RealWonder: Real-Time Physical Action-Conditioned Video Generation
Abstract: Current video generation models cannot simulate physical consequences of 3D actions like forces and robotic manipulations, as they lack structural understanding of how actions affect 3D scenes. We present RealWonder, the first real-time system for action-conditioned video generation from a single image. Our key insight is using physics simulation as an intermediate bridge: instead of directly encoding continuous actions, we translate them through physics simulation into visual representations (optical flow and RGB) that video models can process. RealWonder integrates three components: 3D reconstruction from single images, physics simulation, and a distilled video generator requiring only 4 diffusion steps. Our system achieves 13.2 FPS at 480x832 resolution, enabling interactive exploration of forces, robot actions, and camera controls on rigid objects, deformable bodies, fluids, and granular materials. We envision RealWonder opens new opportunities to apply video models in immersive experiences, AR/VR, and robot learning. Our code and model weights are publicly available in our project website: https://liuwei283.github.io/RealWonder/








Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RealWonder, a system that can turn a single picture into a realistic, moving video that reacts to real 3D physical actions—like pushing an object, blowing wind, or using a robot gripper—while running fast enough for live, interactive use.
In short: it’s like a smart video “what-if” machine. You give it a photo and tell it what action to apply (push here, wind from the left, move the camera), and it shows you what would likely happen, in real time.
What questions did the researchers ask?
- How can we make video generators react to real physical actions (like forces and robot moves), not just text or simple 2D edits?
- Can we do this fast enough for live interaction, not minutes per clip?
- Can we avoid needing huge datasets of “action + video” examples, which are hard to collect?
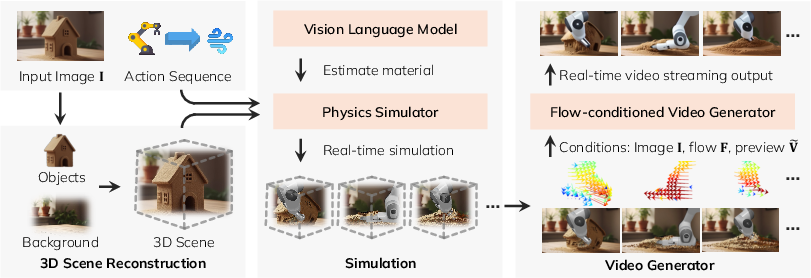
How does RealWonder work?
Think of RealWonder as a three-part pipeline that uses physics as a bridge between “actions in the real world” and “pixels in a video.”
Here’s the idea, with simple analogies:
- Rebuild the 3D scene from a single picture
- Analogy: From one photo, it creates a rough 3D model made of dots (a point cloud), separating background and objects.
- It guesses each object’s material (rigid like a mug, flexible like cloth, liquid like water, sandy like granular materials). This matters because different materials move differently when pushed.
- Simulate what happens with physics
- Analogy: Like a video game physics engine. If you press with a force, turn on a wind field, or close a robot gripper, the engine predicts how things move and collide.
- It then turns the result into two simple, visual “hints” for the video model:
- Optical flow: a motion map that shows how each pixel should move next (like tiny arrows over the image).
- Coarse RGB preview: a quick, low-detail render that shows the rough look and occlusions (who’s in front of whom).
- Generate a realistic video, fast
- Analogy: The video model is an artist who paints each frame. The physics “hints” guide the artist so the motion matches your actions.
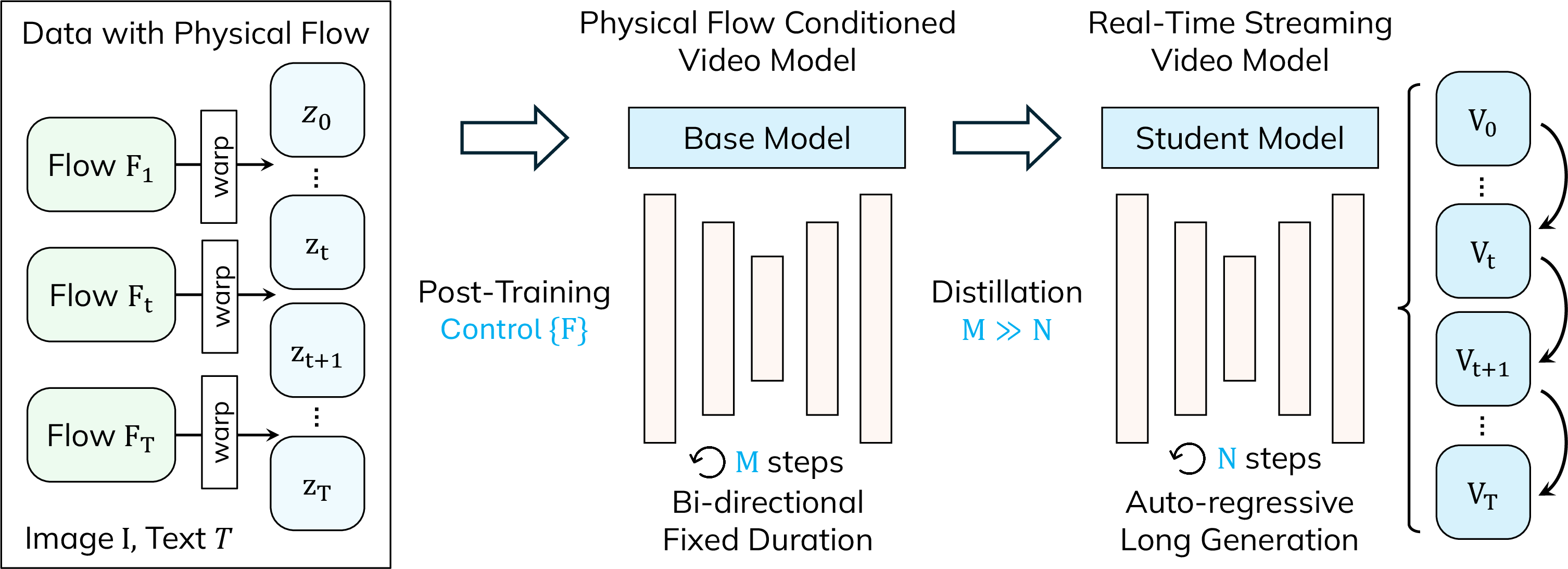
- The researchers trained the model in two steps:
- First, they taught a standard image-to-video model to follow optical flow, so it understands motion directions and speeds.
- Then, they “distilled” it into a faster student model (like a teacher–student lesson), cutting the usual 50 refinement steps down to just 4. This makes it fast enough to stream at about 13.2 frames per second at 480×832 resolution.
- During generation, the model uses both the motion map (optical flow) and the coarse preview to keep motion accurate and visuals clean.
Key terms in everyday language:
- Optical flow: a per-pixel “movement map” predicting where each pixel goes next.
- Point cloud: a simple 3D shape made of lots of points instead of a solid mesh.
- Distillation: training a smaller, faster model to imitate a bigger, slower one.
- Real time: fast enough to update interactively while you’re using it.
What did they find, and why is it important?
Main results:
- Real-time interaction: The system runs at about 13.2 FPS with a low delay, so you can apply actions (like push or wind) and immediately see the effects.
- True 3D actions: It accepts real physical actions—forces, torques, robot gripper moves, and camera motion—not just 2D drags or text prompts.
- Works across many materials: rigid objects, cloth, stretchy things, fluids (like water), and granular stuff (like sand or snow).
- Better action-following and physical plausibility: In comparisons with other methods, RealWonder more reliably shows the correct outcomes of the user’s actions and looks more physically believable.
- Strong user preference: In a study with 400 people, videos from RealWonder were preferred over baseline methods for following actions, motion realism, and physical plausibility.
- Fast and flexible: Unlike some methods that need long, heavy processing or special training pairs of actions and videos, RealWonder uses physics to “translate” actions into visual motion, which the video model can easily follow.
Why this matters:
- It bridges a gap. Most video generators can make pretty videos, but they don’t know what a push, pull, or grip means in 3D. RealWonder uses physics as a bridge to connect real actions to video motion.
- It’s scalable. Because it learns from visual motion (flow) rather than action–video pairs, it avoids a big data problem.
What could this be used for?
- Robot learning and motion planning: Try out forces and gripper moves virtually and see the likely outcomes before doing them for real.
- AR/VR and games: Make interactive scenes that react plausibly to users’ actions in real time.
- Education and storytelling: Show “what-if” physics scenarios from a single image, helping people visualize cause and effect.
- Creative tools: Let artists and designers quickly preview action-driven animations without building full 3D scenes by hand.
A quick note on limitations
- The 3D reconstruction from one image isn’t perfect, and mistakes in depth or materials can cause errors.
- The goal is “physically plausible,” not guaranteed “physically exact.” The system blends physics predictions with a learned video model, which may fill in details creatively.
Takeaway
RealWonder shows a practical way to make videos that react to real 3D actions by using physics as a translator. It runs in real time, handles many kinds of materials and actions, and produces videos that people find both realistic and responsive—opening doors for robotics, interactive media, and beyond.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Based on the paper, the following concrete gaps remain for future work:
- Single-image 3D reconstruction and scale ambiguity: reliance on monocular depth, inpainting, and single-image mesh completion leads to occlusion, scale, and intrinsics ambiguities; no mechanism to incorporate multi-view/SLAM data or to update geometry online during interaction.
- Material identification and parameters: VLM-based, six-class material assignment with homogeneous, hand-set parameters; no data-driven system identification or validation against ground-truth mechanical properties; heterogeneous and spatially varying materials are not supported.
- Physical solver fidelity and coupling: use of PBD for smoke/cloth and low-resolution MPM (grid=64) ignores turbulence, fluid–air coupling, and detailed contact/fracture; multi-material coupling is not quantitatively validated; trade-offs between fidelity and real-time speed are uncharacterized.
- Contact and friction modeling: stick–slip transitions, rolling friction, and complex contact events are simplified; no sensitivity analysis to friction parameters or metrics assessing contact realism.
- Simulator–generator causality gap: the video model “fills in” unmodeled effects (e.g., waves, splashes), risking decoupling from applied actions; there are no physics-based constraints or priors in the generator to enforce conservation or consistency.
- Distribution shift in flow conditioning: training uses RAFT-extracted flows from generic videos, while inference uses simulator-projected flows; mismatch is neither quantified nor mitigated via domain adaptation or simulator-flow–based training.
- Limited action space and embodiment: only a predefined Franka manipulator is supported; richer articulated bodies, soft/underactuated grippers, tool-use, and compliant/force-control behaviors are not explored.
- Camera motion and unseen content: single-image reconstruction and inpainting cannot reveal truly unseen regions under large camera moves; no geometry-aware novel view/content synthesis strategy is provided for significant viewpoint changes.
- Background dynamics: the background is assumed static; dynamic backgrounds and exogenous disturbances (e.g., moving crowds, traffic, weather) are not modeled or conditioned.
- Robustness to out-of-range actions: admissible ranges for forces/torques/velocities are not reported; failure modes and stabilization (e.g., adaptive substeps, action clipping) under extreme inputs are unstudied.
- Long-horizon stability and drift: although streaming is shown, there is no quantitative analysis of error accumulation, temporal drift, or quality decay over minutes-long sequences; re-anchoring or closed-loop correction mechanisms are not presented.
- Resolution/FPS scaling: results are at 480×832 and ~13.2 FPS; behavior at 1080p/4K, 30–60 FPS, and on commodity/edge hardware is not evaluated; memory/latency bottlenecks and compression strategies remain open.
- Cold-start latency and deployment: scene reconstruction takes ~13.5 s and material estimation relies on GPT-4V; strategies for low-latency or on-device initialization for AR/VR/robotics are not addressed.
- Lack of standardized benchmarks: evaluation uses a curated 30-image set and subjective/GPT-4o metrics; there is no public benchmark with ground-truth actions, multi-material scenes, and quantitative physical targets (e.g., trajectories, contact timings).
- Absence of physical accuracy metrics: beyond “physically plausible” perception, there is no assessment of physical correctness (e.g., mass/volume conservation, momentum/energy, terminal velocities), nor comparisons against measured trajectories.
- Uncertainty quantification: the pipeline provides no confidence estimates for reconstruction, material inference, simulation, or video outputs; uncertainty propagation and calibration (critical for planning) are missing.
- End-to-end adaptability: the pipeline is non-differentiable; there is no mechanism to adjust reconstruction/material/simulation parameters from video feedback (e.g., differentiable physics or learned surrogates for self-calibration).
- Occlusion/disocclusion handling: simulator-derived flows near motion boundaries and disocclusions can be unreliable; conditioning lacks explicit occlusion/depth masks, and the benefit of adding them is unstudied.
- Conditioning design space: only optical flow and coarse RGB previews are used; potential gains from depth, normals, segmentation, contact maps, or signed-distance fields, and their combinations, are unexplored.
- Hyperparameter sensitivity: SDEdit mixing (e.g., choice of α at step 3), diffusion step count, and flow-warping settings lack systematic sensitivity analysis.
- Data and motion priors: training data (OpenVid + T2V synthetic) may induce biases (e.g., default motion directions); bias analysis and mitigation strategies are not provided.
- Safety/ethics for downstream use: for motion planning and AR/VR, visually plausible yet physically incorrect videos can mislead users; no mechanisms to detect or flag low-physical-consistency frames are proposed.
- Inverse control: the framework maps actions to videos but does not tackle the inverse problem (deriving actions that achieve desired visual/physical outcomes) for planning or user-guided editing.
- Multi-agent and crowd interactions: interactions among multiple independent agents with their own policies/actions are not supported; coordination and collision-avoidance scenarios remain open.
- Generalization guarantees: there is no characterization of how performance degrades with scene complexity (object count, material diversity), large action magnitudes, or out-of-distribution environments.
Practical Applications
Below are the practical, real-world applications that follow directly from the paper’s findings, methods, and innovations. Each item specifies sector(s), actionable use cases, likely tools/products/workflows, and key assumptions or dependencies that could affect feasibility.
Immediate Applications
These can be deployed now using the released code and readily available tooling; they target interactive previsualization, content creation, and research workflows that do not require strict physical accuracy.
- Interactive “what‑if” physics previsualization for robotics labs
- Sector: Robotics, Software
- Use case: Rapidly explore manipulation strategies (push, grasp, lift, wind/force fields) from a single scene photo; iterate on gripper poses and camera viewpoints, and visually assess consequences before real trials.
- Tools/workflows: A ROS2 node or web dashboard wrapping RealWonder; Franka or similar robot end‑effector command inputs; on‑GPU streaming at ~13 FPS; export clips for lab review.
- Assumptions/dependencies: Visual plausibility, not engineering‑grade dynamics; single‑image 3D reconstruction and VLM‑estimated materials can introduce errors; safe use requires separating preview from execution; needs a modern GPU.
- Action‑conditioned video synthesis for robot learning data augmentation
- Sector: Robotics, ML/AI
- Use case: Generate large sets of action‑conditioned videos with optical flow “labels” to train perception models that predict motion from actions, improve affordance understanding, or pretrain vision modules.
- Tools/workflows: Batch pipeline producing {image, actions, flow, video} tuples; integrate RAFT or simulator‑projected flow; use for pretraining or curriculum learning.
- Assumptions/dependencies: Domain gap between synthetic previews and real robot data; RealWonder avoids action‑video pairs for training but still requires careful validation; videos are physically plausible but not metrically accurate.
- AR/VR “what‑if” overlays for live scenes
- Sector: AR/VR, Mobile, Creative Tech
- Use case: Users apply virtual forces or wind to a photographed scene and see real‑time outcomes (cloth fluttering, sand collapsing, liquids sloshing); camera control previews for immersive storytelling.
- Tools/workflows: ARKit/ARCore front‑end with cloud GPU; real‑time streaming; creator tools to author sequences of actions and camera paths.
- Assumptions/dependencies: Bandwidth/latency for cloud streaming; limited mobile on‑device compute; single‑image reconstruction may miss occluded geometry; visual plausibility over physical accuracy.
- Previsualization for film, TV, advertising, and games
- Sector: Media/Entertainment, Game Dev
- Use case: From a storyboard frame or reference image, preview wind effects on costumes, object hits, camera dolly moves, and simple fluid/granular behaviors in seconds instead of minutes.
- Tools/workflows: Blender/Unreal/Unity plug‑in; “RealWonder Studio” panel for action authoring; export clips for editorial/previz boards; rapid iteration on motion beats.
- Assumptions/dependencies: Not a substitute for physically‑based FX; use for ideation and shot blocking; requires pipeline integration and GPU resources.
- Physics sandbox for classrooms and outreach
- Sector: Education
- Use case: Demonstrate forces, torques, camera motion, and material responses (rigid, elastic, cloth, fluid, granular) interactively from everyday images; support inquiry‑based learning.
- Tools/workflows: Web app with sliders for wind/forces and gripper poses; shareable links for homework and labs; record short clips for reports.
- Assumptions/dependencies: Visual plausibility rather than strict numerics; clearly communicate limitations; content moderation for public deployments.
- E‑commerce and marketing product interactions
- Sector: Retail, Marketing
- Use case: Quick demos of “how it moves” (e.g., a jacket in wind, sand flowing from a toy, liquid poured from a bottle) using catalog images to boost engagement.
- Tools/workflows: Web widget backed by RealWonder; preset action templates per product category; automated clip generation for A/B tests.
- Assumptions/dependencies: Risk of misrepresentation—must disclose that visuals are illustrative; single‑image reconstruction may misinterpret hidden structure; GPU hosting costs.
- UI/UX prototyping of physics‑influenced animations
- Sector: Software, HCI
- Use case: Designers sketch 3D forces or camera moves on a static mock and instantly see motion; export short clips for design reviews.
- Tools/workflows: Figma/After Effects plug‑in; “actions panel” for force fields, gripper moves, and camera path; clip export for stakeholders.
- Assumptions/dependencies: Not bound to strict physics; depends on accurate scene segmentation and depth estimation; GPU requirement.
- Academic research on interactive video world models
- Sector: Academia
- Use case: Study physics‑aware conditioning, optical‑flow control, streaming distillation, and simulator‑to‑vision bridges; build benchmarks for action‑conditioned video tasks.
- Tools/workflows: Reproduce paper with public code/checkpoints; extend training data; evaluate human preference and VBench metrics.
- Assumptions/dependencies: Compute needs (~A100/H200 class GPUs); licensing of base models/datasets; reproducibility of simulator integrations.
- Social media content creation (“photo‑to‑motion”)
- Sector: Consumer Apps
- Use case: Turn a single photo into a fun, physics‑flavored clip (e.g., wind blowing hair or cloth, robot “picking up” an object), with text prompts for style.
- Tools/workflows: Mobile app with cloud inference; curated action templates; sharing pipelines.
- Assumptions/dependencies: Moderation, privacy, and IP; cloud costs and latency; user expectations set to “illustrative.”
Long‑Term Applications
These require further research, scaling, accuracy improvements, or more robust integration with robotics and XR systems.
- Visual MPC and closed‑loop robot planning with action‑conditioned predictors
- Sector: Robotics
- Use case: Use RealWonder‑style models inside planning loops to score candidate actions by predicted visual outcomes and constraints (e.g., “minimize spill” or “avoid occlusion”).
- Tools/workflows: Coupled simulator‑vision loop; learned reward functions over predicted video; policy search using visual objectives.
- Assumptions/dependencies: Needs tighter physical fidelity, calibration to real hardware, low latency at higher resolutions, and robust multi‑view/scene updates beyond single images.
- Physics‑aware digital twins for manufacturing/logistics
- Sector: Industrial Engineering, Digital Twins
- Use case: Quickly visualize how proposed manipulations, process changes, or airflow affect production lines and materials; stakeholder communication and rapid prototyping.
- Tools/workflows: Integrations with MES/PLM; multi‑camera scene reconstructions; hybrid simulators for higher‑fidelity rigid/fluid dynamics; versioned scenario authoring.
- Assumptions/dependencies: Must progress from “plausible” to “predictive” accuracy; multi‑sensor inputs; regulatory acceptance for any operations‑critical use.
- High‑fidelity XR training simulators (industrial safety, emergency response)
- Sector: Training/Certification, Public Safety
- Use case: Author variational scenarios (spill, wind, collapses) from site photographs; train response and hazard recognition in VR with realistic motion feedback.
- Tools/workflows: Scenario scripting over image‑based reconstructions; head‑mounted XR streaming; assessment modules.
- Assumptions/dependencies: Verified realism and domain calibration; content validation and pedagogical alignment; hardware availability and network QoS.
- Autonomous system perception pretraining on physics‑grounded video
- Sector: Robotics, Autonomous Systems
- Use case: Pretrain video models to recognize action‑consequence patterns (optical flow + RGB) for better anticipation and affordance reasoning in real environments.
- Tools/workflows: Large‑scale synthetic datasets from action programs; curriculum from simple rigid scenes to multi‑material interactions; transfer learning pipelines.
- Assumptions/dependencies: Bridging synthetic‑to‑real generalization; potential bias from single‑image reconstruction; evaluation frameworks for action adherence.
- Urban planning and public engagement “what‑if” visualizations
- Sector: Government/Policy, Civil Engineering
- Use case: Communicate qualitative effects of wind corridors, pedestrian flows, or material behavior in public spaces using approachable visuals.
- Tools/workflows: Participatory planning platforms; authoring tools for forces and camera paths on site photos; community workshops.
- Assumptions/dependencies: Non‑engineering use only unless paired with validated CFD/FEA; clear disclaimers; multi‑image/multi‑view reconstruction needed.
- Mobile/on‑device real‑time physics‑conditioned generation
- Sector: Mobile, Edge Computing
- Use case: Run reduced models on smartphones or AR glasses for live overlays (camera motion, simple force fields).
- Tools/workflows: Quantized/optimized student models; hardware acceleration (NPUs, GPUs); energy‑aware scheduling.
- Assumptions/dependencies: Significant model compression; potential quality trade‑offs; UI for robust action input; device‑specific optimizations.
- Scientific visualization front‑end for simulators
- Sector: Scientific Computing, Visualization
- Use case: Convert coarse solver outputs (flows, point clouds) into photorealistic videos that communicate phenomena to mixed audiences.
- Tools/workflows: Coupling HPC solvers to RealWonder‑like rendering; scene/material editing; provenance tracking.
- Assumptions/dependencies: Clear separation between illustrative rendering and ground‑truth science; trust and reproducibility requirements.
- Curriculum platforms for large‑scale physics education
- Sector: Education (K‑12, Higher Ed)
- Use case: Standardized modules where students author actions on photos and see plausible outcomes, reinforcing qualitative reasoning about forces and materials.
- Tools/workflows: LMS integration, class templates, analytics for learning outcomes; device‑agnostic front‑end.
- Assumptions/dependencies: Accessibility and compute logistics; teacher training; consistent disclosure of limitations.
- Creative tooling ecosystems and marketplaces
- Sector: Media/Entertainment, Creator Economy
- Use case: “Action packs” and material presets (cloth, fluid, granular) sold or shared; collaborative previz boards and camera path libraries.
- Tools/workflows: Plug‑ins for major DCC tools; cloud rendering with team collaboration; asset/version control.
- Assumptions/dependencies: Licensing of base models/datasets; content IP; cost of real‑time GPU streaming at scale.
Notes on cross‑cutting assumptions and dependencies
- Physical fidelity vs. plausibility: The system targets visually plausible outcomes, not engineering‑grade accuracy. Use in safety‑critical or compliance contexts requires additional validated simulators and calibration.
- Single‑image 3D reconstruction: Quality depends on segmentation, depth, and occlusion handling; multi‑view capture would improve robustness.
- Material estimation via VLM: Defaults may be wrong; expert overrides or measured parameters are recommended where accuracy matters.
- Compute and latency: Real‑time performance reported at ~13.2 FPS (480×832) on a single high‑end GPU; mobile or higher‑resolution deployments need optimization, compression, or cloud streaming.
- Data and licensing: Training used RAFT flows and public/synthetic video corpora; downstream products must respect dataset/model licenses and content moderation requirements.
Glossary
- 2AFC (Two-alternative Forced Choice): A psychophysics evaluation protocol where participants choose the better of two options based on a specified criterion. Example: "We employ a Two-alternative Forced Choice (2AFC) protocol."
- 3D Gaussian Splatting: A 3D representation/rendering technique that uses Gaussian primitives to model and render scenes. Example: "reconstructed 3D Gaussian Splatting particles."
- Attention sink: A stabilization trick for long-context attention that reserves tokens to absorb attention and reduce drift. Example: "and adding attention sink, similar to concurrent works~\cite{motionstream2025,liu2025rolling,infinite-forcing}."
- Autoregressive rollout: Generating sequences step-by-step where each output depends on previous outputs, often used during training to simulate deployment. Example: "with autoregressive rollout during training."
- Bidirectional model: A model that processes entire sequences with access to both past and future context simultaneously. Example: "The flow-conditioned teacher remains a bidirectional model requiring full sequence processing, incompatible with real-time streaming generation."
- Causal attention: An attention mechanism that restricts each token to attend only to past (and current) tokens, enabling streaming generation. Example: "the goal is to let the bidirectional model adapt to causal attention."
- Coarse RGB Rendering: A fast, approximate rendering of scene appearance used as a conditioning signal. Example: "Coarse RGB Rendering."
- Distribution Matching Distillation (DMD): A distillation method that aligns the student model’s output distribution with a teacher’s by minimizing a divergence measure. Example: "Following Distribution Matching Distillation (DMD)~\cite{yin2024one,yin2024improved}, we minimize the reverse KL divergence..."
- End-effector: The tool or gripper at the end of a robot arm that interacts with the environment. Example: "Robot end-effector commands specifying position, orientation, and gripper state..."
- Flow-based noise warping: A technique that warps noise according to optical flow to encode motion patterns into diffusion initialization. Example: "we employ flow-based noise warping~\cite{burgert2025go}: we sample single-frame Gaussian noise..."
- Flow conditioning: Conditioning a generative model on optical flow to control motion in generated videos. Example: "Here we describe how the model is trained to take flow conditioning"
- Flow-matching objective: A training objective that learns a velocity field mapping noise to data, often used in diffusion/flow-based generative models. Example: "We then finetune using the flow-matching objective to model the velocity field..."
- Flow-warped noise: Noise that has been warped by optical flow to reflect motion structure before denoising. Example: "instead of denoising from pure flow-warped noise $\mathbf{V}_{t,(4)} = z^{\mathbf{F}_t$ all the way..."
- Force field: A spatially distributed force (e.g., wind) applied over a region rather than at a single point. Example: "3D forces, force fields, and robot gripper actions."
- Franka: A widely used robotic arm platform often used in manipulation research. Example: "for a pre-defined robot model (e.g., Franka)"
- Friction angle: A material parameter for granular media that characterizes internal friction resistance. Example: "For granular substance, we additionally use the friction angle ."
- Genesis: A physics simulation engine used to simulate dynamics and robotics. Example: "we adopt the Genesis as the simulator~\cite{Genesis}."
- Granular materials: Collections of macroscopic particles (e.g., sand, snow) with complex flow and contact behavior. Example: "fluids, and granular materials."
- Incompressibility: A constraint that enforces constant volume (no compression), often used in fluid/smoke simulation. Example: "The constraints for smoke include incompressibility~\cite{macklin2013position}."
- Inverse kinematics (IK): The process of solving joint parameters to achieve a desired end-effector pose. Example: "through solving inverse kinematics (IK), which then drive the articulated robot model in simulation~\cite{Genesis}."
- KV cache: Cached key/value tensors from attention layers used to accelerate autoregressive inference. Example: "by storing the KV cache before RoPE~\cite{su2021roformer} is applied"
- LoRA: A parameter-efficient fine-tuning method that injects low-rank adapters into attention layers. Example: "through LoRA~\cite{hu2022lora} post-training."
- Material Point Method (MPM): A hybrid particle-grid simulation technique for continuum materials like fluids and granular media. Example: "Material Point Method (MPM) for liquid and granular materials~\cite{jiang2016material}."
- ODE trajectories: Trajectories generated by solving ordinary differential equations, used here for adapting diffusion to causal generation. Example: "we sample 2K ODE trajectories from the post-trained model mentioned above and train the student model..."
- Optical flow: A per-pixel motion field between frames indicating apparent motion in the image plane. Example: "rendering the results as optical flow and coarse RGB previews."
- Point cloud rasterization: Rendering technique that projects and shades point clouds directly to image pixels. Example: "using simple point cloud rasterization."
- Poisson's ratio: A material property describing lateral contraction relative to axial extension under load. Example: "Young's modulus , and Poisson's ratio ."
- Position-Based Dynamics (PBD): A simulation method that enforces constraints directly on positions for stable real-time dynamics. Example: "Position-Based Dynamics (PBD) for elastic bodies, cloth and smoke~\cite{bender2015position}."
- Reverse KL divergence: A divergence measure used to align model distributions by minimizing KL(model || data). Example: "we minimize the reverse KL divergence between the student's output distribution and the teacher's:"
- RoPE (Rotary Positional Embeddings): A positional encoding method for attention that rotates query/key representations by position-dependent phases. Example: "before RoPE~\cite{su2021roformer} is applied"
- SDEdit: A technique that edits images/videos by starting denoising from a noised version of a target, guiding diffusion with a reference. Example: "We incorporate this additional signal through SDEdit~\cite{meng2021sdedit} during the 4-step denoising process."
- Self Forcing: A training paradigm that stabilizes causal/streaming generation through rollout and distribution alignment. Example: "we adopt the Self Forcing training paradigm~\cite{huang2025self} with autoregressive rollout during training."
- Shape matching: A method in rigid/fluid simulation that enforces that particle clusters preserve a target shape during dynamics. Example: "rigid body dynamics through shape matching for collision handling~\cite{muller2005meshless}"
- VAE (Variational Autoencoder): A latent-variable generative model with an encoder/decoder used for compressing images/videos. Example: "where is the VAE encoder"
- VBench: A benchmark suite for evaluating video generation quality, aesthetics, and consistency. Example: "we adopt the imaging, aesthetic, and consistency metrics from VBench~\cite{huang2024vbench}."
- Vision-LLM (VLM): A model that processes both visual inputs and language to perform tasks like classification or reasoning. Example: "We employ a vision-LLM (VLM) to classify each object into one of six material categories"
- Viscosity: A measure of a fluid’s resistance to deformation or flow. Example: "These include density, friction coefficients, elastic moduli, and viscosity"
- Young's modulus: A material stiffness parameter relating stress to strain in the elastic regime. Example: "Young's modulus , and Poisson's ratio ."
Collections
Sign up for free to add this paper to one or more collections.