- The paper introduces DSIPA, a training-free, black-box detection method that leverages sentiment divergence to identify LLM-generated text.
- It employs low-emotional rewriting and sentiment feature extraction to compare sentiment stability between human and synthetic texts, achieving F1 scores exceeding 80–90%.
- The method demonstrates robust performance across diverse domains and adversarial conditions, offering practical applications for forensics, content moderation, and security auditing.
Detecting LLM-Generated Texts via Sentiment-Invariant Patterns Divergence Analysis
Introduction
The detection of LLM-generated text presents new challenges as models reach human-level fluency and cross-domain generalization. Traditional detection strategies relying on watermarking, supervised classification, or shallow statistical interventions increasingly fail to generalize or remain robust under adversarial perturbations, paraphrasing, and domain shift. The "DSIPA: Detecting LLM-Generated Texts via Sentiment-Invariant Patterns Divergence Analysis" (2604.26328) introduces a training-free, black-box detection paradigm that exploits behavioral asymmetries in sentiment distribution under controlled stylistic variation as a discriminative signal for synthetic text provenance.
Methodology
DSIPA hypothesizes that LLM outputs display markedly stable affective patterns under stylistic or emotional modulation, attributable to the risk-averse, alignment-focused training and data curation of LLMs. In contrast, human-written texts naturally manifest broader variation in sentiment expression under equivalent stylistic perturbations.
The framework consists of three main stages:
- Low-Emotional Rewriting (LER): Multiple stylistic rewrites are generated using semantically neutral, emotion-suppressing prompts applied to the original text via zero-shot LLM calls.
- Sentiment Feature Extraction: For both the original and rewritten variants, vectorized sentiment features are computed using LLM-based sentiment analysis instructions, yielding k-dimensional distributions across valence, arousal, and polarity.
- Sentiment Distribution Divergence Analysis: Two central unsupervised metrics are defined:
- Sentiment Distribution Consistency (SDC): Measures the divergence ∥logσ(x)−logσ(x′)∥ between the original and rewritten sentiment feature distributions.
- Sentiment Distribution Preservation (SDP): Quantifies the invariance of sentiment under paired invertible semantic transformations (e.g., third-person versus first-person rewrite followed by inverse transform) using analogous log-space divergence.
Decisions are made via a threshold applied to the mean divergence aggregated over rewrites; scores below the threshold indicate LLM provenance.
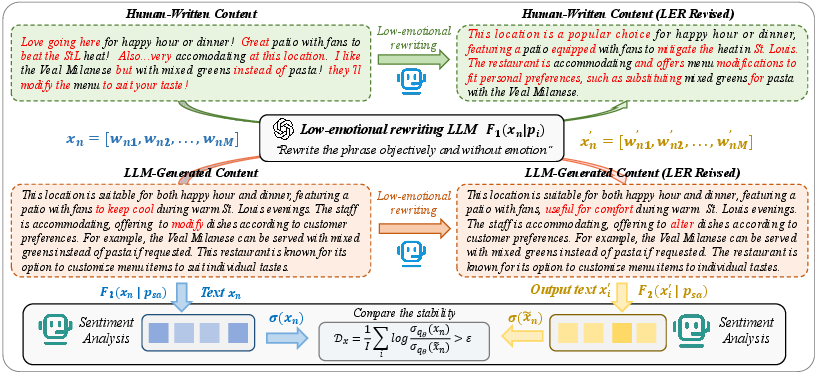
Figure 1: The DSIPA pipeline applies low-emotional rewriting and sentiment analysis to input text, then quantifies divergence for detection.
Experimental Evaluation
Main Results
DSIPA is evaluated on five domains encompassing news (Reuter), academic abstracts, program code (HumanEval), student essays, and community reviews (Yelp), using modern LLMs, including GPT-4-0613, Gemini-1.5-pro, LLaMa-3.3, and GPT-5.2.
DSIPA achieves consistently superior F1 detection scores—often exceeding 80–90%—outperforming strong baselines such as DetectGPT, Binoculars, RAIDAR, and commercial classifiers (GPTZero), especially as LLM generations become more advanced and stylistically natural.
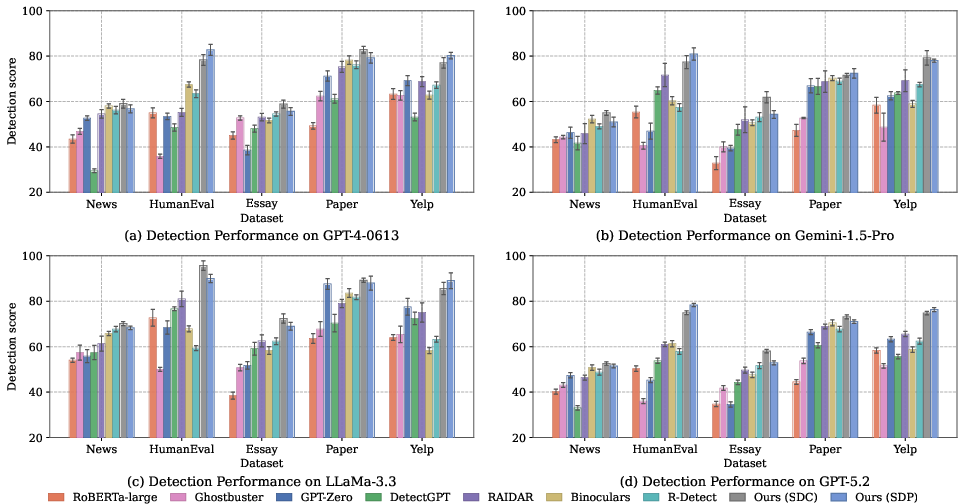
Figure 2: DSIPA demonstrates state-of-the-art F1 detection performance across all major domains and LLMs evaluated.
Domain-specific strengths are observed in code and academic writing, where existing detectors' effectiveness degrades sharply due to the specialized, structured, or neutral nature of the content. Notably, detection accuracy remains high as input length increases, confirming that DSIPA's sentiment-invariant signal integrates over both short and long context windows.
Cross-Model Generalization
Evaluation across sequential LLM generations (Text-Davinci-003 to GPT-5.2) and across five separate domains reveals that while baseline detectors' F1 scores often degrade as model fluency increases, DSIPA maintains robust performance. Variability in detection remains low (std. deviation of F1 scores <5%), confirming domain-agnostic applicability.
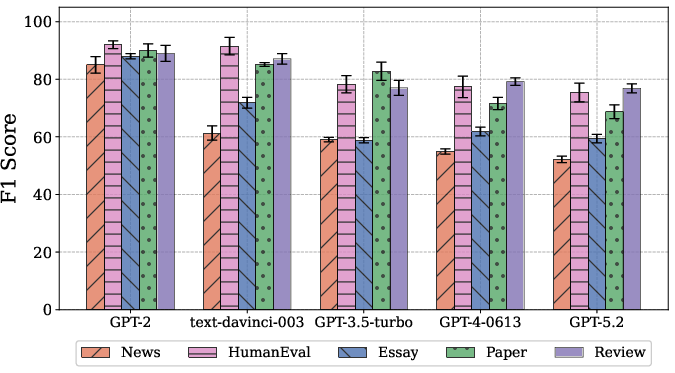
Figure 3: Comparative DSIPA performance scaling across successive GPT-series generations; consistent high accuracy is maintained.
Behavioral Basis—Distributional and Sequential Analysis
Distributional analyses illustrate non-overlapping, distinguishable sentiment stability profiles between human and LLM-generated content. LLM outputs cluster with low SDC/SDP variance, while human texts manifest higher dispersion. KL divergence between distributions remains consistently high across domains, signifying a persistent behavioral signal.
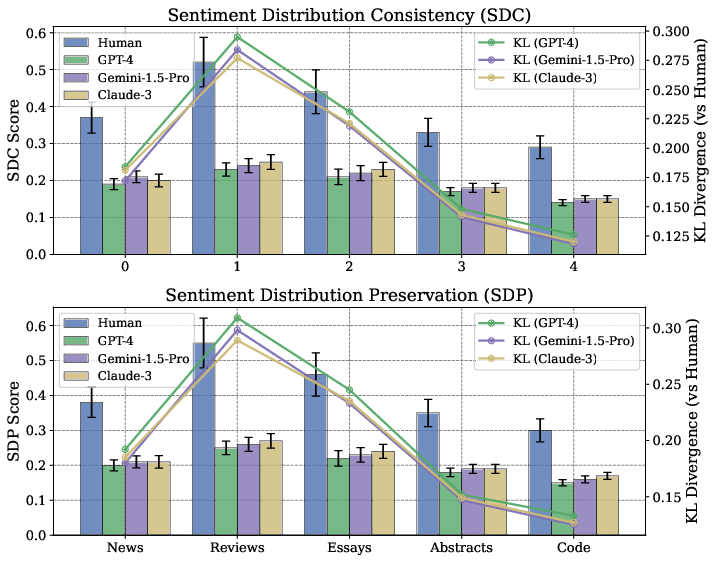
Figure 4: SDC and SDP metrics distinctively separate human and LLM-generated distributions across domains.
Further, the Emotional Shift Rate (ESR)—quantifying per-sentence sentiment trajectory—exposes low-variance affective dynamics in LLM outputs (∼0.15 mean ESR), contrasting with heightened volatility in human writing (∼0.31 mean ESR). This property persists even in genres with subdued emotional tone, emphasizing the rigidity of LLM affective structure.
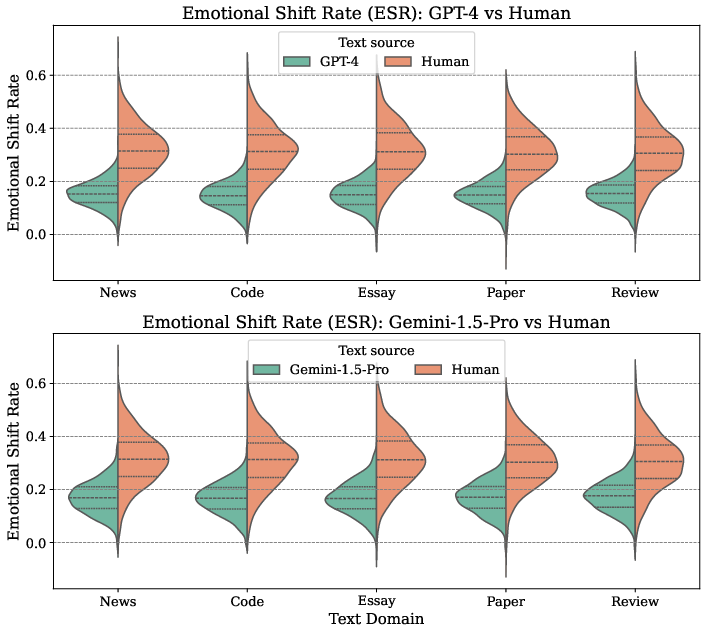
Figure 5: ESR distributions indicate lower affective dynamics for LLM texts compared to human-authored counterparts.
Robustness
DSIPA's performance under adversarial perturbations (TextAttack), paraphrasing, and round-trip back-translation is systematically analyzed. In all scenarios, DSIPA sustains the highest post-attack F1 scores and the smallest absolute degradation compared to baselines, reflecting the resilience of its high-level behavioral signal to lexical or surface statistical obfuscations.
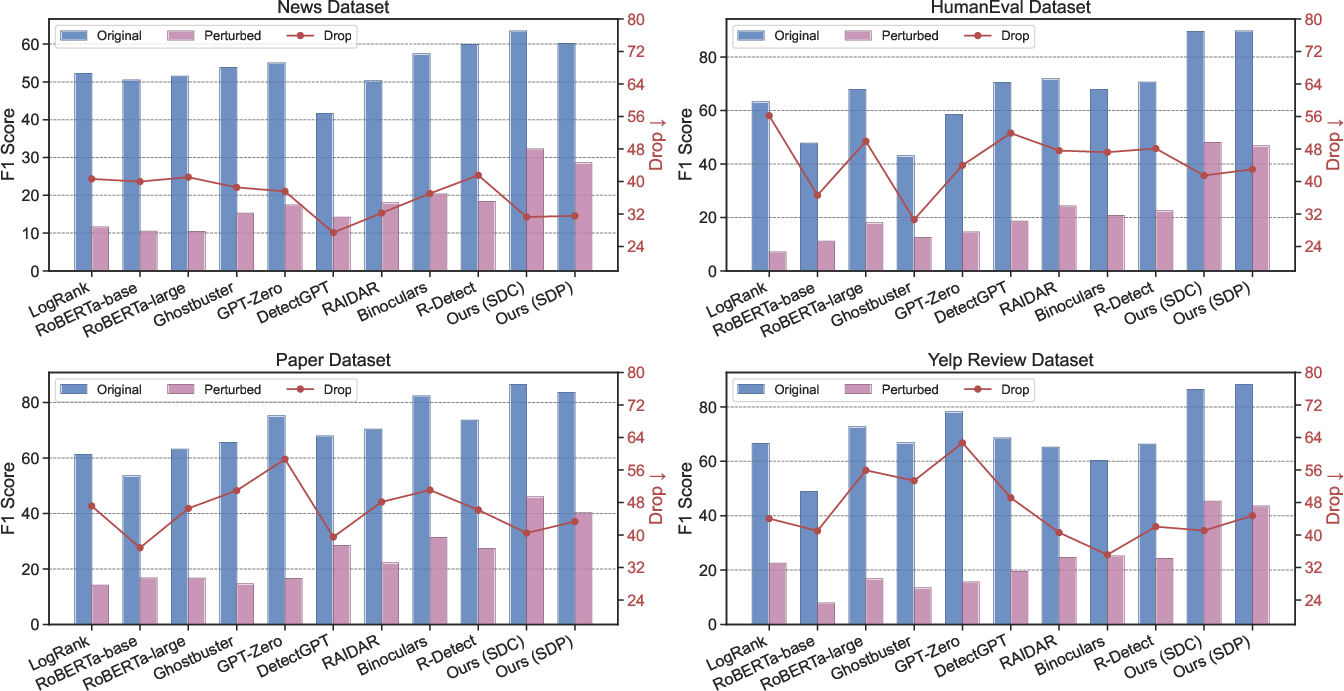
Figure 6: DSIPA demonstrates the smallest relative performance degradation under adversarial text perturbations.
Length variation experiments, scaling up to 1024-token input, establish that sentiment-invariant divergence features robustly aggregate with increased content, enabling high precision even for document-length detection.
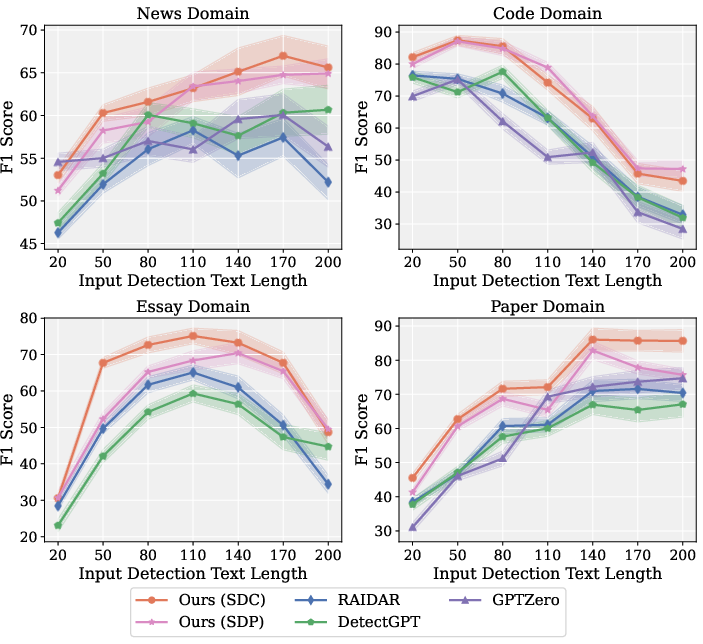
Figure 7: Detection reliability of DSIPA persists with increasing text length, outperforming baselines even for lengthy samples.
Computational Analysis
While DSIPA introduces computation overhead due to multi-prompt rewriting, it achieves favorable runtime-efficiency tradeoffs relative to other inference-intensive methods (2.18s/sample for 512 tokens at N=5 rewrites), and detection performance saturates beyond five rewrites, setting practical limits on resource usage.
Implications and Future Prospects
DSIPA reframes LLM detection as behaviorally grounded provenance inference, leveraging affective invariance as a robust and interpretable signal. Importantly, its training-free, black-box architecture allows operation over unseen models, proprietary APIs, and emerging open-source systems. Forensics, moderation, and security auditing stand to benefit from generalization capability, robustness, and interpretability.
Nevertheless, as LLMs are increasingly optimized for human-like affective variation or trained on adversarial feedback loops, the discriminative advantage of sentiment invariance may erode. Ongoing development of hybrid behavioral signals—combining affective, syntactic, and discourse-level features—will be critical for countering adaptive evasion strategies and sustaining detection capability in the LLM arms race.
Conclusion
DSIPA presents a highly effective, unsupervised, training-free detection framework for LLM-generated text. By operationalizing distributional and sequential sentiment stability as the core discriminative signal, it achieves robust, generalizable detection performance. Empirical evidence across models, domains, and adversarial regimes establishes the method's practical and theoretical contributions. Future work will integrate multifaceted behavioral priors for enhanced resilience as synthetic text generation continues to advance (2604.26328).

