- The paper introduces a decoupled two-stage fine-tuning paradigm that first exposes models to graded multimodal perturbations and then realigns them to clean data.
- It employs a comprehensive perturbation taxonomy covering 28 channels to systematically harden both visual and textual processing against adversarial and corruptive effects.
- Experimental results demonstrate task success rate improvements up to 16.49% across multiple VLA architectures, particularly under challenging multimodal corruptions.
STRONG-VLA: Decoupled Robustness Learning for VLA Models under Multimodal Perturbations
Introduction and Motivation
The development of Vision-Language-Action (VLA) models has significantly advanced embodied intelligence by integrating perception, language understanding, and control in a unified framework, as exemplified by architectures such as RT-1/RT-2, OpenVLA, and Octo. However, operational robustness under real-world uncertainty—including sensor noise, ambiguous/incomplete instructions, and distribution shifts—is a key bottleneck for reliable deployment. VLA models are notably vulnerable to multimodal perturbations: joint visual and textual disturbances can induce early action errors that catastrophically propagate, resulting in severe performance collapse, particularly in long-horizon tasks.
Conventional robustness approaches largely rely on joint fine-tuning with perturbed data, implicitly treating invariance as a monolithic optimization problem. This neglects the inherent conflict between sensitivity (required for clean input fidelity) and invariance (needed for robust execution under corruption). As a consequence, existing methods often yield suboptimal trade-offs—either degrading nominal performance or failing to generalize robustness to unseen perturbations.
STRONG-VLA: Decoupled Curriculum Fine-Tuning
STRONG-VLA introduces a two-stage fine-tuning framework that explicitly decouples robustness acquisition from task-aligned execution. In Stage I, the model undergoes curriculum-driven training by progressive exposure to a comprehensive taxonomy of multimodal perturbations, ramping up in severity in a controlled manner. In Stage II, the robustified model is realigned to clean data, restoring performance on nominal task distributions without erasing the acquired invariance. This staged protocol isolates conflicting objectives and enables stable optimization under multi-modal task-level perturbations.
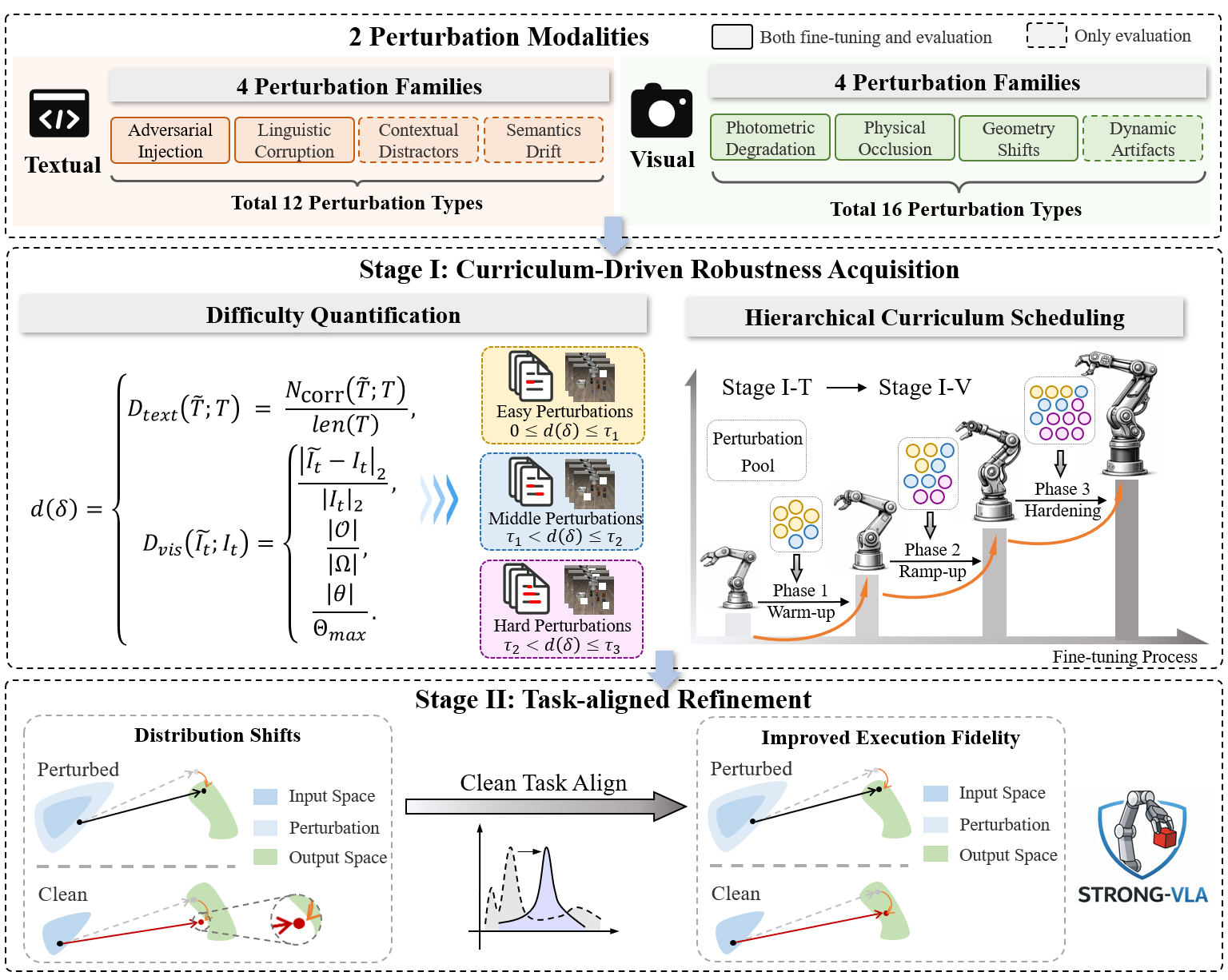
Figure 1: STRONG-VLA’s two-stage training paradigm systematically separates robustification from task alignment, enabling generalization beyond seen settings.
Multimodal Perturbation Taxonomy and Curriculum Design
A critical component of STRONG-VLA is its realistic perturbation benchmark: 28 perturbation channels spanning four textual and four visual perturbation families, each grounded in observed real-world VLA failure modes. Textual families include adversarial injection, linguistic corruption, contextual distractors, and semantic drift; visual families address photometric degradation, physical occlusion, geometric shifts, and dynamic artifacts.

Figure 2: STRONG-VLA’s perturbation taxonomy systematically organizes both textual and visual disturbances with representative examples.
Each perturbation instance is associated with a rigorously defined difficulty metric, enabling quantitative step-wise curriculum scheduling. For textual perturbations, severity is measured by the fraction of corrupted or extraneous content (e.g., token insertions, Unicode obfuscation). Visual difficulty is parameterized using L2 pixel-wise distance (photometric), occlusion coverage, and transformation magnitude (geometric). This design supports a curriculum that first hardens language understanding and then sequentially boosts perceptual robustness.

Figure 3: Visual perturbation examples at graded difficulty; increasing corruption deteriorates policy reliability in standard VLA pipelines.
Experimental Results and Empirical Claims
Evaluations are conducted across three prominent VLA backbones—OpenVLA, OpenVLA-OFT, and π0—on the LIBERO benchmark, spanning open-ended spatial, object, goal, and long-horizon manipulation tasks. Task-level robustness is quantified by task success rate (TSR) under four evaluation protocols: seen/unseen textual and visual perturbations.
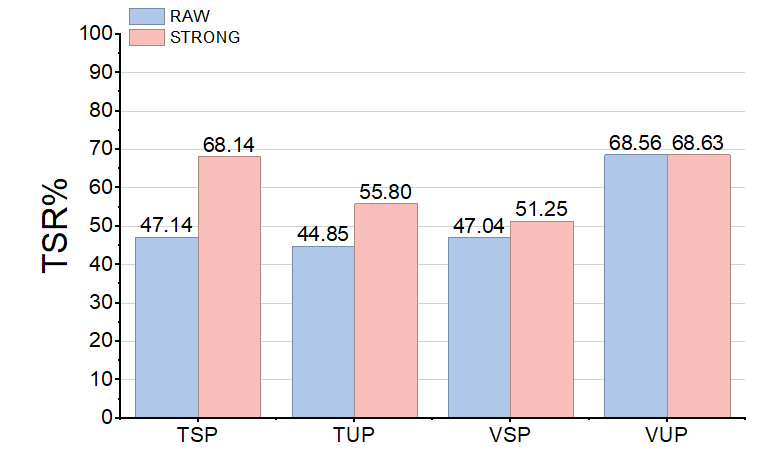
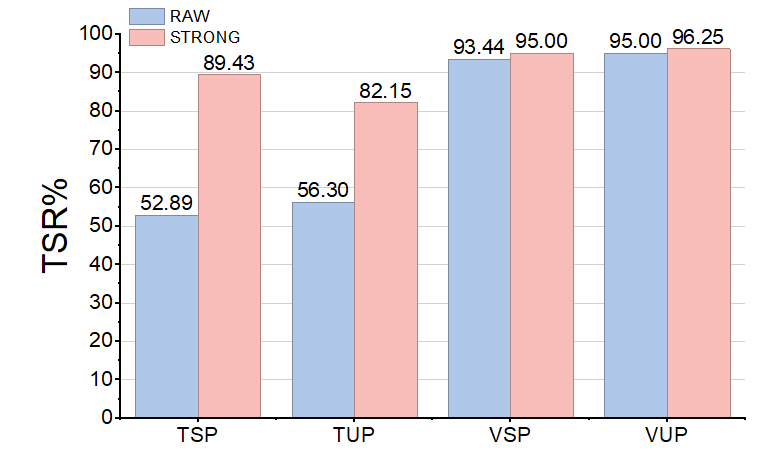
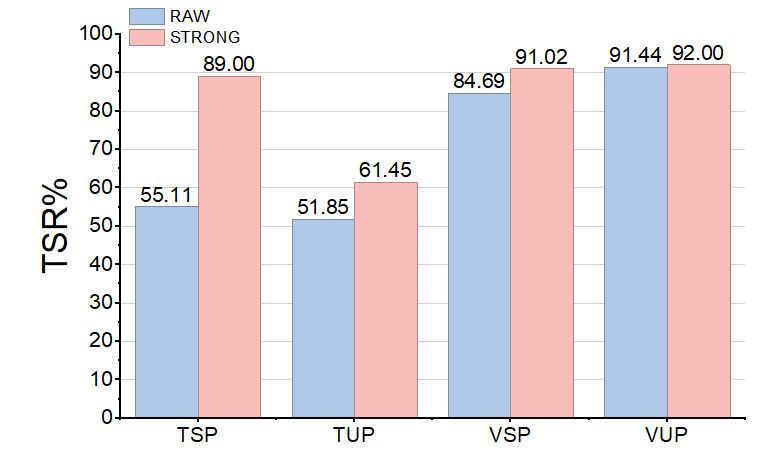
Figure 4: STRONG-VLA markedly improves robustness (TSR) across both seen and unseen perturbations and three VLA backbones.
Key empirical claims:
- STRONG-VLA consistently raises TSR by up to 12.60%/7.77% (OpenVLA), 14.48%/13.81% (OpenVLA-OFT), and 16.49%/5.58% (π0) under seen/unseen perturbations.
- Robustness gains are especially pronounced under textual (adversarial and corruption) perturbations, with strong generalization in the zero-shot regime.
- Gains for visual perturbations are less uniformly transferable, highlighting distribution-dependent limitations—particularly for photometric corruptions outside the fine-tuning curriculum.
- Multimodal perturbations (simultaneous text+vision corruptions) lead to the steepest nominal performance declines, yet STRONG-VLA delivers the largest relative improvements in this regime.
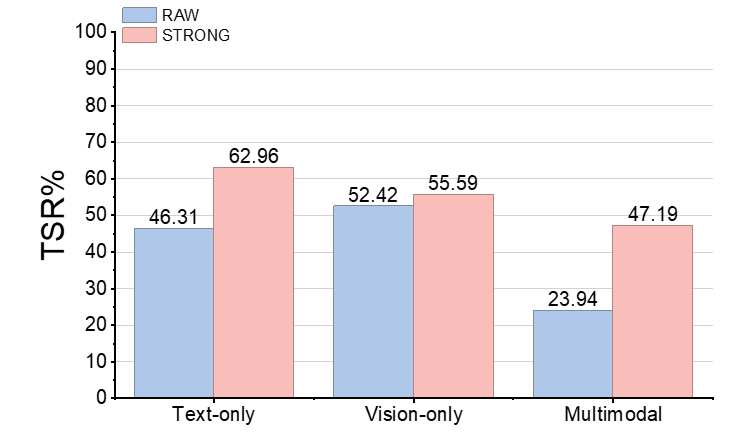
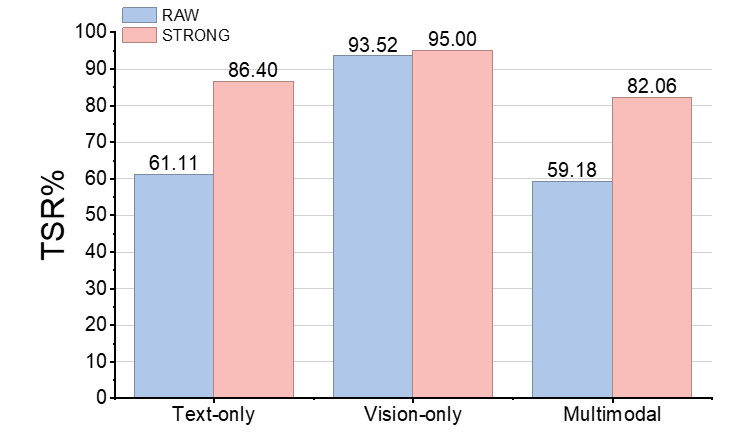
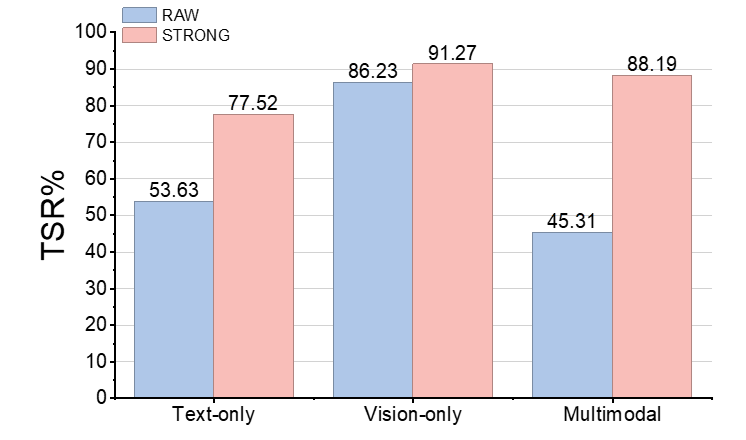
Figure 5: STRONG-VLA achieves substantial robustness gains under text-only, vision-only, and especially multimodal perturbations compared to unimodal baselines.
Ablation studies confirm that both stage-wise curriculum and clean-data refinement are independently critical: curriculum scheduling stabilizes sequential robustness acquisition, while the final stage restores task-level fidelity eroded by over-exposure to corrupted inputs. Joint training, by contrast, results in inferior TSR and greater performance variance.
Real-World Transfer and Practical Implications
The method is validated on an AIRBOT robotic arm in real-world pick-and-place scenarios under diverse sensor and instruction-level corruptions. STRONG-VLA-trained models achieve successful execution where unrefined models fail, evidencing transfer from simulation to hardware despite pronounced sensory noise and visual ambiguities.

Figure 6: STRONG-VLA robustifies real-world policy execution, as visible in third-person trajectory comparisons on the AIRBOT platform.
Qualitative analysis of first-person camera input frames underlines the fragility of raw models and the robustness conferred by stage-wise curriculum training in the presence of occlusions, corruption, and adversarial context.

Figure 7: Raw model first-person views typify failure points, which STRONG-VLA is capable of overcoming under identical perturbations.
Theoretical and Practical Implications
STRONG-VLA empirically establishes that robustness in VLA models is fundamentally distribution-dependent rather than a static property. The explicit decoupling of objectives enables models to independently optimize for invariance and sensitivity, mitigating the gradient conflicts endemic to joint or mixed-distribution training. The robustification generalizes strongly for compositional, adversarial, and realistic instruction-level attacks, but limitations persist for certain out-of-distribution visual corruptions, indicating a need for more comprehensive or adaptive curriculum design.
The framework demonstrates promising cross-architecture generalization, suggesting potential for adoption as a drop-in protocol across both transformer and flow-based VLA policy paradigms. Decoupled curriculum fine-tuning offers a scalable path for future VLA-based robotic systems requiring reliable task execution in the presence of open-world uncertainty, adversarial instruction, and substantially non-stationary sensor conditions.
Future Directions
- Curriculum learning with adaptive or learned difficulty progression could improve generalization to unseen visual distribution shifts.
- Automated perturbation discovery (e.g., adversarial search or generative data augmentation) could further close the gap in robustness for edge-case visual artifacts.
- Extensions to continual or lifelong learning, where the perturbation distribution actively evolves with deployment context, merit investigation.
- Integrating STRONG-VLA with emerging multi-agent or multi-modal world modeling architectures would expand its applicability to collaborative and generalist embodied AI.
Conclusion
STRONG-VLA provides a rigorously structured, decoupled training paradigm for robustness in Vision-Language-Action models. Its curriculum-based robustness acquisition and subsequent task-aligned refinement deliver substantial improvements in both simulated and real-world task settings, especially under challenging multimodal and adversarial distributions. The findings reinforce the necessity of distribution-aware robustification in embodied AI and delineate clear paths for further research towards reliable real-world VLA deployment (2604.10055).