- The paper introduces Code-as-Room, a multi-stage pipeline using top-down images to generate 3D rooms through executable code synthesis.
- Code-as-Room significantly enhances spatial accuracy and room completeness, achieving 93.5% rotation accuracy and 100% pipeline completion rates.
- The framework integrates cross-stage memory for information retention, resolving spatial errors and infinite loops in generative processes.
Code-as-Room: Agentic 3D Room Generation from Top-Down Images via Code Synthesis
Motivation and Background
Designing fully functional and realistic 3D indoor rooms is a core challenge for interior design, VR, gaming, and embodied AI. Traditional graphics and procedural methods leverage hand-crafted rules, constraint systems, and design templates but lack flexibility in modeling complex spatial relationships and diverse user preferences. Recent multimodal LLMs (MLLMs) have been applied to 3D room generation, mainly through text instruction-driven pipelines or structured data representations (e.g., JSON). However, text inputs fail to capture explicit spatial priors, leading to suboptimal room layouts and object placements. Image-conditioned agents, such as VIGA, have attempted direct room synthesis from visual input, but struggle with fine spatial alignment, instability, and endless loops.
Code-as-Room (CaR) addresses these deficiencies by leveraging top-down room images as explicit spatial priors and structuring generation as a multi-stage agentic pipeline rooted in executable Blender code. The framework activates the code-generation capacity of MLLMs and overcomes context forgetting via a persistent cross-stage memory system.

Figure 1: Code-as-Room enables interactive 3D room synthesis from a single top-down view image, harnessing structured agentic execution and MLLM capabilities for parsing, design, and Blender coding.
Methodology: Structured Agentic Pipeline
The CaR pipeline operates across five specialized stages, leveraging a cross-stage memory for coherent information retention and robust code generation from a single image.
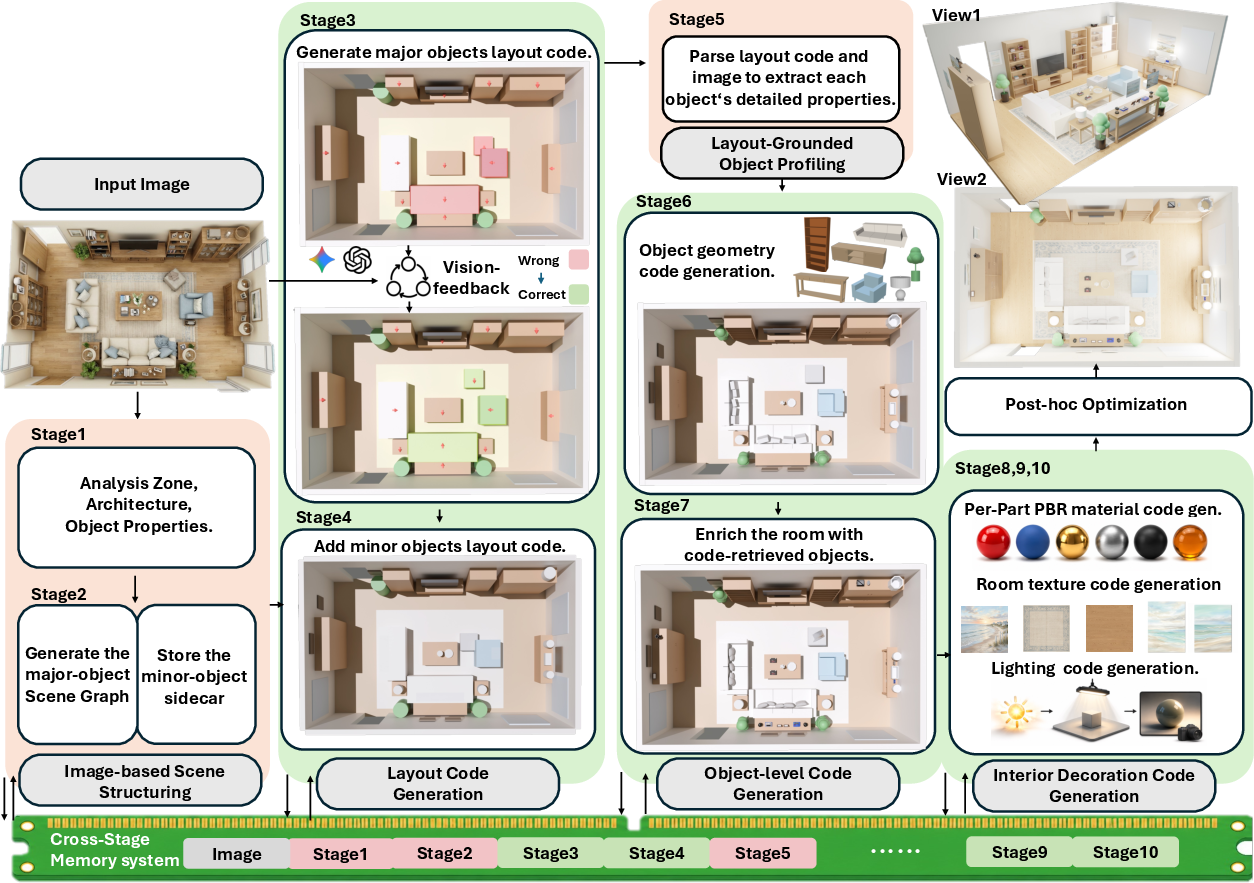
Figure 2: Code-as-Room pipeline: sequential MLLM agent stages progressively convert a top-down image into a complete 3D room, each reading and writing to cross-stage memory for context stability.
1. Image-Based Scene Structuring:
The first stage parses the top-down image to recognize major furniture, accessory items, and interior finishes, building a scene graph to capture spatial relationships and functional zones.
2. Layout Code Generation with Visual Feedback Loop:
Scene elements are instantiated in Blender using bounding-box proxies. A render-and-compare loop refines placement and spatial relations, incorporating iterative feedback from MLLM-based critics to maximize layout alignment.
3. Object Profiling and Code Generation:
Each object is profiled for appearance, part structure, materials, and functional characteristics. Geometry is synthesized via procedural part primitives, and asset retrieval augments representation for small, complex items.
4. Interior Decoration (Material, Texture, Lighting):
Semantic part-level materials, textures, and lighting configurations are systematically assigned. Large surfaces and decorations leverage image generation models for texture synthesis, maintaining spatial alignment.
5. Post-Hoc Correction and Finalization:
Deterministic corrections ensure boundary consistency, resolve collisions, and guarantee Blender code executability.
Cross-stage memory persists artifacts at each phase, preserving global context and eliminating information loss during multi-agent orchestration.
Benchmarking and Evaluation
CaR includes a dedicated benchmark for code-based 3D room synthesis, encompassing visual understanding, spatial reasoning, vision-to-code capabilities, and holistic scene quality. Comparative experiments use leading MLLMs: Gemini-3 Flash, Gemini-3.1 Pro, and GPT-5.5, as well as direct generation and VIGA baselines.

Figure 3: Qualitative comparisons of benchmark tasks: CaR-equipped Gemini models generate more spatially aligned, complete 3D rooms than direct VLM-based approaches.
CaR substantially enhances all backbones in object recall, layout IoU, spatial relation accuracy, and code execution rate. Gemini variants, when paired with CaR, achieve up to 93.5% rotation accuracy, 88.42% functional region accuracy, and 100% pipeline completion, strongly outperforming direct GPT-5.5 and VIGA. The structured harness prevents infinite loops and stabilizes generation.

Figure 4: Representative qualitative results: CaR produces more coherent furniture arrangements, richer local details, and enhanced scene usability.
Human expert evaluations corroborate quantitative metrics, with CaR-Gemini3.1-Pro achieving highest scores for similarity, usability, and acceptability. Notably, VIGA lags behind in spatial precision and detail richness.
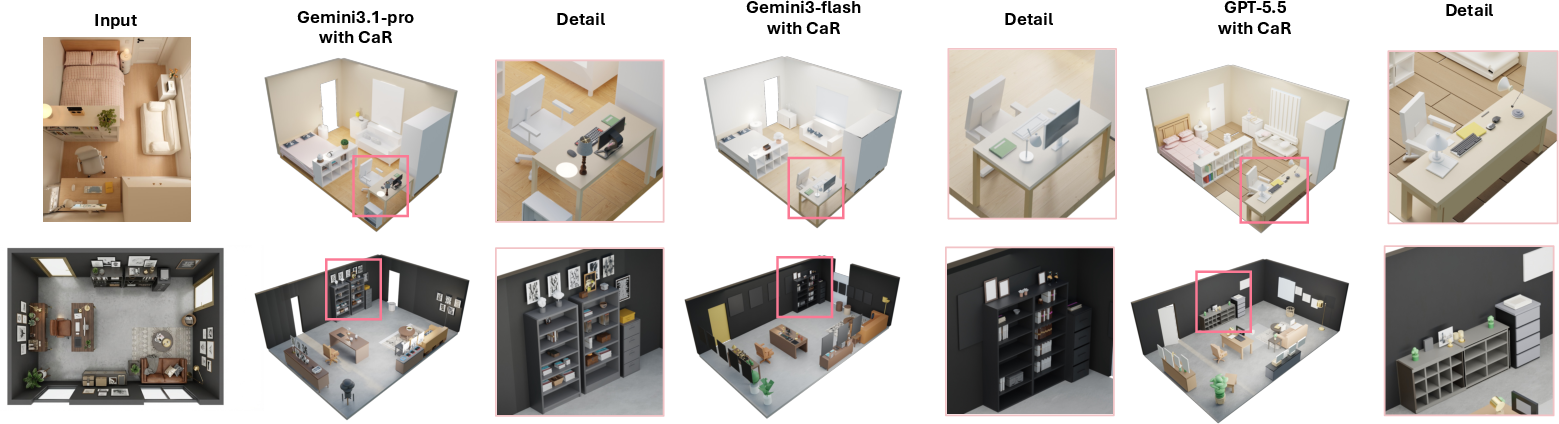
Figure 5: Detailed qualitative analysis: CaR variants recover nuanced local structures and precise spatial relationships missed by baselines.
Comparisons show CaR significantly reduces self-overlap and spatial errors versus both direct VLM generation and VIGA, improving scene completeness and alignments.

Figure 6: Comparative performance: Gemini 3.1-Pro + CaR outclasses VIGA in spatial reasoning, object recovery, and overall qualitative metrics.
Scene Re-Rendering and Visual Enhancement
The geometric consistency of CaR-produced rooms allows for downstream rendering enhancement via image translation. Utilizing GPT-5.5, base scenes are visually refined, yielding more realistic materials, illumination, and object fidelity while retaining exact spatial priors.

Figure 7: Visual enhancement: base 3D scenes (left) transformed into photorealistic renderings (right) by GPT-5.5, showing potential for neural rendering pipelines.
This indicates the utility of CaR outputs as structural priors for high-fidelity visual refinement and downstream applications in VR and embodied AI.
Ablation Studies
Ablation analyses reveal the criticality of the cross-stage memory and visual feedback iterations. Disabling memory drops object recall by 7.3% and layout IoU by 15.2%. Excessive feedback iterations (>5) induce layout drift and degrade spatial alignment. Optimal pipeline configurations balance refinement granularity with computational efficiency.
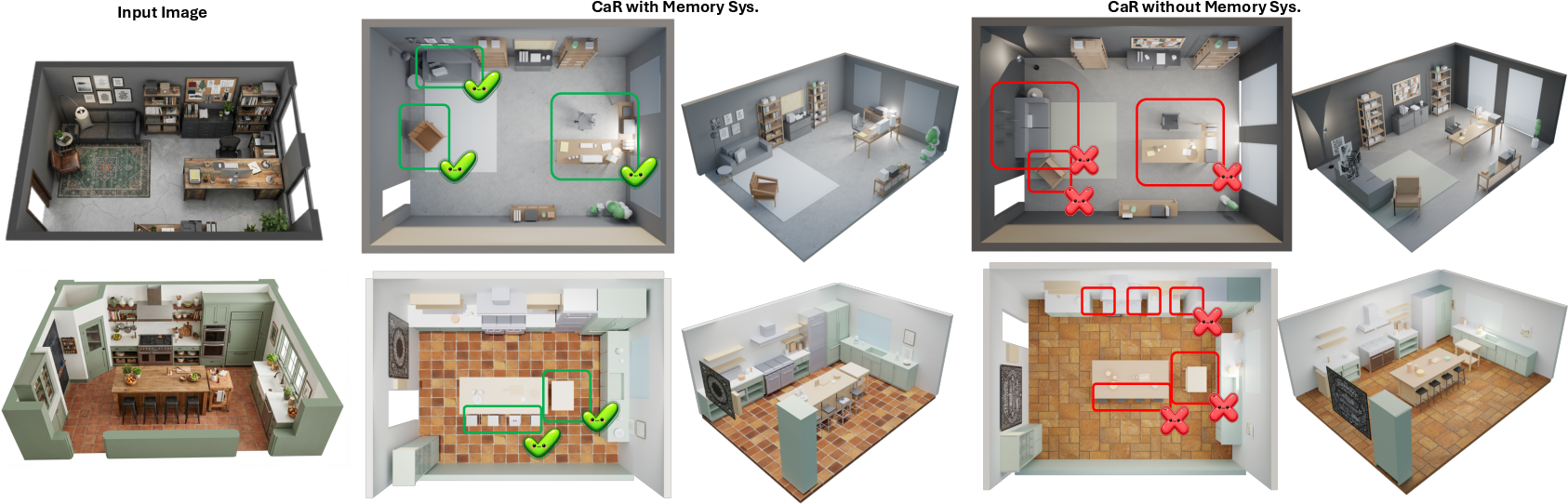
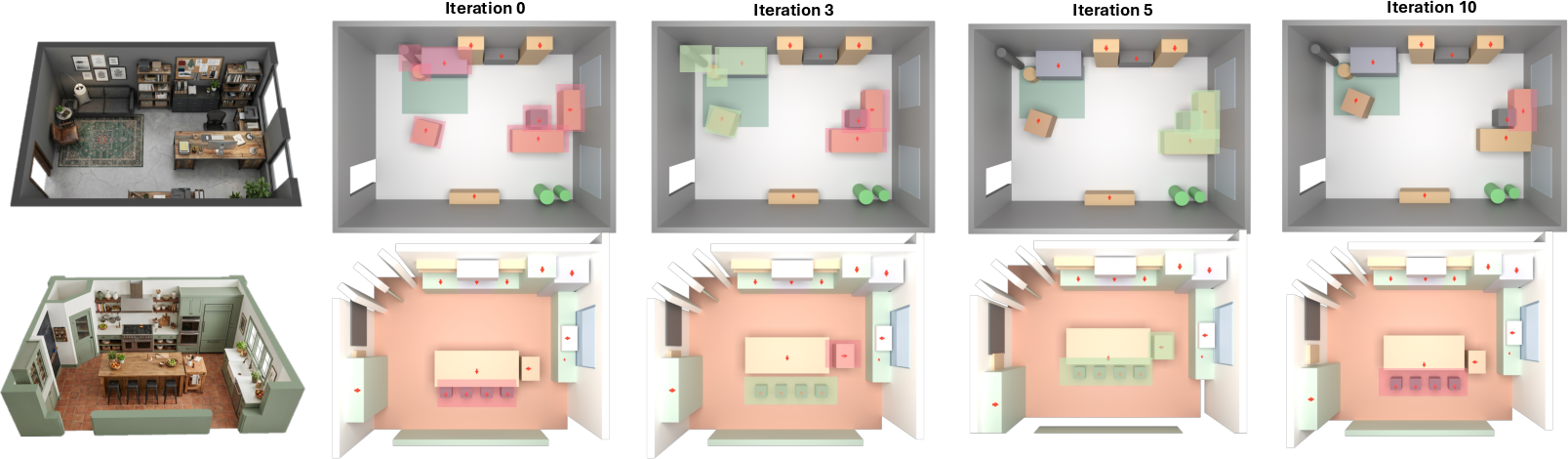
Figure 8: Ablation study: memory and feedback loop are vital for spatial accuracy and object recalls, with over-iteration leading to diminishing returns.
Implications and Future Work
CaR operationalizes top-down image input as a spatial prior for 3D scene construction, bridging the gap between real-world design workflows and agentic AI-based synthesis. The structured harness allows stable and interpretable generative pipelines, facilitating iterative editing and multi-modal interaction.
Practically, CaR is applicable to interior design, VR prototyping, digital twin creation, robotics simulation, and generative content for gaming. Theoretically, it demonstrates the importance of agentic orchestration, visual feedback, and memory persistence in bridging visual grounding and code-based generative reasoning.
Limitations include current restriction to top-down views and procedural code alignment challenges for complex real-world objects. Neural rendering, improved asset retrieval, and generalization to arbitrary-view inputs represent ongoing research directions.
Conclusion
Code-as-Room presents a robust, multi-stage agentic framework for 3D room synthesis from top-down images, utilizing MLLM-driven code generation and structured execution harnesses. Extensive benchmarks and human studies confirm significant improvements over prior baselines in spatial reasoning, scene completeness, and usability. Future extensions will address arbitrary-view inputs and further integrate neural rendering models for refined visual outputs.