- The paper introduces MF-RAE to integrate Representation Autoencoders with MeanFlow transformers for efficient one-step image generation, reducing training resources by 83%.
- The methodology employs Consistency Mid-Training and MeanFlow Distillation to achieve a 1-step FID score of 2.03 on ImageNet 256, enhancing both quality and scalability.
- The approach minimizes computational costs and hyperparameter complexity, paving the way for future developments in transformer-based generative models.
Introduction
The paper "MeanFlow Transformers with Representation Autoencoders" (2511.13019) addresses the inefficiencies in training and generation constraints faced by MeanFlow (MF), a diffusion-motivated generative model, especially when dealing with high-dimensional data. By integrating the latent space of a Representation Autoencoder (RAE) and employing a pre-trained vision encoder, significant improvements in efficiency, stability, and quality of generative models are achieved. These novel approaches overcome the traditional bottlenecks in slow sampling and computational intensity.
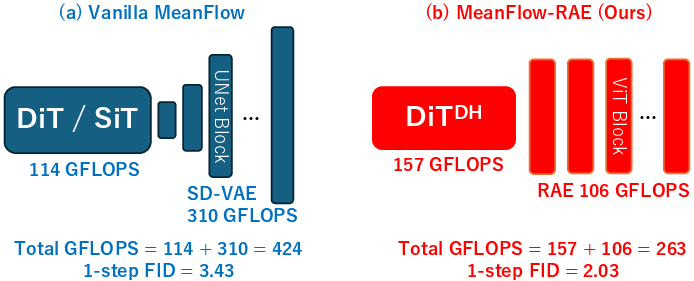
Figure 1: Overview of our method's advantages on ImageNet~256.
Training and Sampling Efficiencies
The study focuses on stabilizing and accelerating MF training within the RAE latent space by adopting trajectory-aware initializations through Consistency Mid-Training (CMT) and a MeanFlow Distillation (MFD) approach. This methodological shift allows for the removal of complex guidance hyperparameters typically required in class-conditional generation and simplifies the training configuration. The paper reports a remarkable reduction in training resources, requiring less than 100 H100 GPU-days compared to over 600 GPU-days with vanilla MF setups.
Empirical evidence demonstrates the superiority of MF-RAE in terms of sample quality and efficiency. The model achieved a 1-step Fréchet Inception Distance (FID) score of 2.03 on ImageNet~256, significantly outperforming vanilla MF's 3.43, while reducing both sampling GFLOPS by 38% and total training cost by 83%. Scaling to ImageNet~512 shows MF-RAE achieving a competitive 1-step FID of 3.23 with the lowest GFLOPS among all baselines, signifying robust model scalability.

Figure 2: ImageNet~256 MF-RAE 1-step samples on class 437: beacon, lighthouse, beacon light, pharos.

Figure 3: ImageNet~256 MF-RAE 1-step samples on classes 288 and 290: leopard and snow leopard.
Theoretical and Practical Implications
The research lays foundational theory in resolving the bias-variance trade-off between using a pre-trained flow matching teacher and one-point velocity estimation in MF. This theoretical insight directs a two-stage procedure, first leveraging MFD to achieve swift convergence by reducing variance, and secondly, utilizing MFT for further fine-tuning to reduce loss bias. This practical advancement along with an architecture agnostic view posits MF-RAE as a promising approach for future transformer-based flow models.

Figure 4: ImageNet~256 MF-RAE 1-step samples on classes 13, 14, 94, and 134: snowbird, indigo bird, hummingbird, and crane bird.

Figure 5: ImageNet~256 MF-RAE 1-step samples for various dogs.
Conclusion
The innovation brought forth by MF-RAE significantly diminishes the computational burden of image generation, enabling efficient one-step generation processes with fewer hyperparameters. The precise utilization of RAE latent spaces coupled with strategic training alterations firmly establishes MF-RAE as a superior model in generative tasks. Looking forward, the adaptability of MF-RAE with potential integration of future training algorithms bodes well for its application in advanced AI systems, securely positioning it to accommodate evolving architectural advancements in transformer-based flow map models.

Figure 6: ImageNet~256 MF-RAE 1-step samples for class 933: cheeseburger.

Figure 7: ImageNet~256 MF-RAE 1-step samples for class 959: carbonara.

Figure 8: ImageNet~256 MF-RAE 1-step samples for class 947: mushroom.

