- The paper introduces a knockoff filtering method to calibrate any rewrite-based detector, achieving FDR control without retraining.
- It leverages the exchangeability of rewrite-based statistics to convert arbitrary detection scores into statistically sound human-text detectors.
- Empirical benchmarks across multiple models and domains demonstrate high power and adaptability, particularly with L2D and IMBD statistics.
A Distribution-Free Calibration System for Rewrite-Based Human-Text Detection via Knockoff Filtering
Introduction
This work introduces a general statistical calibration framework for the detection of human-written text in the presence of large-scale LLM-generated text, leveraging the knockoff filtering methodology to control the False Discovery Rate (FDR) in a distribution-free setting. The key insight is that many rewrite-based detectors inherently generate exchangeable text--rewrite pairs under the null hypothesis (AI-written text), which satisfies the requirements of Model-X knockoff constructions. This realization enables the decoupling of score/statistic design from control of false positives, providing deployment-facing guarantees (FDR) irrespective of the distributional properties of the rewrite process or the statistic used.
Methodology: Knockoff-Driven Detection
The framework converts any rewrite-based detection statistic into an FDR-controlled human-text detector via post-hoc calibration, without retraining. The method comprises three main steps: (1) generation of knockoff samples via LLM rewriting, (2) calculation of an antisymmetric detection statistic comparing the original and rewritten text, and (3) application of the knockoff filtering rule to select human-written candidates. The statistical guarantees rest on a quantitative symmetry condition—anti-symmetry of the test statistic f(Ti,Ri) and exchangeability of these statistics for null (AI-generated) texts.
The threshold for positive discovery is adaptively set to control the empirical FDR at a target level q, resulting in robust finite-sample guarantees contingent on satisfaction of the symmetry assumption. The construction reduces to a supermartingale-based selective inference bound as developed for Model-X knockoffs, adapted here to the LLM-text regime.
Symmetry Validation and Assumptions
Empirical validation focuses on checking that under the null (AI-generated texts) the distribution of the detection statistic is nearly symmetric around zero. The diagnostics include the fraction of knockoff statistics above zero (expected to converge to 0.5 under symmetry) and Kolmogorov–Smirnov tests for symmetry. Across multiple rewrites and diverse detection methods, the symmetry condition is generally observed to hold to a high degree, supporting the validity of subsequent inferences.
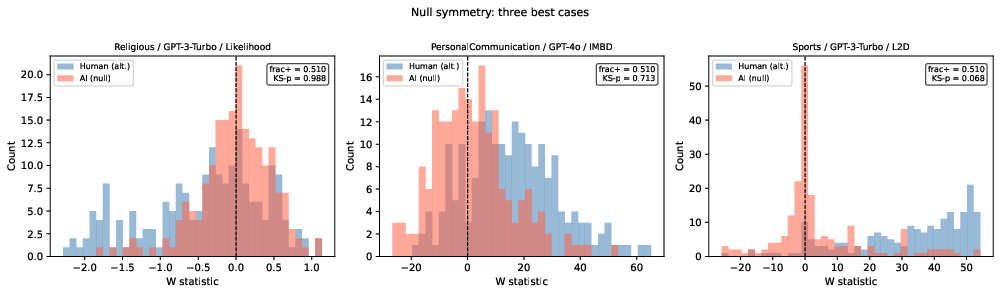
Figure 1: The distribution of knockoff statistics si demonstrates symmetric behavior around zero for representative high-symmetry cases, validating the foundational symmetry assumption of the framework.
Empirical Evaluation and Results
The framework is benchmarked across three detection statistics (L2D, IMBD, and likelihood-based scoring) and four major LLMs (GPT-3.5T, GPT-4o, Gemini, and Llama-3-70B-Instruct) on a large multi-domain dataset covering 19 text domains. Two principal questions are addressed empirically: (1) whether the knockoff approach maintains FDR control at the target level across diverse conditions, and (2) the detection power achievable, as a function of both the statistic and the domain/model.
Key findings include:
- When FDR control is targeted at q=0.2 and q=0.5, empirical FDR is generally maintained within a modest margin above the nominal level, especially for L2D and IMBD statistics. L2D in particular achieves high statistical power ($0.83$–$0.94$ at q=0.2) across models, with FDR near or below the nominal line.
- The likelihood-based method, which does not benefit from explicit training to separate human and LLM text, nevertheless achieves non-trivial detection power and typically maintains FDR control except for some mild inflation in specific model–domain pairs.
- Cross-domain calibration, where null statistics are centered using data from held-out domains, improves power but can slightly inflate FDR in certain cases. The framework therefore supports transfer learning scenarios but requires empirical diagnostics to guard against anti-conservative calibration.
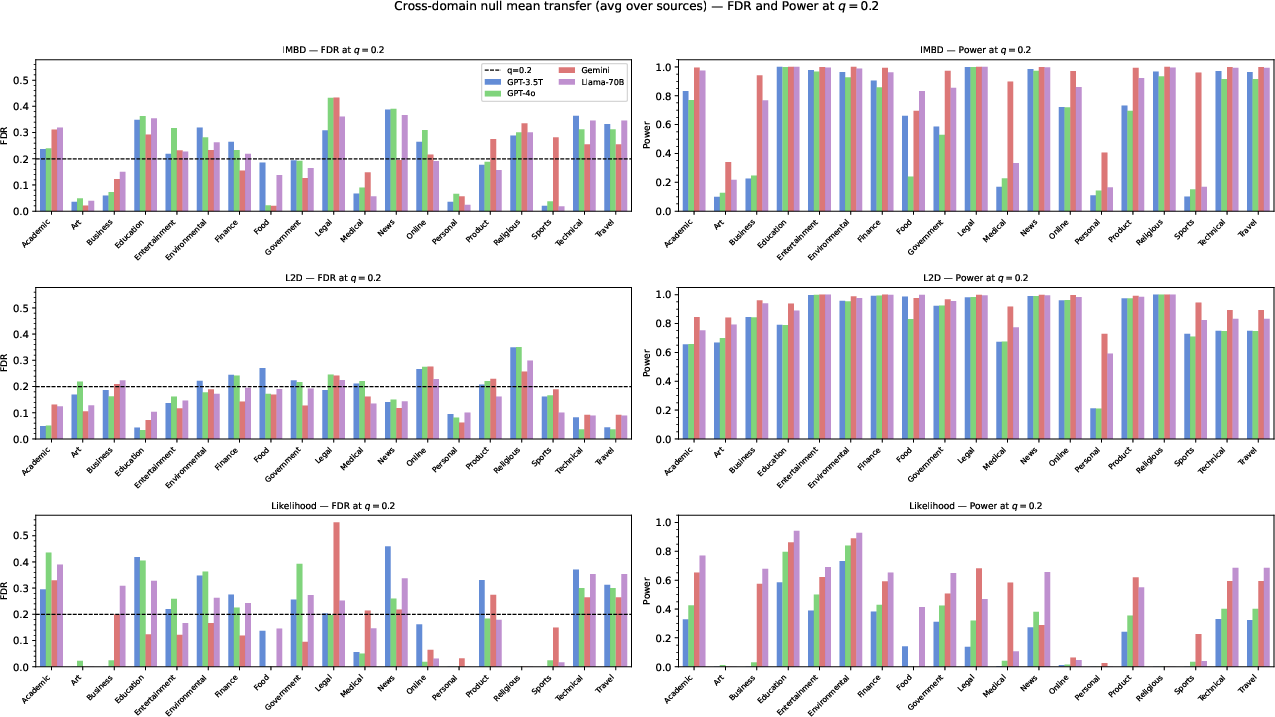
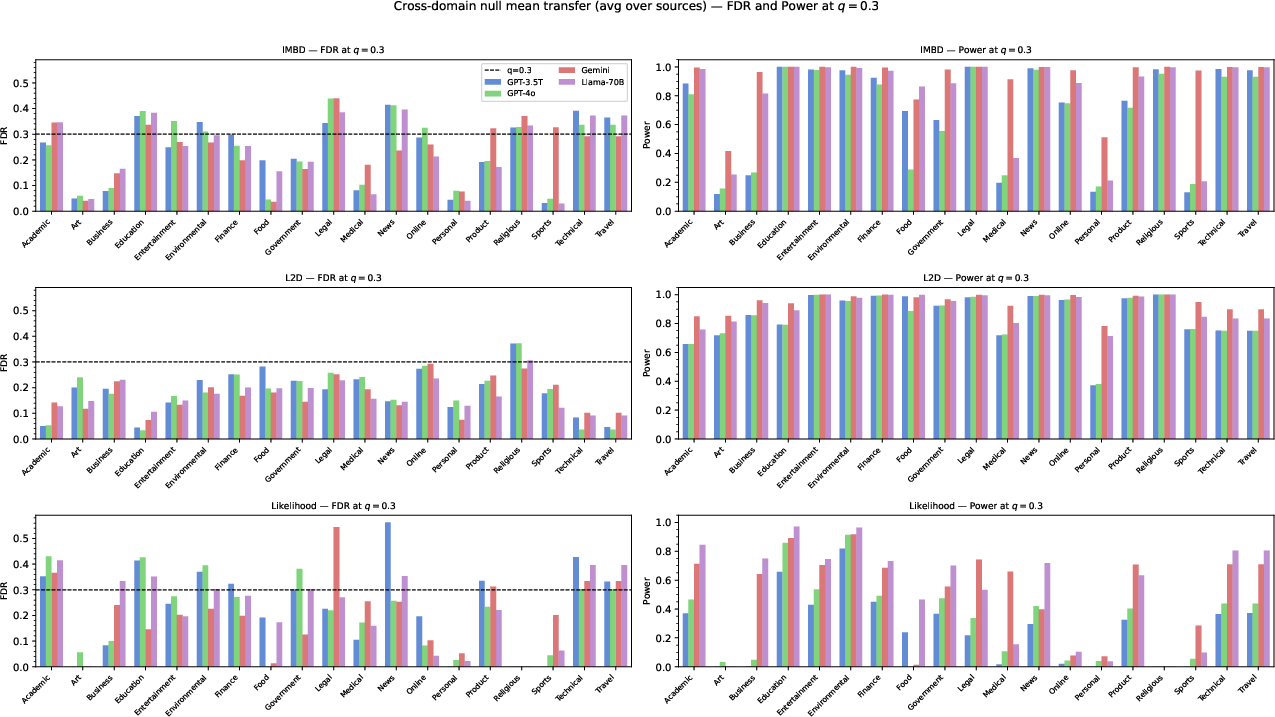
Figure 2: Empirical FDR and power for q=0.2 across methods and models, demonstrating robust control and high detection sensitivity in most configurations.
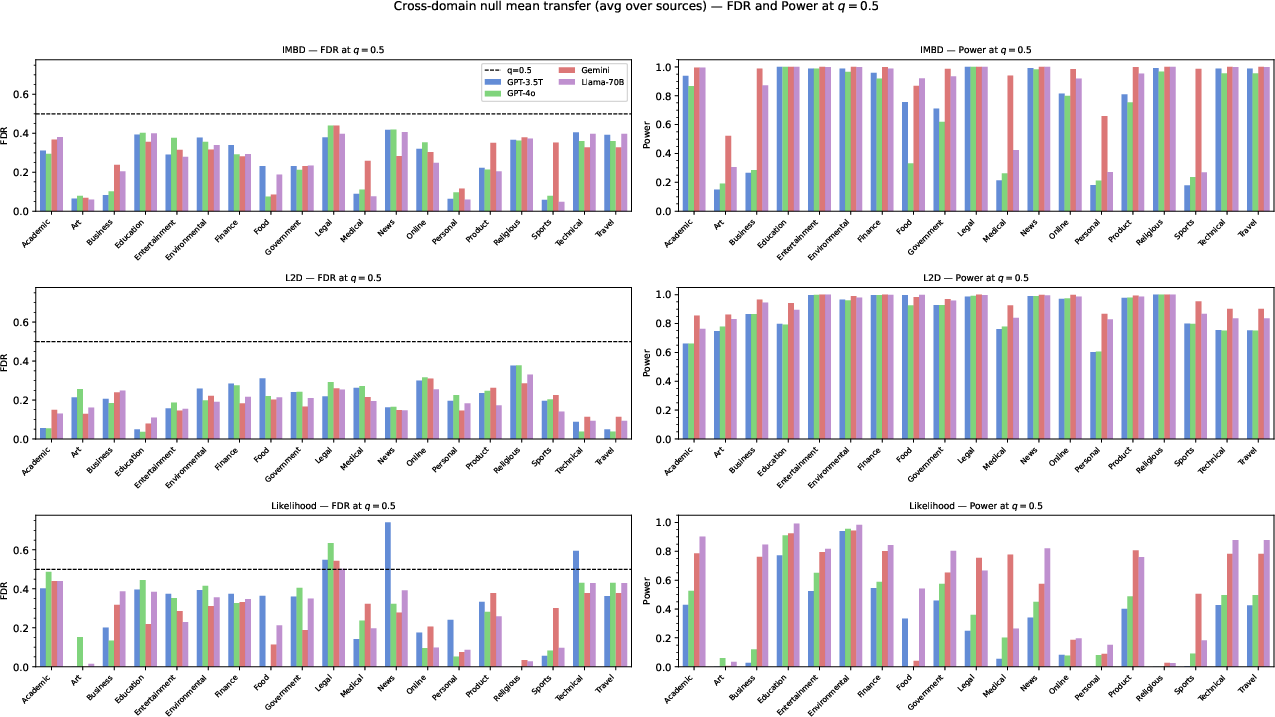
Figure 3: FDR and power performance at the relaxed threshold q=0.5, indicating scalability of the framework to practical, high-throughput scenarios.
Practical and Theoretical Implications
The primary theoretical advance is extending the suite of high-dimensional selective inference tools (knockoff filters) to the context of NLP and LLM-authorship attribution without explicit distributional modeling. This provides strong guarantees for FDR control in finite samples, a property that is underutilized in present NLP practice and is essential for scalable deployment in real-world settings (e.g., mass screening of educational assignments or content moderation).
Practically, the calibration layer can be wrapped around any rewrite-based human-text detector, enabling modular improvement of either the statistic or the FDR control without retraining. This improves consistency and interpretability for downstream applications where the cost of false accusations is substantial.
Limiting factors include persistent symmetry violations when the rewrite model is not sufficiently exchangeable for given domains or statistics, resulting in conservative or slightly anti-conservative FDR. Mean-correction or cross-domain centering, while helpful, cannot fully compensate for uninformative or inherently biased statistics. Future developments will likely focus on designing base statistics that inherently enforce knockoff symmetry while optimizing for power, and on dynamic, data-driven calibration regimes for robust real-time deployment.
Conclusion
This framework establishes a principled and distribution-free methodology for human-text detection in the era of LLM ubiquity, transforming the generally heuristic rewrite-based detection into a calibrated, statistically-interpretable process. The separation of detection and calibration allows both modular improvement and immediate adaptation to new LLM or domain conditions, provided symmetry can be empirically established. The generality of the knockoff filtering approach promises future adaptation to other generative detection tasks requiring strong error rate control.

