- The paper demonstrates that employing token normalization and Gaussian noise injection addresses high token variance and exposure bias in AR models.
- The methodology yields improved convergence rates and enhanced generative performance with significantly lower generation FIDs.
- Experimental results validate the approach across different AR backbones, bridging the performance gap with traditional VAE methods.
RAE-AR: Taming Autoregressive Models with Representation Autoencoders
Introduction
The integration of high-dimensional semantic representations into generative models has been a longstanding ambition for unifying visual understanding and generative modeling. While diffusion models have successfully leveraged representation autoencoders (RAEs) as latent spaces, the extension of these approaches to autoregressive (AR) models remains problematic. The paper "RAE-AR: Taming Autoregressive Models with Representation Autoencoders" (2604.01545) thoroughly investigates this challenge, identifying the critical technical hurdles and proposing methodological improvements that enable RAEs to function as effective latent spaces for AR generative modeling.
Problem Analysis: Limitations of RAEs in AR Models
The empirical comparison between reconstruction-oriented VAEs and semantic representation encoders (such as DINOv2, SigLIP2, and MAE) reveals that, although RAEs reach competitive reconstruction scores, their direct deployment in AR frameworks yields poor generative performance. This is quantified by significantly higher generation FID (gFID) and lower Inception Scores (IS) for RAEs compared to VAEs. The principal challenges identified are:
- Token-wise Distribution Variance: AR models are more sensitive to inter-token variance due to their sequential, token-level distribution modeling. Large variance increases the modeling complexity.
- Amplified Exposure Bias: High-dimensional latent spaces exacerbate the mismatch between training (teacher-forcing with ground-truth tokens) and inference (autoregressive sampling based on previously generated tokens), leading to error accumulation and degraded sample quality.
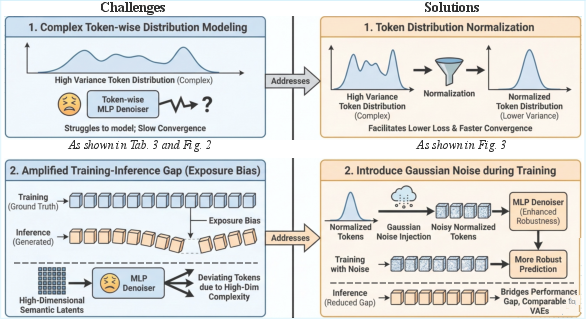
Figure 1: The challenges of integrating representation autoencoders into AR models: token variance and exposure bias. We correspondingly take token normalization and noise perturbation strategies.

Figure 2: The mean and variance map visualization of the five generative latents. Token-wise distribution variance obviously exists and may influence the modeling difficulty of AR models, as verified by the poor generation performance.
Methodological Contributions
Token Normalization via Distribution Normalization
The spatial distribution analysis of latent tokens demonstrates that lower token-wise variance correlates with superior generative performance. To alleviate the burdens imposed by high token-wise diversity, the authors introduce token normalization, constraining each token to zero mean and unit variance. This normalization significantly enhances convergence rate and lowers training loss without architectural changes.
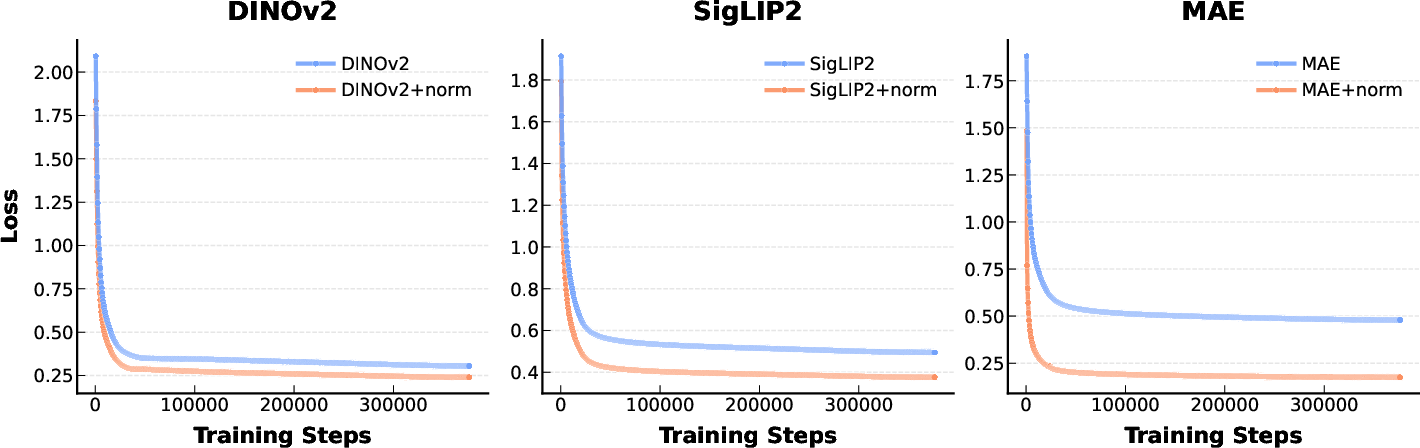
Figure 3: The training loss curve comparison on the three representation autoencoders. Token normalization introduces lower training loss and fast convergence.
Gaussian Noise Injection for Exposure Bias Mitigation
Token normalization alone is insufficient due to persistent exposure bias. To address this, the paper proposes Gaussian noise injection during training, perturbing latent tokens so the model learns to handle distributional deviations encountered during inference. This regularization enhances the model’s robustness without requiring changes to the AR architecture.
Notably, optimal performance is attained by combining both strategies, which together compensate for the unique challenges of using high-dimensional semantic latents in AR settings. The empirical ablation confirms that the combination yields superior sample quality, with generative performance metrics largely closing the gap with VAE-based models.

Figure 4: The reconstruction results comparison between VAE, VA-VAE, and three representation autoencoders. VAE type usually performs better in fidelity and details.

Figure 5: The visual generation comparison between the baseline and our RAE-AR on the three representation autoencoders.
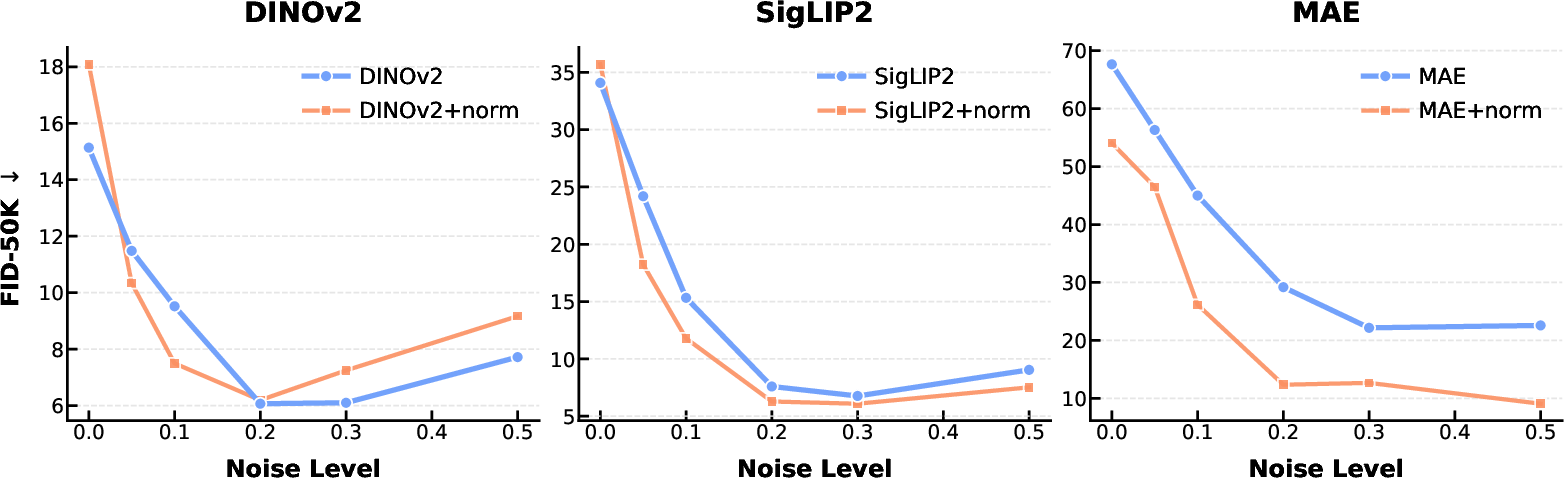
Figure 6: The relationship between noise perturbation level and generation performance on the three representation autoencoders.
Experimental Results
A comprehensive suite of experiments is conducted on several AR backbones, assessing both pixel-level and perceptual metrics (rFID, PSNR, LPIPS, SSIM, gFID, IS, Precision, Recall). Key findings are:
- RAE-AR achieves a gFID of 6.091 (SigLIP2) and 7.494 (DINOv2) compared to 3.237 for VAE; a substantial improvement over the baseline (e.g., SigLIP2 baseline: gFID of 34.084).
- Clean convergence curves and superior image synthesis quality are achieved when token normalization and noise injection are combined.
- Visual quality demonstrates convincing recovery of structure and detail in outputs compared to heavily distorted or blurred baselines.
- The approach is validated on both raster-scan and mask-based AR models, indicating generality.
Practical and Theoretical Implications
This work systematically dismantles the belief that semantic representation encoders are inappropriate as AR latent spaces. By identifying and correcting for token variance and exposure bias, the paper expands the applicability of RAEs, providing a foundation for unified, representation-driven architectures suitable for visual understanding and generation tasks. The ability to use frozen semantic encoders also facilitates modular transfer and cross-modal pretraining strategies.
From a systems perspective, these findings encourage architectural modularity, decoupling representation and generative backbones, and simplifying the path toward large-scale, generalist visual models that do not sacrifice generative performance for semantic structure.
Future Directions
The investigation opens several research trajectories:
- Exploration of alternative normalization strategies (e.g., hyperspherical latents or advanced whitening).
- Further analysis of regularization and noise schedules adapted to latent dimensionality.
- Extension to multimodal or cross-modal sequence generation where exposure bias is even more pronounced.
- Investigation of interaction effects with newer AR model architectures or more data-efficient regimes.
- Integration with foundation model pretraining to exploit large-scale semantic priors.
Conclusion
The integration of representation autoencoders into AR models is rendered tractable and effective via token normalization and targeted noise perturbation during training. These innovations enable AR models to leverage high-dimensional semantic latents, delivering generative performance that matches traditional VAE-based systems. This constitutes a significant step toward unifying representation learning and generative modeling, with broad implications for both architectural design and practical deployment in vision systems.