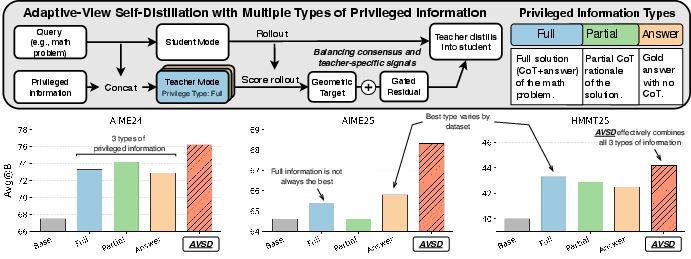
AVSD: Adaptive-View Self-Distillation by Balancing Consensus and Teacher-Specific Privileged Signals
Abstract: Self-distillation enables LLMs to learn on-policy from their own trajectories by using the same model as both student and teacher, with the teacher being conditioned on privileged information unavailable to the student. Such information can come in different types or views, such as solutions, demonstrations, feedback, or final answers. This setup provides dense token-level feedback without relying on a separate external model, but creates a fundamental asymmetry: the teacher may rely on view-specific information that the student cannot access at inference time. Moreover, the best type of privileged information is often task-dependent, making it difficult to choose a single teacher view. In this work, we address both these challenges jointly by introducing AVSD (Adaptive-View Self-Distillation), a novel method of self-distillation with multiple privileged-information views, which reconstructs token-level supervision by separating stable cross-view consensus from view-specific residual signals. AVSD identifies the consensus signal shared across views, which provides a reliable update direction, and then selectively adds the view-specific residual signal to adjust the update magnitude when it both aligns with the consensus direction and remains proportionate to the consensus signal. Experiments on math competition benchmarks (AIME24, AIME25, and HMMT25) show that AVSD consistently outperforms both single-view self-distillation baselines and GRPO, achieving average Avg@8 gains of 3.1% and 2.2% over the strongest baselines on Qwen3-8B and Qwen3-4B, respectively. Moreover, on code-generation benchmarks (Codeforces, LiveCodeBench v6) using Qwen3-8B, AVSD outperforms the single-view self-distillation baseline by 2.4% on average.



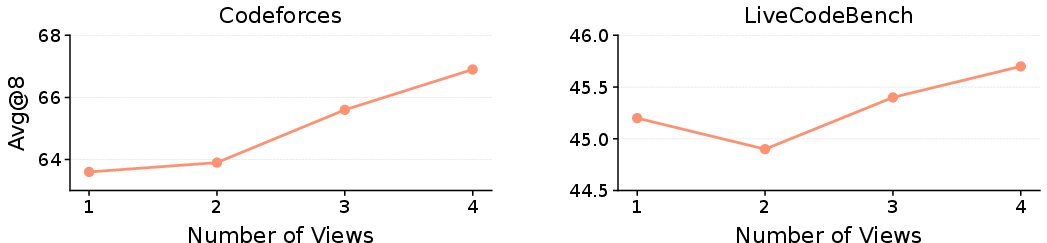
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (in simple terms)
This paper shows a better way to help an AI learn to solve tough problems (like competition math or coding) by learning from its own attempts. Instead of having one “teacher” version of the AI that sees just one kind of special hint (like the final answer or a full solution), the authors let the teacher see several different kinds of hints at once. Then they combine these hints in a smart way so the student AI learns what lots of hints agree on, and only adds extra, view-specific advice when it’s safe to do so. They call this method AVSD, short for Adaptive-View Self-Distillation.
The big questions the paper asks
- If different types of training hints exist (full solution, partial reasoning, final answer), which is the best to learn from?
- Can we use multiple hint types together so the AI gets strong, reliable guidance without being misled by any one hint type?
- How do we turn those multiple hints into step-by-step guidance for each word or symbol the AI writes?
How the method works, with simple analogies
Think of training the AI like coaching a student writer:
- The student writes an answer (its own attempt).
- Several teachers read the same draft, but each teacher has a different kind of extra info:
- One sees a full worked solution.
- One sees only the final answer.
- One sees a short hint or partial reasoning.
Each teacher suggests which words or steps in the draft should be encouraged or discouraged. The challenge: sometimes one teacher’s advice depends on secret info the student won’t have during real tests. So we need to combine advice carefully.
Here’s the core idea:
- Consensus signal (what most teachers agree on): This is like “common advice.” If many teachers nudge the same word/step in the same direction, that’s probably safe and useful. The paper captures this with a “geometric consensus” target, which mathematically emphasizes agreement across teachers and downplays anything one teacher alone pushes.
- Residual signal (extra, teacher-specific tips): Sometimes one teacher has a unique, useful tip that others don’t emphasize. The “arithmetic average” preserves these one-off boosts. The “residual” is the extra push you get from at least one teacher beyond the group’s shared advice.
- A safety gate that decides when to add the extra (residual) advice:
- Alignment check: Do the teachers mostly point in the same direction for this word/step? If they disagree, we don’t trust the extra tip.
- Size check: Is the extra tip modest compared to the shared advice? If the extra tip is too big, it could overpower the group and flip the decision—so we shrink or block it.
Putting it together:
- Start with the consensus (the shared, safe advice).
- Add the extra, view-specific advice only if: 1) teachers broadly agree on direction, and 2) the extra is not too large.
- Train the student to adjust the probability of each next word/step based on this gated advice. This is called “on-policy” learning because the student learns from its own attempts, not from a separate dataset of someone else’s solutions.
Why “token-level” matters: The AI writes answers one “token” (a word, symbol, or piece of a word) at a time. AVSD gives feedback for each token, so the model learns exactly which parts of its thinking to strengthen or weaken, rather than only getting a thumbs-up/down at the end.
What they found and why it matters
The authors tested AVSD on tough math (AIME 2024, AIME 2025, HMMT 2025) and coding (Codeforces, LiveCodeBench) benchmarks using several models. Key results:
- AVSD beat both:
- Single-view self-distillation (learning from only one hint type).
- GRPO (a popular reinforcement learning method that often gives only end-of-answer rewards).
- The gains were consistent across different model sizes and tasks. On average, AVSD improved accuracy by a few percentage points over strong baselines, which is meaningful on hard benchmarks.
- Analyses showed:
- Using only consensus is too cautious (you lose helpful unique tips).
- Using only the permissive average is too noisy (you risk following misleading, view-specific quirks).
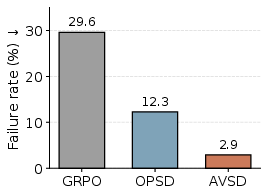
- AVSD’s gated combination is best: it gives more reliable token-level “credit assignment,” meaning it’s better at telling which parts of an incorrect answer to discourage and which parts of a correct approach to encourage.
- Adding more hint types generally helps (up to a point), because it strengthens the consensus and adds diverse, complementary tips.
Why this is important
- More reliable learning from your own attempts: AVSD gives the model dense, step-by-step guidance without needing a bigger external teacher. That can reduce training cost and make learning more stable.
- Better use of diverse training signals: Real datasets often include different kinds of information (full solutions, partial steps, final answers, test feedback). AVSD shows how to blend them so the model learns what’s truly useful and broadly agreed upon, while still benefiting from unique hints—safely.
- Stronger reasoning in math and code: The method improves on competitive benchmarks, suggesting it could help future systems reason more carefully and fix their own mistakes more effectively.
Simple takeaways
- Don’t rely on one kind of hint; combine many.
- Trust what multiple hints agree on.
- Only add unique, view-specific tips when they don’t conflict and aren’t overpowering.
- This balanced approach helps AI learn better, faster, and more safely from its own work.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of the key gaps and open problems left unresolved by the paper that future work could address.
- Theoretical guarantees: no convergence analysis or optimality characterization of the gated reconstruction (e.g., conditions under which AVSD provably improves over single-view or simple averaging, or bounds on regret/variance of the token-level advantage).
- Mutual-information leakage: no formal guarantee that the gate meaningfully reduces privileged-information leakage; no quantitative MI estimate or causal analysis verifying reduced reliance on view-specific artifacts.
- Gate design sensitivity: no study of sensitivity to the gate’s hyperparameters (e.g., epsilon), functional form, or stability across tasks/models.
- Learnable vs analytic gates: the gate is hand-designed; no exploration of learned/token-wise/meta-learned gates, instance-level gates, or adaptive temperature/regularization schedules.
- Alternative aggregations: no comparison to other multi-teacher fusion rules (e.g., temperature-scaled product-of-experts, power means, logit-space learned mixtures, Bayesian model averaging, confidence-weighted aggregation).
- Noisy or adversarial views: robustness to incorrect, noisy, or adversarial privileged views is not tested; unclear how consensus/residual behaves when some views are systematically wrong or biased.
- Heterogeneous view quality: no mechanism to weight views by estimated quality, uncertainty, or relevance; all views are implicitly treated as equally trustworthy.
- View diversity measurement: no metric for view independence/diversity or empirical link between view diversity and performance; unclear when adding a view helps vs harms.
- Scaling to many views: experiments cap at M=4; no analysis of computational scaling, memory footprint, or accuracy/efficiency trade-offs as M grows large.
- Compute- and energy-normalized comparisons: overhead is qualitatively described as “modest,” but no FLOPs, wall-clock, memory, or energy breakdowns vs baselines (especially for long trajectories and large M).
- Prefill-only assumption: the practicality of prefill-only multi-view evaluation at every prefix is not quantified for long contexts; memory/latency implications and batching limits are not explored.
- Dataset construction of views: procedures for creating partial solutions, algorithmic hints, and execution feedback are not rigorously specified nor stress-tested across diverse datasets/domains.
- Availability constraints: AVSD assumes access to verified solutions/answers or reference implementations; no pathways for weak/noisy labels or settings where such privileged artifacts are scarce or unavailable.
- Generality beyond verifiable tasks: applicability to non-verifiable, open-ended tasks (dialogue, instruction following, safety alignment) is untested; unclear how to define “views” and evaluate correctness without verifiers.
- Domain coverage: evaluation is limited to math/code; no tests on other reasoning-heavy or multimodal tasks (e.g., scientific QA, planning, theorem proving, VLMs).
- Multilingual and cross-domain generalization: no evidence for transfer across languages, domains, or problem styles; sensitivity to domain shifts is unstudied.
- Baseline choice fairness: OPSD uses a fixed single privileged view (full solution/reference impl); no “best-single-view-per-dataset” oracle baseline, which may narrow reported gains.
- Missing RL/hybrid baselines: no comparison to stronger RL and hybrid RL–distillation methods (e.g., PPO variants, DAPO/step-DPO, RLAIF, RLSD), or to RLSD variants that explicitly anchor direction with rewards.
- Combination with RL: although claimed complementary, AVSD is not combined with GRPO/RLVR; open question whether AVSD+RL yields additive or synergistic gains.
- Statistical rigor: no confidence intervals, multiple-seed variability, or significance testing; especially important for small test sets like AIME and for modest deltas.
- Decoding sensitivity: no robustness study across temperatures, top-p, or sampling strategies; unclear whether AVSD’s gains persist under different inference settings.
- Correct-rollout credit: token-level sign analysis focuses on incorrect rollouts; missing complementary analysis showing that AVSD consistently rewards high-impact tokens in correct rollouts.
- Diversity vs conservatism: consensus may over-penalize diverse reasoning paths; no evaluation of output diversity, exploration, or mode collapse effects.
- Calibration and likelihood quality: no assessment of whether AVSD improves probability calibration, entropy, or alignment of token likelihoods with correctness.
- Noisy verifiers and flaky tests: code experiments assume reliable test feedback; robustness to flaky tests, partial coverage, or non-deterministic environments is untested.
- Data leakage/contamination: no audit ensuring training privileged artifacts don’t overlap with evaluation problems/solutions; critical for competition-style benchmarks.
- Memory footprint: no reporting of peak GPU memory for multi-view teacher evaluations per step; may limit applicability to longer contexts or larger M.
- Instance-level view selection: AVSD gates residuals at the token level but always evaluates all views; no policy for instance-level view selection to cut compute or emphasize the most informative views.
- View scheduling/curriculum: no exploration of curricula that stage or adapt view usage over training (e.g., start with robust consensus, gradually introduce riskier views).
- Failure modes analysis: limited qualitative failure analysis; no systematic taxonomy of when consensus harms (e.g., shared teacher biases) or when residuals mislead despite the gate.
- Hyperparameter ranges: training/eval hyperparameters are deferred to the appendix; no systematic sensitivity analysis or ablation on key knobs (learning rate, KL coefficients, sequence length).
- Upper bounds on gains: diminishing returns with added views are observed but not characterized; unclear when the marginal benefit saturates or reverses.
- Interpretability of gate decisions: beyond a single visualization, no quantitative analysis of which token categories (operators, numbers, syntax) most benefit from residual gating, or how gate behavior correlates with error types.
- Practical deployment: no discussion of serving-time constraints (e.g., whether any privileged precomputation is needed), or how to operationalize AVSD in resource-constrained pipelines.
Practical Applications
Immediate Applications
Below are concrete, deployable use cases that can leverage the AVSD method today, organized by sector and setting. Each item highlights potential tools/workflows and the key assumptions or dependencies to watch.
- Software engineering (developer productivity and CI/CD)
- Self-improving code assistants
- Workflow: Incorporate unit-test execution feedback, algorithmic hints, and reference implementations as privileged views during fine-tuning of code LLMs. Use AVSD to train a single model that generalizes at inference without test access.
- Tools/products: IDE plugins that regularly fine-tune local/enterprise models with “multi-view packs” (reference solution + test results + reviewer comments).
- Assumptions/dependencies: Availability of tests/reference solutions or ability to synthesize hints; compute budget for on-policy rollouts; data governance for internal code.
- CI-integrated model refinement
- Workflow: In CI pipelines, store multiple views from code reviews, tests, and golden solutions; periodically run AVSD to improve an internal code-gen model.
- Tools/products: “AVSD Trainer” module for MLOps/TRL-style libraries; privileged view cache and test-runner connectors.
- Assumptions/dependencies: Continuous capture of multi-view artifacts; stable evaluation harnesses.
- Education (math and STEM tutoring)
- Multi-format tutor distillation
- Workflow: Train math-tutoring models using multiple views (full solutions, partial rationales, final answers) curated from existing problem banks; deploy the distilled student as a tutor that gives stepwise hints without needing the full solution at inference.
- Tools/products: “Tutor Distillation Pipeline” that ingests problem sets and auto-generates partial rationale and answer-only views; LMS integration.
- Assumptions/dependencies: Access to solutions/answers; reliable view generation (e.g., truncating solutions to form partial rationales); alignment with academic integrity policies.
- Enterprise knowledge work (internal LLMs with artifacts)
- Domain adaptation using heterogeneous supervision
- Workflow: Use internal artifacts—e.g., SOPs, checklists, FAQs (final answers), detailed postmortems (full solutions), and quick-start guides (partial/hints)—as privileged views to fine-tune reasoning for support and operations tasks.
- Tools/products: Knowledge ingestion pipelines that tag documents by “view type” and schedule AVSD runs over on-policy samples.
- Assumptions/dependencies: Document classification into views; permissioning; consistent formatting for prefill.
- Research and academia (LLM training & eval)
- Better token-level credit assignment for verifiable tasks
- Workflow: Replace sparse RL reward-only routines with AVSD or combine with RL; use multiple privileged views to stabilize update directions in math/code benchmarks.
- Tools/products: Open-source AVSD training recipes; ablation kits to compare consensus-only vs arithmetic-only vs gated reconstruction.
- Assumptions/dependencies: Benchmarks with verifiable endpoints; ability to parallelize teacher-view prefills.
- Daily life (end-user assistants)
- More reliable math helpers and coding copilots
- Workflow: Vendors fine-tune small/medium LLMs with AVSD using public problem sets and test suites; deploy assistants that show improved correctness without needing chain-of-thought at inference.
- Tools/products: Lightweight models served on-device or in-browser, updated periodically via AVSD.
- Assumptions/dependencies: Public datasets with multi-view signals; responsible handling of generated rationales.
- Data operations and content pipelines
- Multi-view dataset curation
- Workflow: For new tasks, standardize collection of multiple supervision views (answer-only, partial reasoning, full solutions, rubric-based feedback); store as training-time privileged contexts.
- Tools/products: View generators (extract answers; truncate chains; auto-hinting); schema for view metadata.
- Assumptions/dependencies: Quality control of generated views; versioning; deduplication.
- Model training efficiency and governance
- Cost-effective post-training without larger teachers
- Workflow: Use a single model as both student and teacher with multiple privileged views; avoid reliance on external larger teacher LMs.
- Tools/products: AVSD adapters for popular training stacks; caching strategies for multi-view prefill.
- Assumptions/dependencies: Sufficient base-model capability; modest extra compute for multi-view teacher prefills; careful batching.
Long-Term Applications
These use cases will benefit from further research, broader validation beyond math/code, or engineering to scale and generalize.
- Healthcare (clinical reasoning and decision support)
- Multi-view distillation from clinical artifacts
- Vision: Train models with privileged views such as clinician notes (full rationale), final diagnoses, and structured hints (differential heuristics) to improve token-level credit assignment while preventing view-specific leakage.
- Potential products: Internal triage assistants and case summarizers with improved reasoning reliability.
- Assumptions/dependencies: Robust de-identification; regulatory approvals; rigorous validation; carefully constructed views to avoid unsafe hallucinations; domain shift beyond math/code.
- Finance (analyst support and report generation)
- Multi-view training with compliance-aware supervision
- Vision: Use analyst rationales (full), bullet-point theses (partial), and final ratings/targets (answers) to train models that generalize without privileged data at inference.
- Potential products: Internal assistants for earnings calls and risk summaries; audit trails showing view provenance in training.
- Assumptions/dependencies: Strict data lineage; legal permissions; handling of proprietary insights; robust guardrails.
- Robotics and embodied agents
- Policy distillation with privileged sensing
- Vision: Extend AVSD-style consensus/residual gating from token distributions to action distributions, combining views from privileged sensors (e.g., ground-truth state), high-level plans, and sparse rewards to stabilize learning.
- Potential products: Sim-to-real transfer pipelines that leverage privileged sim signals but deploy without them.
- Assumptions/dependencies: Adapting AVSD to continuous control/action spaces; reliable multi-view construction in RL; safety validation.
- Multi-modal and agentic systems
- Cross-view supervision across text, vision, and tool feedback
- Vision: Aggregate privileged views such as tool traces, verifier outcomes, retrieved documents, and stepwise reasoning in multi-modal tasks (e.g., chart understanding, data wrangling).
- Potential products: Data analysis copilots that learn from tool output + rationale + answer views; agent frameworks with gated residuals to reduce tool-specific shortcuts.
- Assumptions/dependencies: Generalizing AVSD math to multi-modal token/action spaces; robust tool-use logging and verifiers.
- Auto-generation of privileged views at scale
- View synthesis and selection
- Vision: Train auxiliary systems to automatically generate high-quality partial rationales, hints, and verifier feedback; learn to weight/route views dynamically based on alignment metrics similar to AVSD’s gate.
- Potential products: “View Factory” services attached to datasets and training runs; auto-curation of optimal view sets for new domains.
- Assumptions/dependencies: Quality and diversity of synthetic views; quality estimation; compute for large-scale view generation.
- Hybrid RL + AVSD training regimes
- Outcome-anchored, token-level credit
- Vision: Combine verifiable RL signals to fix the update direction at the trajectory level with AVSD’s gated residuals for token-level shaping; particularly useful in partially verifiable domains (subset of steps or tests).
- Potential products: Training stacks that automatically switch between reward-anchored and multi-view-distillation phases.
- Assumptions/dependencies: Reliable verifiers; curriculum strategies; stability under mixed objectives.
- Standards and policy for multi-view supervision
- Data and evaluation governance
- Vision: Establish organizational policies to retain multiple supervision views (answers, hints, rationales, test results) and document their provenance; standardize benchmarks that report token-level credit quality in addition to accuracy.
- Potential products: View-aware dataset standards; audit frameworks that track how views influence updates.
- Assumptions/dependencies: Community consensus; privacy/security; legal clarity on storing and using rationales.
- Privacy-aware training with privileged artifacts
- Controlled use of restricted views
- Vision: Use AVSD’s gated residual mechanism to minimize over-reliance on proprietary or sensitive view-specific signals, reducing leakage risk while benefiting from them during training.
- Potential products: “Compliance-safe distillation” modes that cap residual influence; differential-privacy extensions.
- Assumptions/dependencies: Formal leakage assessments; DP or auditing tools; further theoretical guarantees.
- Generalization to open-ended tasks
- Beyond strictly verifiable tasks
- Vision: Define proxy views for tasks without exact answers (e.g., summarization): editorial guidelines (full), bullet key points (partial), headline (answer), and quality ratings/edits as feedback; adapt AVSD to noisy/subjective views.
- Potential products: Content-generation models that learn consistent style and quality signals from heterogeneous editorial artifacts.
- Assumptions/dependencies: Designing reliable proxies; measuring consensus quality; handling subjective disagreement.
In all settings, feasibility improves when organizations:
- Capture and retain multiple “views” of supervision (answers, partial rationales, full solutions, tests/feedback).
- Have pipelines to generate or curate view quality, and to parallelize teacher-view prefills.
- Enforce governance for privileged data and track view provenance.
AVSD’s core insight—anchor on cross-view consensus and gate view-specific residuals—translates into practical training gains for verifiable reasoning tasks today, and offers a roadmap to extend multi-view supervision to broader, multi-modal, and safety-critical domains.
Glossary
- Advantage: The token-level signal indicating how much to promote or suppress a token based on teacher vs. student probabilities. " in Eq.~\eqref{eq:advantage} is the token-level distillation advantage."
- Alignment component: A gating factor measuring cross-view agreement by comparing the magnitude of the averaged signed advantage to the average per-view magnitudes. "We define the alignment component by the ratio between the magnitude of the averaged signed advantage and the average magnitude of the per-view advantages:"
- Arithmetic-geometric mean inequality: A mathematical inequality used to show the residual’s non-negativity when comparing arithmetic and geometric aggregates. "It is non-negative by the arithmetic-geometric mean inequality"
- Arithmetic marginal target: The pooled teacher distribution formed by averaging view-conditioned teachers, preserving tokens strongly supported by any view. "The arithmetic target preserves complementary support that appears in only one or a few views"
- Avg@8: An evaluation metric averaging accuracy over the top-8 samples or attempts. "achieving average Avg@8 gains of 3.1\% and 2.2\%"
- Consensus signal: The shared update direction across views that provides reliable supervision. "AVSD identifies the consensus signal shared across views"
- Cross-view residual: The extra support present in the arithmetic marginal but absent from geometric consensus; used to adjust update magnitude. "We call the cross-view residual"
- Forward-KL: The forward Kullback–Leibler divergence, used in aggregating teacher distributions by minimizing average divergence from teachers to the pooled target. "the average forward-KL aggregation problem"
- Geometric consensus target: The pooled teacher distribution using the geometric mean, emphasizing tokens supported across all views. "We call the geometric consensus target"
- GRPO (Group Relative Policy Optimization): A reinforcement learning algorithm using group-based relative rewards for optimization. "GRPO~\citep{shao2024deepseekmath}, group relative policy optimization with binary outcome rewards verified against ground-truth answers,"
- Log-derivative form: A formulation of the reverse-KL objective that expresses gradients via log-derivatives, enabling policy-gradient style updates. "using the log-derivative form of the reverse-KL objective"
- Mutual-information gap: An irreducible mismatch when imitating a teacher with access to privileged information that the student lacks. "an irreducible mutual-information gap"
- Off-policy: Training on data not generated by the current student policy, leading to distribution mismatch. "On-policy distillation addresses this off-policy issue"
- On-policy distillation: Distillation that trains on trajectories sampled from the current student policy to reduce mismatch. "On-policy distillation addresses this off-policy issue"
- On-policy self-distillation: A setup where the model acts as both student and teacher on its own rollouts, with the teacher given privileged information. "an on-policy self-distillation framework"
- Policy-gradient form: An expression of gradients as expectations over actions weighted by advantages. "in policy-gradient form as"
- Prefill-only forward passes: Non-autoregressive forward evaluations that compute teacher probabilities over a fixed student-generated prefix. "the additional view-conditioned teacher evaluations are prefill-only forward passes"
- Privileged information: Training-time information available to the teacher but not to the student at inference (e.g., solutions, answers, feedback). "privileged information unavailable to the student"
- Privileged view: A specific type or format of privileged information provided to the teacher (e.g., full solution, final answer). "different privileged views"
- Reinforcement learning with verifiable rewards (RLVR): RL methods that use rewards derived from verifiable outcomes in tasks like math or code. "Reinforcement learning with verifiable rewards (RLVR)~\citep{shao2024deepseekmath, deepseekai2025deepseekr1} has become the dominant paradigm"
- Residual gate: A mechanism that controls how much of the residual signal is added to the consensus to prevent direction flips or domination. "Residual Gate."
- Reverse-KL: The reverse Kullback–Leibler divergence, used to align the student to the teacher by penalizing deviations from teacher probabilities. "The single-view reverse-KL~\citep{gu2024minillm, agarwal2024onpolicy} objective is"
- Rollout: A sequence generated by the student policy during training, used for on-policy learning. "we sample an on-policy rollout"
- Single-view self-distillation: Self-distillation that relies on one fixed type of privileged context throughout training. "the standard single-view self-distillation baseline"
- Stop-gradient operator: An operator that treats certain quantities as constants during backpropagation to prevent gradient flow. " is the stop gradient operator."
- Teacher family: The set of teacher distributions induced by multiple privileged views, collectively providing supervision. "the teacher family provides a stable signal"
- Token-level supervision: Fine-grained training signals applied at each token rather than only at sequence outcomes. "which reconstructs token-level supervision"
- View-conditioned teacher: A teacher distribution obtained by conditioning the same model on a particular privileged view. "the normalized geometric mean of the view-conditioned teachers."
Collections
Sign up for free to add this paper to one or more collections.