- The paper introduces a training-free pipeline that integrates scene perception, anchor-guided alignment, and VLM-driven physical simulation for realistic multi-object video synthesis.
- The methodology decouples physical simulation from photorealistic rendering through explicit mechanical reasoning, minimizing interpenetration and ensuring precise geometry and pose alignment.
- Experimental results demonstrate superior semantic adherence (3.29/5), enhanced physical coherence (3.15/5), and real-time interactive rendering at approximately 15 FPS on complex scenes.
TelePhysics: A Physics-Grounded Framework for Multi-Object Scene Generation and Controllable Video Synthesis from a Single Image
Introduction
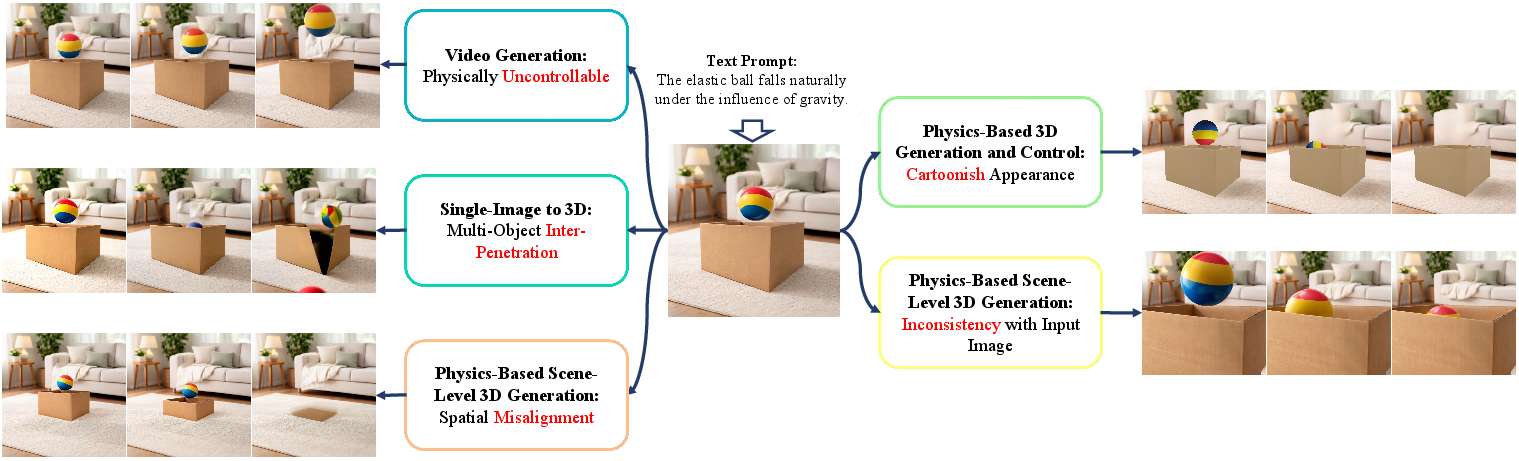
TelePhysics proposes a training-free pipeline for generating dynamic, physically plausible video sequences from a static single input image by reconstructing a holistic, mechanically coherent 3D scene representation. Previous generative video and scene-level 3D methods lack explicit physical control, suffer from object interpenetration, spatial misalignment, and often exhibit stylized, inconsistent appearance or geometry that deviates from the input image. TelePhysics targets these limitations via unified scene perception, anchor-guided multi-object alignment, VLM-driven physical parameter inference, explicit physics-based simulation, and high-fidelity, real-time photorealistic rendering.

Figure 1: TelePhysics is a unified, training-free framework designed to facilitate holistic 3D scene generation and physically grounded video synthesis from a single input image. The figure showcases interactions among multiple objects across diverse scenes.
Limitations of Existing Paradigms
State-of-the-art appearance-driven video generation and 3D lifting pipelines are fundamentally decoupled from the underlying laws of physics, with five key deficits:
Pipeline Overview and Technical Contributions
TelePhysics introduces a modular pipeline with explicit mechanical reasoning, decoupling physical simulation from high-dimensional appearance modeling. The architecture comprises four sequential modules:
- Scene Perception: Instance segmentation and mask-based mesh reconstruction for all foreground entities with generative background inpainting/outpainting, ensuring separation and eliminating interpenetration.
- Scene Alignment: Multi-object meshes are aggregated, anchor-based ground plane estimation and rigid transformation (Anchor-Guided Manifold Fitting; AGMF), and camera pose refinement by a differentiable, region-aware, coarse-to-fine optimization strategy achieves global geometric and photometric consistency in a world coordinate system.
- Physical Simulation: VLMs (Qwen2.5-VL-72B-Instruct) automatically infer per-entity material/physical parameters, solved by a GPU-accelerated multi-physics backend (Genesis), assigning RBD, MPM, or PBD solvers per material for synchronous interaction and trajectory computation.
- WonderTrace Video Generation: Interpreter renders physically simulated trajectories to photorealistic and temporally coherent videos via partial denoising diffusion with real-time efficiency.
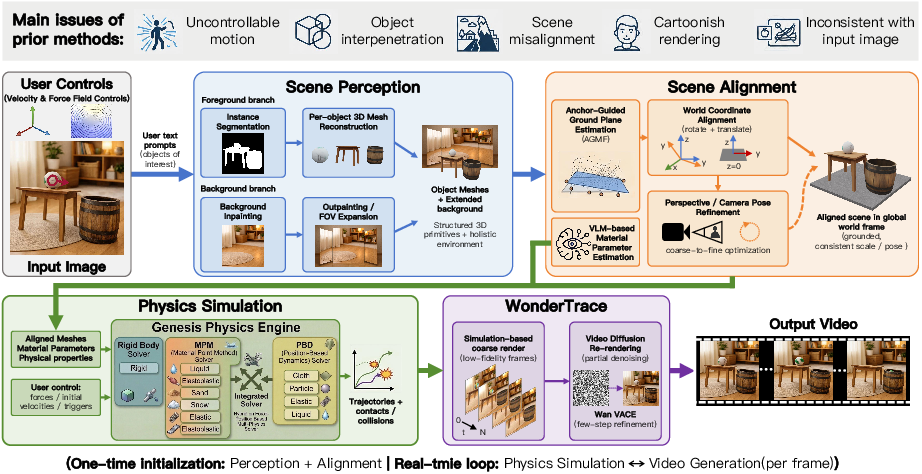
Figure 3: The TelePhysics pipeline with four stages: (a) perception and explicit mesh construction, (b) world-frame alignment and camera pose optimization, (c) physical simulation, and (d) photorealistic refinement for video synthesis.
Scene-Aware Multi-Object Alignment
The AGMF algorithm disambiguates ground planes by isolating object-specific geometric extrema, targeting true support manifolds and robustly handling vertical structure distractors (e.g., human torsos). This decisively mitigates prevalent errors of vanilla RANSAC approaches.
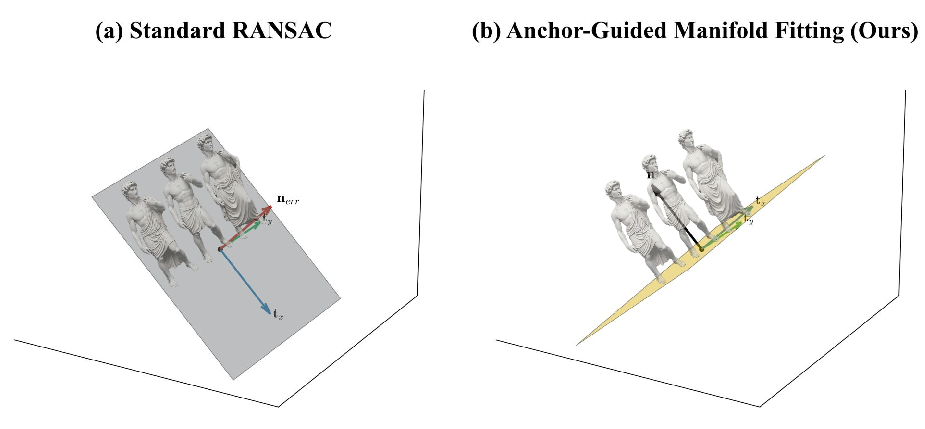
Figure 5: Comparison of plane estimation: left, standard RANSAC aligns with vertical structures; right, AGMF isolates ground contact points for physically plausible global alignment.
Subsequent perspective and camera pose refinement is driven by a composite photometric-geometric loss, using global random search for robust initialization and Powell's method for local minimum convergence. This ensures fine alignment between simulated scene renders and the true input image, a critical element for high-fidelity downstream rendering and simulation accuracy.
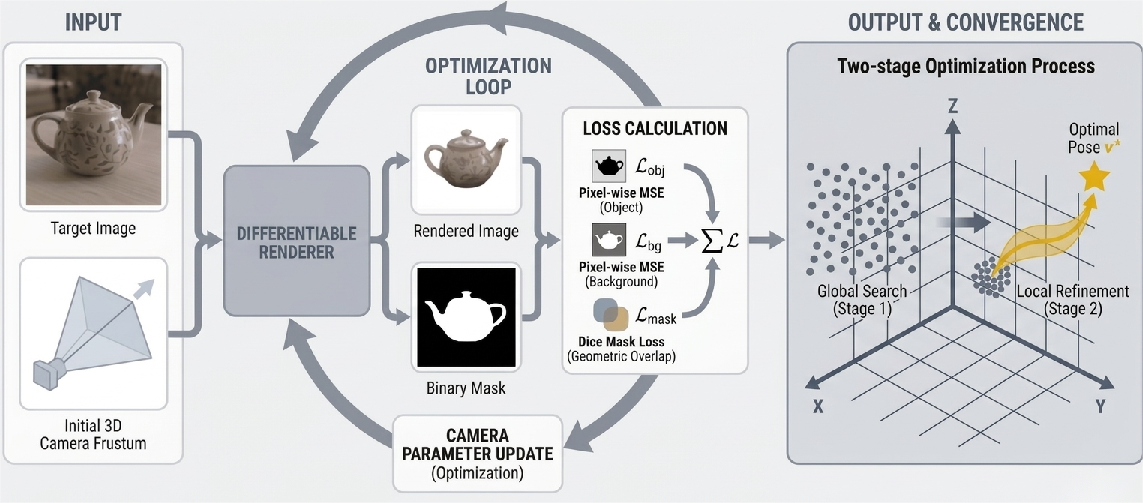
Figure 4: Differentiable rendering-based camera pose optimization pipeline, illustrating convergence from stochastic sampling to precise alignment.

Figure 6: Qualitative evolution of scene-camera alignment, reducing rendering loss—rows show input, render, and masks—with robust global-to-local optimization.
Physics-Based Simulation and Material Inference
Physical properties (mass, stiffness, friction, etc.) are automatically predicted via a VLM prompt and assigned to explicit meshes. The simulation backend (Genesis) fuses RBD for rigid, MPM for hyperelastic/fluid, and PBD for thin-shell/cloth entities with GPU-parallel updates and adaptive time-stepping. Mechanical events (e.g., collisions, stacking, deformation) are resolved in the unified world frame, supporting deterministic replay and events with real-time force field injection.
Photorealistic and Consistent Re-Rendering
WonderTrace transforms raw engine renderings, often synthetic and lacking realism, into temporally coherent, photorealistic video sequences via conditional, partial denoising diffusion. Condition inputs include RGB, depth, optical flow, and masks, with inference accelerated by initiating from physics renders rather than random noise—preserving structural events with low-latency, and supporting arbitrary camera navigation due to the panoramic, inpainting-augmented background.

Figure 7: Illustration of the support for arbitrary camera motion and viewpoint—enabling seamless, physically consistent parallax and scene expansion.
Experimental Evaluation
TelePhysics is benchmarked on a 60-scene, multi-object test set with complex events: collision, stacking, rolling, and support. Qualitative comparison demonstrates:
Quantitatively, TelePhysics yields the strongest semantic adherence (3.29/5) and physical commonsense (3.15/5) (GPT-5 Likert protocol), competitive video quality (3.61/5), and receives maximal human study preference scores (6.93/7). Runtime analysis reports: full scene perception and alignment in ~46s/scene, real-time interactive physics at ~15 FPS, and high-fidelity video synthesis completed with 10 diffusion steps for optimal structural metrics.
Ablation Analysis
Modular ablations demonstrate:
- AGMF-based alignment eliminates interpenetration, achieves peak mask IoU, and enables high interaction success rates, highlighting the necessity of anchor-based layout.
- Coarse-to-fine camera optimization produces lowest reprojection errors and highest geometric consistency (Mask IoU 0.54).
- Force field configuration: Excluding physically plausible forces boosts naive motion amplitude but violates realism; explicit physical solvers are essential for mechanically meaningful outcomes.
- Real-time video synthesis: 10 denoising steps balance SSIM/LPIPS favorably to deeper diffusion passes.
Robustness to Challenging Dynamic Interactions
TelePhysics seamlessly handles complicated dynamic multi-object events such as sequential collisions, stacked assemblies, and simulated fluids. The pipeline maintains strict adherence to input image constraints, dynamic interactions, and precise spatial correspondence, even under occlusion or ambiguous viewpoints.

Figure 9: TelePhysics maintains robust, physically plausible scene dynamics in complex, multi-agent interaction scenarios.
Implications, Limitations, and Future Outlook
TelePhysics establishes a generic framework for controlled 3D scene synthesis from minimal visual input, with potential to support physically accurate animation, robotics, digital twin systems, and embodied AI. Its capability to decouple physical simulation from rendering enables photorealism without sacrificing explicit control or real-time response.
Notable limitations include reliance on the accuracy of monocular segmentation, susceptibility to errors in heavily occluded or articulated contexts, challenges with transparent surfaces, and the need to heuristically initialize unobservable material parameters from single images.
Future efforts should address joint inference of geometry, material, and contacts from multimodal signals, explicit uncertainty propagation for occluded entities, and efficient end-to-end optimization for real-time photorealistic synthesis at higher spatial resolutions.
Conclusion
TelePhysics represents a cohesive, training-free paradigm for multi-object, physically grounded video generation from single images. Through anchor-guided alignment, VLM-driven inference, explicit physics, and diffusion-based photorealistic rendering, it achieves superior semantic, physical, and perceptual fidelity versus prior methods while supporting real-time interactive control. This pipeline provides a foundation for future AI systems requiring integrated physical reasoning and photorealistic scene synthesis from limited input.