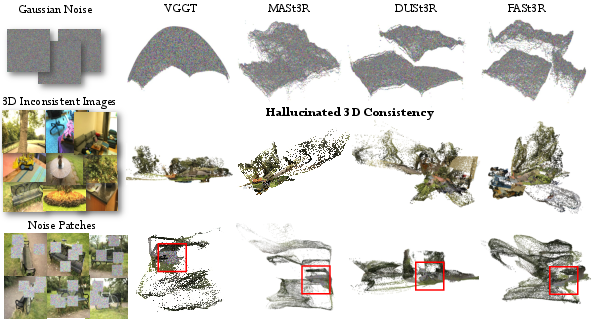
- The paper demonstrates that 3D foundation models can hallucinate plausible geometry even when inputs are inconsistent or corrupted.
- It introduces a unified parametric metric framework that decomposes evaluation into backbone, residual, and aggregation components.
- Results indicate that classical COLMAP-based metrics align more closely with human judgments than neural metrics under severe corruptions.
Evaluating 3D Consistency Under Hallucinated Geometric Priors: An Analysis of "Can These Views Be One Scene?" (2605.18754)
Introduction and Motivation
The paper "Can These Views Be One Scene? Evaluating Multiview 3D Consistency when 3D Foundation Models Hallucinate" addresses a critical issue in the current landscape of 3D vision: the reliability of multiview 3D consistency metrics, particularly when data-driven 3D reconstruction backbones hallucinate plausible geometry even for fundamentally inconsistent or corrupted inputs. Given the proliferation of generative novel view synthesis (NVS) and sparse-view 3D reconstruction pipelines—often trained or deployed on internet-scale, noisy, or adversarial data—the need for robust, interpretable, and human-aligned consistency metrics is acute. The work systematically deconstructs and evaluates the failure modes of learned 3D backbones, proposes a unified parametric metric framework, and introduces controlled robustness benchmarks and classical geometry-based evaluators.

Figure 1: The challenge—inputs that do not define a static 3D scene (unrelated scenes, repeated views, or noise) are still reconstructed as plausible geometry by learned backbones, resulting in spuriously high consistency scores.
Unified Parametric Metric Framework
A cornerstone of the study is the formalization of neural, ground-truth-free multiview 3D consistency metrics as a backbone–residual–aggregation pipeline. Here, the backbone (B) is a learned reconstruction model (e.g., MASt3R, Fast3R, VGGT), the residual function (ρ) computes dense cross-view feature dissimilarities (DINOv2/FeatUp), and the aggregation function (A) reduces the distribution of discrepancies to a scalar metric. This formalism cleanly subsumes existing metrics (notably MEt3R) and enables analytic ablation across each component.
Key details:
- Backbones: Include pairwise (MASt3R, DUSt3R) and joint/global (Fast3R, VGGT) reconstruction models.
- Residuals: Include both warp-based and point-consistency residuals, capturing feature consistency pinned to candidate correspondences.
- Aggregations: Extend beyond the mean to distributional measures (MMD, energy distance, IMQ kernel), increasing sensitivity to outliers and multi-modal residuals.
Robustness Benchmark: SysCON3D
To expose and quantify metric brittleness, the SysCON3D benchmark introduces controlled multiview input corruption:
- Cross-scene mixtures with varying outlier rates (L1, L2, L3).
- Patched or full Gaussian noise.
- Repeated/identical views.
Metrics are evaluated on their ability to both separate consistent from inconsistent inputs (Cohen's d, win rate) and recover the expected severity ranking.
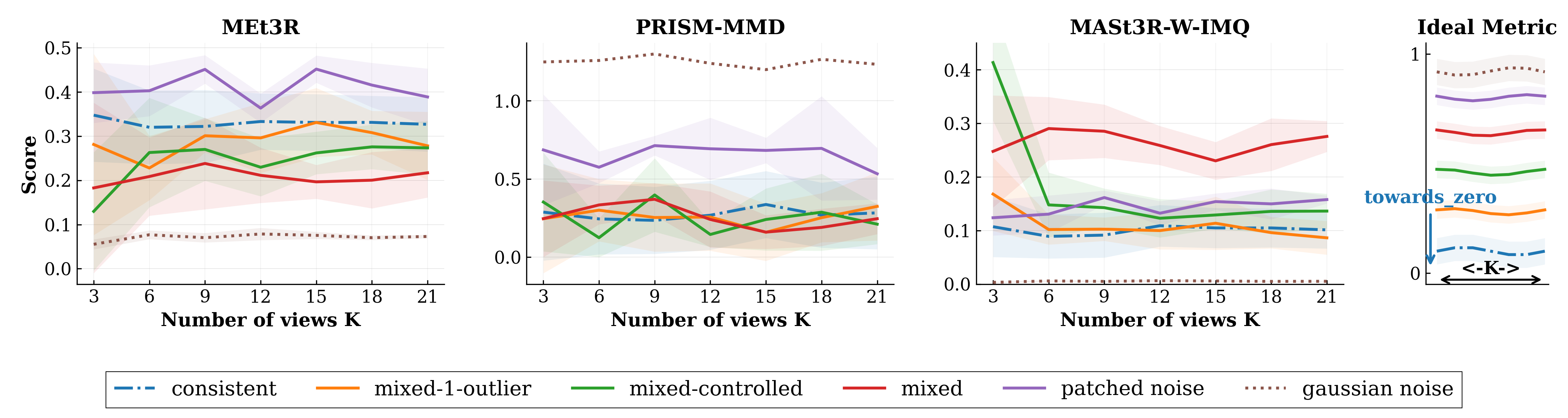
Figure 2: Metric trends across SysCON3D—desired behavior is clear separation by 3D consistency, which most learned metrics fail to achieve, especially under severe corruption.
Analysis of Reconstruction Backbone Failures
One of the most consequential findings is that learned reconstruction backbones (VGGT, MASt3R, DUSt3R, Fast3R) systematically hallucinate 3D geometry even on utterly inconsistent or random inputs, including complete noise. This undermines the very notion of geometric support as evidence-based and renders many backbone-based metrics unreliable.
Quantitative diagnostics reveal high rates of cross-scene overlap (e.g., DUSt3R reports overlap on 69% of random pairs where the correct answer is 0%), confidence scores that do not drop reliably on failure cases, and significant "ghost mass"—pixels supported by points from unrelated scenes.

Figure 4: Fast3R, MASt3R, and VGGT all reconstruct dense, structured (but hallucinatory) geometry from Gaussian noise inputs (K=3, seed 3045).
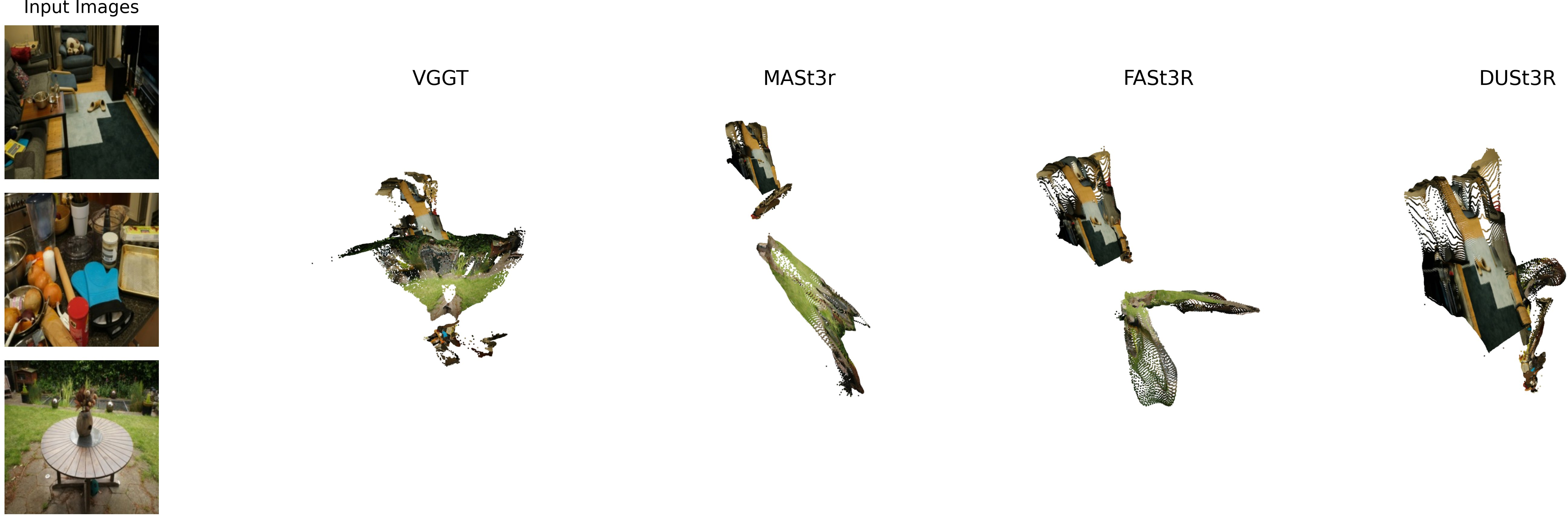
Figure 5: The same backbones reconstruct plausible-seeming geometry even from random mixtures (L3) with no shared physical scene.
Distributional Aggregation: Substituting mean aggregation with distributional measures (e.g., IMQ-MMD, energy) improves robustness, particularly for severe mixture corruptions (L3), with up to 3× improvement in win rate over MEt3R. However, no neural metric achieves robust separation for all failure modes. Notably, performance on noise remains poor, as residual distributions lack informative separation when the backbone reconstructs degenerate geometry.
External Baselines: Metrics like PRISM-MMD and TSED, which leverage classical geometric constraints or object-level embedding anchors, show stronger alignment with control-task ground truth.
Classical Geometric Verification: COLMAP-Based Metrics
Classical structure-from-motion (COLMAP) is introduced as an alternative, leveraging explicit feature matching, RANSAC-based inlier detection, pose estimation, and photometric-geometric depth agreement. Critically, these pipelines can fail safely (e.g., inability to register cameras, sparse geometry only), and failures are directly measurable.
Metrics based on COLMAP (W-GPC, ICM, coverage) show:
- Zero support on noise or scene mixtures—hard rejection, unlike neural backbones.
- Up to ρ0 higher correlation with human evaluation on real NVS outputs.
- Robust ranking of SysCON3D variants, faithfully capturing severity orderings.
Alignment with Human Judgment
A structured human evaluation is performed over NVS outputs (DL3DV, Mip-NeRF360 datasets) for eight methods, scoring 3D consistency, realism, and plausibility independently.
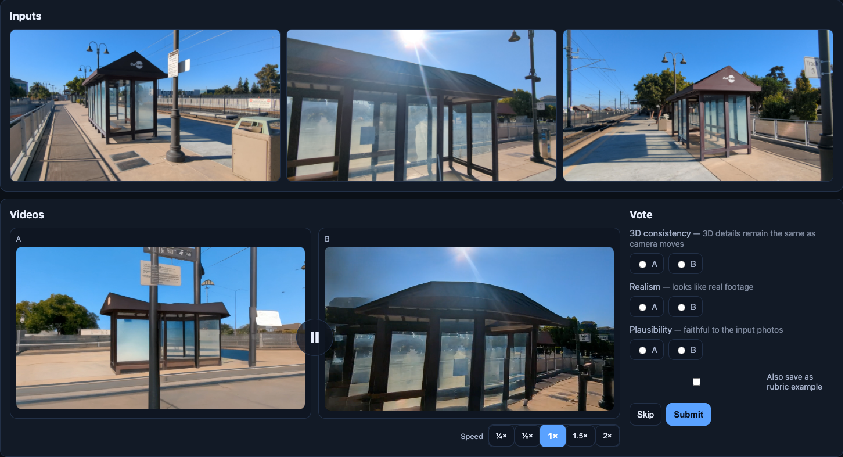
Figure 6: Human evaluation interface—participants make forced A/B choices on 3D consistency, realism, and plausibility, with ratings aggregated via a multi-axis Elo protocol.
Findings include:
- Neural metrics with improved aggregation (e.g., MASt3R-W-IMQ) achieve moderate Spearman correlation with human rankings (ρ1 up to 0.48 on DL3DV for ρ2), but are still outperformed by COLMAP-based metrics (ρ3 up to 0.98).
- COLMAP scores offer interpretable, failure-aware rankings, and flag fundamentally inconsistent or low-quality input sets.
Theoretical and Practical Implications
Theoretical Implications
- Failure of Priors as Evaluators: Data-driven priors, trained to always reconstruct geometry, are fundamentally misaligned with the needs of a geometric verifier. Backbones that cannot abstain or express calibrated uncertainty confound the interpretation of scene consistency.
- Limits of Aggregation: Residual-distribution aggregation improves robustness but cannot completely recover from errors originating at the backbone level.
- Necessity of Failure-Awareness: Reliable metrics in open-set or adversarial settings must incorporate explicit geometric verification, capable of refusing to assign support in the absence of evidence.
Practical Recommendations
- Metric Selection: In high-noise, uncurated, or safety-critical domains, usage of COLMAP-based metrics (W-GPC, ICM) is recommended, with neural metric outputs (such as MASt3R-W-IMQ) serving only as secondary diagnostics.
- Interpretation of Scores: Large disagreement between COLMAP-based and neural metrics should trigger manual review or further investigation.
- Model Use: Learned backbones retain value as fast diagnostics when input quality is assured and may serve as viable metrics if future advances address the hallucination issue.
Future Directions
- Developing abstaining or uncertainty-calibrated 3D backbones, capable of expressing when scene evidence is insufficient.
- Hybrid metrics that combine data-driven geometric priors with explicit geometric verification for context-sensitive robustness.
- Adversarial and open-set evaluation: Expansion of benchmarks like SysCON3D to encompass broader, more naturalistic corruptions and real-world data characteristics.
Conclusion
This work rigorously diagnoses the failure modes of current ground-truth-free multiview 3D consistency metrics, revealing that learned 3D backbones hallucinate geometric evidence in the face of inconsistent or nonsensical inputs—a fact that breaks the trustworthiness of automated evaluators. By introducing systematic robustness benchmarks (SysCON3D), a parametric metric decomposition, and interpretable COLMAP-based verification metrics, the authors provide both analytic clarity and practical tools for the NVS and 3D vision community. The results argue definitively for the integration of explicit geometric verification in any setting where robustness and alignment to human judgement are required, and call for the development of new backbones and metrics that respect the distinction between reconstruction and verification.
References:
"Can These Views Be One Scene? Evaluating Multiview 3D Consistency when 3D Foundation Models Hallucinate" (2605.18754)