Both Semantics and Reconstruction Matter: Making Representation Encoders Ready for Text-to-Image Generation and Editing
Abstract: Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction. To unify vision generation and understanding, a burgeoning trend is to adopt high-dimensional features from representation encoders as generative latents. However, we empirically identify two fundamental obstacles in this paradigm: (1) the discriminative feature space lacks compact regularization, making diffusion models prone to off-manifold latents that lead to inaccurate object structures; and (2) the encoder's inherently weak pixel-level reconstruction hinders the generator from learning accurate fine-grained geometry and texture. In this paper, we propose a systematic framework to adapt understanding-oriented encoder features for generative tasks. We introduce a semantic-pixel reconstruction objective to regularize the latent space, enabling the compression of both semantic information and fine-grained details into a highly compact representation (96 channels with 16x16 spatial downsampling). This design ensures that the latent space remains semantically rich and achieves state-of-the-art image reconstruction, while remaining compact enough for accurate generation. Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model. Benchmarking against various feature spaces, we demonstrate that our approach achieves state-of-the-art reconstruction, faster convergence, and substantial performance gains in both T2I and editing tasks, validating that representation encoders can be effectively adapted into robust generative components.



Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What this paper is about (big picture)
This paper is about making computers better at creating and editing images from text by giving them the right kind of “internal language” to think in. Today’s best image generators use a simple, compact code for pictures that’s great for copying pixels but weak at understanding what’s in the scene. Meanwhile, the best vision encoders (used for recognizing objects) understand meaning very well but aren’t designed for drawing detailed images.
The authors show how to combine both strengths—meaning and detail—into one shared representation so text-to-image generation and image editing become more accurate, faster to train, and better at following instructions.
What questions the paper asks
- Can we use the rich, semantic features from powerful vision encoders (like DINOv2 or SigLIP2) for image generation, instead of the usual low-level VAE codes?
- Why do current attempts to generate images directly in these semantic feature spaces produce weird shapes and textures?
- Can we design a new representation that keeps high-level meaning and also supports sharp, faithful pixel-level details?
- Will this new representation help both text-to-image generation and instruction-based image editing?
How they approached it (in simple terms)
Think of an image system as a brain with two skills:
- “Understanding” (semantics): knowing that an image has “a small red car on a street.”
- “Drawing” (reconstruction): being able to paint the car’s exact shape, reflections, and text.
Most current systems are lopsided—either they understand well but can’t draw faithfully, or they draw pixels well but don’t truly understand the scene. The authors build a middle ground called PS-VAE that teaches the model to do both.
Here are the main ideas, explained with plain analogies:
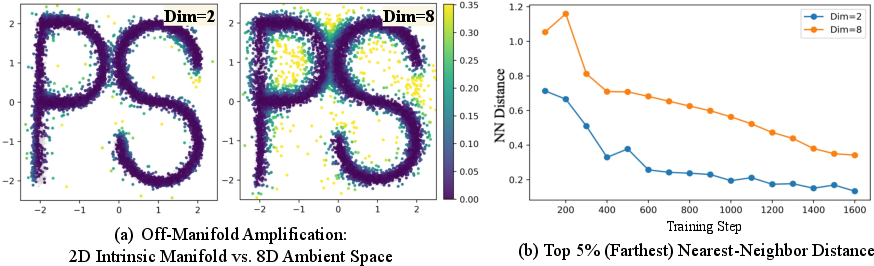
- The “off-manifold” problem: Imagine trying to draw along a thin trail on a giant field. If you wander off the trail, your drawing becomes nonsense. When models generate in huge, unconstrained feature spaces from understanding-focused encoders, they easily drift “off the trail,” leading to broken shapes or textures. This happens because the space is very high-dimensional and not tightly organized for generation.
- Step 1: Make the space compact and safe (S-VAE).
- They take the big semantic features (e.g., from DINOv2) and compress them into a small, well-regularized code (96 channels on a 16×16 grid).
- They train a “semantic autoencoder” to ensure the compressed code still matches the original meaning.
- They also add a regularizer (KL loss) that gently squeezes the space into a tidy shape, so generation stays “on the trail.”
- Step 2: Add pixel-level detail without losing meaning (PS-VAE).
- After the semantic space is stable, they let the pixel reconstruction loss update the encoder too, so it learns to keep fine textures (like hair strands, text, or fabric).
- At the same time, they keep a semantic loss to make sure it doesn’t forget high-level understanding.
- The result is a single compact code that preserves both meaning and detail.
- Training the generator:
- They train a diffusion model to generate in this new compact code.
- For text-to-image and editing, they use an efficient “deep-fusion” transformer design to mix text and image latents. They also use a “wide head” trick to better handle high-channel features.
In short: they first fix the “drifting off the trail” issue by making a compact, regularized semantic space (S-VAE). Then they teach it to remember pixel details too (PS-VAE). Finally, they train a generator on that space.
What they found and why it matters
- Stronger reconstruction (sharper, more faithful images):
- Compared to a popular baseline VAE trained on pixels (MAR-VAE), their PS-VAE greatly improves standard fidelity scores: rFID drops from about 0.53 to 0.20 (lower is better), PSNR rises from ~26.2 to ~28.8 (higher is better), SSIM rises from ~0.72 to ~0.82 (higher is better).
- Translation: the system can recreate images more accurately, with better structure and textures.
- Better text-to-image generation:
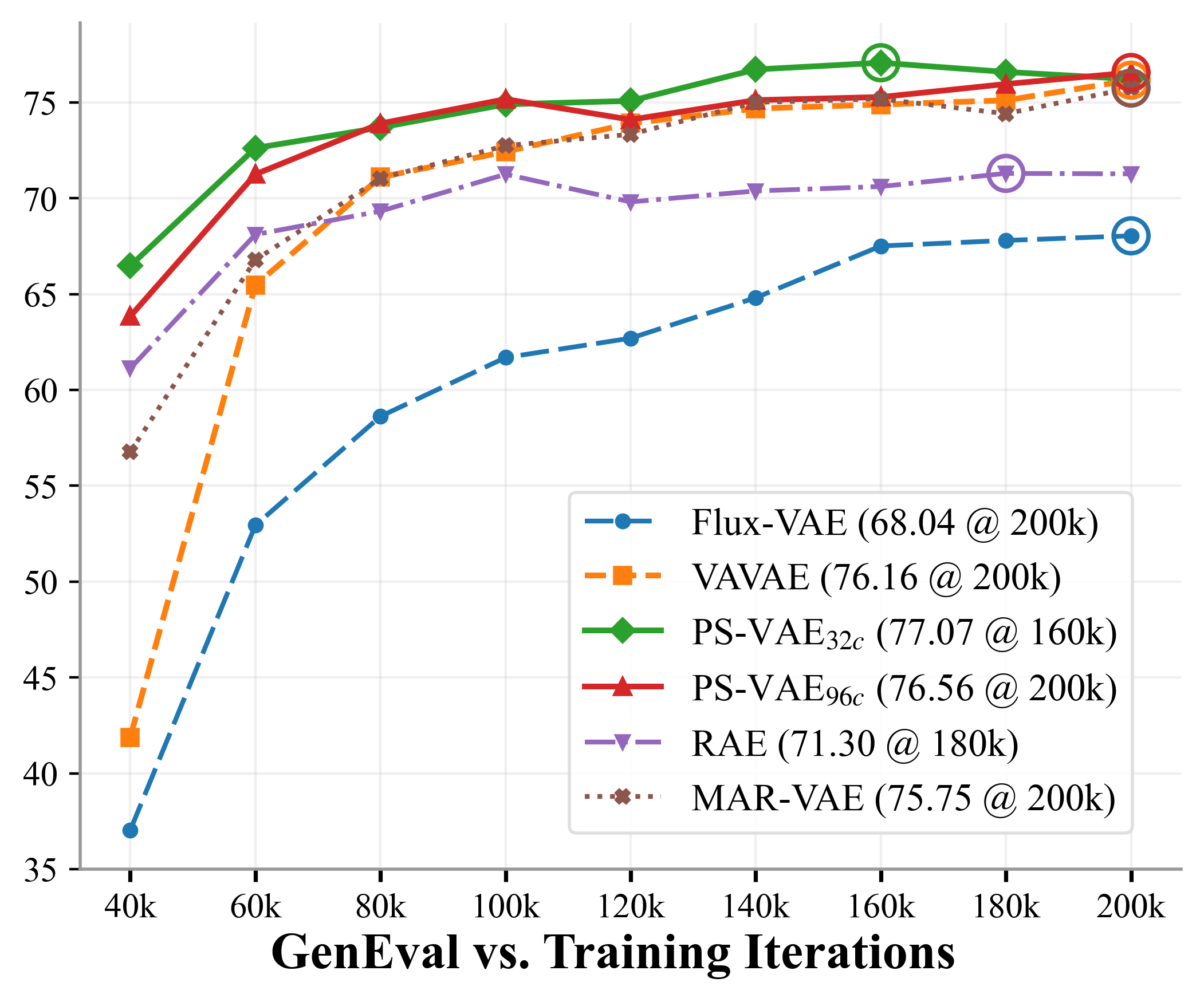
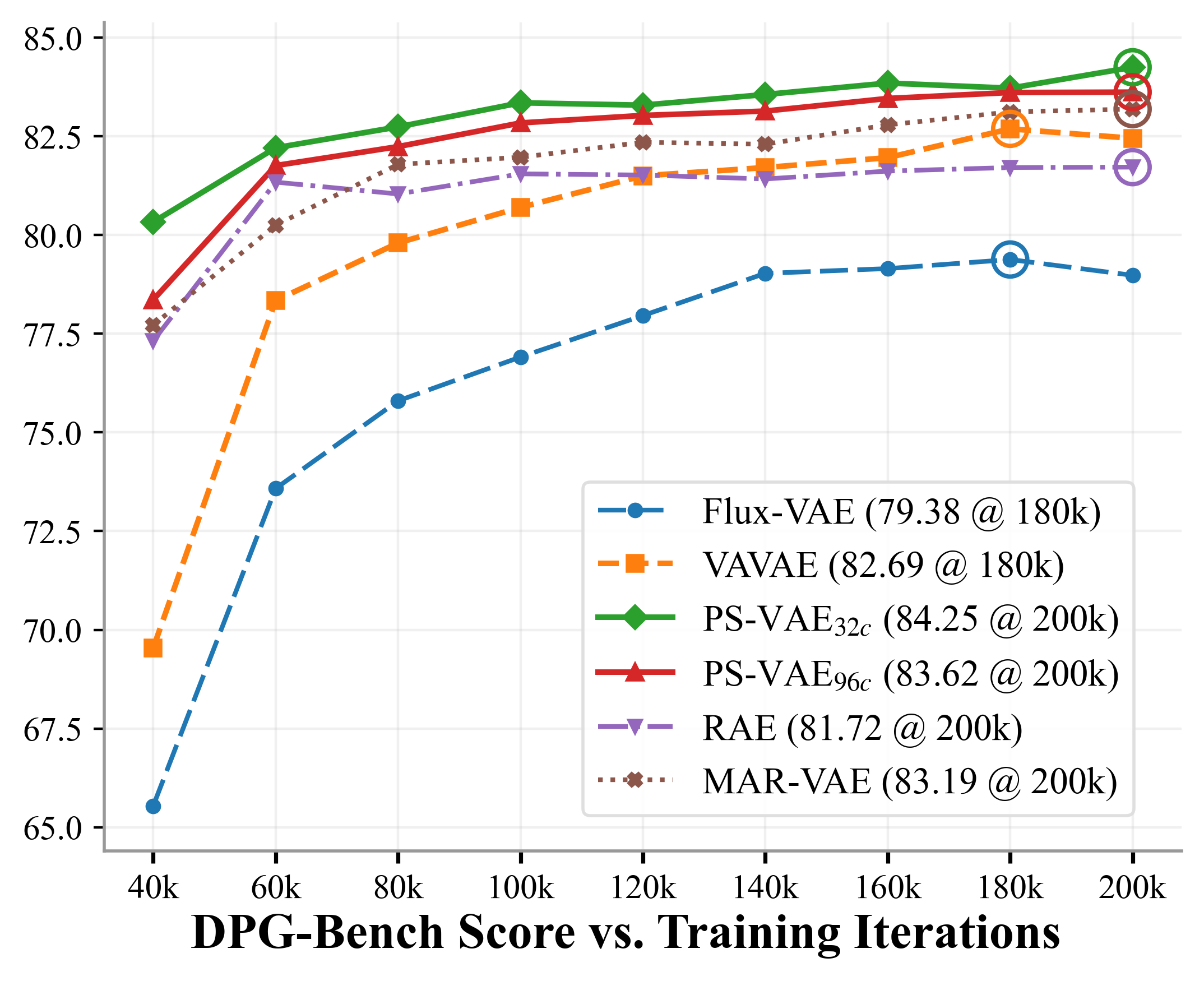
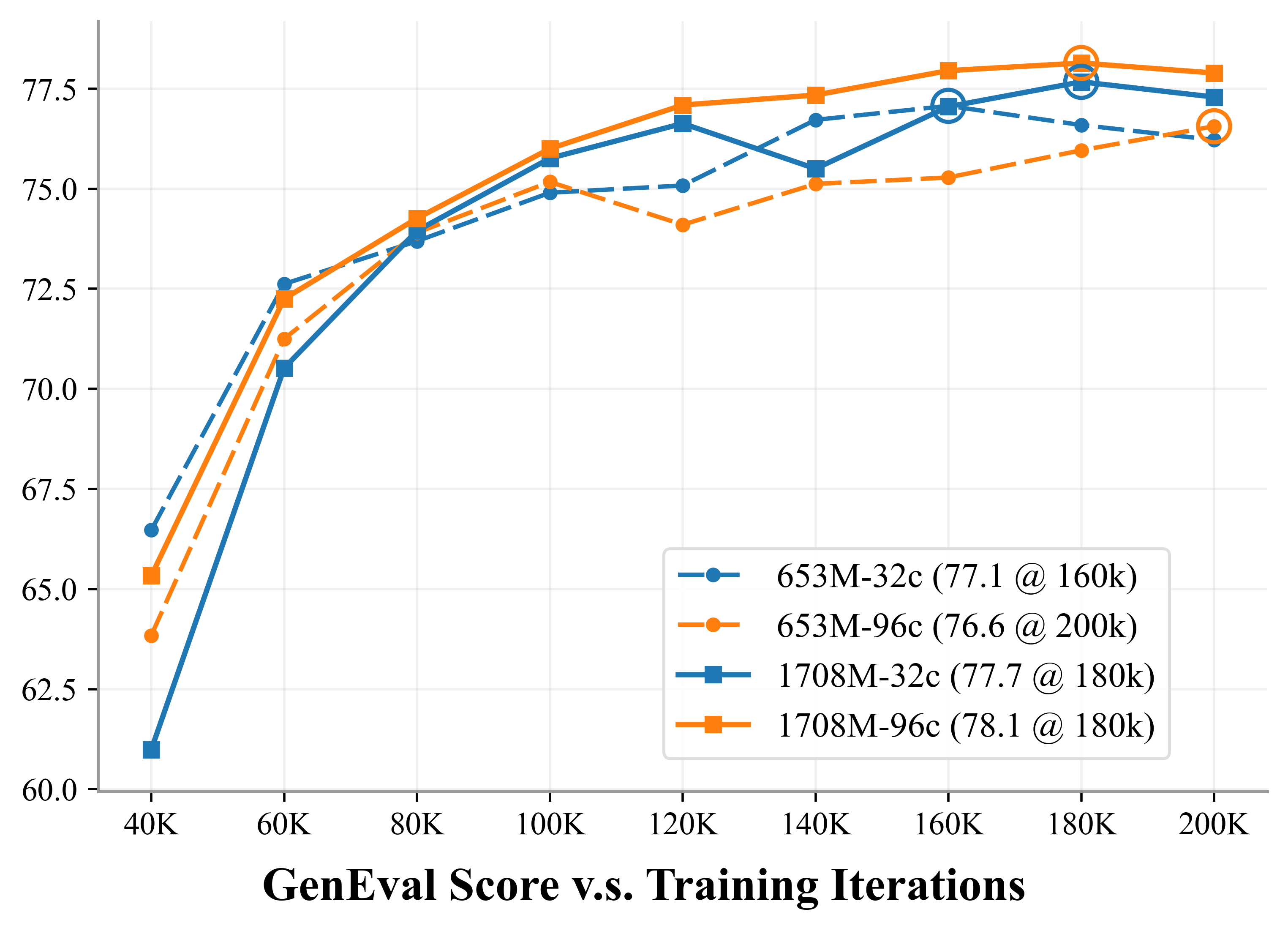
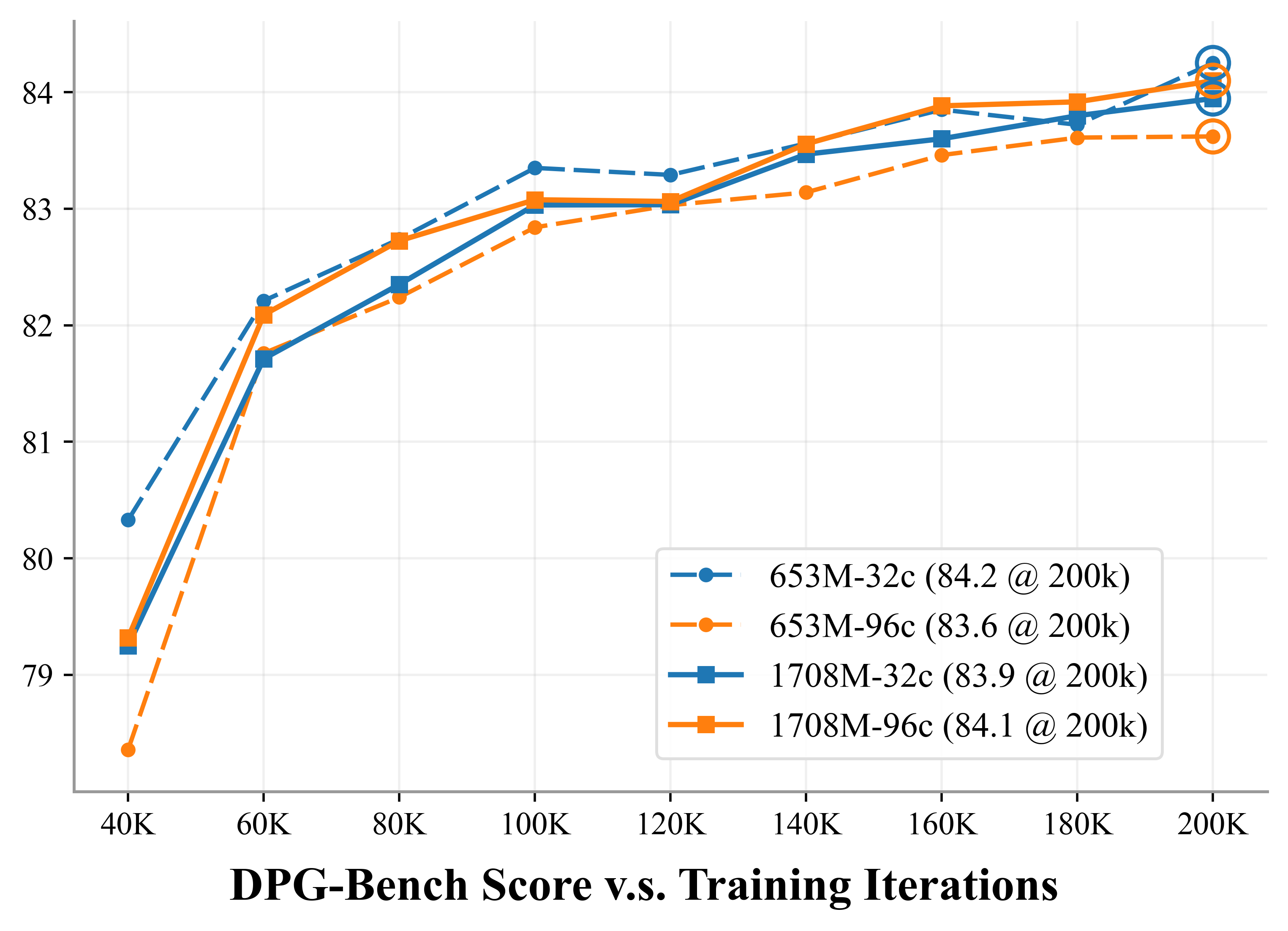
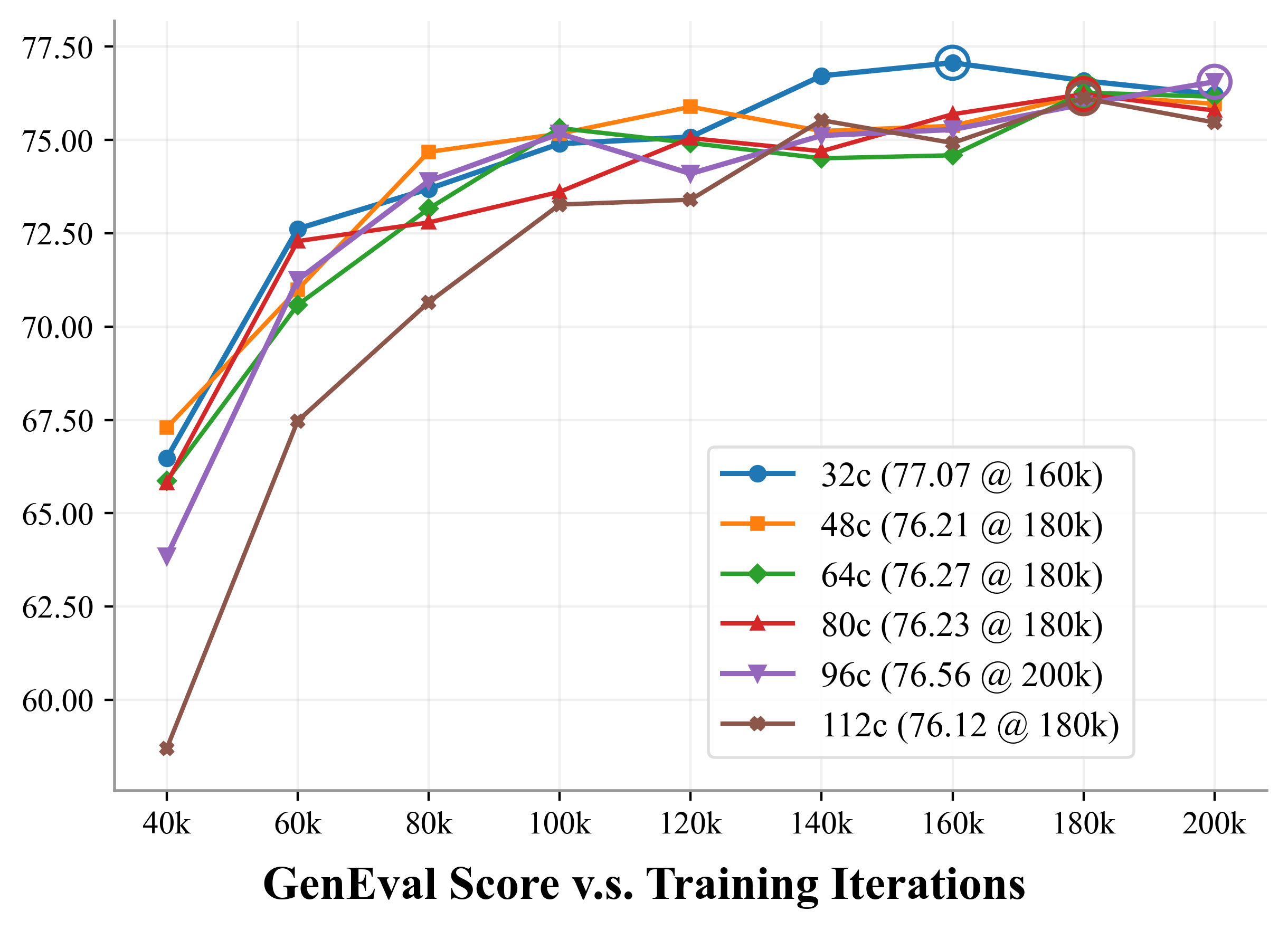
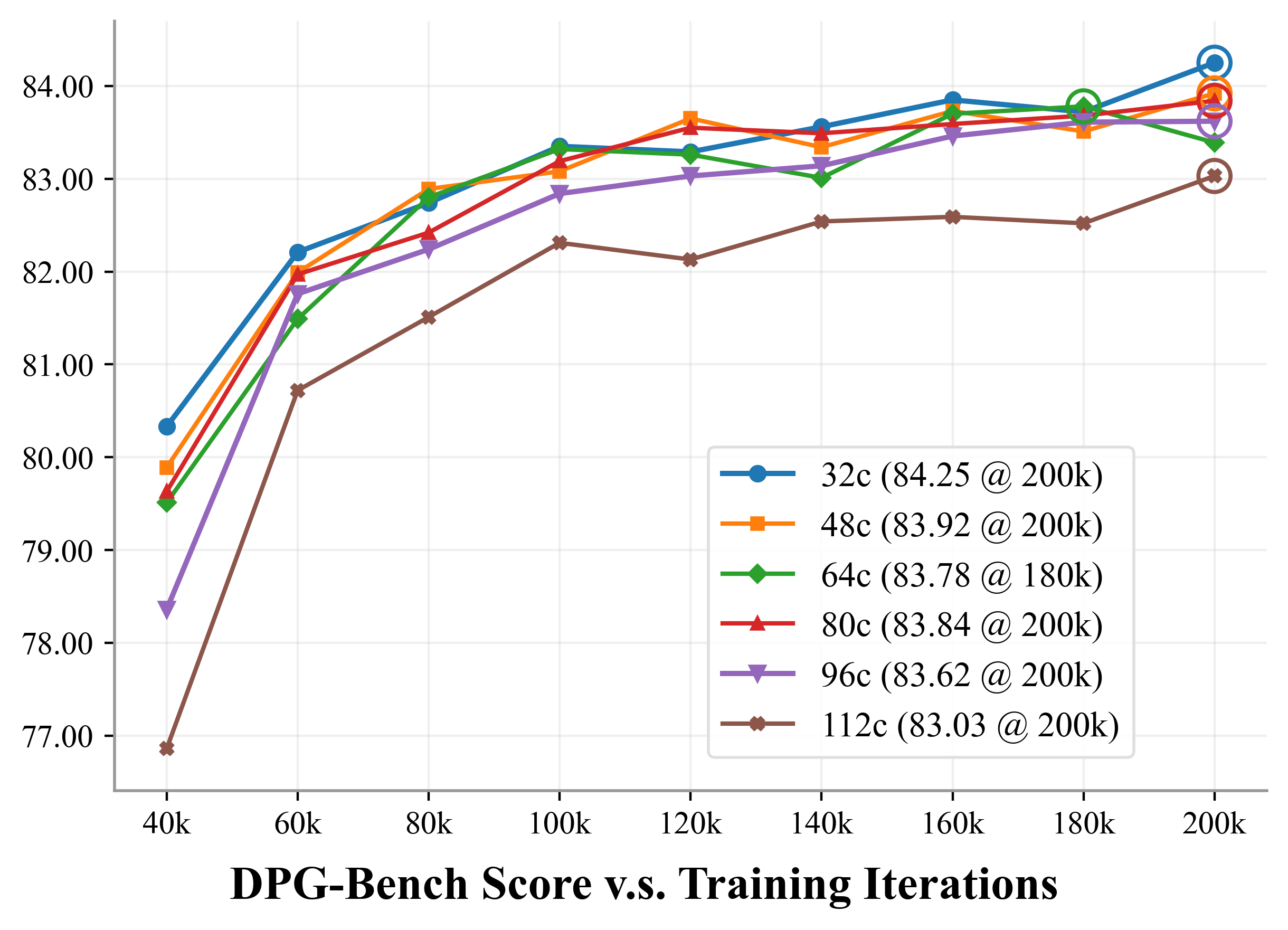
- It converges faster during training and ends up slightly better on standard benchmarks (e.g., GenEval and DPG-Bench), meaning it follows prompts well and produces cleaner objects with fewer visual artifacts.
- Much better instruction-based image editing:
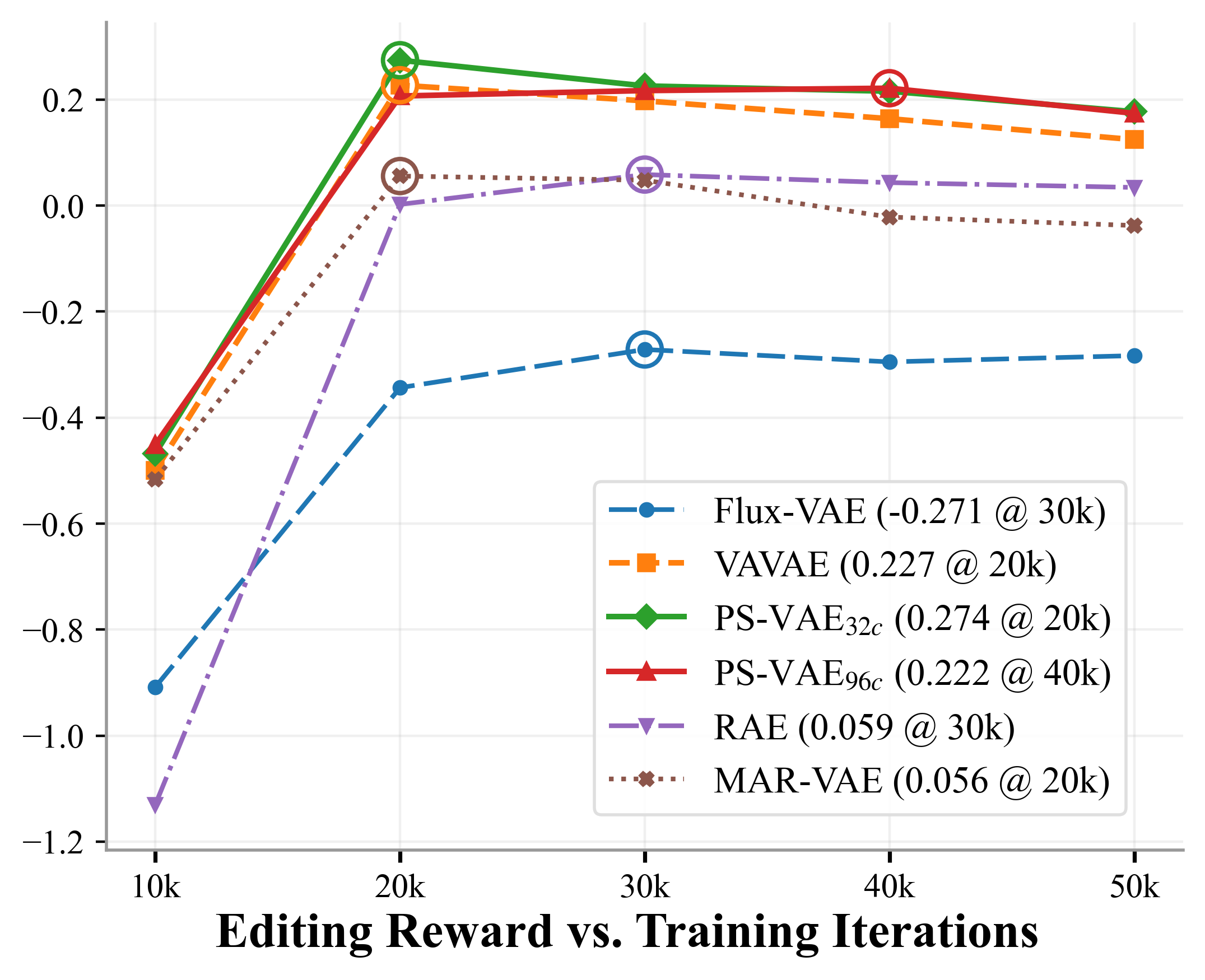
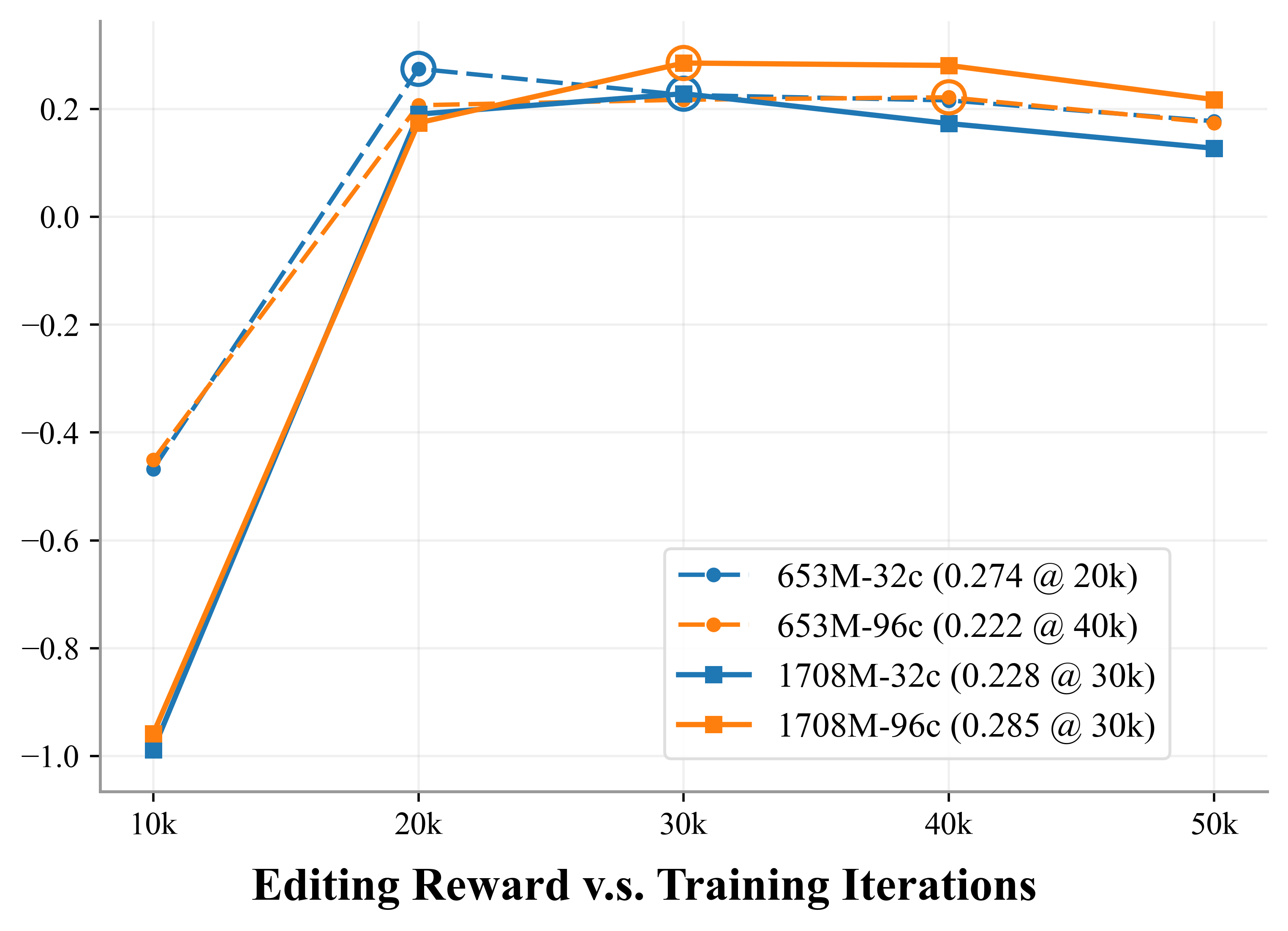
- Editing Reward improves a lot (from ~0.06 to ~0.22), meaning the system both understands the requested edit and preserves original image details (like consistent faces, letters, and surfaces). This is where having both meaning and pixels really pays off.
- Explains why earlier methods struggled:
- Generating directly in huge, unconstrained semantic spaces causes “off-manifold” outputs (like drawing off the trail), which leads to warped shapes and textures. Their compact, regularized semantic space fixes this.
- Scales well:
- With bigger generators, their 96-channel version keeps improving, suggesting this design has a higher performance ceiling as models get larger.
- Generalizes across encoders:
- They also adapt SigLIP2 (a popular vision–language encoder) with similar benefits, hinting at a path to unified models that do both understanding and generation with the same encoder.
Why this is important
This work is a step toward unifying image “understanding” and image “creation” inside one system. That means:
- Faster, better training: Generators can learn from strong, structured features instead of starting from raw pixels.
- More reliable results: Fewer distorted shapes and textures thanks to a regulated, compact latent space.
- Stronger editing tools: Systems can understand what to change and preserve what should stay, which is crucial for practical photo editing, content creation, and design tools.
- A shared foundation: The same encoder can serve both analysis tasks (like recognition) and creative tasks (like generation), simplifying future AI systems.
In everyday terms: the paper shows how to give AI both a good vocabulary for meaning and a good memory for details. With both, it can follow instructions better and draw what it understands more faithfully.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single consolidated list of concrete gaps and unresolved questions that future work could address:
- Resolution scaling: The autoencoder and generator are trained and evaluated at 224–256 px; it remains unknown how PS-VAE behaves at 512/1024+ px in terms of reconstruction fidelity, semantic preservation, and T2I/Editing performance, as well as the compute/memory trade-offs.
- Dataset diversity for reconstruction: Reconstruction is trained only on ImageNet-1K; robustness to diverse domains (e.g., scenes, faces, typography, diagrams, medical, artworks) and out-of-distribution content is untested.
- Generalization of the approach across encoders: Results are shown for DINOv2-B and partially for SigLIP2; applicability to other encoders (e.g., EVA-CLIP, InternViT, MOCO-v3, MAE, Perception Encoder), different patch sizes, and tokenization schemes remains unexplored.
- Post-tuning understanding ability: The claim that fine-tuning preserves “strong understanding” is not validated on standard benchmarks (e.g., ImageNet-1K linear probe, retrieval, segmentation, detection); quantify any trade-off between generative adaptation and discriminative performance.
- Nonlinear manifold modeling: The off-manifold analysis assumes a linear embedding (x=Qz); how the conclusions change under nonlinear manifolds (more realistic for foundation encoders) is unstudied. Empirical estimation of intrinsic dimension and manifold structure in encoder features is missing.
- Off-manifold detection and control at inference: No mechanism is provided to detect or project generated latents back onto the valid decoding manifold during sampling (e.g., manifold projection, energy-based penalties, contractive losses, or learned priors).
- KL prior design and sensitivity: The KL weight, choice of standard Gaussian prior, and risk of posterior collapse are not ablated; alternative priors (e.g., learned priors, normalizing flows, VQ), annealing schedules, and their influence on generation and reconstruction remain open.
- Loss balancing and curriculum: The interaction between semantic loss and pixel loss (and their weights) is only briefly adjusted for SigLIP2; a systematic study of dynamic weighting, curricula, or multi-objective optimization is absent.
- Stability and drift when unfreezing: Potential semantic drift or catastrophic forgetting when unfreezing the encoder (Stage 2) is not quantified; no diagnostics on feature-space alignment before/after training across layers.
- Scaling laws across latent capacity and model size: Only 32c vs 96c are explored; the optimal latent dimensionality, stride (e.g., 8 vs 16), and patch size under varying generator capacity and data regimes remain unclear.
- Compute and efficiency trade-offs: There are no measurements of training/inference time, memory footprint, throughput, or cost vs. performance comparisons against strong VAEs, especially for 96c latents and wide DDT heads.
- SNR shift rule generality: The timestep “shift factor” heuristic is validated on a few settings; its theoretical grounding, universality across latent designs, and interaction with different noise schedules/samplers are not established.
- Evaluation completeness: Generation is evaluated on GenEval and DPG-Bench only; missing metrics include human preference, FID/KID on diverse sets, aesthetic/portrait quality, text rendering OCR accuracy, and bias/fairness diagnostics.
- Editing evaluation granularity: Editing is assessed with a single automatic metric (EditingReward); per-category breakdowns, human studies, and consistency metrics (e.g., LPIPS to input in preserved areas) are not reported.
- Broader task coverage: The unified latent space is not evaluated on inpainting, outpainting, control-conditioned generation (depth/pose/edges), video generation/editing, 3D-aware synthesis, or cross-modal tasks beyond T2I/editing.
- Robustness and OOD behavior: Behavior under adversarial/contradictory prompts, rare concepts, heavy composition, or corrupted/noisy inputs is untested.
- Text–image alignment under instruction variety: The capacity to follow complex multi-step or long-horizon instructions, or to handle multilingual prompts, is not studied.
- LLM capability retention: The TransFusion design favors parameter efficiency; whether language modeling quality is preserved (or needed) and how multimodal alignment evolves is unassessed.
- Architectural alternatives to KL-regularized AE: Other regularizations (e.g., contrastive alignment across layers, Jacobian penalties, contractive AEs, InfoNCE with pixel supervision) and their effect on off-manifold behavior are untested.
- Decoder and latent topology: Whether the pixel decoder architecture (LDM-style) is optimal for semantic-rich latents is unexplored; alternative decoders (e.g., cross-scale, implicit decoders, or hypernetworks) may better exploit semantics.
- Manifold-aware training: No experiments with explicit manifold learning (e.g., local tangent regularization, geodesic consistency, or isometry-preserving objectives) to align training dynamics with the intrinsic data manifold.
- Skip/Head design ablation: The wide DDT head with long skip improves performance, but the contribution of the skip connection vs. width, and potential information leakage of noise, aren’t disentangled or theoretically grounded beyond intuition.
- Quantization vs. continuous latents: Whether vector-quantized variants (VQ) or hybrid continuous–discrete latents improve manifold regularization, compression, and generation quality is not evaluated.
- Continual learning and adaptability: How the encoder+AE adapts to new domains without forgetting (e.g., via LoRA, adapters, or replay) and whether semantic/pixel objectives remain compatible during continual updates is unknown.
- Safety and bias considerations: No analysis of bias amplification, content safety, or responsible deployment when adapting discriminative encoders into generative systems.
- Reproducibility and ablations: Key hyperparameters (e.g., KL weight, semantic/pixel loss weights, optimizer details) and ablations (e.g., removing cosine term, using perceptual losses) are not comprehensively presented; full code/weights availability is unclear.
- Upper bounds with stronger data: The method is trained on CC12M-LLaVA-NeXT and OmniEdit; how performance scales with larger or cleaner datasets (e.g., LAION variants, curated captioning, or high-quality editing corpora) is untested.
- Text rendering and fine-grained control: Claims of improved text rendering and face fidelity are qualitative; quantitative OCR metrics, face identity preservation scores, and attribute consistency measures are missing.
- Multi-resolution/variable-length latents: The design fixes a 16×16 grid; the benefits of multi-scale latents, variable strides, or hierarchical token layouts for handling diverse image sizes/aspect ratios are not explored.
- SigLIP2 joint objective: For SigLIP2, the modified semantic/pixel weighting is ad hoc; deeper study of how contrastive pretraining interacts with pixel reconstruction and the impact on downstream retrieval/zero-shot tasks is needed.
Practical Applications
Immediate Applications
The following applications can be deployed now by teams that adopt the paper’s PS-VAE framework and training recipes (S-VAE regularization + pixel–semantic reconstruction, Transfusion-style deep fusion, Wide DDT head, and the benchmark/evaluation pipeline).
- High-fidelity, instruction-based image editing in creative software
- Sector: software/creative tools (photo editing, design)
- Tools/products/workflows: integrate PS-VAE as an “Edit Engine” in apps (e.g., Photoshop-like) to perform text-driven edits that preserve fine details; pipeline: DINOv2 or SigLIP2 encoder → S-VAE (KL-regularized 96c latent) → PS-VAE (joint pixel–semantic reconstruction) → generator with Transfusion blocks + Wide DDT head; evaluate with EditingReward
- Assumptions/dependencies: access to OmniEdit training data; GPU inference; content safety filters
- Robust text-to-image generation for marketing and e-commerce assets
- Sector: advertising/e-commerce
- Tools/products/workflows: “Product Composer” that generates on-brand visuals with accurate geometry and textures (better GenEval scores); faster coverage reduces training costs and time-to-market
- Assumptions/dependencies: brand safety/approval pipelines; caption quality (CC12M-LLaVA-NeXT-like); 256×256 training with optional super-resolution
- Lower-cost training and faster convergence for generative model teams
- Sector: software/AI platforms
- Tools/products/workflows: replace VAE latents or RAE features with PS-VAE 96c latents to improve convergence and stability; adopt Wide DDT head to mitigate channel-width bottlenecks; use the timestep shift rule for SNR consistency across feature spaces
- Assumptions/dependencies: compatible backbone (e.g., Qwen), long-caption data, training infrastructure
- Synthetic data generation with structural integrity for CV research and product teams
- Sector: academia/software (vision), robotics simulation
- Tools/products/workflows: use PS-VAE generator to produce synthetic datasets with correct object geometry (validated via GenEval/detection) improving downstream detection/segmentation training
- Assumptions/dependencies: task-specific prompt design; synthetic-to-real validation; labeling pipelines
- Unified “understand-and-edit” workflows for multimodal assistants
- Sector: software (LVLMs, agents), education
- Tools/products/workflows: deploy a single encoder (DINOv2 or SigLIP2 with PS-VAE) that supports both perception and generation for assistants that analyze an image and apply precise, text-guided edits; Transfusion-style joint processing for text+image tokens
- Assumptions/dependencies: maintain language capability in the fusion backbone (if needed), guardrails for harmful content
- Mobile “describe-and-edit” photo features with compact latents
- Sector: consumer mobile
- Tools/products/workflows: implement on-device or hybrid inference using compact stride-16, 96-channel latents; enable natural-language editing while preserving faces/textures
- Assumptions/dependencies: model compression/distillation (potential 32c variant), hardware acceleration, super-res for final export
- Standardized evaluation pipeline adoption across teams
- Sector: academia/industry research
- Tools/products/workflows: adopt unified benchmarks (rFID/PSNR/SSIM/LPIPS, GenEval, DPG-Bench, EditingReward) to compare generative spaces; reproduce off-manifold diagnostics and ablations
- Assumptions/dependencies: dataset access (ImageNet-1K for reconstruction, CC12M-LLaVA-NeXT for T2I, OmniEdit for editing)
- Platform trust measures alongside improved editing fidelity
- Sector: policy/platform integrity
- Tools/products/workflows: integrate provenance/watermarking and detection pipelines at decode time, acknowledging higher-quality edits are now easier; establish “AI-edited” labeling workflows
- Assumptions/dependencies: watermark standardization, user consent flows, moderation guidelines
Long-Term Applications
These applications require further scaling, domain adaptation, higher-resolution training, or additional research (e.g., video/3D, safety, regulation).
- High-resolution (4K+) professional imaging and publishing
- Sector: creative industries/media
- Tools/products/workflows: scale PS-VAE channels/backbones (e.g., Qwen-3B+) and add super-resolution stages to deliver production-grade renders and print assets
- Assumptions/dependencies: large high-quality datasets, extended training budgets, perceptual upscalers
- Video generation and instruction-based video editing with semantic–pixel latents
- Sector: film/entertainment/social media
- Tools/products/workflows: extend PS-VAE to spatiotemporal encoders/decoders with temporal consistency losses for edit-while-you-describe workflows
- Assumptions/dependencies: video datasets, temporal models, memory-efficient training
- Domain-specific medical imaging synthesis and edit assistance
- Sector: healthcare
- Tools/products/workflows: specialized “Med-PS-VAE” trained on compliant datasets to generate/edit images for simulation, planning, and augmentation while preserving anatomy
- Assumptions/dependencies: clinical data access, rigorous validation, bias auditing, regulatory approvals and safety constraints
- Robotics simulation and digital twins with structurally faithful visuals
- Sector: robotics/autonomy/industrial IoT
- Tools/products/workflows: leverage off-manifold mitigation to generate reliable scenes/sensors for sim2real; couple with 3D/physics engines
- Assumptions/dependencies: 3D latent extensions, physically grounded datasets, domain encoders
- CAD/material design and precise texture authoring from instructions
- Sector: manufacturing/industrial design
- Tools/products/workflows: PS-VAE-powered material/finish editors that adhere to specified attributes (color/material/tone), feeding downstream CAD workflows
- Assumptions/dependencies: domain fine-tuning, integration with CAD/PDM systems
- Education-grade diagram and lab content generation with exact structural control
- Sector: education/edtech
- Tools/products/workflows: assistants that produce textbook-grade figures, lab setups, and step-by-step edits matching curricula
- Assumptions/dependencies: domain-specific corpora, pedagogy alignment, classroom safety policies
- Enterprise document and UI asset generation with accurate text rendering
- Sector: finance/enterprise software
- Tools/products/workflows: “DocSynth Edit” for instruction-driven updates to forms, dashboards, and infographics; leverage PS-VAE’s fine-grained control and prompt-following
- Assumptions/dependencies: OCR/semantic alignment layers, compliance rules, audit trails
- Standards and regulation for content provenance at the latent/decoder level
- Sector: policy/standards
- Tools/products/workflows: embed provenance signals at the pixel decoder; define cross-vendor watermark standards and detection APIs for editing pipelines
- Assumptions/dependencies: industry consortia, regulatory alignment, public trust mechanisms
- Universal unified vision encoder specification for multimodal foundation models
- Sector: AI research/software platforms
- Tools/products/workflows: formalize PS-VAE-like latent specifications (channels/stride/KL regularization/semantic losses) for interoperable perception–generation modules
- Assumptions/dependencies: community adoption, licensing of base encoders (DINOv2/SigLIP2)
- Low-power AR/VR content assistants and on-device generative imaging
- Sector: AR/VR/edge computing
- Tools/products/workflows: deploy distilled 32c-variant PS-VAE latents for wearable devices to generate or edit visuals on demand
- Assumptions/dependencies: hardware acceleration, memory budgets, efficient sampling strategies
Notes on Assumptions and Dependencies Across Applications
- Base encoders: availability and licensing of DINOv2 or SigLIP2; PS-VAE retains understanding ability after fine-tuning.
- Training data: long-caption data (e.g., CC12M-LLaVA-NeXT) and editing pairs (OmniEdit) materially affect prompt-following and edit quality.
- Resolution: current results trained at 256×256; many production cases need upscalers or high-res training.
- Architecture: Transfusion-style deep fusion with Wide DDT head consistently boosts performance in high-channel spaces.
- Safety: improved fidelity increases deepfake risk; watermarking, detection, and policy guardrails should be co-deployed.
- Compute: although PS-VAE converges faster than RAE and strong VAEs, scaling to high-res/video still requires significant compute.
- Evaluation: adopt rFID/PSNR/SSIM/LPIPS for reconstruction; GenEval/DPG-Bench for T2I; EditingReward for edits to quantify structural fidelity, semantic alignment, and instruction adherence.
Glossary
- ambient space: The higher-dimensional space that contains a lower-dimensional data manifold; learning within it can be harder and less efficient. "learning in the 8D ambient space results in slower convergence and a degradation in sample quality."
- autoregressive paradigm: A modeling approach that generates outputs sequentially, conditioned on previously generated elements. "Related work in the autoregressive paradigm~{ma2025unitok, song2025dualtoken, lin2025toklip, han2025tar} is discussed in the Supplementary Material, as it follows a fundamentally different modeling approach."
- Bagel-style models: A deep-fusion design that unfreezes both text and image branches to improve multimodal alignment. "Bagel-style models~{deng2025bagel}, which unfreeze both text and image branches to improve multimodal alignment;"
- causal mask: An attention mask that restricts tokens to attend only to prior positions, enforcing autoregressive behavior. "Text tokens use a causal mask, while noisy image latent uses full attention mask."
- CC12M-LLaVA-NeXT: A large-scale training dataset of images paired with long-form captions for vision-language tasks. "We utilize CC12M-LLaVA-NeXT~{cc12m, cc12m-llavanext} for training, which comprises 10.9 million images with detailed long-form captions~{liu2024llavanext}."
- classifier-free guidance: A sampling technique that adjusts generation by interpolating conditional and unconditional predictions without an explicit classifier. "During inference, we use 50-step Euler sampling with a timestep shift of 3 and a classifier-free guidance scale of 6.5."
- column-orthonormal mapping: A linear mapping whose columns are orthonormal, preserving lengths when projecting between spaces. "where is a column-orthonormal mapping ()."
- contrastive learning: A representation learning paradigm that pulls semantically similar pairs together and pushes dissimilar pairs apart. "Representation encoders trained via self-supervision~\citep{dino,dinov2,dinov3,moco,mae} or contrastive learning~\citep{clip,siglipv2,perception-encoder} have established themselves as the cornerstone of visual understanding."
- cosine similarity loss: A loss that measures angular similarity between vectors, encouraging directionally aligned features. "which combines an loss and a cosine similarity loss on features"
- Deep-fusion architecture: A multimodal generation design that fuses image and text tokens deeply within a shared backbone. "For these reasons, we adopt a deep-fusion architecture as our generation paradigm."
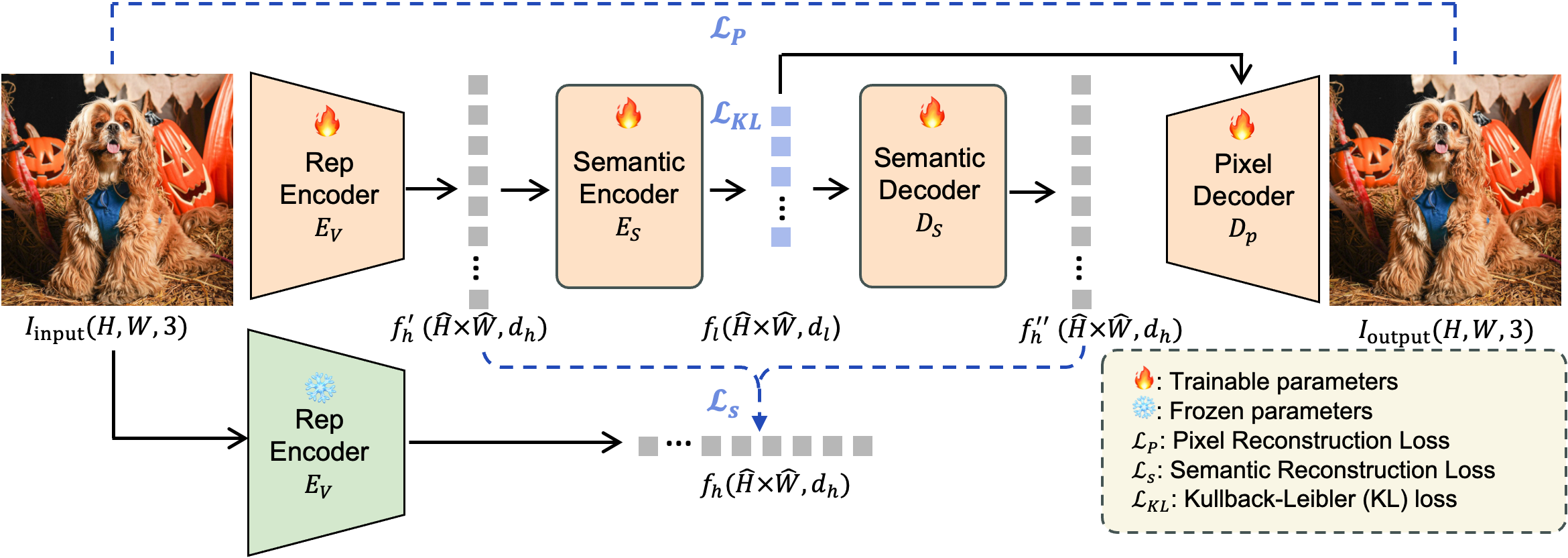
- detach operation: A computational graph operation that stops gradient flow through a tensor. "reconstructs the output image $I_{\mathrm{output}$ from the detached semantic latent via the pixel reconstruction loss"
- DiT architecture: A diffusion transformer architecture tailored to handle image-like tokens for generation. "By redesigning the DiT architecture to handle high-dimensional features, it successfully enables generation within the representation space"
- diffusion model: A generative model that learns to reverse a noise-adding process to produce data samples. "Training on such a redundant high-dimensional space makes the diffusion model prone to producing off-manifold latents"
- DINOv2: A self-supervised vision encoder producing semantic-rich features. "Specifically, we instantiate PS-VAE with a 96-channel latent design based on DINOv2~\citep{dinov2}."
- DPG-Bench: A benchmark that evaluates text-to-image alignment using a vision–language judge. "DPG-Bench~\citep{dpg}: 83.2 83.6"
- EditingReward: An automatic metric for evaluating instruction-based image editing quality and adherence. "Results are evaluated using EditingReward~{wu2025editreward}, a state-of-the-art image editing scoring model"
- EMA (Exponential Moving Average): A training stabilization technique that maintains a smoothed version of model parameters. "and apply EMA with a decay of 0.9999."
- Euler sampling: A numerical integration method used to discretize the reverse diffusion process during generation. "During inference, we use 50-step Euler sampling"
- Flux-VAE: A VAE variant with specific stride and patch size used as a reference in benchmarks. "Flux-VAE~{flux2024} (16-channel, stride-8, patch size 2)"
- full attention mask: An attention configuration allowing all tokens to attend to each other. "Text tokens use a causal mask, while noisy image latent uses full attention mask."
- generative latents: Latent representations used as the target space for generative models. "adopt high-dimensional features from representation encoders as generative latents."
- GenEval: An object-detection-based benchmark emphasizing structure and texture fidelity in text-to-image outputs. "GenEval~\citep{geneval}: 75.8 76.6"
- ImageNet-1K: A standard image classification dataset often used for training or evaluation of vision models. "we train our reconstruction models exclusively on ImageNet-1K~{russakovsky2015imagenet}"
- intrinsic manifold: The true low-dimensional structure underlying high-dimensional observations. "To rigorously analyze the difficulty of learning a low-dimensional intrinsic manifold embedded in a high-dimensional space"
- instruction-based image editing: Editing images according to natural-language instructions while preserving input content. "on the challenging instruction-based image editing task—requiring both accurate image understanding and faithful instruction execution—PS-VAE delivers a substantial improvement"
- isometric mapping: A mapping that preserves distances between points, used to embed low-dimensional data into higher dimensions. "embed it into via a linear isometric mapping "
- KL-regularized latent space: A latent space constrained via KL divergence to encourage compactness and stable generation. "we propose S-VAE, which maps the frozen representation features into a compact, KL-regularized latent space~\citep{rombach2022high} via a semantic autoencoder."
- Kullback–Leibler divergence: A measure of difference between probability distributions, used to regularize VAEs. "while the latent is further regularized by a Kullback--Leibler divergence loss $\mathcal{L}_{\mathrm{KL}$ following~{rombach2022high}."
- Latent Diffusion Models (LDMs): Generative models that operate in a lower-dimensional latent space rather than pixel space. "Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces"
- Logit-Normal distribution: A distribution over [0,1] obtained by applying the logistic function to a normal variable, used for timestep sampling. "where is sampled from a Logit-Normal distribution~{esser2024scaling,rae}."
- LPIPS: A perceptual similarity metric for image reconstruction quality. "We evaluate performance using rFID, SSIM, PSNR, and LPIPS on the ImageNet-1K validation set."
- LlamaFusion: A fusion architecture that freezes the language branch and adds parallel image blocks. "LlamaFusion~{shi2024lmfusion}, which freezes all language blocks and adds parallel image blocks with identical architecture;"
- manifold discovery: The task of identifying the low-dimensional data structure within high-dimensional observations. "This imposes a significant burden of manifold discovery—identifying the sparse data subspace within the vast high-dimensional ambient space"
- MAR-VAE: A baseline VAE used for comparison in reconstruction and generation tasks. "Compared to vanilla VAEs such as MAR-VAE~{li2024autoregressive}, this architecture achieves state-of-the-art reconstruction quality"
- MLP projection layer: A multilayer perceptron used to change feature dimensionality. "and an MLP projection layer for dimensionality adjustment."
- nearest-neighbor distance: A metric for evaluating sample proximity to the data manifold. "We measure the mean nearest-neighbor distance of the top 5\% tail samples"
- off-manifold generation: Producing latents outside the valid data manifold, leading to decoding artifacts. "off-manifold generation arising from unconstrained feature spaces"
- off-manifold latents: Latent features that lie outside the learned manifold, causing unreliable decoding. "making diffusion models prone to off-manifold latents that lead to inaccurate object structures;"
- OmniEdit dataset: A large-scale dataset of image–editing pairs across diverse editing categories. "We utilize the OmniEdit dataset~{wei2024omniedit}, which"
- OOD (out-of-distribution): Data points that do not conform to the training distribution. "We define ``off-manifold'' latents as features falling into undefined/OOD regions where image decoding becomes unreliable."
- pixel decoder: The network component that reconstructs images from latent representations. "we additionally train a pixel decoder that reconstructs the output image"
- pixel-level reconstruction: Training objective to faithfully recover pixel values from latent codes. "Modern Latent Diffusion Models (LDMs) typically operate in low-level Variational Autoencoder (VAE) latent spaces that are primarily optimized for pixel-level reconstruction."
- PSNR (Peak Signal-to-Noise Ratio): A reconstruction quality metric measuring signal fidelity relative to noise. "PSNR (26.18 28.79)"
- PS-VAE (Pixel–Semantic VAE): A VAE that jointly enforces semantic and pixel-level reconstruction to produce compact, detail-preserving latents. "Finally, \textcolor{Red}{PS-VAE} further augments the semantic latent space with pixel-level reconstruction"
- rFID: A reconstruction Fréchet Inception Distance variant assessing perceptual fidelity. "improving rFID (0.534 0.203)"
- RAE: A representation-aware diffusion approach operating directly on high-dimensional encoder features. "Recent work, RAE~\citep{rae}, offers a pioneering answer to this question."
- representation-alignment objectives: Losses that align VAE latents with encoder representations to impose semantic structure. "aligning standard VAE latents with representation encoders through representation-alignment objectives, treating the encoder as a soft semantic constraint"
- representation encoders: Pretrained models that map images to semantic-rich features for understanding tasks. "Representation encoders trained via self-supervision~\citep{dino,dinov2,dinov3,moco,mae} or contrastive learning~\citep{clip,siglipv2,perception-encoder} have established themselves as the cornerstone of visual understanding."
- semantic autoencoder: An autoencoder trained to compress and reconstruct high-level semantic features. "we propose S-VAE, which maps the frozen representation features into a compact, KL-regularized latent space~\citep{rombach2022high} via a semantic autoencoder."
- semantic reconstruction loss: A feature-level objective combining L2 and cosine losses to preserve semantics. "Both the semantic encoder and decoder are optimized with a semantic reconstruction loss "
- S-VAE (Semantic VAE): A VAE that compresses representation-encoder features into a compact, KL-regularized latent space. "we propose S-VAE, which maps the frozen representation features into a compact, KL-regularized latent space~\citep{rombach2022high} via a semantic autoencoder."
- self-supervised learning: Training without explicit labels by predicting withheld or augmented information. "These powerful encoders are typically obtained through two major paradigms: self-supervised learning~{simclr, moco, byol, dino, dinov2, dinov3}"
- SigLIP2: A vision encoder trained with language-image pretraining, used as a unified encoder for understanding and generation. "We also validate our method on SigLIP2~{siglipv2}, which is used in Bagel~{deng2025bagel}, observing consistent generation behavior."
- SNR (Signal-to-noise ratio): A measure of latent-to-noise balance affecting diffusion training and sampling dynamics. "Variations in patch size and channel dimensionality along the sequence length alter the signal-to-noise ratio (SNR) during interpolation between noise and latents."
- SSIM (Structural Similarity Index): A metric assessing structural fidelity of reconstructed images. "SSIM (0.715 0.817)."
- stride: The spatial downsampling factor of the encoder/decoder latent grid. "Flux-VAE~{flux2024} (16-channel, stride-8, patch size 2)"
- timestep shift: A reparameterization of diffusion timestep to equalize SNR across feature spaces. "we apply a shifted timestep "
- Transfusion: A fusion design that processes image and text tokens jointly in shared transformer blocks. "Transfusion~{zhou2025transfusion}, which processes image and text tokens jointly using fully shared transformer blocks."
- Text-to-Image (T2I): Generating images conditioned on textual prompts. "Leveraging this representation, we design a unified Text-to-Image (T2I) and image editing model."
- Variational Autoencoder (VAE): A generative model that learns a probabilistic latent space with a reconstruction and KL objective. "Variational Autoencoders (VAEs)~\citep{kingma2013auto} are fundamental components of Latent Diffusion Models (LDMs)~\citep{rombach2022high}, primarily serving to reduce the computational cost of high-resolution generation."
- velocity estimators: Denoising targets predicting the optimal reverse diffusion velocity for intrinsic and embedded processes. "We denote the optimal velocity estimators for the intrinsic and embedded processes as and , respectively."
- VAVAE: A VAE baseline used to compare fusion architectures and generation quality. "We evaluate the three deep-fusion architectures using VAVAE~{li2024autoregressive}"
- vision–LLM: A multimodal model that jointly processes images and text, used as an automatic judge. "Conversely, DPG-Bench employs a vision–LLM as a judge, prioritizing high-level alignment over fine-grained details."
- wide DDT head: A widened diffusion transformer head with long skip connections that improves performance in high-channel latent spaces. "we incorporate the wide DDT head~{wang2025ddt} from RAE~{rae}, which enhances generation quality in high-channel feature spaces(as we analyzed in \Cref{sec:wide_head})."
Collections
Sign up for free to add this paper to one or more collections.

