Diffusion Transformers with Representation Autoencoders
Abstract: Latent generative modeling, where a pretrained autoencoder maps pixels into a latent space for the diffusion process, has become the standard strategy for Diffusion Transformers (DiT); however, the autoencoder component has barely evolved. Most DiTs continue to rely on the original VAE encoder, which introduces several limitations: outdated backbones that compromise architectural simplicity, low-dimensional latent spaces that restrict information capacity, and weak representations that result from purely reconstruction-based training and ultimately limit generative quality. In this work, we explore replacing the VAE with pretrained representation encoders (e.g., DINO, SigLIP, MAE) paired with trained decoders, forming what we term Representation Autoencoders (RAEs). These models provide both high-quality reconstructions and semantically rich latent spaces, while allowing for a scalable transformer-based architecture. Since these latent spaces are typically high-dimensional, a key challenge is enabling diffusion transformers to operate effectively within them. We analyze the sources of this difficulty, propose theoretically motivated solutions, and validate them empirically. Our approach achieves faster convergence without auxiliary representation alignment losses. Using a DiT variant equipped with a lightweight, wide DDT head, we achieve strong image generation results on ImageNet: 1.51 FID at 256x256 (no guidance) and 1.13 at both 256x256 and 512x512 (with guidance). RAE offers clear advantages and should be the new default for diffusion transformer training.




Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making AI image generators faster and better by changing the “hidden language” they use to think about pictures. Most modern diffusion models (like those used in image generation) don’t work directly with pixels. Instead, they first turn images into compact “codes” using an autoencoder, then learn to generate in that hidden space. The authors say the usual autoencoder (called a VAE) is outdated, too small, and not very smart about image meaning. They replace it with a stronger kind of autoencoder built from powerful vision models (like DINO, MAE, and SigLIP) and show this makes training easier and the results better. They call this new setup a Representation Autoencoder, or RAE.
Key Questions the Paper Asks
- Can we replace the old VAE with a modern vision encoder (like DINO or MAE) and still reconstruct images well?
- If we do that, can a diffusion transformer still learn to generate images in this new, higher‑dimensional hidden space?
- What changes are needed to make training stable and efficient?
- Does this actually make image generation faster and higher quality on tough datasets like ImageNet?
Methods and Approach
To understand the approach, think of three parts working together:
- The encoder: turns an image into a grid of numeric “tokens” that describe it.
- The diffusion transformer: learns to create new token grids from noise, step by step.
- The decoder: turns tokens back into a full image.
What is a Representation Autoencoder (RAE)?
- Instead of using a VAE encoder designed mainly to compress images hard, the authors use a frozen, pretrained representation encoder like DINOv2, MAE, or SigLIP. These models are already great at understanding what’s in an image.
- They add a lightweight transformer decoder that learns to reconstruct the original image from those rich tokens.
- Unlike a VAE, the RAE does not squeeze the information into a tiny space. It keeps a higher‑dimensional, more meaningful representation, which helps the generator understand global structure and details.
Analogy: If making an image is like writing a story, a VAE gives you a tiny outline, while an RAE gives you a full set of notes about characters, setting, and plot. It’s easier to write a good story from better notes.
Training the RAE decoder
- The encoder is frozen (not trained further). Only the decoder learns.
- The decoder is trained to reconstruct the input image using a mix of simple pixel loss (L1), a perceptual loss (LPIPS) that cares about how images look to humans, and a small adversarial (GAN) loss for sharpness.
Making diffusion work in high‑dimensional tokens
Using richer, higher‑dimensional tokens is great for meaning, but it creates three challenges. The authors explain and fix each one:
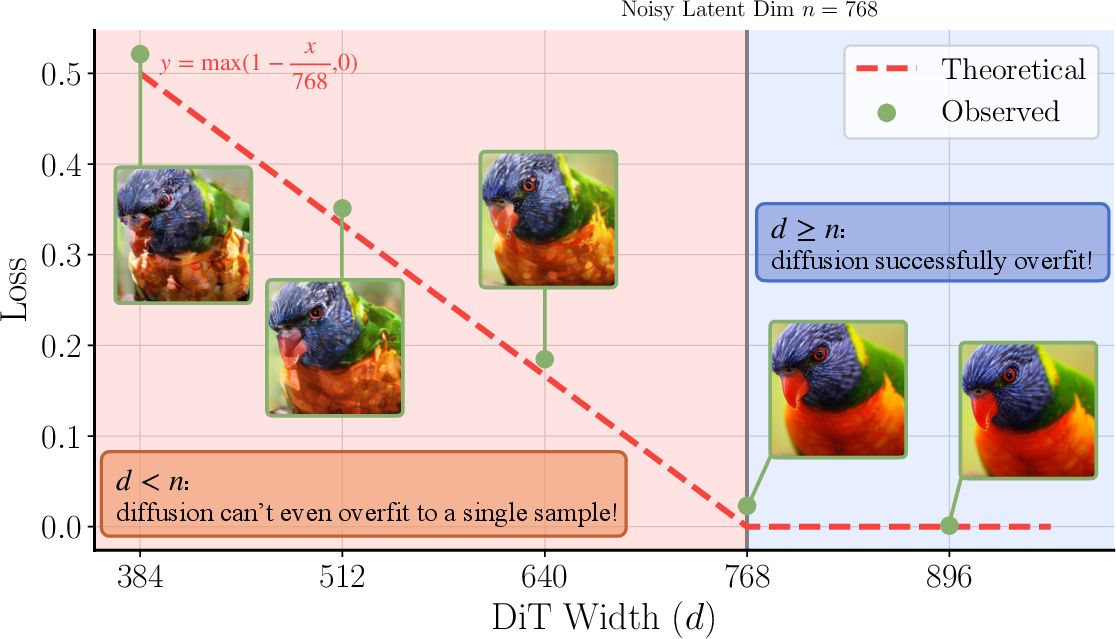
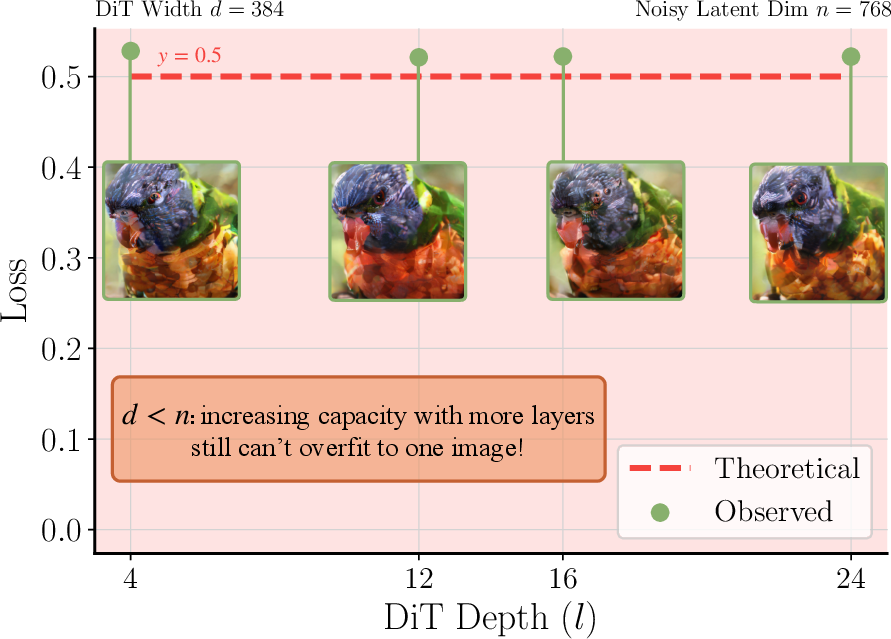
- Model width must match token size
- Finding: If the model’s inner width (number of hidden features) is smaller than the token dimension (e.g., 768), training struggles or fails.
- Fix: Use a wide enough diffusion transformer so its width is at least the token dimension. Analogy: If you try to pour 768 lanes of traffic into a 384‑lane tunnel, there will be a jam. Make the tunnel at least as wide as the traffic.
- Noise schedule should depend on data dimension
- In diffusion, you add noise to data during training. The authors show that when tokens have more channels/features, the usual noise schedule is too weak.
- Fix: Adjust the noise schedule based on the total data dimension (number of tokens × token size), not just the image resolution. This makes training stable again.
- The decoder must handle slightly “noisy” tokens
- Diffusion models sometimes produce tokens that are a bit off from the exact training codes.
- Fix: During decoder training, add small random noise to the encoder tokens so the decoder learns to reconstruct well even from slightly imperfect inputs. This improves generation quality.
A more efficient diffusion transformer: a wide, shallow “DDT head”
- Making the whole transformer wide can be expensive. The authors bolt on a small, shallow but wide “head” just for denoising, called a DDT head.
- This gives you the extra width you need for high‑dimensional tokens without making the entire model huge.
- They call the full model “DiT with a DDT head” (you can think of it as a standard diffusion transformer plus a wide add‑on at the end).
Main Findings and Why They Matter
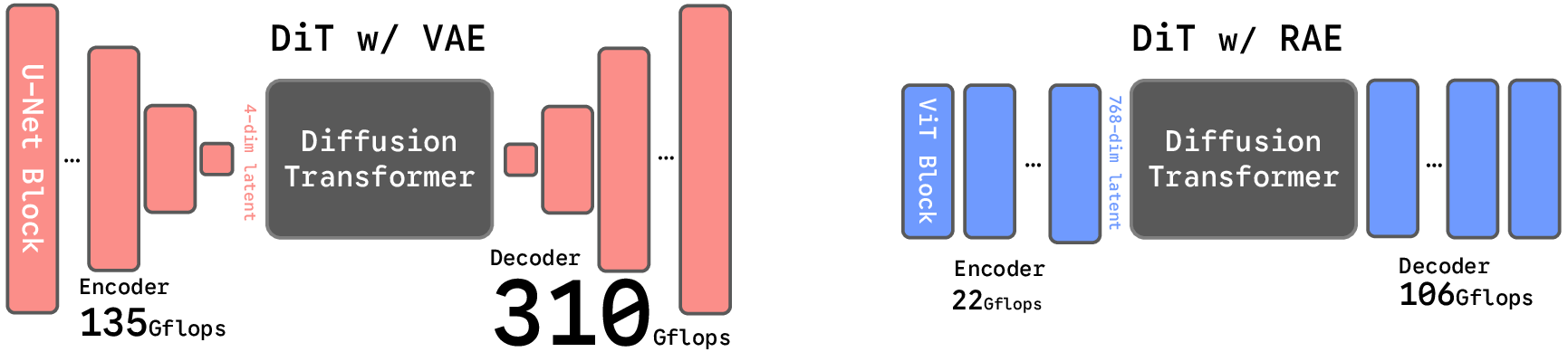
- Better reconstructions than the old VAE: With a frozen encoder like MAE or DINO and a simple decoder, the RAE reconstructs images as well as or better than the commonly used VAE in Stable Diffusion, while being more efficient.
- Faster, more stable training: With the three fixes (width match, dimension‑aware noise schedule, noise‑augmented decoder), diffusion transformers train quickly and stably on the richer RAE tokens.
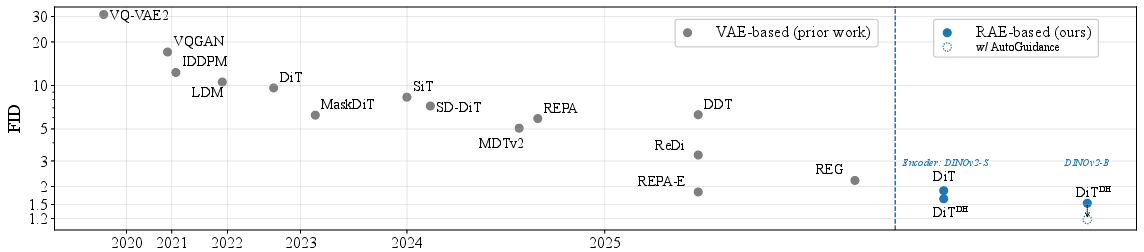
- Stronger image generation on ImageNet:
- At 256×256, FID 1.51 without guidance and 1.13 with guidance.
- At 512×512, FID 1.13 with guidance.
- Lower FID means better image quality; these are state‑of‑the‑art or very competitive results.
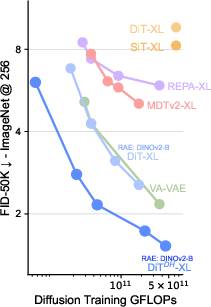
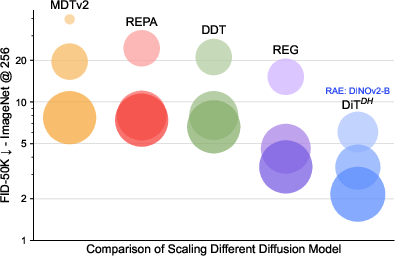
- Much faster convergence than prior methods: The RAE setup lets diffusion models reach good quality with less compute and fewer epochs compared to models that stick with old VAE latents or require extra alignment losses.
- Scales to higher resolution efficiently: You can keep the same tokens and let the decoder upsample to higher resolution (like 512×512), keeping quality strong without 4× more tokens.
- Structure matters: Simply using high‑dimensional raw pixels doesn’t work nearly as well. The “semantically structured” tokens from RAE encoders like DINO are key.
Why this is important: It challenges two common beliefs:
- That “semantic” encoders can’t reconstruct images well. They can, with the right decoder.
- That diffusion struggles in high‑dimensional spaces. It doesn’t, if you adjust model width and the noise schedule and train the decoder to handle slight noise.
Implications and Potential Impact
- A new default for training diffusion transformers: RAEs can replace VAEs to give richer, more meaningful hidden spaces that make training faster and generation better.
- Simpler pipelines: No need for extra “alignment” losses or multi‑stage tricks. Just use a strong pretrained encoder, train a decoder, and apply the three practical fixes.
- Better models, less compute: Because training converges faster, labs and developers can reach high quality without huge budgets.
- Easier scaling to big images: The decoder can handle upsampling, so you can reuse the same generator for higher resolutions with minor changes.
- Broader lesson: Building generators on top of strong representation learning (like DINO/MAE) tightly connects “understanding” and “creating” images, which could benefit future image, video, and multimodal models.
In short: By swapping the old VAE for a Representation Autoencoder and tuning the diffusion transformer to match it, the authors get faster training and higher‑quality images. This makes a strong case for RAEs to become the new standard in diffusion‑based image generation.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to be actionable for future research:
- Domain generalization: Validate RAE + DiT beyond ImageNet (e.g., COCO with captions, long-tail datasets, medical/remote sensing, sketches), measuring reconstruction/generation under significant distribution shifts and corruptions.
- Text-to-image conditioning: Test whether multimodal encoders (SigLIP/CLIP/JEPA) used as RAEs enable strong text-conditional diffusion without auxiliary alignment losses; compare to classifier-free guidance and REPA-style objectives.
- Encoder selection principles: Identify encoder properties that predict “diffusability” and generation quality (e.g., token covariance structure, inter-patch correlation, invariance/robustness) and synthesize a diagnostic metric to screen encoders.
- MAE vs DINOv2 discrepancy: Explain why MAE yields best reconstruction (rFID) but DINOv2 yields best generation (gFID); ablate feature statistics (e.g., whitening, norm/variance, frequency content) to isolate causal factors.
- Width requirement theory: Generalize and tighten the theorem on width ≥ token dimension beyond the toy linear/projection setting to realistic transformer blocks (self-attention, non-linearities), full datasets (not single-sample), and alternative parameterizations (EDM2, score matching, VP/VE SDEs).
- Circumventing width ≥ dimension: Explore architectures that avoid scaling backbone width to latent dimension (e.g., low-rank/adaptive projections, per-channel factorization, MoE heads, token-wise MLPs, grouped attention).
- First-layer projection design: Systematically study how the initial channel-to-hidden projection (linear vs gated/normalized/conv) impacts stability and quality in high-dimensional latents.
- Noise schedule shift derivation: Replace the heuristic SD3-style dimension-dependent shift (base dimension n=4096, α=√(m/n)) with a principled derivation tied to corruption rates in channel and spatial dimensions; quantify sensitivity to base n, α, and sampler/objective (Euler vs Heun, flow matching vs EDM2).
- Learnable scheduling: Investigate learned or adaptive timestep mapping conditioned on token statistics (e.g., feature norms, per-layer SNR) to better calibrate noise for high-dimensional latents.
- Noise-augmented decoder tuning: Optimize the decoder’s noise augmentation (σ distribution, curriculum, non-Gaussian noise) to reduce the rFID penalty while retaining gFID gains; evaluate inference-time noise-aware decoding (e.g., denoiser conditioning).
- Decoder robustness vs detail: Develop decoders that retain high-frequency detail under noisy latents (e.g., diffusion-aware decoders, multi-scale skip connections, hybrid GAN+SR objectives); quantify trade-offs under controlled noise injections.
- High-resolution scaling strategy: Compare “decoder upsampling” (p_d ≠ p_e) against hierarchical/patch-expansion latent diffusion (more tokens) across cost–quality Pareto curves; test hybrid approaches (low-NFE latent refinement followed by decoder SR finetune).
- DDT head design space: Expand ablations on head depth/width, attention vs MLP-only, parameter sharing, and placement (early vs late injection); analyze why DDT helps in high-dimensional RAEs but hurts in low-dimensional VAEs and whether specialized heads can help both.
- Compute/memory profiling: Rigorously benchmark training/inference throughput, memory, energy, and wall-clock for RAE vs VAE latents and DiT vs DiT+DDT across resolutions; reconcile the claim of “no extra cost” with the width increases required by RAEs.
- Token count and patch size: Study the effect of varying token length (patch size, stride, overlapping patches) on training stability, cost, and quality; determine optimal tokenization for different encoder families and resolutions.
- End-to-end co-training: Explore partial encoder finetuning (adapters, LoRA) or joint training (encoder–decoder–diffuser) without collapsing semantics; measure representation retention (linear probe) vs generation gains.
- Conditioning interfaces: Investigate how class/text conditioning interacts with RAE latents (e.g., cross-attention locations, token selection, conditioning scale) and whether RAEs enable stronger controllability/editability than VAE latents.
- Safety and bias: Assess whether pretrained representation encoders introduce semantic biases or privacy risks in RAE-based generation; develop mitigation strategies (data curation, debiasing adapters, filtering).
- Evaluation protocol standardization: Quantify the impact of balanced vs random class sampling on FID/IS/precision–recall; release evaluation scripts and fix parameters (NFE, sampler, guidance strength) to ensure apples-to-apples comparisons.
- Alternative objectives/samplers: Test EDM2/VE/VP objectives, preconditioning, and advanced samplers (DPM-Solver++, Heun, SNR-based weighting) on RAEs; measure convergence speed and final quality relative to flow matching.
- Robustness and OOD decoding: Evaluate decoder performance on diffusion latents with structured errors (e.g., anisotropic noise, channel-dependent perturbations, adversarial noise) and develop defenses.
- Latent editability and controllability: Probe whether RAEs afford better semantic editing (token-wise interventions, feature steering) than VAE latents; design interfaces for attribute control.
- Extreme latent dimensions: Scale to ViT-H/G or SigLIP-L (d≫1024) to stress-test the width requirement and DDT scalability; identify bottlenecks and propose remedies (memory-efficient attention, chunked heads).
- Multi-modal and non-image extensions: Validate RAEs for video (spatiotemporal tokens), audio, 3D, and multimodal generation; adapt the dimension-dependent scheduling and decoder noise augmentation to these modalities.
- Data and licensing constraints: Clarify licensing and reproducibility for using third-party encoders (DINOv2, SigLIP, MAE); evaluate whether encoder licensing or training data restrictions affect deployment.
- Integration with alignment methods: Although RAEs avoid auxiliary alignment losses, test whether lightweight alignment (e.g., REPA-style on select layers) can further help in low-data regimes or for weaker encoders.
- Precision–recall trade-offs: Go beyond FID/IS to analyze coverage vs fidelity under RAEs (e.g., improved recall but slightly reduced precision); characterize how decoder noise augmentation and DDT head affect this balance.
Practical Applications
Immediate Applications
The following applications can be deployed now by swapping VAEs with Representation Autoencoders (RAEs), adopting the training recipe (width matching, dimension-dependent schedule shift, noise-augmented decoding), and optionally using the wide DDT head for compute-efficient scaling.
- Drop-in replacement for VAEs in latent diffusion pipelines (Software/AI)
- Use case: Upgrade existing DiT/latent diffusion stacks to RAE latents (DINOv2/MAE/SigLIP encoders + ViT decoder with L1+LPIPS+GAN and noise augmentation).
- Benefits: Faster convergence (up to ~16–47× reported vs. alignment-based or VAE baselines), lower FID (e.g., 1.51 at 256×256 unguided; 1.13 guided at 256×256 and 512×512), simpler architecture.
- Tools/workflows:
- Freeze pretrained encoder (DINOv2-B or domain-specific), train a ViT decoder.
- Train DiT with width ≥ token dim (e.g., 768), apply dimension-dependent schedule shift, add decoder noise augmentation.
- Optional: Attach wide DDT head to boost width without quadratic compute.
- Assumptions/dependencies: Access to suitable pretrained encoders and training data; license compatibility for encoders; availability of training resources (GPUs/TPUs); integration effort in existing codebases.
- Multi-resolution production generation via decoder upsampling (Media/Design/Advertising/Gaming)
- Use case: Generate 256×256 samples and upsample to 512×512 by swapping in an upsampling decoder (set decoder patch size p_d=2p_e) without retraining the diffusion model.
- Benefits: 4× fewer tokens vs. direct 512×512 training, competitive FID (e.g., 1.61 vs. 1.13 direct).
- Tools/products: A reusable “resolution-scaled” decoder library for post-hoc upsampling in production.
- Assumptions/dependencies: Trained base decoder; tolerance for slight rFID degradation; quality verification for target use.
- Cost and energy savings through faster convergence (Energy/Cloud/Platform)
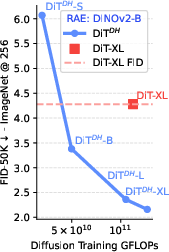
- Use case: Reduce training FLOPs while improving image quality (e.g., DiT-B + DDT head improves FID with ~40% training FLOPs vs. DiT-XL).
- Benefits: Lower cloud bills and carbon footprint; quicker iteration cycles.
- Tools/workflows: Training dashboards with dimension-dependent schedule shift utility; width-matching checker.
- Assumptions/dependencies: Ability to reconfigure model widths and schedules; monitoring FID/IS metrics; balanced-class FID evaluation protocol.
- Domain-specific generative modeling with frozen encoders (Healthcare, Geospatial, Retail, Industrial)
- Use case: Use a domain-pretrained encoder (e.g., MAE trained on medical scans or satellite imagery) with a trained decoder to build domain RAEs for high-fidelity generative tasks.
- Benefits: Preserve strong semantics (e.g., higher linear-probe accuracy), better generative fidelity than SD-VAE latents.
- Tools/workflows: Decoder training with adversarial and perceptual losses; noise-augmented decoding for robust inference.
- Assumptions/dependencies: Access to domain encoders; compliance with privacy/regulatory constraints; domain-level curation and evaluation metrics beyond ImageNet.
- Synthetic data generation with improved semantic fidelity (Industry/Academia)
- Use case: Produce class-conditional or attribute-rich synthetic datasets for downstream training (classification/detection/segmentation).
- Benefits: Semantically richer features may yield better transfer performance and lower mode collapse risks.
- Tools/workflows: Conditional RAEs with class labels; pipeline for balanced sampling to meet FID fairness; data curation tools.
- Assumptions/dependencies: Target task requires synthetic data; proper labeling; safeguards against distribution shift and bias amplification.
- On-device or edge creative apps with better quality per FLOP (Mobile/Consumer)
- Use case: Photo editing, inpainting, stylistic enhancement powered by RAE latents; small DiT + DDT head configurations for improved FLOP-efficiency.
- Benefits: Higher visual fidelity without raising token counts; robust decoding due to noise augmentation.
- Tools/products: SDKs integrating RAEs for mobile image generation; lightweight inference graphs with shallow-wide heads.
- Assumptions/dependencies: Efficient on-device accelerators; trimmed model widths; careful memory management.
- Reproducible evaluation and fair benchmarking (Academia/Policy)
- Use case: Adopt class-balanced sampling for conditional FID and standardized dimension-dependent schedule reporting.
- Benefits: More reliable inter-paper comparisons; mitigates hidden evaluation inconsistencies.
- Tools/workflows: Evaluation scripts enforcing balanced sampling; documentation of schedule shift factors.
- Assumptions/dependencies: Community buy-in; availability of checkpoints for re-evaluation.
- Robust image restoration and enhancement workflows (Daily life/Software)
- Use case: Leverage RAEs to reconstruct or enhance images (denoising, deartifacting) using pretrained semantic encoders and robust decoders.
- Benefits: High-fidelity reconstructions (e.g., rFID down to 0.16 with MAE-B) and resilience to noisy latents.
- Tools/products: Restoration plugins for photo apps; ViT-based decoders trained with LPIPS + adversarial losses.
- Assumptions/dependencies: Quality of pretrained encoders on target domains; tuning of decoder noise augmentation to balance reconstruction vs. robustness.
Long-Term Applications
These require further research, scaling, domain adaptation, or ecosystem development before broad deployment.
- Video RAEs and high-dimensional latent diffusion for temporal generation (Media/Robotics/Simulation)
- Use case: Extend RAEs to video encoders (e.g., TimeSformer/ViT-video) and train diffusion transformers with wide heads to model structured spatiotemporal latents.
- Potential products: High-fidelity video synthesis, simulation data for robotics, film previsualization tools.
- Assumptions/dependencies: Robust video encoders; temporal-aware decoders; schedule shifts calibrated to spatiotemporal dimensionality; significant compute.
- Multimodal RAEs for text-conditioned generation (Software/Creative Tools)
- Use case: Use language-supervised encoders (SigLIP/CLIP-like) to unify semantic latents and text prompts for tighter alignment and faster training.
- Potential workflows: Next-gen T2I models with semantically rich latents and reduced need for alignment losses.
- Assumptions/dependencies: Strong multimodal encoders; careful conditioning design; evaluation beyond FID (alignment, faithfulness, safety).
- Semantic editing interfaces through structured latent manipulation (Design/Advertising/Film)
- Use case: Interactive tools that steer high-level attributes directly in the RAE latent space (style, composition, object attributes).
- Potential products: Creative UIs offering intuitive semantic controls; CAD-like semantic knobs for image synthesis.
- Assumptions/dependencies: Robust disentanglement or controllability methods in high-dimensional latents; user studies; safety guardrails.
- Ultra-high-resolution (4K/8K) generation via hierarchical decoder scaling (Media/Imaging)
- Use case: Stack decoder upsamplers (p_d multipliers) with learned detail injection to scale resolution without quadratic token growth.
- Potential products: Efficient 4K/8K synthesis for cinema/marketing; scalable print design workflows.
- Assumptions/dependencies: Multi-stage decoders; artifact mitigation; training data diversity at high resolution.
- Domain-specific synthetic data ecosystems (Healthcare/Geospatial/Manufacturing)
- Use case: Curated RAEs for regulated domains to generate data for rare conditions, adverse scenarios, or sparse classes.
- Potential products: Compliance-certified synthetic data services; scenario libraries for safety testing.
- Assumptions/dependencies: Regulatory approval, privacy-preserving practices, robust validation (beyond FID), governance frameworks against misuse.
- Hardware and compiler co-design for wide-head transformers (Semiconductors/Cloud)
- Use case: Optimize accelerators and kernels for shallow-but-wide heads to exploit width scaling without quadratic compute costs.
- Potential products: RAE/DiT-aware compilers; operator fusion for ViT decoders and diffusion heads.
- Assumptions/dependencies: Vendor support; standardized model IR; performance benchmarking suites.
- Representation-aware codecs and hybrid compression (Streaming/Imaging)
- Use case: Investigate light compression of semantically rich latents and reconstruction via ViT decoders for bandwidth-sensitive applications.
- Potential products: New codecs that trade off exact pixel fidelity for semantic consistency; streaming of latent features with client-side decoders.
- Assumptions/dependencies: Acceptable perceptual trade-offs; standards development; device-side decoder support.
- Safety, watermarking, and provenance in semantically rich latents (Policy/Compliance)
- Use case: Embed provenance or watermarks at the latent level; detect manipulation by inspecting structured features.
- Potential workflows: Compliance-grade watermarking pipelines; risk auditing tools for generative content.
- Assumptions/dependencies: Reliable watermarking in high-dimensional latents; resistance to removal; policy harmonization.
- Cross-task transfer: bridging discriminative and generative modeling (Academia/Software)
- Use case: Exploit shared RAEs to pretrain encoders that serve both generation and downstream recognition tasks, improving sample efficiency.
- Potential products: Unified foundation models for vision tasks; training recipes that reuse RAEs across pipelines.
- Assumptions/dependencies: Demonstrated transfer gains across diverse tasks; stable training for joint objectives; careful evaluation protocols.
Glossary
- Adversarial losses: Loss terms from GAN training used to encourage realistic reconstructions. "and adversarial losses~\citep{GAN}, following common practice in VAEs:"
- AutoGuidance: A sampling guidance technique that improves diffusion model outputs without external classifiers. "with AutoGuidance~\citep{AG}"
- DDT: A prior diffusion transformer approach that decouples components and leverages representation alignment to accelerate convergence. "draw inspiration from DDT~\citep{ddt}"
- DDT head: A shallow, wide transformer head attached to a DiT to increase effective width for denoising without quadratic compute. "introduce the DDT head—a shallow yet wide transformer module dedicated to denoising."
- DINOv2: A self-supervised vision transformer encoder producing semantically rich image features. "DINOv2-B \citep{Dinov2}"
- DiT: Diffusion Transformers; transformer-based denoising backbones for latent diffusion. "Diffusion Transformers (DiT)~\citep{dit,sit}"
- Diffusability: The degree to which a latent distribution can be effectively modeled by a diffusion model. "we now proceed to investigate the diffusability~\citep{ImprovDiffus} of its latent space"
- Euler sampler: A numerical sampler (ODE/flow-based) used to generate samples from trained diffusion/flow-matching models. "with 50 steps with the Euler sampler (denoted as gFID)"
- FID: Fréchet Inception Distance; a standard metric for generative image quality. "We use FID score~\citep{fid}"
- Flow matching objective: A training objective that learns a velocity field to map noise to data via continuous-time flows. "we adopt the flow matching objective~\citep{fm, rf}"
- gFID: FID measured on generated samples (generation FID) rather than reconstructions. "denoted as gFID"
- GFLOPs: Billions of floating-point operations; a measure of computational cost. "more efficient in GFLOPs"
- JEPA: Joint-Embedding Predictive Architecture; a self-supervised representation learning framework. "JEPA~\citep{assran2023self}"
- Latent Diffusion Models (LDM): Generative models that perform diffusion in a learned latent space instead of pixel space. "Latent Diffusion Models (LDM)~\citep{LDM}"
- LightningDiT: A DiT variant used as the backbone for diffusion in this work. "We use LightningDiT~\citep{lgt}"
- Linear probing: Evaluating representation quality by training a linear classifier on frozen features. "via linear probing on ImageNet-1K"
- LPIPS: Learned Perceptual Image Patch Similarity; a perceptual reconstruction quality metric. "LPIPS~\citep{lpips}"
- MAE: Masked Autoencoder; a self-supervised vision model trained by reconstructing masked patches. "MAE~\citep{MAE}"
- Normalizing Flows: Generative models built from invertible transformations with tractable likelihoods. "Normalizing Flows~\citep{dinh2016density, ho2019flow++, zhai2024normalizing}"
- Noise-augmented decoding: Training the decoder on latents perturbed with Gaussian noise to improve robustness at sampling time. "We now adopt the noise-augmented decoding for all our following experiments."
- RAE (Representation Autoencoder): An autoencoder that uses a frozen pretrained representation encoder with a trained decoder, yielding semantic, high-dimensional latents. "Representation Autoencoders (RAEs)"
- REPA: A representation alignment approach that improves DiT convergence by aligning internal features to pretrained encoders. "REPA~\citep{repa}"
- rFID: Reconstruction FID; FID computed on reconstructed images to assess autoencoding quality. "denoted as rFID."
- Schedule shift: Adjusting the diffusion noise/timestep schedule based on data dimensionality or resolution for stable training. "resolution-based schedule shifts~\citep{chen2023importance, simplediffusion, SD3}"
- SD-VAE: The VAE used in Stable Diffusion; a convolutional, compressed latent autoencoder widely used in LDMs. "SD-VAE \citep{LDM}"
- SigLIP2: A language-supervised vision encoder producing semantically aligned image features. "SigLIP2-B~\citep{siglip2}"
- ViT: Vision Transformer; a transformer architecture operating on image patches, used here as the decoder. "A ViT decoder with patch size maps them back to pixels"
Collections
Sign up for free to add this paper to one or more collections.