- The paper presents a rigorous benchmark comparing traditional SfM+MVS pipelines with end-to-end learning-based approaches for photogrammetric 3D reconstruction.
- It evaluates methods using UAV datasets by analyzing metrics such as RMS error, mean distance, and surface coverage to reveal trade-offs between speed and fidelity.
- The study highlights the potential of hybrid architectures that integrate explicit geometry with deep learning to achieve scalable and accurate 3D mapping.
Comparative Analysis of Multi-View Stereo Methods for Photogrammetric 3D Reconstruction
Introduction
The paper "A Comparison of Multi-View Stereo Methods for Photogrammetric 3D Reconstruction: From Traditional to Learning-Based Approaches" (2604.10246) presents a rigorous benchmark of modern photogrammetric 3D reconstruction techniques. It systematically contrasts traditional Structure-from-Motion (SfM) and Multi-View Stereo (MVS) pipelines—chiefly exemplified by COLMAP—with a spectrum of recent learning-based MVS algorithms, spanning both geometry-guided and end-to-end deep neural architectures. The evaluation leverages high-resolution UAV-derived datasets of challenging island and urban scenes, employing normalized distance metrics and coverage to dissect both geometric fidelity and practical scalability.
Methodological Overview
The comparison encompasses three categories of methods:
Experimental Design and Dataset
Two UAV photogrammetry datasets are utilized: the MARS-LVIG island set with LiDAR ground-truth, and a Pix4D urban set with Pix4Dmapper-generated point clouds as references. Both feature high image resolution and complex scene variability. Scaling and rescaling protocols are enforced for cross-method fairness, including 512-pixel input normalization for learning-based models, and camera pose extraction consistency for geometry-guided algorithms.
A progressive input selection strategy probes each method’s scaling characteristics, incrementally increasing the number of views (2, 10, 20, 50, 100) to interrogate both computational efficiency and the impact on accuracy/completeness.
Runtime and Scalability Analysis
Dense MVS reconstruction demands substantial computation, with traditional approaches (e.g., COLMAP) incurring prohibitive costs: COLMAP requires up to 1326 seconds for 100 images on the island dataset, with similar trends observed in urban cases. Geometry-guided learning-based methods inherit this bottleneck due to their reliance on sparsely reconstructed upstream models. Where traditional SfM fails at registration, these methods cannot proceed at all.
End-to-end learning-based approaches vary significantly in scalability. DUSt3R and MASt3R support only limited multi-view fusion before runtime escalates impractically and memory constraints emerge. VGGT and especially Fast3R, by leveraging transformer architectures and efficient attention mechanisms, exhibit markedly faster inference: Fast3R completes 100-image reconstructions in less than 20 seconds, an order-of-magnitude improvement over both traditional and other learning methods.
Failure Modes and Qualitative Assessment
Qualitative inspection reveals that, across all non-traditional methods, significant artifacts—primarily discontinuities, layerings, and surface deformations—persist in large-scale aerial contexts. These errors are exacerbated in textureless or repeating-pattern areas (e.g., vegetation, rooftops, water), where both geometric cues and learned priors provide insufficient constraint.

Figure 2: Failure cases on the Island dataset with 50 images; red circles highlight regions of discontinuities and layering.

Figure 3: Failure cases on the Urban dataset with 50 images; local boundary artifacts due to correspondence ambiguities are shown.
Accuracy and Coverage Benchmarking
Quantitative evaluation uses normalized root mean square (RMS) and mean distance (MD) between reconstructed and ground-truth point clouds, alongside proportion-of-surface coverage.
- In sparse-view (2 images) regimes, DUSt3R delivers highest pointwise accuracy (2.88 GSD RMS and 2.21 GSD MD on Island). However, as the number of views increases, DUSt3R’s accuracy degrades sharply—RMS error surpasses 9 GSD at 20 views—indicative of insufficient geometric integration or fusion inconsistencies.
- VGGT demonstrates greater resilience as image count grows, with only moderate performance degradation. Its coverage remains the most stable across all scenes and input sizes.
- Fast3R offers the fastest runtime but consistently lower coverage and larger residual error, suggesting a trade-off between inference speed and dense geometric consistency.
- MASt3R outperforms on sparse input but sharply declines as input size scales, suffering from poor multi-view fusion and pronounced structural artifacts.
- FoundationStereo and Stereo4D are restricted to two-view matching and fail outright on these aerial datasets due to pervasive distortions and discontinuities in output point clouds.
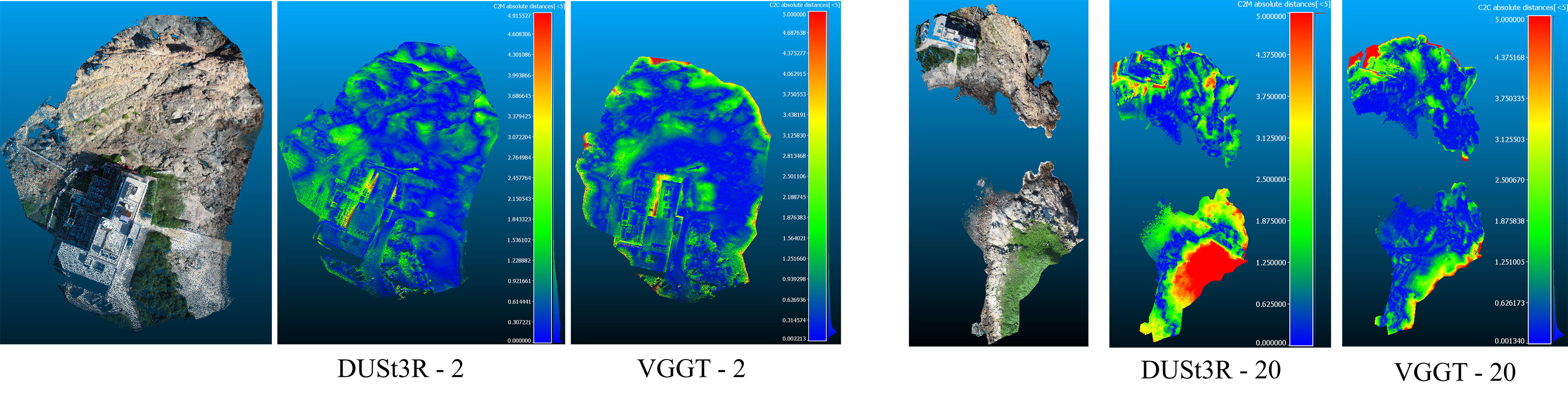
Figure 4: Error maps for DUSt3R and VGGT reconstructions on the Island dataset, contrasting low (2) and moderate (20) input views; blue indicates higher fidelity, red higher error.
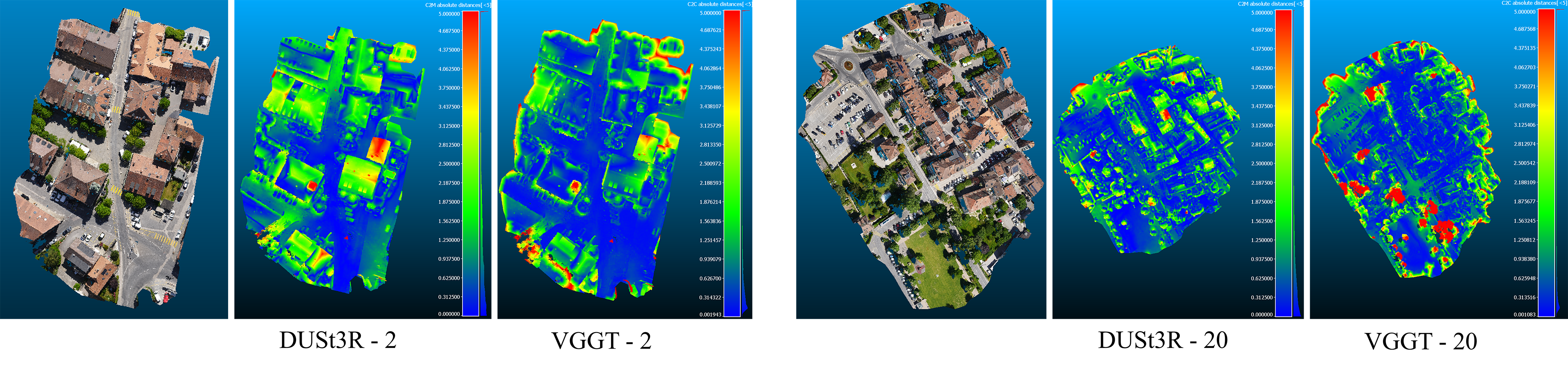
Figure 5: Error maps for DUSt3R and VGGT reconstructions on the Urban dataset, with the same color coding as Figure 4.
Coverage analysis exposes the limitations of most approaches in complex aerial scenes. DUSt3R achieves the highest coverage in two-view settings, but its recall collapses with larger input sizes. VGGT maintains ~70% coverage even at increased view counts. Fast3R reconstructs less than half the reference surface in most cases, despite its speed.
Implications and Prospects
The findings establish that end-to-end transformer-based learning systems, particularly VGGT and Fast3R, now rival or surpass traditional MVS paradigms in runtime and can support large-scale photogrammetric mapping in practice. Nonetheless, persistent problems—residual geometric errors, local layering artifacts, and susceptibility to poor texture or repetitive structure—still preclude these methods from mission-critical high-precision mapping applications.
From a theoretical perspective, the results corroborate that learning-based models have not fully solved the global consistency and geometric integration challenges inherent in multi-view photogrammetry. The inability of geometry-guided deep models to function without reliable pose priors highlights the absence of true geometric self-sufficiency.
For practical deployment, these results suggest the necessity of hybrid architectures: fusing explicit geometry, pose-aware priors (potentially from SLAM or other sensor modalities), and scalable deep networks to achieve both efficiency and fidelity. Future developments are likely to focus on fully integrating pose estimation into end-to-end frameworks, improving robustness to outlier structure and texture ambiguity, and adopting scalable global optimization layers within neural architectures.
Conclusion
The study provides a substantive baseline for the current state of MVS technologies in aerial photogrammetric mapping. While end-to-end learning-based methods, particularly transformer-based architectures like VGGT and Fast3R, offer clear advances in efficiency and robustness, further research is required to resolve fundamental accuracy bottlenecks. Continued investigation into geometry-aware deep architectures and scalable fusion of auxiliary priors will be critical for closing the gap between algorithmic generality and the demands of large-scale, high-precision 3D mapping.
