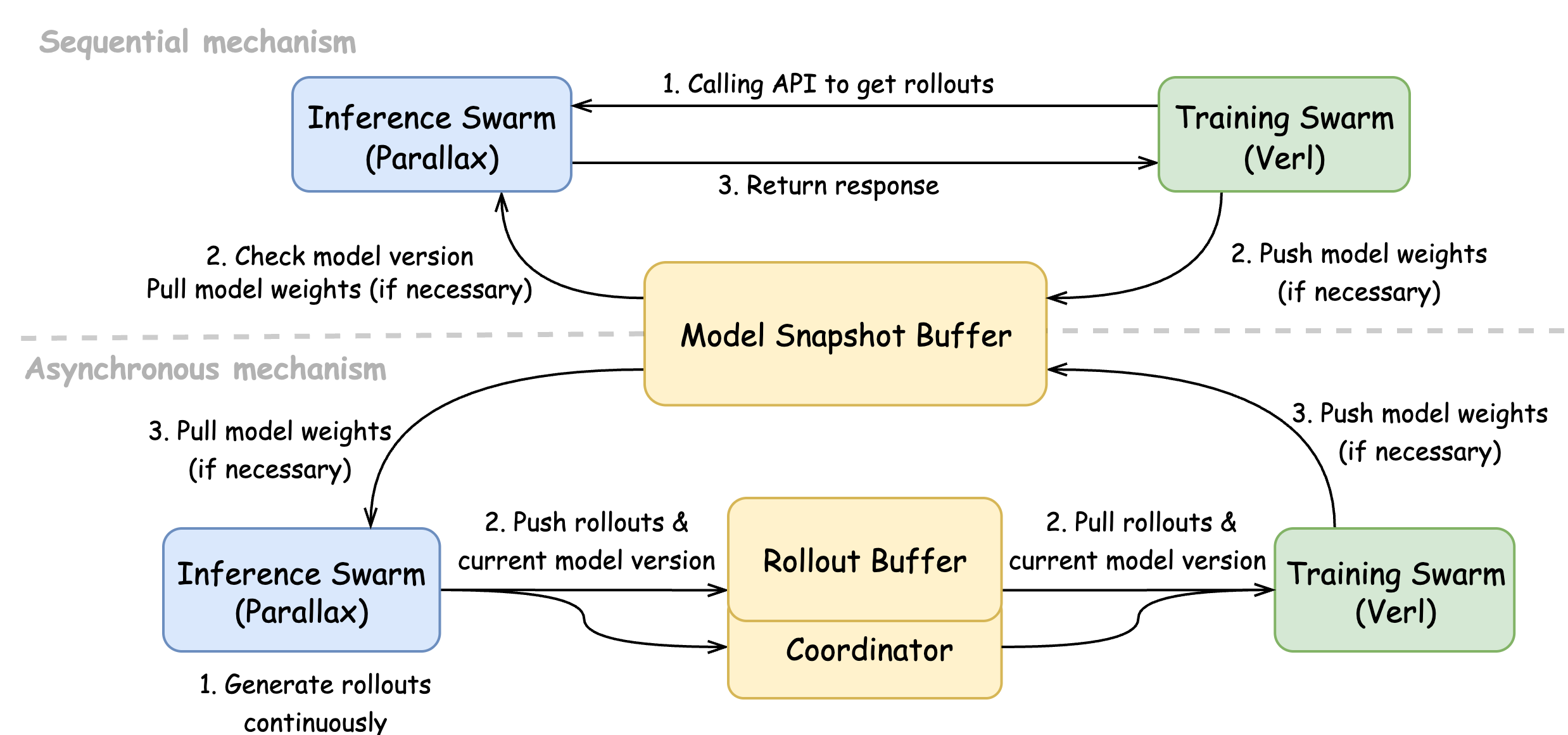
Figure 1: Echo\ architecture and the two synchronisation mechanisms between the training and inference swarms.
Synchronization Mechanisms
Echo implements two synchronization protocols:
- Sequential Mechanism (Accuracy-Centric): The training swarm requests trajectories via API calls, ensuring policy weights are updated beforehand to minimize bias. This approach achieves optimal statistical accuracy.
- Asynchronous Mechanism (Efficiency-Centric): Rollouts are generated continuously and tagged with policy versions. A replay buffer synchronizes data consumption, allowing the training swarm to proceed autonomously and enhancing device utilization.
Parallax Inference Engine
Parallax transforms consumer-grade devices into a unified pipeline-parallel sampler, supporting heterogeneous hardware such as consumer GPUs and Apple Silicon. This decentralized approach does not rely on high-speed interconnects like RDMA, ensuring broad compatibility with commodity networks.
Training Framework
The Echo framework extends the Verl stack, supporting diverse RL algorithms including parameter-efficient training methods like LoRA. This flexibility allows Echo to adapt easily to advancements in RL techniques and hardware constraints.
Experiments
Evaluation Setup
Experiments were conducted on various tasks and model scales to evaluate the performance of Echo compared to traditional co-located systems. The RL workloads used Qwen series models across diverse tasks: Sokoban, mathematical problem solving, and logical reasoning puzzles.
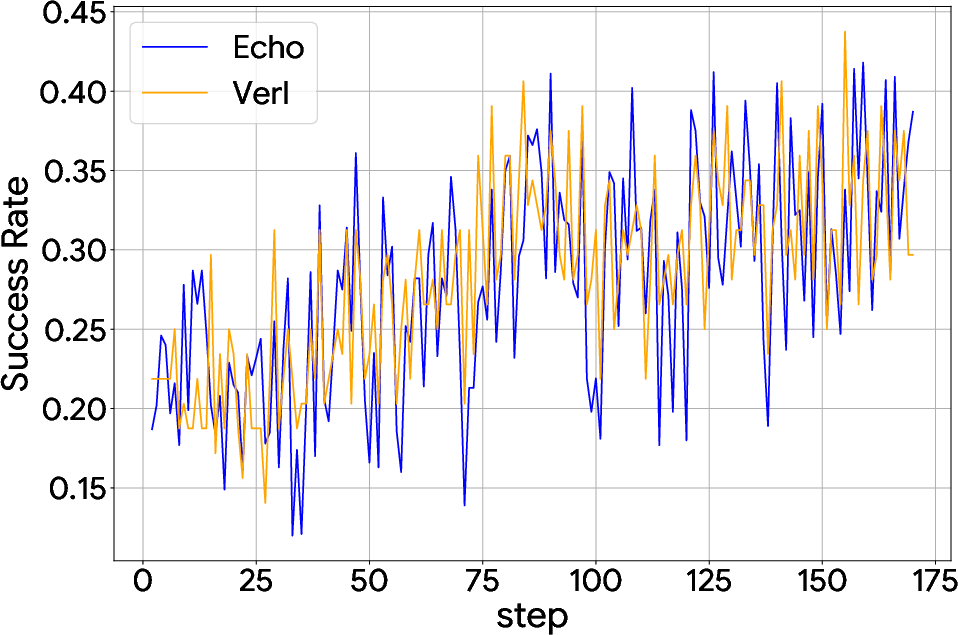
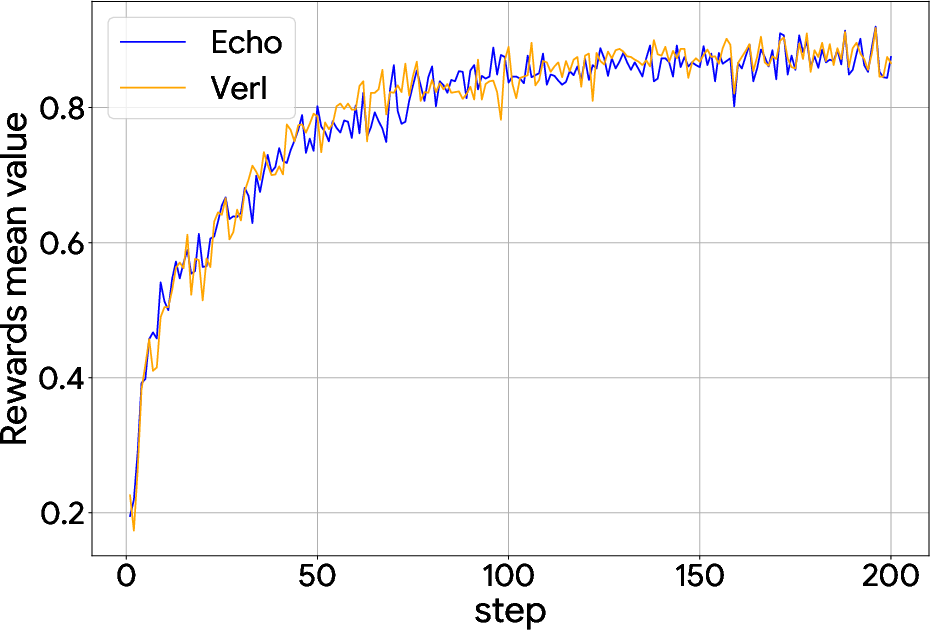
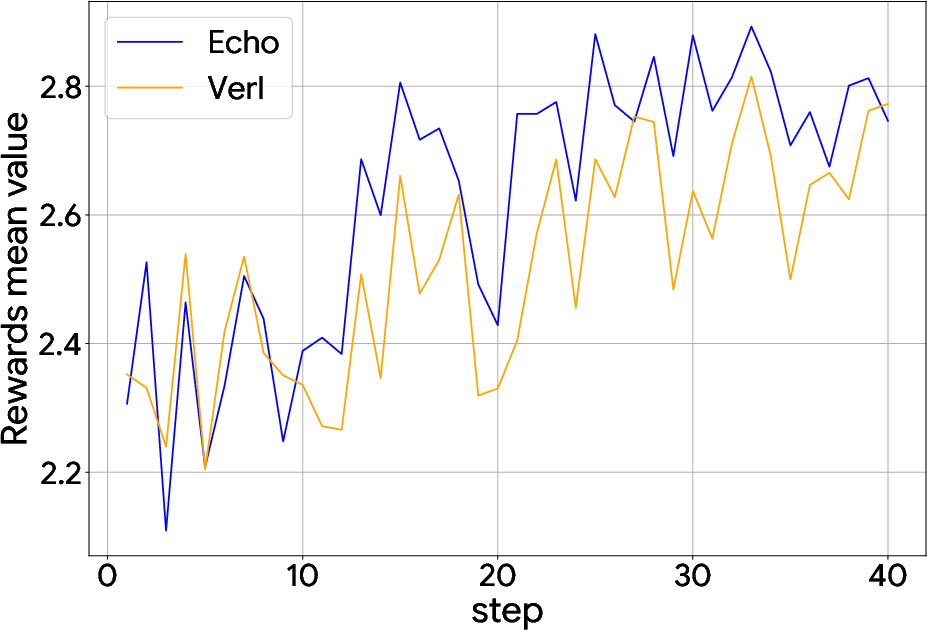
Figure 2: Sokoban w/ Qwen3-4B.
Echo demonstrated comparable convergence speed and final rewards while off-loading trajectory generation to edge devices. In particular, experiments showed significant performance improvements across different tasks by leveraging decentralized hardware resources.
Sokoban Task: Echo enhanced success rates by effectively utilizing heterogeneous devices, with Qwen3-30B-A3B-Thinking-2507-Echo surpassing other state-of-the-art models.
Mathematical Reasoning: Using Echo, Qwen2.5-7B achieved improvements over larger baseline models on benchmark datasets.
Figure 3: Sokoban Environment.
Logic Puzzles: With GRPO and LoRA training, Echo's performance in complex reasoning tasks displayed superior accuracy, particularly in challenging multi-agent scenarios.
Conclusion
Echo provides a viable architecture for RL training on decentralized resources, matching or surpassing conventional datacenter performance metrics. Its design demonstrates the potential for large-scale RL utilizing geographically dispersed hardware.
Future Work
Future developments will focus on enhancing model-parameter synchronization by:
- Adaptive Synchronization Policies: Using runtime statistics to dynamically adjust synchronization frequency, minimizing unnecessary data transfers.
- Communication-Efficient Encoding: Implementing model compression techniques to reduce synchronization volumes, enabling broader deployment possibilities on diverse edge devices.
These optimizations aim to further extend Echo's capabilities, supporting a wider array of computation environments.