- The paper introduces PhysLayer, a unified framework for language-guided, depth-aware animation that achieves controllable and physically plausible video synthesis.
- It employs vision-language models, depth-discretized layered dynamics, and latent diffusion refinement to significantly improve metrics like CLIP-Similarity and FID.
- By leveraging depth-aware scaling and 2.5D rigid-body simulation, PhysLayer provides actionable insights for advancing realistic image-to-video synthesis.
PhysLayer: Language-Guided Layered Animation with Depth-Aware Physics
Introduction
PhysLayer addresses a fundamental challenge in image-to-video synthesis: combining high visual fidelity with physically plausible, controllable object dynamics, all driven by natural language. While generative video models based on diffusion or transformer architectures have improved visual realism, they often produce physically implausible motions and lack precise object control. Some recent efforts incorporate explicit physics priors, but remain restricted to 2D planar motion and do not model rich spatial or depth-aware interactions.
PhysLayer proposes a unified, language-guided, depth-aware animation framework capable of simulating realistic physical object behaviors from a single image. By integrating state-of-the-art vision-LLMs for holistic scene and material understanding, depth-discretized layered dynamics, and neural video rendering pipelines, PhysLayer delivers controllable and physically consistent video outputs with demonstrated gains in both metric and user study evaluations.

Figure 1: A showcase of PhysLayer’s core capabilities: object insertion with depth-aware collisions, controlled object manipulation with perspective scaling, and scene-consistent animation ensuring both physical plausibility and visual coherence.
Framework Architecture
The framework consists of three principal modules:
- Language-Guided Scene Understanding and Layer Decomposition: A vision-LLM (Gemini-pro-vision) interprets user prompts to identify animation tasks (object insertion, control, or removal) and infers corresponding physical properties such as material, mass, friction, and elasticity. Grounded-SAM and GeoWizard are employed for segmentation, depth, and normal estimation, creating a layered representation of the scene where spatial and physical relationships are explicit.
- Depth-Aware Layered Physics Simulation: Rigid-body physics simulation is performed in an augmented “2.5D” domain, discretizing the depth axis and simulating planar plus depth-wise motion. Perspective-consistent scaling adjusts apparent object size with depth, matching human perception under projection. Forces, initial conditions, and control actions are determined semantically from the parsed prompt, enabling high-level, human-controllable animation.
- Physics-Guided Video Synthesis: Rendered object transformations are composited on an inpainted and intrinsically decomposed background. A relighting module applies physically consistent shading based on depth and normals, followed by latent diffusion-based refinement to ensure spatial coherence and visual realism over time.
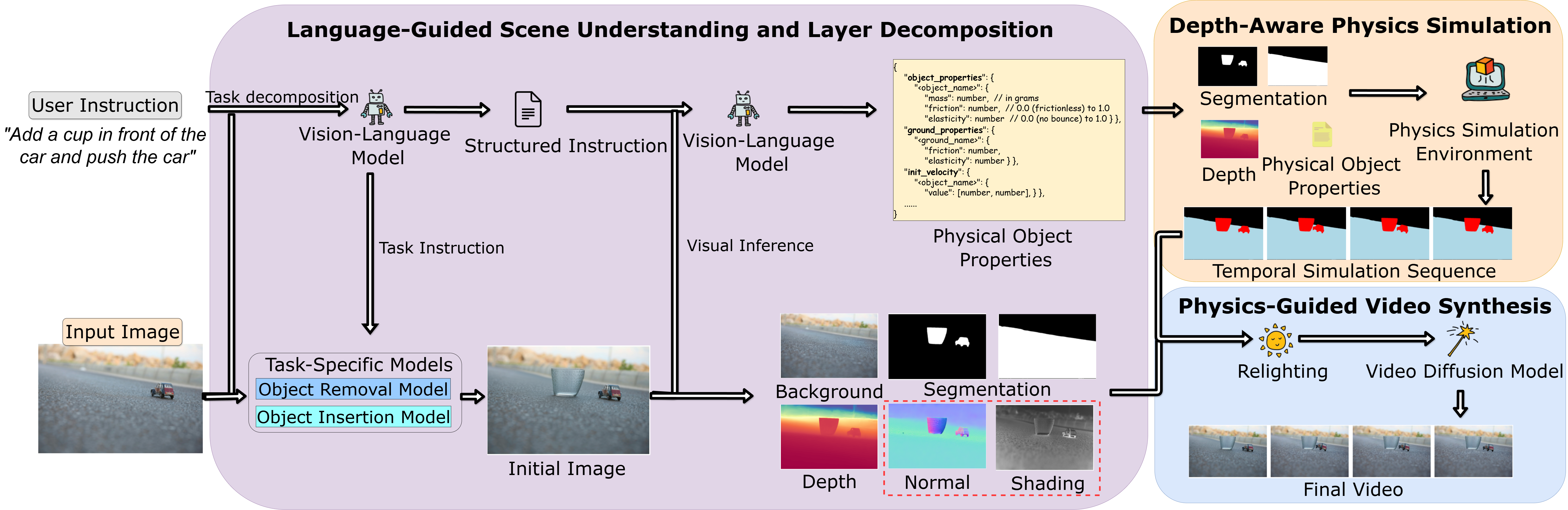
Figure 2: Overview of the PhysLayer framework, illustrating the flow from scene understanding and decomposition, to depth-aware physics simulation, and final physics-guided video synthesis.
Methodological Advancements
Layered Depth-Discretized Dynamics
PhysLayer models the scene as a set of physically interacting layers, each corresponding to a discrete, data-driven depth interval derived from the estimated depth histogram. Within each layer, 2D rigid-body physics is simulated via Pymunk; cross-layer interactions are handled by dynamically reassigning objects as they traverse depth boundaries. This approach circumvents the need for full 3D geometry recovery, balancing increased realism with computational tractability.
Apparent object scale is modulated according to projected depth, using a calibration heuristic for focal length. This ensures faithful foreshortening effects as objects move towards or away from the camera, a critical aesthetic and physical cue missing in planar-only approaches.
Language-guided Physical Control
The use of vision-LLMs (VLMs) extends beyond animation intent parsing: VLMs infer physical parameters of scene objects, making the system robust to a diverse set of materials and environmental contexts. By recognizing user intent (“move the cup towards the window,” “drop the ball from 30cm,” etc.), PhysLayer achieves intuitive, language-natural control for varied animation tasks, eliminating the need for explicit motion parameter specification.
Relighting and Rendering
Illumination consistency is achieved through intrinsic decomposition: estimated albedo, normals, and lighting direction are used to apply depth-aware relighting in each frame. This allows for temporal consistency and correct appearance changes arising from object movement. Final visual refinement leverages latent diffusion to correct minor inconsistencies and ensure coherence.
Experimental Results
PhysLayer is benchmarked on curated datasets covering indoor/outdoor images, diverse scene complexities, and three categories of animation tasks. The model is compared to leading baselines, including DynamiCrafter, I2VGen-XL, PIA, CogVideoX, and PhysGen. PhysLayer demonstrates improved CLIP-Similarity (+2.2%), FID (+9.3%), and Motion-FID (+3%), with human evaluations showing even more pronounced gains: physical plausibility (+24%) and text-video alignment (+35%) over competing methods.

Figure 3: Qualitative comparisons demonstrating that PhysLayer produces more temporally consistent and physically plausible animations on challenging scenarios compared to state-of-the-art baselines.
The ablation study reveals that depth-aware scaling is a dominant factor for FID improvement, and both language guidance and depth motion substantially contribute to quality and controllability. User studies corroborate these findings, with PhysLayer outperforming baselines (e.g., text alignment score: 4.23 vs. ≤3.12, physics plausibility: 4.10 vs. ≤3.31 on a 1–5 scale).
Limitations and Future Directions
PhysLayer’s reliance on depth-layered rigid-body simulation introduces several constraints. The model does not yet support deformable body dynamics, articulated objects, or complex physical phenomena such as fluid interaction. Layered collision handling prioritizes efficiency over cross-layer accuracy, limiting physical fidelity when objects at disparate depths interact. The fixed viewpoint assumption restricts scenarios with substantial camera motion, underscoring the need for multi-view geometry estimation.
Future research should address: (1) extending to non-rigid and articulated motions, (2) improving cross-layer interaction modeling, (3) integrating neural predictors for material and physical property estimation, (4) accelerating inference for real-time applications, and (5) supporting camera movement and multi-view coherence.
Conclusion
PhysLayer demonstrates that practical, physically-aware image animation can be achieved by integrating language-grounded scene understanding, depth-discretized rigid-body simulation, and advanced video synthesis techniques. The framework offers significant improvements in both quantitative and perceptual measures and establishes a path toward more robust, controllable, physically meaningful generative animation tools. Future directions include richer physical modeling and broader support for complex, dynamic environments.
(2604.23574)