ShowRoom3D: Text to High-Quality 3D Room Generation Using 3D Priors
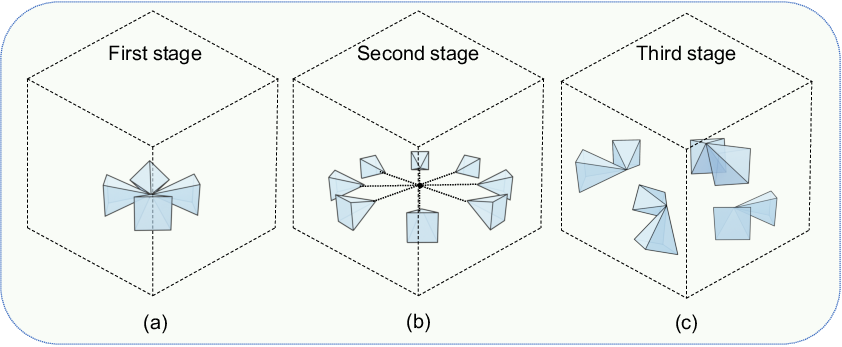
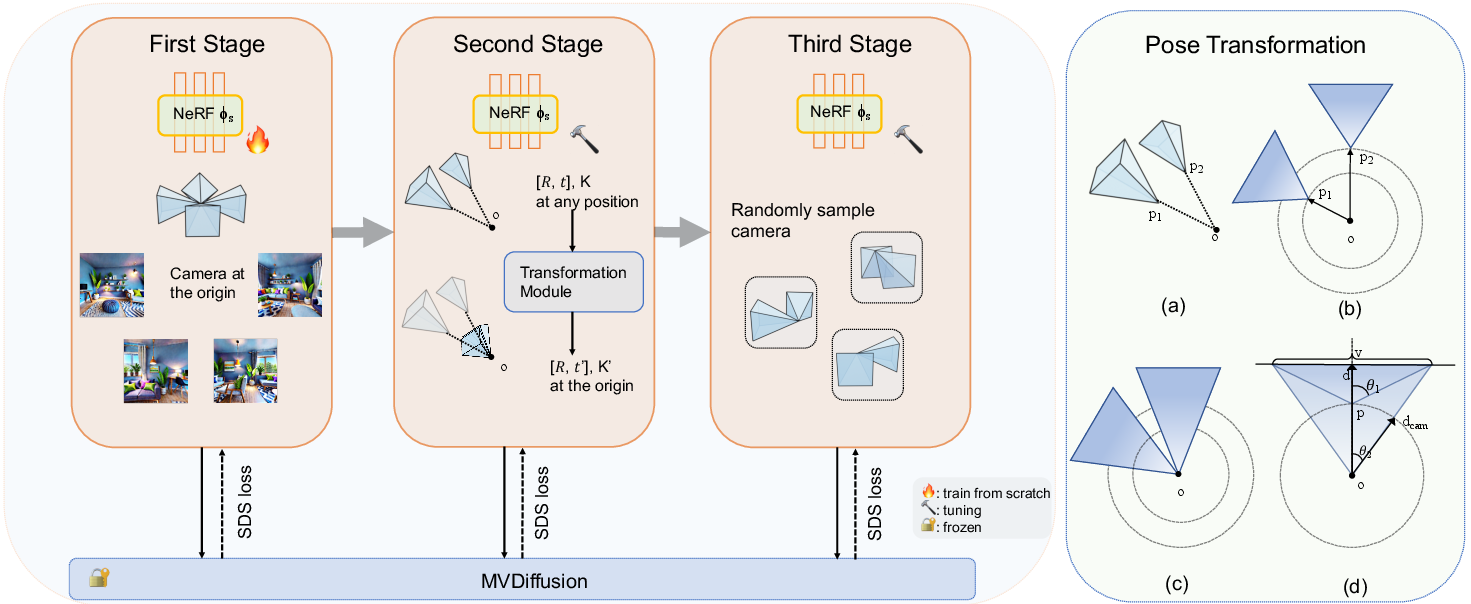
Abstract: We introduce ShowRoom3D, a three-stage approach for generating high-quality 3D room-scale scenes from texts. Previous methods using 2D diffusion priors to optimize neural radiance fields for generating room-scale scenes have shown unsatisfactory quality. This is primarily attributed to the limitations of 2D priors lacking 3D awareness and constraints in the training methodology. In this paper, we utilize a 3D diffusion prior, MVDiffusion, to optimize the 3D room-scale scene. Our contributions are in two aspects. Firstly, we propose a progressive view selection process to optimize NeRF. This involves dividing the training process into three stages, gradually expanding the camera sampling scope. Secondly, we propose the pose transformation method in the second stage. It will ensure MVDiffusion provide the accurate view guidance. As a result, ShowRoom3D enables the generation of rooms with improved structural integrity, enhanced clarity from any view, reduced content repetition, and higher consistency across different perspectives. Extensive experiments demonstrate that our method, significantly outperforms state-of-the-art approaches by a large margin in terms of user study.
- Re-imagine the negative prompt algorithm: Transform 2d diffusion into 3d, alleviate janus problem and beyond. CoRR, abs/2304.04968, 2023.
- Efficient geometry-aware 3d generative adversarial networks. In CVPR, pages 16102–16112. IEEE, 2022.
- Matterport3d: Learning from RGB-D data in indoor environments. In 3DV, pages 667–676. IEEE Computer Society, 2017.
- Set-the-scene: Global-local training for generating controllable nerf scenes. CoRR, abs/2303.13450, 2023.
- Scannet: Richly-annotated 3d reconstructions of indoor scenes. In CVPR, pages 2432–2443. IEEE Computer Society, 2017.
- Objaverse: A universe of annotated 3d objects. In CVPR, pages 13142–13153. IEEE, 2023.
- GRAM: generative radiance manifolds for 3d-aware image generation. In CVPR, pages 10663–10673. IEEE, 2022.
- Scenescape: Text-driven consistent scene generation. CoRR, abs/2302.01133, 2023.
- threestudio: A unified framework for 3d content generation. https://github.com/threestudio-project/threestudio, 2023.
- Text2room: Extracting textured 3d meshes from 2d text-to-image models. CoRR, abs/2303.11989, 2023.
- Lora: Low-rank adaptation of large language models. In ICLR. OpenReview.net, 2022.
- Zero-shot text-guided object generation with dream fields. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 867–876, 2022.
- Simple and effective synthesis of indoor 3d scenes. In AAAI, pages 1169–1178. AAAI Press, 2023.
- Magic3d: High-resolution text-to-3d content creation. In CVPR, pages 300–309. IEEE, 2023a.
- Componerf: Text-guided multi-object compositional nerf with editable 3d scene layout. CoRR, abs/2303.13843, 2023b.
- Devrf: Fast deformable voxel radiance fields for dynamic scenes. Advances in Neural Information Processing Systems, 35:36762–36775, 2022.
- Dynvideo-e: Harnessing dynamic nerf for large-scale motion-and view-change human-centric video editing. arXiv preprint arXiv:2310.10624, 2023a.
- Hosnerf: Dynamic human-object-scene neural radiance fields from a single video. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 18483–18494, 2023b.
- Zero-1-to-3: Zero-shot one image to 3d object. CoRR, abs/2303.11328, 2023c.
- SKED: sketch-guided text-based 3d editing. CoRR, abs/2303.10735, 2023.
- Nerf: Representing scenes as neural radiance fields for view synthesis. In ECCV (1), pages 405–421. Springer, 2020.
- Instant neural graphics primitives with a multiresolution hash encoding. ACM Trans. Graph., 41(4):102:1–102:15, 2022.
- GIRAFFE: representing scenes as compositional generative neural feature fields. In CVPR, pages 11453–11464. Computer Vision Foundation / IEEE, 2021.
- Nerfies: Deformable neural radiance fields. In ICCV, pages 5845–5854. IEEE, 2021.
- SDXL: improving latent diffusion models for high-resolution image synthesis. CoRR, abs/2307.01952, 2023.
- Dreamfusion: Text-to-3d using 2d diffusion. In ICLR. OpenReview.net, 2023.
- D-nerf: Neural radiance fields for dynamic scenes. In CVPR, pages 10318–10327. Computer Vision Foundation / IEEE, 2021.
- Magic123: One image to high-quality 3d object generation using both 2d and 3d diffusion priors. CoRR, abs/2306.17843, 2023.
- Learning transferable visual models from natural language supervision. In ICML, pages 8748–8763. PMLR, 2021.
- Look outside the room: Synthesizing A consistent long-term 3d scene video from A single image. In CVPR, pages 3553–3563. IEEE, 2022.
- Geometry-free view synthesis: Transformers and no 3d priors. In ICCV, pages 14336–14346. IEEE, 2021.
- High-resolution image synthesis with latent diffusion models. In CVPR, pages 10674–10685. IEEE, 2022.
- Photorealistic text-to-image diffusion models with deep language understanding. In NeurIPS, 2022.
- Christoph Schuhmann. Clip+mlp aesthetic score predictor. https://github.com/christophschuhmann/improved-aesthetic-predictor, 2023.
- GRAF: generative radiance fields for 3d-aware image synthesis. In NeurIPS, 2020.
- Vox-e: Text-guided voxel editing of 3d objects. CoRR, abs/2303.12048, 2023.
- Deep marching tetrahedra: a hybrid representation for high-resolution 3d shape synthesis. In NeurIPS, pages 6087–6101, 2021.
- Mvdream: Multi-view diffusion for 3d generation. CoRR, abs/2308.16512, 2023.
- Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction. In CVPR, pages 5449–5459. IEEE, 2022.
- Mvdiffusion: Enabling holistic multi-view image generation with correspondence-aware diffusion. CoRR, abs/2307.01097, 2023.
- Consistent view synthesis with pose-guided diffusion models. In CVPR, pages 16773–16783. IEEE, 2023.
- Score jacobian chaining: Lifting pretrained 2d diffusion models for 3d generation. In CVPR, pages 12619–12629. IEEE, 2023a.
- Prolificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. CoRR, abs/2305.16213, 2023b.
- Humannerf: Free-viewpoint rendering of moving people from monocular video. In Proceedings of the IEEE/CVF conference on computer vision and pattern Recognition, pages 16210–16220, 2022.
- Synsin: End-to-end view synthesis from a single image. In CVPR, pages 7465–7475. Computer Vision Foundation / IEEE, 2020.
- PV3D: A 3d generative model for portrait video generation. In ICLR. OpenReview.net, 2023.
- Text2nerf: Text-driven 3d scene generation with neural radiance fields. CoRR, abs/2305.11588, 2023.
- Stereo magnification: learning view synthesis using multiplane images. ACM Trans. Graph., 37(4):65, 2018.
- Hifa: High-fidelity text-to-3d with advanced diffusion guidance. CoRR, abs/2305.18766, 2023.
- Dreameditor: Text-driven 3d scene editing with neural fields. CoRR, abs/2306.13455, 2023.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Collections
Sign up for free to add this paper to one or more collections.