- The paper demonstrates that base LLM outputs have a high human probability, with detectors misclassifying them as human over instruction-tuned outputs.
- It introduces Humanization by Iterative Paraphrasing (HIP), a minimally fine-tuned, iterative method that shifts output statistics to bypass AI detectors while preserving semantics.
- Experimental results reveal HIP consistently outperforms baselines across scales and models, challenging current detection paradigms and calling for robust design improvements.
Empirical Analysis of Base Models and Commercial AI Text Detectors
Overview
"Base Models Look Human To AI Detectors" (2605.19516) provides a thorough empirical investigation into the efficacy of commercial AI-generated text detectors, specifically GPTZero and Pangram, in distinguishing output from base LLMs versus instruction-tuned LLMs. The authors find that, across both Open-Source (Llama3, Qwen3) and commercial model families, base model generations are much more likely to be classified as "human" by these detectors than outputs from their instruction-tuned counterparts. This observation motivates the introduction of the Humanization by Iterative Paraphrasing (HIP) method—a minimally fine-tuned, detector-agnostic, iterative paraphrasing pipeline for evasion of AI detectors with high semantic fidelity.
Empirical Investigation of Detector Behavior
The central empirical finding is that base LLMs, when conditioned on human-written text, produce output that existing commercial detectors almost always misclassify as human-authored. For instance, for Llama3-8B, GPTZero and Pangram assign human probabilities of 96.7% and 98.8% to base model completions, versus 30.3% and 17.1% for instruction-tuned continuations. These effects generalize across both human and AI-generated contexts, indicating that detector behavior is highly sensitive to post-training artifacts introduced during instruction tuning and RLHF, rather than intrinsic differences between human and machine text.
The strong numerical disparity in detector outcomes is robust across model scales and families.
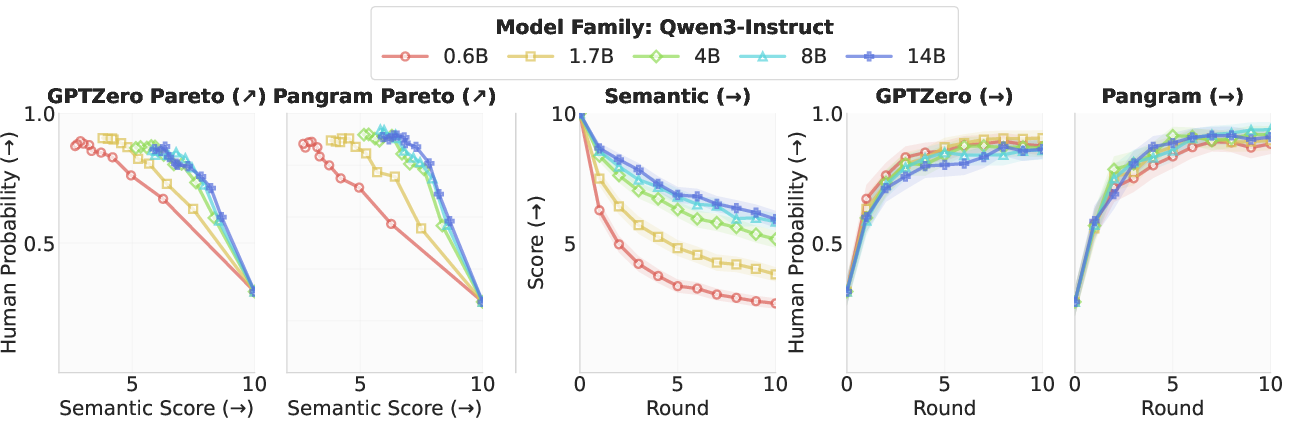
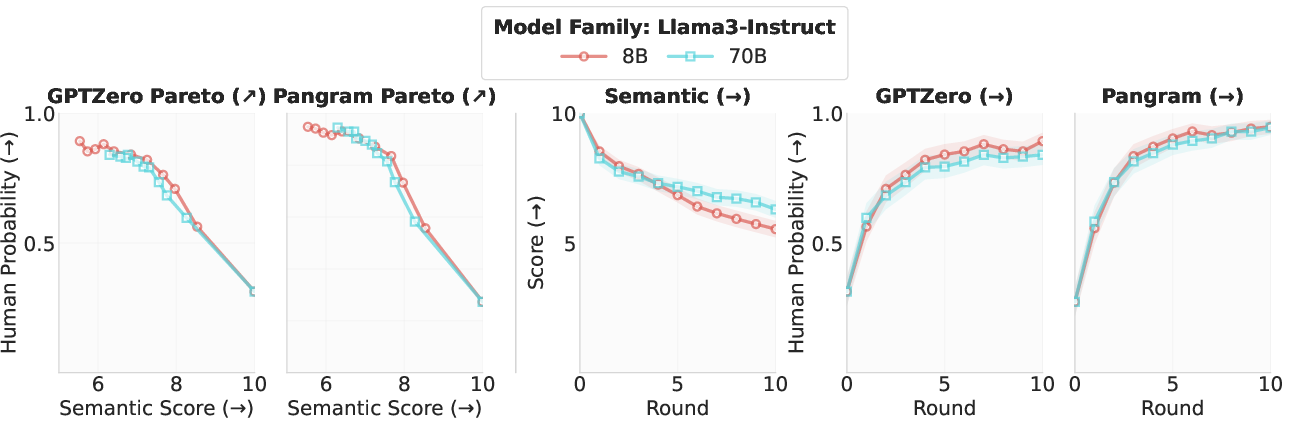
Figure 2: HIP's effect on semantic preservation and human-likeness across Qwen3 and Llama3 model families, showing strong trade-offs and consistent gains over instruct variants.
These findings indicate that commercial detectors are primarily tracking surface-level artifacts of instruction tuning and local context, rather than any model-invariant property of machine-generated language.
The HIP Paraphrasing Pipeline
Building on these observations, the authors introduce HIP, a detector-agnostic and minimally invasive paraphrasing pipeline comprised of three main stages:
- Data Construction: Construct (AI, human) paraphrase pairs, with AI-style rewrites of high-quality human texts, filtered for semantic fidelity.
- Minimal Fine-Tuning: Perform minimal supervised fine-tuning (often LoRA) of a base LLM on the paired data, training the model to map AI paraphrases to human originals, while preserving native continuation behavior.
- Iterative Paraphrasing: Apply the adapted paraphraser multiple times to a passage. Each round shifts statistical features of the output away from the AI-generated regime and progressively increases detector-assigned human probability, at the cost of gradual semantic drift.
The iterative aspect of HIP exploits context amplification to overcome residual detectable structure—each round enhances humanization while balancing semantic retention.
Experimental Results
HIP is evaluated across Qwen3 and Llama3 at several scales (0.6B to 70B) and compared to a range of baselines: zero-shot paraphrasing, supervised paraphrasers (DIPPER), Unicode-homoglyph attacks (SilverSpeak), and RL-based detector-evasion methods (StealthRL). Evaluation is performed using both semantic preservation (GPT-5-nano) and the human-probability assigned by both GPTZero and Pangram.
Key results include:
- Superior Evasion-Semantic Trade-off: HIP produces the strongest Pareto frontiers across both commercial detectors, substantially outperforming all baselines, including DIPPER and RL-based evasion.
- Consistent Effect Across Scale and Model Family: The HIP effect persists for both base and instruct variants and is robust to scale once minimal paraphrase competence is achieved.
- Qualitative Trajectories: Paraphrase outputs undergo gradual humanization while maintaining high semantic scores until significant rounds of iteration.
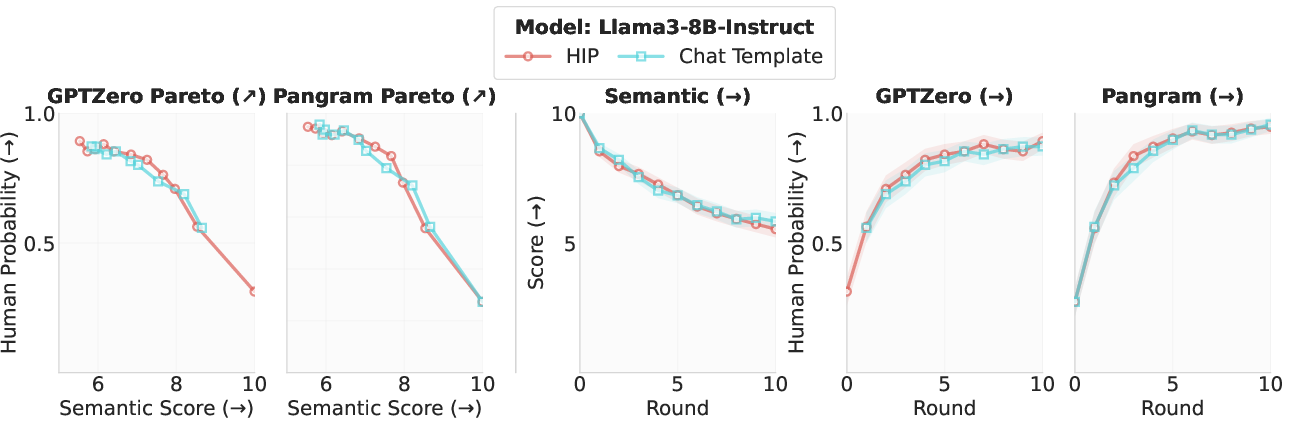
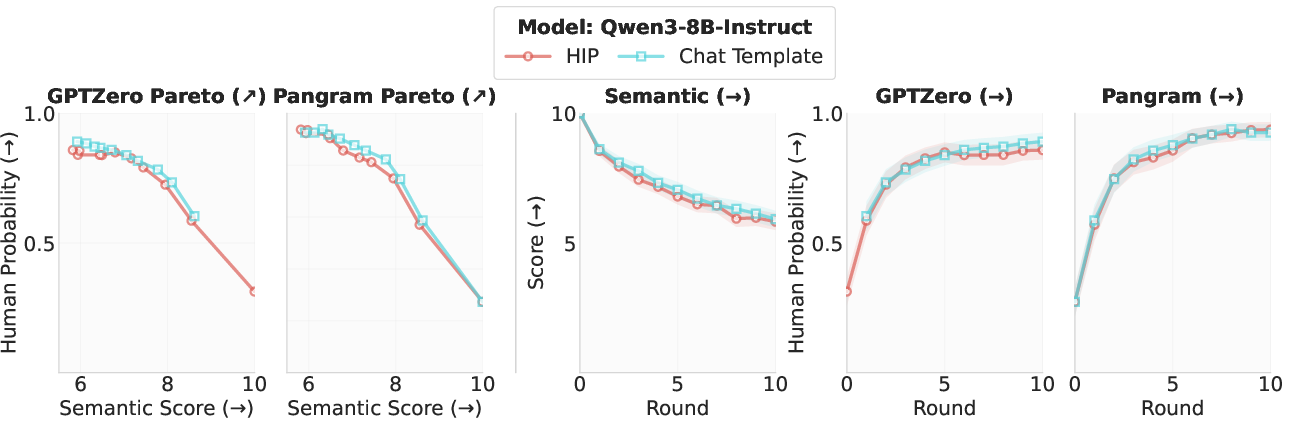
Figure 4: Comparison between HIP with standard and native chat-template formatting on instruct models, showing near-equivalent humanization effects.
Further ablation reveals that HIP's effect does not depend on prompt format (plain source-target vs. chat template), and that output-layer-only adaptation is insufficient—full HIP requires deeper representational adaptation.
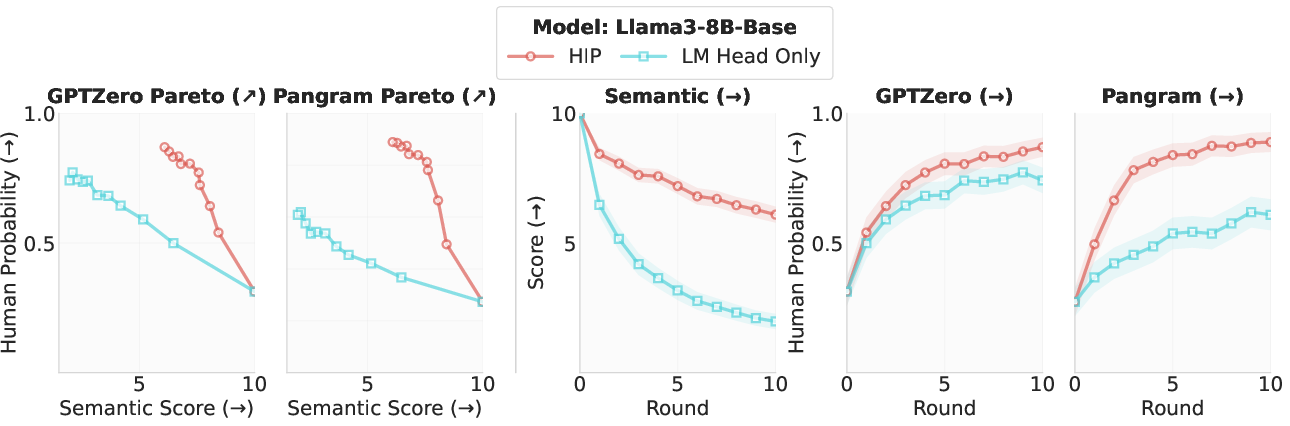
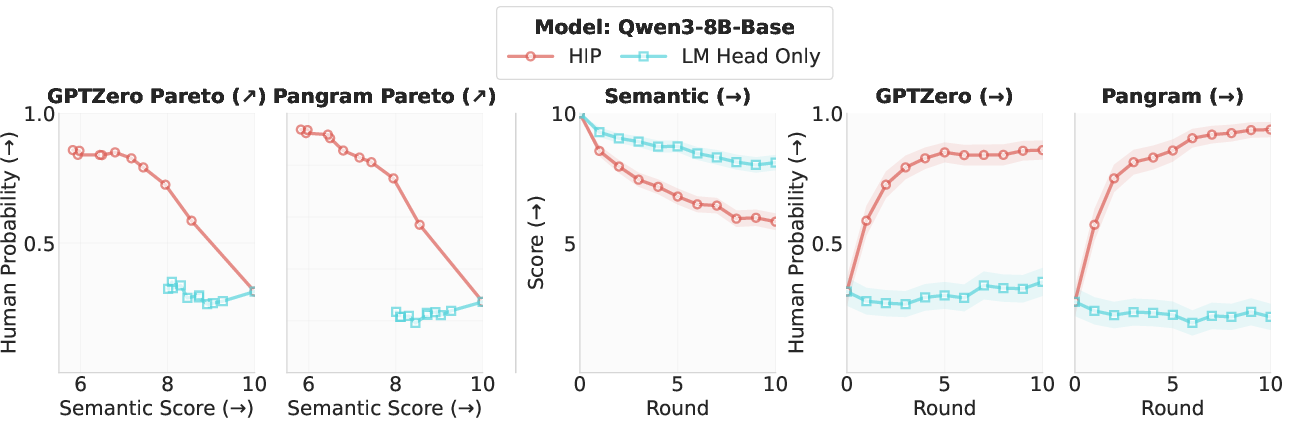
Figure 1: Output-layer-only adaptation is markedly inferior to full HIP in both evasion capability and semantic trade-off.
Implications
The study reveals that current commercial detectors do not identify AI-generated text per se, but rather detect artifacts introduced by alignment procedures, such as instruction tuning and RLHF, and rely heavily on local context. This has several major implications:
- Security of Detector Systems: Current detectors can be systematically bypassed using HIP-style approaches without any detector-aware optimization. This undermines the reliability of existing detector-based academic-integrity workflows.
- Future of Detector Design: Detector research must move beyond reliance on instruction-tuning-related artifacts or local context, and instead attempt to model statistical properties of base-model generation, post-training fingerprints, and adversarial paraphrasing more explicitly.
- AI Model Alignment: The connection between human-likeness in detector space and continued exposure to human-written data indicates that alignment pipelines may benefit from careful mitigation of detectable statistical fingerprints.
Limitations and Further Work
- Detector Adaptation: Current detector vulnerabilities may not persist if detectors are retrained on HIP outputs.
- Generalization to Closed-Weight Models: HIP applied via OpenAI’s fine-tuning API on GPT-4.1-nano does not yield comparable benefits, suggesting platform-specific effects on adaptation.
- Potential for Misuse: While HIP can be leveraged for benign editorial applications, the existence of such trivial bypasses raises critical questions about the practical value of AI-text detection in sensitive domains.
Conclusion
This work demonstrates that commercial AI-generated text detectors such as GPTZero and Pangram are easily evaded by base LLM outputs and minimal paraphrasing pipelines. The HIP methodology achieves strong semantic-faithful evasion, outpacing existing baselines. The findings challenge prevailing assumptions about the efficacy of detector-based safeguards and highlight urgent needs for more robust, context-invariant detection paradigms attuned to evolved alignment and paraphrasing strategies.
Figure 6: HIP's trade-off frontiers versus baselines, with HIP achieving consistently superior semantic preservation given the same level of detector evasion.

