- The paper introduces a framework using foreground-background decoupling and trajectory-aware optimization to craft physically plausible adversarial 3D textures for VLA models.
- It demonstrates significant increases in task failure rates, achieving up to 96.7% failure in targeted attacks and robustness to camera, pose, and lighting variations.
- Key experiments validate the transferability of adversarial textures across models and their physical instantiation, exposing critical vulnerabilities in embodied AI systems.
Tex3D: Objects as Attack Surfaces via Adversarial 3D Textures for Vision-Language-Action Models
Introduction and Motivation
Tex3D presents a comprehensive framework for constructing adversarial 3D texture attacks on vision-language-action (VLA) models, a class of embodied agents integrating perception, language, and control. Existing adversarial attacks typically involve language perturbation or 2D image-space manipulations, but these exhibit limited physical realizability and poor robustness to geometric changes, particularly in real-world robotic deployments. Tex3D circumvents these limitations by treating object texture as the attack surface, enabling adversarial perturbations that are physically plausible, transferable across camera views and object poses, and robust to varied real-world conditions.
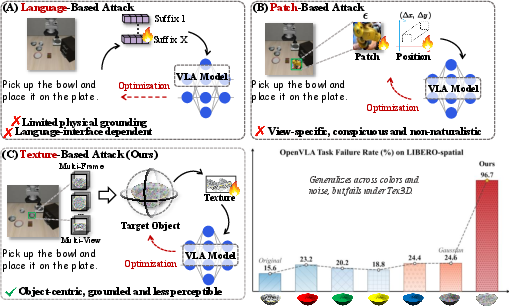
Figure 1: Comparison between Tex3D and existing attack paradigms. Bottom-right: VLA exhibits a certain degree of generalization under color changes and Gaussian noise perturbations, but its task failure rate rises sharply under Tex3D.
Framework and Technical Contributions
Foreground-Background Decoupling (FBD)
Optimizing adversarial 3D textures in standard embodied simulators is nontrivial due to the lack of differentiability with respect to object appearance. Tex3D introduces Foreground-Background Decoupling (FBD) to establish a differentiable optimization path. The scheme uses MuJoCo for non-adversarial simulation of the environment, while the target object's rendering is delegated to the differentiable renderer Nvdiffrast. Cross-renderer alignment is performed for camera, object pose, and lighting parameters to maintain geometric and photometric consistency. The composited observation is then fed into a frozen VLA model, and action-level gradients are propagated back solely to the adversarial object's texture, enabling efficient and targeted optimization.
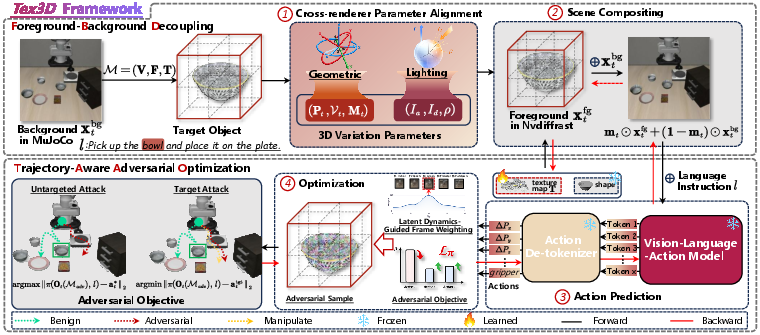
Figure 2: Overview of Tex3D. FBD renders the background in MuJoCo and the target object in Nvdiffrast, enabling spatial and photometric alignment for differentiable optimization.
Trajectory-Aware Adversarial Optimization (TAAO)
Standard 3D-adversarial attacks in vision assume static viewpoints and short episodes. Tex3D introduces Trajectory-Aware Adversarial Optimization (TAAO), which identifies behaviorally critical frames via latent velocity and acceleration in the encoded visual feature space. Frame weighting is realized through a temperature-scaled softmax scheme emphasizing pivotal moments—e.g., onset of grasp or object transfer—in manipulation trajectories. Optimization is performed on a vertex-based color parameterization to enforce smooth, low-rank texture updates, which regularize the attack and enhance transferability across models.
Experimental Results and Key Findings
Tex3D is evaluated on the LIBERO suite, covering four manipulation categories and four representative VLA models (OpenVLA, OpenVLA-OFT, π0, and π0.5) in both simulated and real-world robot settings.
Tex3D achieves failure rates of up to 96.7% on OpenVLA (Spatial tasks), with an average increase from 24.1% (clean) to 88.1% (untargeted) and 90.5% (targeted attack) across task categories and models. Comparable gains are observed on OpenVLA-OFT, π0, and π0.5, with high performance in both untargeted and targeted settings. Notably, adversarial textures crafted by Tex3D maintain their efficacy under severe camera, pose, and lighting variations, outperforming 2D patch-based and noise baselines by significant margins.

Figure 3: Qualitative results of Tex3D on manipulation tasks. For each task, the green row shows the clean rollout, whereas the red row shows the adversarial rollout under Tex3D.
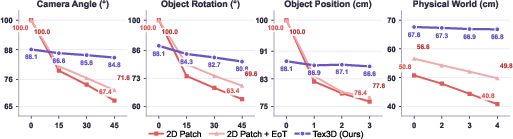
Figure 4: Robustness comparison of Tex3D and 2D patch-based baselines under varying camera angles, object rotations, positions, and physical world offsets.
The physical instantiation of adversarial textures, realized via 3D-printed objects, preserves high failure rates (66.8%–67.6%)—a marked improvement over 2D-patch attacks (40.8%–56.6%) under real-world conditions.

Figure 5: Physical-world qualitative comparison. The first row: clean samples, second row: results under 2D patch-based attacks, third row: results under Tex3D.
Cross-model transfer experiments demonstrate substantial effectiveness even when the attack texture is optimized on one model and evaluated on others, confirming the data-driven, physically grounded nature of the attack surface.
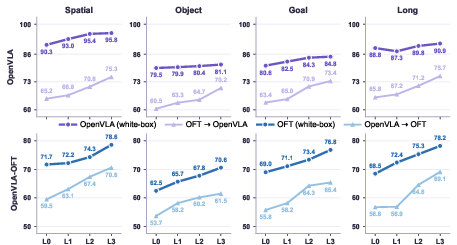
Figure 6: Tex3D performance across four perturbation levels. Each subplot shows task failure rates (\%) from L0 to L3 settings, where L0 is naturalness-constrained and L1–L3 increase the perturbation budget.
Robustness and Defense Analysis
Tex3D exhibits resilience against conventional input-level defenses such as JPEG compression, noise augmentation, and median filtering, with task failure rates remaining largely unchanged (86.6%–87.3%). Additionally, ablation studies on FBD and TAAO components confirm the necessity of both geometric/lighting alignment and dynamics-guided frame weighting for achieving maximal attack effectiveness and computational efficiency.
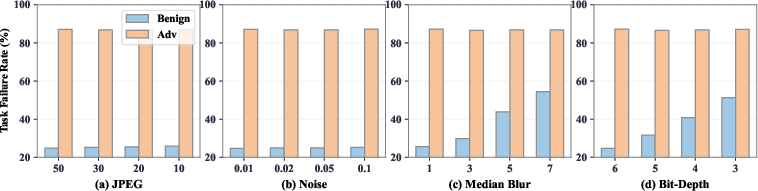
Figure 7: Impact of input-space defenses on Tex3D.
Tex3D's design ensures that failures are not attributable to rendering discrepancies, color shifts, or isolated single-frame optimization; instead, the attack is driven by temporally consistent, physically plausible, trajectory-aware texture perturbations.

Figure 8: Qualitative perceptual-similarity comparison between Tex3D and 2D patch-based attacks. Right columns: rendering-consistency comparison at the same optimization step.
Implications and Future Directions
Tex3D exposes critical vulnerabilities in VLA models, especially the brittleness towards even near-imperceptible, physically realizable 3D appearance shifts. The results underscore the broader concern that current VLA training and evaluation regimes lack sufficient coverage of realistic or adversarial appearance variance. Integrating adversarially robust data augmentation, physical-world distribution shifts, and action-level consistency constraints is essential for future improvements.
From the perspective of embodied AI safety, Tex3D's demonstrated attack transferability, robustness under real-world perturbations, and efficacy against multiple architectures imply that adversarially robust policy learning will be a central research direction. Systematic benchmarking and robustness-aware training against object-level adversarial textures is necessary for VLA systems deployed in safety-critical or unstructured environments.
Conclusion
Tex3D establishes adversarial object textures as a highly effective and physically plausible attack surface for VLA systems. By introducing efficient differentiable optimization and trajectory-aware attack strategies, it demonstrates severe vulnerabilities in prevalent VLA architectures. The findings mandate a paradigm shift toward robust, physically grounded training and evaluation pipelines for embodied agents, with far-reaching implications for AI safety and deployment robustness in robotic manipulation and broader vision-language-action domains.

