Improved Baselines with Representation Autoencoders
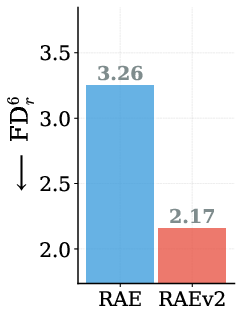
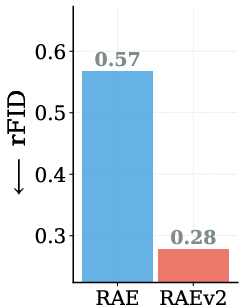
Abstract: Representation Autoencoders (RAE) replace traditional VAE with pretrained vision encoders. In this paper, we systematically investigate several design choices and find three insights which simplify and improve RAE. First, we study a generalized formulation where the representation is defined as sum of the last k encoder layers rather than solely the final layer. This simple change greatly improves reconstruction without encoder finetuning or specialized data (e.g., text, faces). Second, we study the prevalent assumption that RAE (using pretrained representation as encoder) replaces representation alignment (REPA), which distills the same representation to intermediate layers instead. Through large-scale empirical analysis, we uncover a surprising finding: RAE and REPA exhibit complementary working mechanisms, allowing the same representation to be used as both encoder and target for intermediate diffusion layers. Finally, the original RAE struggles with classifier-free guidance (CFG) and requires training a second, weaker diffusion model for AutoGuidance (AG). We show that REPA itself can be viewed as x-prediction in RAE latent space. By simply re-parameterizing the output of the DiT model, it can provide guidance for "free". Overall, RAEv2 leads to more than 10x faster convergence over the original RAE, achieving a state-of-the-art gFID of 1.06 in just 80 epochs on ImageNet-256. On FDrk, RAEv2 achieves a state-of-the-art 2.17 at just 80 epochs compared to the previous best 3.26 (800 epochs) without any post-training. This motivates EP_FID@k (epochs to reach unguided gFID <= k) as a measure of training efficiency. RAEv2 attains an EP_FID@2 of 35 epochs, versus 177 for the original RAE. We also validate our approach across diverse settings for text-to-image generation and navigation world models, showing consistent improvements. Code is available at https://raev2.github.io.


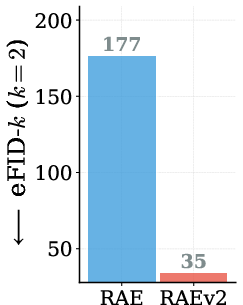



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces RAEv2, a new and improved way for computers to learn how to create and understand images. It builds on “Representation Autoencoders” (RAE), which use a smart, already-trained vision model as a “compressor” for images, instead of the older VAE compressor. The authors show three simple ideas that make RAE faster, better at rebuilding images, and better at generating high‑quality pictures.
What questions did the researchers ask?
The authors focused on three easy-to-understand questions:
- Can we get better image reconstructions by using more of a vision model’s knowledge, not just its final layer?
- Do two popular tricks—RAE (using a pretrained encoder as the image “code”) and REPA (teaching the middle layers of the generator to look like the encoder’s features)—work against each other, or can they help each other?
- Can we guide the image generator without training a second model or doing extra work at test time?
How did they study it? (Simple explanations and analogies)
Think of the process like this:
- Compression and rebuilding: An autoencoder is like zipping and unzipping a photo. The “zip” part creates a short code (latent) that captures the essence of the image, and the “unzip” part rebuilds it.
- Using a smart eye: RAE replaces the usual zipper (VAE) with a powerful, pretrained vision encoder (like DINOv3), which already knows a lot about images from seeing millions of them. This gives a smarter “summary code” for images.
The paper tests three upgrades:
- Use more than one layer from the encoder
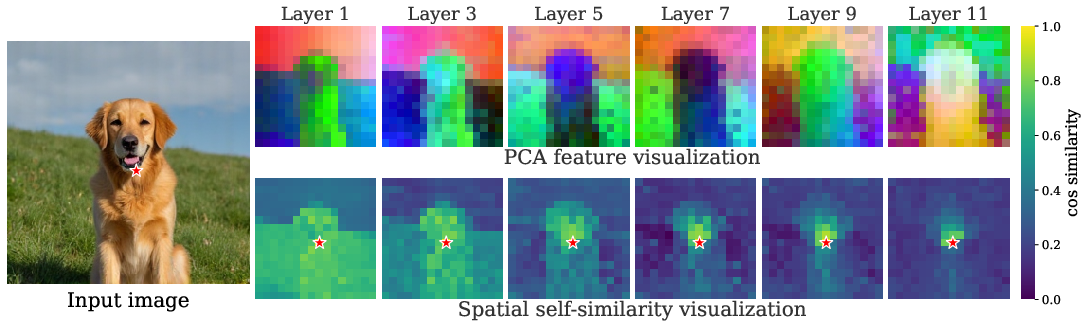
- Analogy: A vision encoder is like a layer cake. Early layers see edges and textures; later layers understand objects and meaning. Instead of taking only the top layer’s summary, they add up the last K layers to get a richer code. This needs no extra training or parameters and keeps the code the same size.
- Combine RAE and REPA instead of choosing one
- RAE uses the encoder’s summary as the input code for the generator.
- REPA teaches the generator’s middle layers to match the encoder’s features.
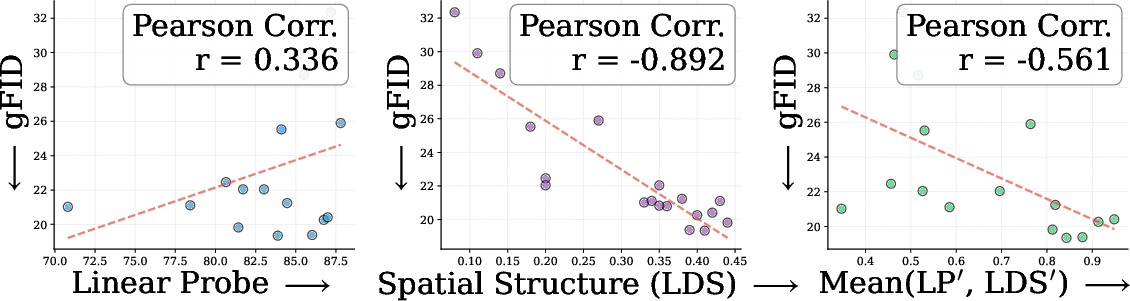
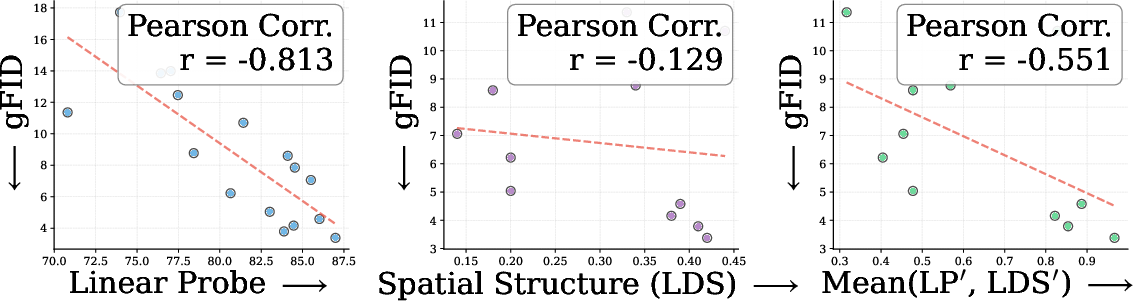
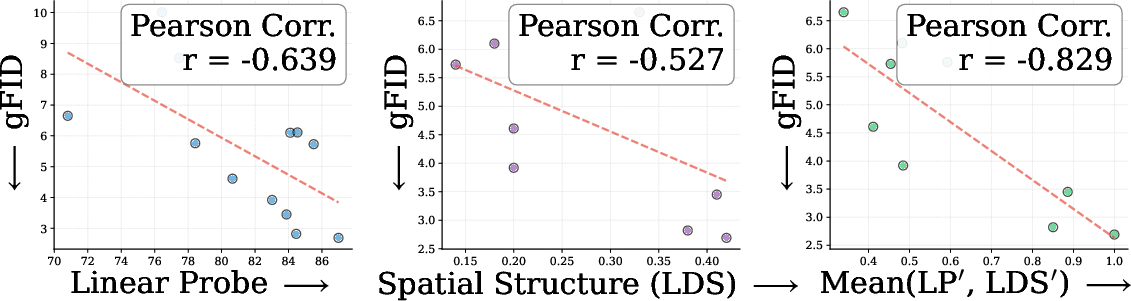
- Analogy: RAE is like giving the generator a great map (strong global meaning). REPA is like reminding it to keep the streets aligned (good spatial layout). The authors tested 27 different encoders and measured two properties:
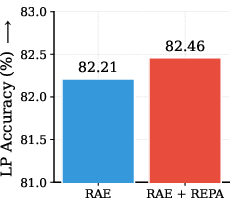
- Global semantics (how well features understand what’s in an image), via linear probing.
- Spatial structure (how well features keep the relationships across image regions), via a self-similarity score.
- They found RAE and REPA help in different, complementary ways.
- Guidance without extra cost
- Generators often need “guidance,” a steering knob that makes outputs more accurate or on-topic. A common method, classifier-free guidance (CFG), runs the model twice per step (doubling work) and doesn’t work well with the original RAE.
- Previous RAE used AutoGuidance, which trained a second, weaker model—more work.
- New idea: The small REPA head (a light prediction layer already attached to the generator’s early layers) can act as that “weaker” guide for free. With a small change (outputting the “clean image code” directly, known as x‑prediction), the main model and REPA head produce compatible outputs in one pass. Then the main model can guide itself internally—no second model, no extra pass.
They tested these ideas on:
- ImageNet-256 (a standard image dataset) using standard image quality scores (lower is better): FID/gFID and FD_r6 (a mix of six feature spaces).
- Text-to-image tasks (turning captions into pictures).
- Navigation world models (predicting future frames from actions), which stress long contexts and stable rollouts.
What did they find, and why is it important?
Here are the main results, in plain terms:
- Using the last K layers beats using only the last layer:
- By adding the last K encoder layers (instead of just the final one), reconstructions got much sharper and more accurate, without any retraining of the encoder. It also improved guided image generation when K is chosen well (often around 7).
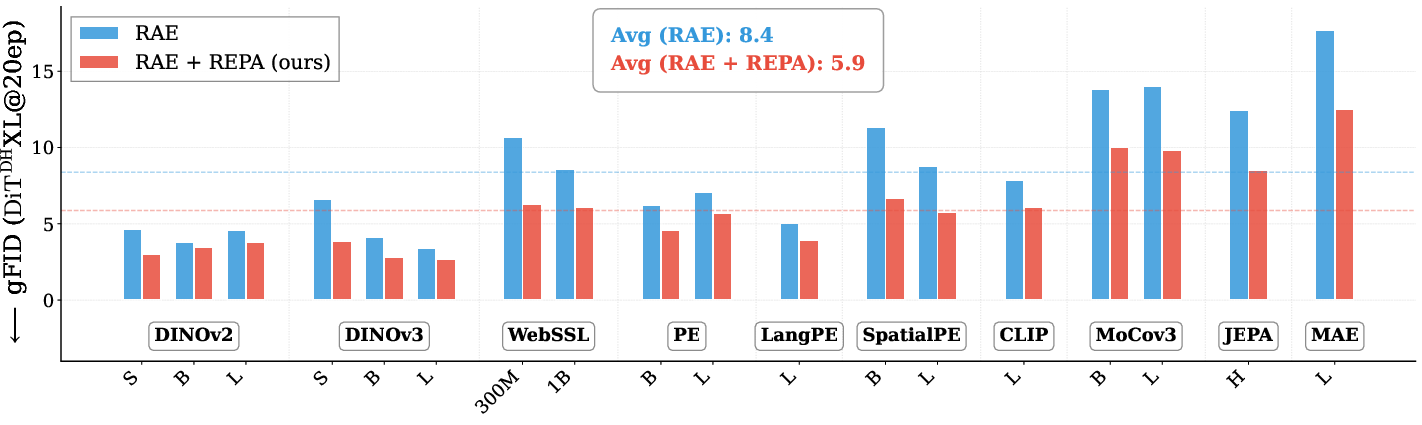
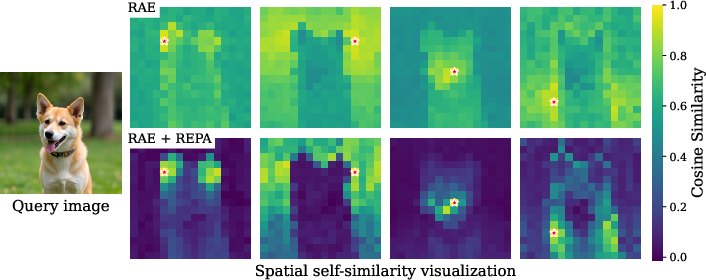
- RAE and REPA help in different ways and work best together:
- RAE gives a strong, meaningful code (great “what’s in the image” understanding).
- REPA improves the spatial layout inside the generator (great “where things go”).
- Together, they boost image quality more than either alone. Strong encoders like DINOv3‑L (good at both meaning and layout) work best with RAEv2.
- Free, fast guidance with the REPA head:
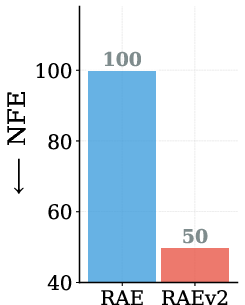
- The authors turned the REPA head into a free guidance signal by switching to x‑prediction (predicting the clean latent directly). This avoids training a second model and avoids the extra compute of CFG, cutting the number of function evaluations at test time in half.
- Much faster training to top quality:
- RAEv2 reached a state‑of‑the‑art guided FID (gFID) of about 1.06 on ImageNet‑256 in just 80 epochs—over 10× faster than earlier RAE setups that needed 800 epochs.
- Using a “training efficiency” metric (epochs needed to reach a certain quality), RAEv2 needed only 35 epochs to get to unguided gFID ≤ 2, compared to 177 for the original RAE.
- On FD_r6 (a stricter, multi‑feature quality score), RAEv2 also set a new best score at 80 epochs.
- Works beyond ImageNet:
- On text-to-image benchmarks, RAEv2 outperformed both the original RAE and a popular VAE setup, improving how well images matched prompts.
- On navigation world models, it handled long contexts and future predictions better, showing the latent space is robust and broadly useful.
Why this matters:
- Better reconstructions help editing, compression, and understanding tasks.
- Faster convergence saves time, electricity, and money.
- Free guidance simplifies models and speeds up generation.
- A single “tokenization” (latent code) that’s good for both understanding and generation makes it easier to build multi‑purpose vision systems.
What does this mean for the future?
- Simpler, stronger building blocks: By using more of a pretrained encoder’s knowledge (multi‑layer features) and by unifying guidance inside the model, RAEv2 shows that small, thoughtful changes can make big gains.
- One code for many tasks: The same latent code works well for classification, generation, text-to-image, and long-horizon prediction, pointing toward more unified vision systems.
- Faster iteration: Because training converges much sooner, researchers and practitioners can try ideas more quickly and cheaply.
- Practical adoption: Less compute, fewer moving parts, and better quality make RAEv2 a strong, practical option for real-world image generation and world modeling.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of unresolved issues and open questions that future work could address:
- Aggregation design beyond simple addition: Evaluate learned or content-adaptive multi-layer fusion (e.g., learned per-layer scalars, attention over layers, gating) versus the fixed sum and random projection; assess if lightweight learnable weights improve Stage-2 without losing training simplicity.
- Layer normalization and scaling: Investigate whether per-layer normalization or rescaling (e.g., LayerNorm/ScaleNorm per layer before summation) improves stability and performance when aggregating last layers.
- Choice of K across conditions: Systematically study sensitivity of the optimal to encoder type, dataset, resolution, training duration, and task; determine if “best at ” generalizes or requires adaptive selection.
- Earlier layers and non-contiguous selections: Test whether including earlier (not just last) layers or non-contiguous layer sets (e.g., middle+last) yields better spatial detail or semantics.
- Mechanistic understanding of aggregation: Provide theory/analysis explaining why multi-layer summation improves reconstruction and guided generation but not unguided generation; analyze representation geometry and noise coupling.
- MLS vs. random projections: Explain why simple addition (MLS) outperforms random-matrix projection (MLR) in Stage-2; test alternative projections (e.g., structured random, orthogonal) and their impact on sample quality.
- Generality across encoder families: Extend encoder sweep to diverse backbones (ConvNeXt, CNNs, hybrid, state-space models, hierarchical ViTs) and tokenization layouts; verify whether RAE–REPA complementarity and K-findings hold.
- Downstream understanding beyond LP: Evaluate generalized RAE on detection, segmentation, depth, and dense tasks to confirm that multi-layer aggregation preserves or improves spatial semantics, not just ImageNet linear probing.
- Latent grid and patch size: Ablate latent resolution (e.g., 8×8, 32×32 grids) and input patch size to quantify effects on reconstruction, generation, and speed.
- Encoder finetuning vs. frozen: Explore mild encoder adaptation (e.g., LoRA, adapters, or training-permitted scalars on layer aggregation) to assess if small learnable changes further improve the recon–gen trade-off.
- REPA weighting and placement: Ablate REPA loss weights, which intermediate layers to supervise, and how many layers to include; quantify stability and gains across schedules and architectures.
- Internal-guidance hyperparameters: Characterize sensitivity of the guidance weight , guidance schedules, and the choice of “early layers” feeding REPA-head; evaluate trade-offs in fidelity vs. diversity and risk of mode collapse.
- Sampler and objective robustness: Test REPA-as-x-pred guidance across samplers (DDIM, Heun, DPM-Solver, EDM, FCFM) and objectives (v-pred vs. x-pred vs. flow-matching) to ensure gains are not sampler-specific.
- Diversity metrics and precision–recall: Report generative precision/recall, coverage, and intra-class diversity under REPA guidance; assess whether internal guidance suppresses diversity relative to CFG/AG.
- Wall-clock gains and FLOPs: Quantify actual end-to-end latency, throughput, and memory for “free guidance” vs. CFG and AG; detail encoder FLOPs (claim of “half FLOPs”), overhead of computing multi-layer sums, and total training/inference costs.
- Higher resolutions and scaling: Validate convergence and quality at 512×512 and 1024×1024; assess whether training-efficiency gains and guidance benefits persist at higher resolutions and model scales.
- Domain robustness and OOD: Evaluate RAEv2 on domain-shifted datasets (e.g., medical, satellite, sketches) to test the stability of the pretrained-encoder latent space and REPA guidance across domains.
- Training efficiency metric (): Justify choice of for the proposed “epochs-to-reach gFID ≤ ” metric; analyze sensitivity to , dataset size, batch size, and guidance; propose a standardized benchmark protocol.
- Broader T2I benchmarks: Augment T2I evaluation with widely used metrics (e.g., PickScore, HPSv2, CLIP-S, GenEval subcategories) and COCO-style caption sets; clarify whether internal guidance was used for T2I and its effect on text adherence.
- Safety and bias in T2I: Assess prompt bias, harmful content, and demographic skew introduced by encoder-driven latents and REPA-guidance; propose mitigation strategies if issues arise.
- Long-horizon world models: Provide complete results for navigation world models (e.g., FVD across horizons, rollout stability, compounding error) and test generalization to different environments and action spaces.
- Compression and tokenization: Explore quantization/entropy coding of RAE latents for storage/streaming; benchmark bitrate vs. reconstruction and generation quality to validate RAE as a practical tokenizer.
- Failure modes and stability: Document and analyze training instabilities, collapse modes, or sensitivity to optimizer and noise schedules when combining RAE, REPA, generalized aggregation, and x-pred.
- Reproducibility and fair comparison: Release full training configs, seeds, and compute budgets; ensure comparisons use matched training steps and data; evaluate sensitivity to encoder licensing/data availability.
- Theoretical rationale for complementarity: Move beyond correlation (LP vs. LDS) to causal tests (e.g., interventions that enforce/perturb self-similarity) to establish why and when REPA and RAE interact beneficially.
Practical Applications
Below is an overview of practical, real-world applications that follow from the paper’s findings and methods. Each item names concrete use cases, links to sectors, and notes assumptions or dependencies that may affect feasibility.
Immediate Applications
- Improved diffusion training efficiency in production pipelines
- Use case: Swap VAEs for RAEv2 in DiT-style pipelines to cut time-to-quality by >10× (e.g., reaching strong gFID/FD_r in ~80 epochs) and reduce compute cost.
- Sectors: Software/AI platforms, cloud providers, creative industries, gaming.
- Tools/workflows: “RAEv2 recipe” for training, including RAE+REPA, x-prediction head, internal guidance, and K-aggregation. CI/CD training templates that track τ_k (epochs to reach unguided gFID ≤ k) alongside gFID/FD_r.
- Assumptions/dependencies: Access to pretrained encoders (e.g., DINOv3-L) and DiT backbones; code changes for x-prediction and REPA head; training data similar to ImageNet, JourneyDB, BLIP3o; primarily validated at 256×256.
- Lower-latency, lower-cost inference via “free” internal guidance
- Use case: Replace classifier-free guidance (CFG) and separate AutoGuidance with REPA-head internal guidance in x-prediction space, removing an extra forward pass and eliminating a secondary model.
- Sectors: Consumer T2I apps, on-device/mobile generation, cloud inference serving.
- Tools/workflows: Inference kernels that compute full-model and REPA-head outputs in a single pass; guidance weight w autotuning.
- Assumptions/dependencies: Model exposes both full x-prediction and REPA-head x-prediction; early-layer REPA head added and trained; sample quality validated against your prompts/domain.
- Better reconstruction without encoder finetuning (training-free K-aggregation)
- Use case: Improve reconstruction for image enhancement, stylization, document cleanup (rendered/handwritten text), and graphics while preserving “understanding” semantics.
- Sectors: Photography, document processing/OCR, design tools, e-commerce imaging.
- Tools/workflows: Parameter-free multi-layer summation of the last K encoder layers (K≈7–23) for reconstruction-quality control; light UI slider for K to trade off reconstruction vs. generation.
- Assumptions/dependencies: A strong pretrained encoder; decoder trained on relevant data; target resolution; potential light retuning per domain.
- Encoder selection and auto-tuning for generative quality
- Use case: Systematically pick vision encoders that maximize RAEv2 quality by combining global semantics (LP) and spatial structure (LDS); tune K for reconstruction/generation trade-offs.
- Sectors: Model development in industry/academia; foundation model labs.
- Tools/workflows: Automated sweeps over encoders (e.g., DINOv3-L) with LP/LDS diagnostics; K-sweep auto-tuner; Pareto dashboards for rFID/gFID/FD_r vs. compute.
- Assumptions/dependencies: Availability/licensing of candidate encoders; reproducible LP/LDS pipelines; compute for short pilot runs.
- Text-to-image (T2I) training improvements on modest budgets
- Use case: Adopt the RAEv2 recipe to reach competitive GenEval/DPG faster, enabling rapid iteration on prompts, styles, and domain adaptation.
- Sectors: Creative software, advertising, media, entertainment.
- Tools/workflows: DiT backbones with 256 text tokens; pretraining on JourneyDB + BLIP3o; finetuning on BLIP3o subsets; internal guidance at inference.
- Assumptions/dependencies: Rights-cleared training data; responsible use and safety layers; resolution currently 256×256 in experiments.
- Faster training of action-conditioned world models for navigation
- Use case: Train RAEv2-based world models with longer contexts (e.g., 4 past frames + actions) more quickly for planning or simulation.
- Sectors: Robotics, autonomy, drones, simulation platforms.
- Tools/workflows: RAEv2 encoder for compact visual tokens; DiT-based future-frame prediction; autoregressive rollout evaluation.
- Assumptions/dependencies: Domain-specific datasets (e.g., RECON/NOMAD-like); transfer to outdoor/indoor settings; safety validation for downstream control.
- Cost and sustainability reporting using τ_k
- Use case: Track and report training efficiency with τ_k (epochs to reach unguided gFID ≤ k) to guide budget allocation and sustainability goals.
- Sectors: Industry (ML Ops), policy/compliance, sustainability offices.
- Tools/workflows: Training dashboards recording τ_k, GPU-hours, energy; procurement checklists prioritizing methods with lower τ_k.
- Assumptions/dependencies: Agreement on k thresholds; acceptance by stakeholders as a decision metric.
- Latent storage and dataset curation
- Use case: Store RAEv2 latents for rapid reconstruction and selective data replay in training, or for space-efficient archives of large corpora used in generative pipelines.
- Sectors: Data engineering, ML Ops, archives.
- Tools/workflows: Latent caches, reversible decode pipelines, hybrid policies (raw vs. latent).
- Assumptions/dependencies: Decoder availability and stability; legal constraints around storing reconstructed content vs. originals.
- Enhanced OCR pre-processing and text rendering repair
- Use case: Improve readability and OCR accuracy for noisy scans or handwritten notes via reconstruction in RAEv2 space.
- Sectors: Enterprise document workflows, education, legal, government services.
- Tools/workflows: Pre-OCR filter using K-aggregated latents to denoise/clarify then pass to OCR; batch pipelines.
- Assumptions/dependencies: Validation on domain-specific documents; careful handling to avoid hallucinated corrections in legal/medical contexts.
- Better user experiences in creative apps
- Use case: Faster, higher-quality image generation, upscaling, and stylization on desktop/mobile; more responsive iteration loops for creators.
- Sectors: Creative software, social media, mobile OEMs.
- Tools/workflows: On-device internal guidance, adjustable K for detail recovery, “balanced” presets (e.g., K=7 with guidance).
- Assumptions/dependencies: Mobile inference constraints; quantization and memory-friendly variants of encoders/decoders.
Long-Term Applications
- Unified tokenization for perception and generation across multimodal systems
- Vision: Standardize on RAEv2-style latents as a shared interface for understanding (classification/LP tasks) and generation (diffusion), simplifying model stacks.
- Sectors: Foundation models, robotics, autonomous systems, AR/VR.
- Potential tools/products: Multimodal backbones that reuse the same latent tokens for perception, planning, and synthesis; SDKs standardized around RAEv2 latents.
- Dependencies: Robustness across domains/resolutions, stable APIs for token-level interoperability, standardized encoders.
- Energy- and compute-aware governance using training efficiency metrics
- Vision: Incorporate τ_k into procurement, grant reviews, and sustainability reporting to incentivize efficient methods.
- Sectors: Policy, public funding agencies, corporate ESG.
- Potential tools/products: Benchmark suites publishing τ_k alongside quality metrics; policy templates guiding “efficiency-first” adoption.
- Dependencies: Community consensus on thresholds and dataset benchmarks; safeguards to prevent gaming τ_k at the expense of safety/fairness.
- Scalable video and 3D generation with internal guidance
- Vision: Extend RAEv2+REPA internal guidance to spatiotemporal models (video) and geometry-aware models (3D/NeRFs), enabling low-latency creative tools and simulators.
- Sectors: Film/VFX, gaming, digital twins, simulation.
- Potential tools/products: Video editors powered by RAEv2 latents; simulators with fast generative dynamics; 3D asset generators.
- Dependencies: Architectures that carry REPA heads across time/geometry; data scale; stability at higher resolutions and longer sequences.
- On-device assistants for AR/VR with real-time generation
- Vision: Exploit half-NFE internal guidance and compact latents to bring real-time or near-real-time generative overlays to headsets and phones.
- Sectors: AR/VR, mobile computing, assistive tech.
- Potential tools/products: Generative AR filters, real-time scene “restyling,” task guidance overlays powered by unified perception-generation latents.
- Dependencies: Efficient encoders/decoders (e.g., mobile-friendly DINO variants), hardware acceleration, thermal/power budgets.
- Domain-specialized medical or scientific imaging models
- Vision: Use generalized RAE to improve reconstruction and detail control (via K) in specialized modalities (microscopy, remote sensing), with faster training.
- Sectors: Healthcare, life sciences, earth observation.
- Potential tools/products: Reconstruction aids, data augmentation generators for rare conditions, scientific simulators.
- Dependencies: Domain-specific pretrained encoders, rigorous validation and regulatory approval; strict safeguards against hallucinations.
- Federated and personalized generative modeling
- Vision: Leverage efficient training and shared tokenization to enable low-cost on-device finetuning or federated updates for user-specific styles or domains.
- Sectors: Consumer apps, enterprise privacy-first deployments.
- Potential tools/products: Personal style adapters trained efficiently using τ_k-aware schedules; privacy-preserving latent sharing.
- Dependencies: Private/edge training frameworks; secure aggregation; careful privacy controls.
- Automated “representation governance” in model development
- Vision: Integrate LP/LDS diagnostics and K-selection into AutoML systems that continually choose encoders and aggregation settings for new tasks.
- Sectors: ML platforms, AutoML vendors.
- Potential tools/products: Encoder marketplaces with measured LP/LDS and licensing; controller agents that optimize the RAEv2 stack per target metric/compute budget.
- Dependencies: Standardized measurement pipelines; accessible licensing; accuracy-efficiency tradeoff models.
- Interoperable latent standards across vendors
- Vision: Converge on a shared RAEv2-like latent spec to allow cross-vendor components (encoders, decoders, generators) to interoperate.
- Sectors: Software ecosystems, cloud marketplaces.
- Potential tools/products: Latent format specs, compatibility test suites, “plug-and-play” decoders/encoders.
- Dependencies: Industry collaboration; IP and licensing alignment; stability of the spec across model generations.
Notes on cross-cutting assumptions and risks
- Most gains are demonstrated with DiT-style transformers at 256×256; scaling to higher resolutions, video lengths, or out-of-domain data will require validation.
- Access and licensing for strong encoders (e.g., DINOv3-L) matter; substitutes may change outcomes.
- Internal guidance requires x-prediction reparameterization and a trained early-layer REPA head; implementation quality affects results.
- While K-aggregation is training-free, production-ready performance often benefits from targeted decoder training on in-domain data.
- Responsible deployment (especially for T2I) requires safety layers (content filters, provenance/watermarking, misuse mitigation).
- τ_k, gFID, and FD_r are proxies; task-specific metrics (e.g., clinical performance, OCR word accuracy) must guide final adoption.
Glossary
- AutoGuidance (AG): A guidance technique that uses a separately trained, smaller diffusion model as a weaker baseline to guide sampling from a stronger model. "requires training a second, weaker diffusion model for AutoGuidance (AG)."
- classifier-free guidance (CFG): A sampling method for diffusion models that mixes conditional and unconditional predictions to steer outputs toward the condition without an external classifier. "RAE struggles with classifier-free guidance (CFG)"
- deep supervised network: A model trained with auxiliary supervision at intermediate layers to improve optimization, akin to deep supervision. "our formulation is equivalent to a deep supervised network"
- DiT (Diffusion Transformer): A transformer architecture adapted for diffusion generative modeling, often predicting noise, velocity, or x in latent space. "By simply re-parameterizing the output of DiT model"
- EMA model: A model whose parameters are maintained by an exponential moving average of training weights, often used for more stable inference. "using the EMA model."
- FDr (Representation Fréchet Distance): A family of Fréchet-distance-based metrics computed in various feature spaces to assess sample fidelity; denotes aggregating across k feature spaces. "On FDr RAEv2 achieves state-of-art 2.17 in just 80 epochs"
- flow-matching: A training recipe for generative models that learns continuous-time dynamics by matching probability flows rather than discrete denoising steps. "flow-matching recipe"
- gFID: Guided Fréchet Inception Distance; FID measured when guidance (e.g., CFG or internal guidance) is used during sampling. "achieving a state-of-the-art gFID of $1.06$ in just 80 epochs on ImageNet-256."
- internal-guidance: A guidance method that computes the guidance signal within the same forward pass of the main model, avoiding extra evaluations. "internal-guidance \cite{internalguidance} with REPA head in x-prediction space is computed within the same forward pass, effectively halving the NFEs."
- linear probing (LP): Evaluating representations by training a linear classifier on frozen features to assess global semantic quality. "Imagenet linear probing accuracy (LP)"
- Local Distance Similarity (LDS): A metric that quantifies the spatial self-similarity or local structural quality of feature representations. "local distance similarity score (LDS)~\cite{irepa}"
- NFEs (Number of Function Evaluations): The count of forward passes through the model during sampling; a measure of inference cost. "effectively halving the NFEs."
- ODE (Euler) sampler: A deterministic sampler that integrates the diffusion ODE (e.g., via Euler steps) to generate samples without stochasticity. "All samples are generated with the ODE (Euler) sampler at 50 steps using the EMA model."
- Pareto-optimal: Achieving a trade-off where improving one objective (e.g., reconstruction) would worsen another (e.g., generation), representing an optimal frontier. "pareto-optimal reconstruction-generation performance"
- random-matrix projection: Combining multi-layer features by concatenation followed by multiplication with a fixed random matrix to reduce dimensionality while approximately preserving structure. "Random-matrix projection. We concatenate the last layer features along the channel dimension and project back to with a fixed random matrix"
- representation alignment (REPA): A training objective that distills a target representation into intermediate diffusion layers to regularize spatial structure. "representation alignment (REPA), which distills same representation to intermediate layers instead."
- Representation Autoencoders (RAE): A framework that replaces a learned encoder with a pretrained vision encoder to define the latent space for diffusion models. "Representation Autoencoders (RAE) replace traditional VAE with pretrained vision encoders."
- rFID: Reconstruction Fréchet Inception Distance; FID computed between original and reconstructed images to assess autoencoder reconstruction quality. "reconstruction (rFID)"
- spatial self-similarity: The pattern of token-to-token similarity within feature maps that reflects spatial structure in learned representations. "improves the spatial self-similarity structure"
- tokenization (unified tokenization): Representing diverse modalities or tasks with a shared latent/token space to support both understanding and generation. "towards a unified tokenization for both understanding and generation."
- velocity (prediction): A diffusion parameterization where the model predicts a scaled combination (velocity) of clean data and noise instead of noise or data directly. "reformulate the full model output to also give x-prediction instead of velocity"
- x-prediction: A diffusion parameterization where the model directly predicts the clean data (x) in latent space, enabling certain guidance strategies. "REPA is x-prediction in RAE latent space."
Collections
Sign up for free to add this paper to one or more collections.