- The paper introduces a novel taxonomy and benchmark (AITDNA) to evaluate AI-generated text detection under realistic, human-AI co-writing conditions.
- The paper finds that detection performance varies significantly with different notion granularities and threshold parameters, affecting policy implications.
- The paper emphasizes that explicit notion definitions and realistic dataset construction are key for reliable deployment of AI text detectors.
Redefining and Evaluating AI-Generated Text Detection under Realistic Assumptions
Introduction: AI-Generated Text Detection and Its Inherent Challenges
The problem of detecting AI-generated text (AITD) is critical as machine-generated content impacts scientific publishing, education, and the propagation of misinformation. However, the AITD literature implements highly heterogeneous definitions and assumptions regarding what constitutes “AI-generated text.” Most prior work evaluates detectors using notion-specific, often synthetic datasets misaligned with the nuanced, interactive realities of human-AI co-writing. This leads to unreliable generalization and hinders policy and practical deployment of detection systems.
Structuring Notions: Toward a Taxonomy of AITD
The study introduces a systematic framework for structuring the diverse AITD notions found in the literature, analyzing them along three axes: normative standards (what AI use is considered malicious/benign), genesis assumptions (the process of human and AI contributions to text creation), and attacker models (the ways AI-origin content can be obfuscated). Five prevalent AITD notions were formalized and expanded with two additional concepts—content-based and authorship-ID-based AITD—capturing underexplored but realistic use cases. The resulting taxonomy distinguishes surface-level, genesis-based (document-, boundary-, sentence-level) from population-based (membership, authorship-ID) and semantic (intent-, content-based) notions.

Figure 1: Structuring AITD notions, organizing detection concepts by genesis-based and population-based criteria.
The analysis demonstrates that existing AITD benchmarks and detectors implicitly assume specific genesis processes (such as en-bloc generation or fine-grained alternation between human and AI), and that these assumptions are rarely made explicit. The framework enables precise characterization of the segmentation and labeling process associated with each detection target, clarifying how policy requirements and attack models translate into evaluation labels.
Dataset Construction: AITDNA and Realistic Human-AI Co-creation
A novel benchmark, AITDNA, was created to support notion-agnostic evaluation, reflecting realistic human-AI collaborative writing. Utilizing a custom co-writing interface based on CARE, AITDNA logs not only the final text but also every human/LLM edit, scalar spans, and the intents behind each request. This allows for precise reconstruction of “genesis” for each token—critical for evaluating complex detection notions. The study protocol involves participants writing both human-only and human-LLM-coauthored documents across argumentative, creative, and scientific-expository tasks, with a diverse array of LLM configurations and writing scenarios.
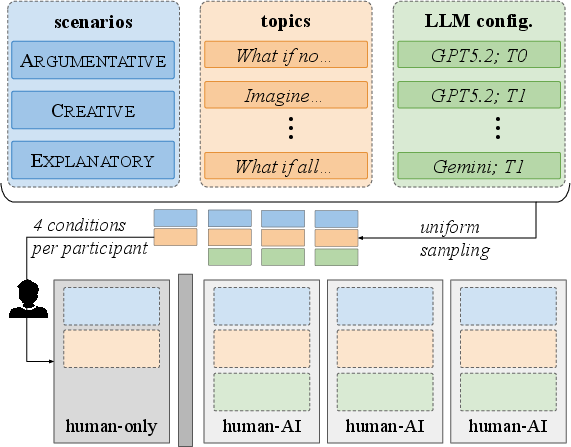
Figure 2: Study setup illustrating randomized assignment of scenario, topic, and LLM configuration to four experimental writing conditions.
Comparison to widely used AITD datasets shows that most prior data sources are not only smaller and less diverse but encode strong, misaligned assumptions about the frequency, granularity, and linguistic character of AI-human mixing.
Hidden Assumptions in Contemporary AITD Datasets
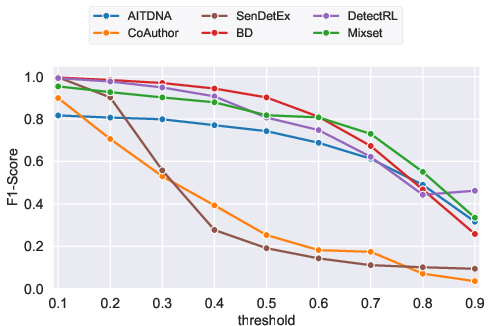
Quantitative and linguistic analysis reveals substantial differences between AITDNA and previous benchmarks with respect to the ratio of AI-generated text, the number of human-AI boundaries, and the linguistic traits of respective spans. For example, AITDNA exhibits a much higher degree of token-level mixing, whereas datasets like DetectRL or Mixset encode artificial alternation patterns and high proportions of AI content not reflective of authentic writing. The linguistic complexity and distributional properties of human versus AI spans in these datasets are not representative, as evidenced by systematic differences in reading-level metrics and syntactic depth.
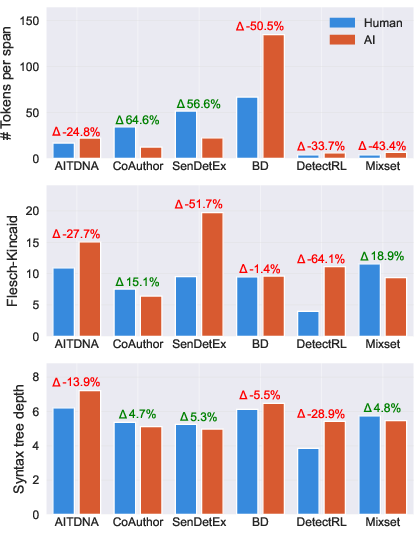
Figure 3: Comparative language characteristics of human and AI spans across datasets, highlighting normalized differences in complexity metrics.
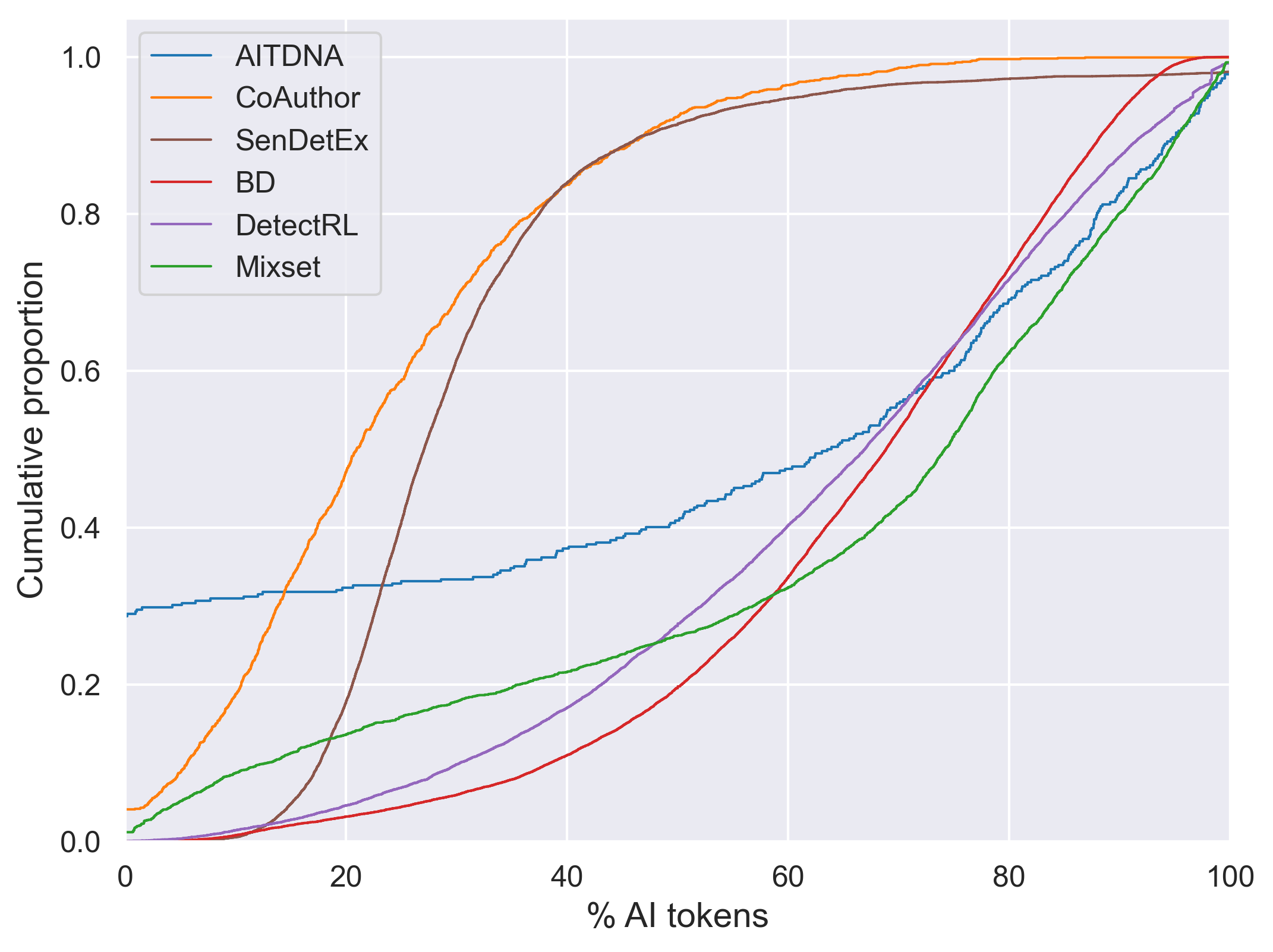
Figure 4: Empirical distributions of AI content ratios, showcasing the variability of τ assumptions across benchmarks.
This casts doubt on the external validity of prior experimental results, since detectors trained or benchmarked on such datasets may not transfer to naturalistic co-authored texts.
Empirical Evaluation: Notion Difficulty, Detector Robustness, and Parameter Sensitivity
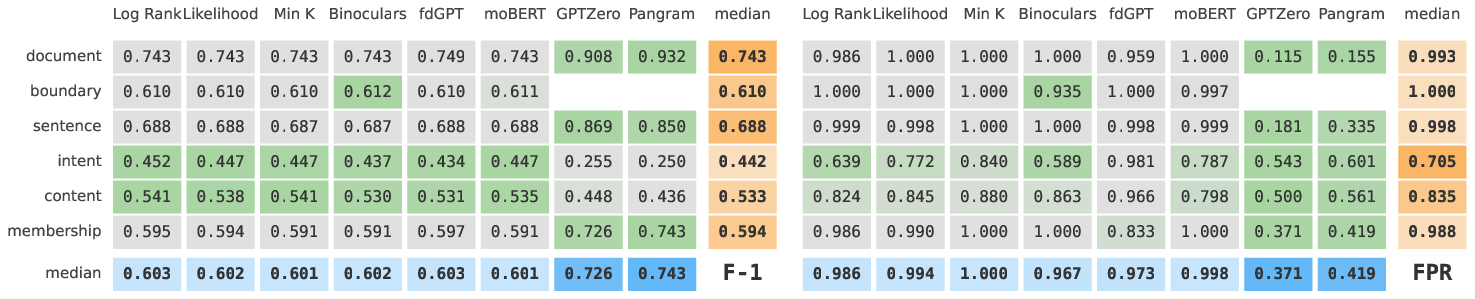
The experiments systematically evaluate eight leading AITD detectors (open and commercial) across the full set of notions and datasets, using granular, policy-aligned ground-truth labels derived from AITDNA. Key findings are:
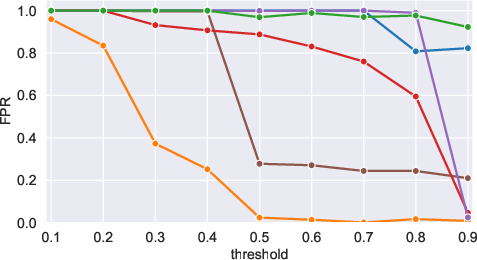
Figure 6: F1-score and FPR for the Likelihood method as a function of τ, illustrating the policy-performance tradeoff.
These results contradict the implicit claim that existing benchmarks or detectors are universally applicable. Performance is highly contingent on (often unspecified) notion parameters and the alignment of dataset genesis to the intended use case. This raises a risk of misinformed policy and technology deployment if these assumptions are not made explicit.
Methodological Implications and Future Directions
The study surfaces critical limitations in prevailing AITD methodology: synthetic data construction, under-reporting of notion parameters, and neglect of semantic and population-based detection targets. Notably, population-based notions—especially those built on authorship identification—are underexplored due to lack of appropriately constructed datasets. The AITDNA benchmark enables, for the first time, notion-agnostic, fine-grained evaluation and illuminates the path toward more robust AITD systems.
Theoretically, these findings argue for explicit reporting of notion specifications, attack models, and thresholding in all future work. Practically, deployment environments must map their policies and adversarial scenarios to the corresponding detection notion in use; otherwise, evaluation and operational results are not directly interpretable or translatable.
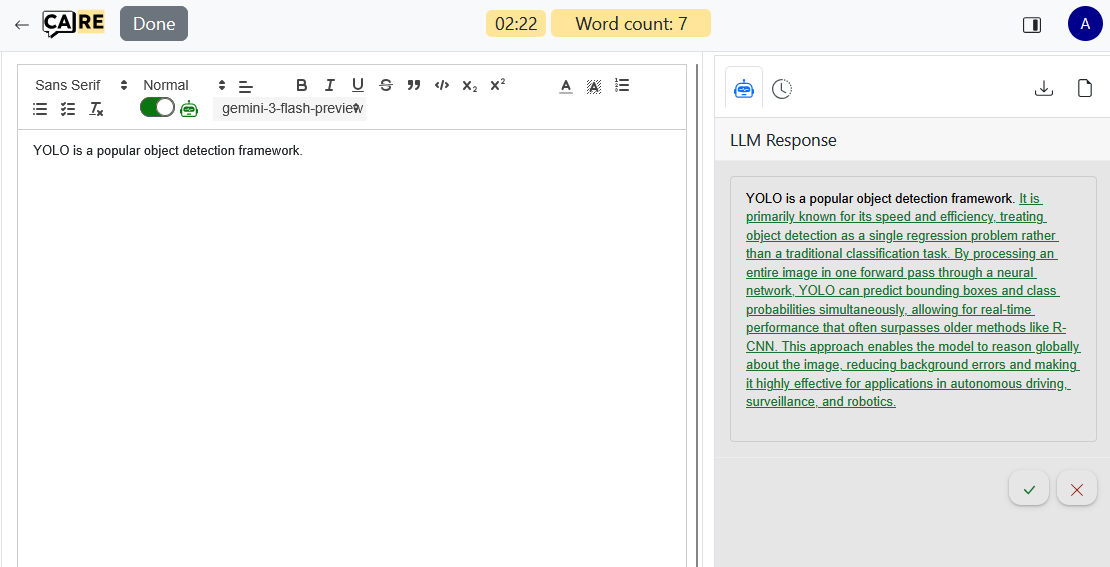
Figure 7: The CARE-based co-writing interface captures detailed genesis, revision, and human-LLM interaction meta-data for each token.
Conclusion
Redefining AI-generated text detection around explicit, policy-aligned notions illuminates previously unrecognized failure modes in dataset construction and detector evaluation. The introduction of AITDNA establishes a reference point for realistic, notion-agnostic benchmarking, and demonstrates that existing detectors and datasets are not robust to the full spectrum of practical scenarios. Alignment of detectors, datasets, and evaluation to clearly specified notions and parameters is essential for methodologically valid and societally useful progress in AITD. Future research must prioritize notion-diverse, genesis-aware benchmarking and the exploration of population-based and semantic detection strategies to meet evolving real-world needs.