- The paper introduces a teacher-free visual skill memory framework that evolves spatial heatmaps, visual exemplars, and symbolic text skills from interaction data.
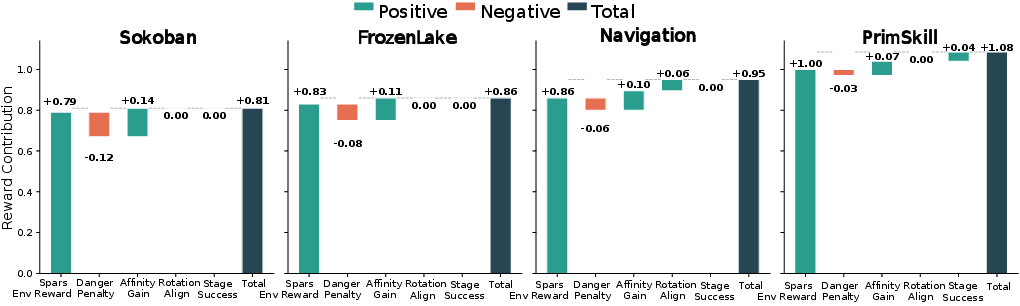
- The methodology employs dense reward shaping via affinity gains and danger penalties, accelerating convergence and outperforming larger VLM models.
- Empirical results demonstrate high spatial generalization and learning efficiency across benchmarks such as Sokoban, 3D navigation, and robotic manipulation.
AtlasVA: Self-Evolving Visual Skill Memory for Teacher-Free VLM Agents
Motivation and Background
AtlasVA addresses critical deficiencies in vision-LLM (VLM) agents tasked with spatially-intensive environments. Existing RL frameworks typically compress agent memory into textual form and rely on external LLM supervisors to refine, summarize, and provide sparse feedback. This setup suffers from inherent modality mismatch: complex spatial topologies, geometric constraints, and local hazards are lost in lossy language translation, which severely impedes credit assignment and spatial reasoning. Further, dependence on proprietary teacher models increases computational costs and impedes autonomy.
AtlasVA proposes a teacher-free Visual Skill Memory (VSM) hierarchy, maintaining spatial heatmaps, visual exemplars, and symbolic textual rules. By evolving danger and affinity atlases directly from interaction statistics and grid heuristics, and synthesizing these into dense reward shaping, the system closes the loop between perception, memory, and policy optimization natively in the agent's visual modality.
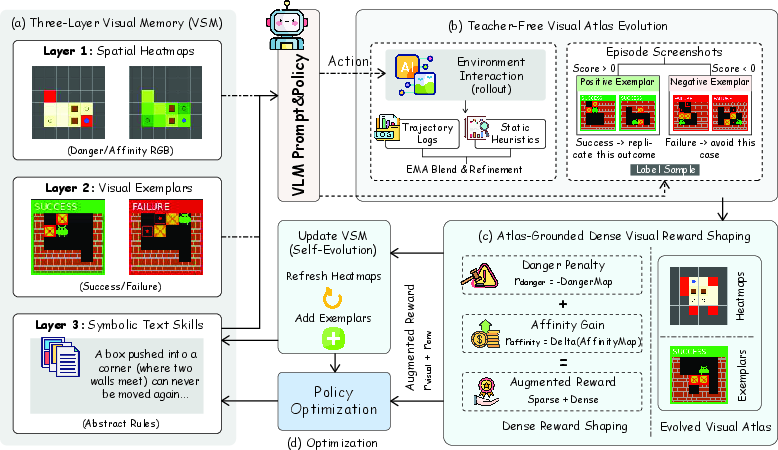
Figure 1: AtlasVA architecture overview: three-layer VSM prompting, teacher-free evolution via rollouts, formulation of reward shaping, and closed optimization loop.
Architecture and Algorithmic Innovations
Visual Skill Memory (VSM) Hierarchy
AtlasVA's core is its three-layer Visual Skill Memory:
- Layer 1: Spatial Heatmaps: Danger and affinity maps, rendered as RGB heatmaps and injected as auxiliary image tokens, establish coordinate-localized priors. This circumvents the modality bottleneck by directly aligning experience with the VLM's visual encoder.
- Layer 2: Visual Exemplars: A capped batch of episodic keyframes (success/failure) is maintained via feature retrieval (DINOv2 cosine similarity), offering highly relevant context for zero-shot spatial matching.
- Layer 3: Symbolic Text Skills: Injected strategic heuristics, distilled directly from environment rulebooks, provide high-level cognitive scaffolding without reliance on external LLM generation.
Prompt injection is structured, with each layer anchored at fixed positions in the multimodal prompt. The deployment policy relies exclusively on these visual and textual cues for inference, ensuring zero information leakage.
Teacher-Free Atlas Evolution
Rather than teacher-driven summarization, AtlasVA bootstraps spatial priors autonomously from raw environment interactions:
Atlas-Grounded Reward Shaping
Sparse terminal environment rewards (∈{0,1}) are augmented via potential-based shaping:
Empirical Results
AtlasVA demonstrates exceptional performance across benchmarks: Sokoban, FrozenLake, 3D navigation, and robotic manipulation (PrimitiveSkill). Despite a compact base (3B parameters), AtlasVA surpasses larger proprietary VLMs (e.g., GPT-5, o3, Gemini) and prior strong open-source models.
- Overall Success Rate: 0.93 (AtlasVA) vs. 0.69 (GPT-5), 0.78 (VAGEN), 0.55/0.14 (Qwen2.5-VL-72B/3B).
- Spatial Generalization: AtlasVA achieves perfect scores (1.00) on all PrimitiveSkill tasks, robustly generalizes to unseen layouts via dynamic heuristic priors, and consistently outperforms in scenarios requiring explicit geometric planning and manipulation.
- Learning Efficiency: AtlasVA converges dramatically faster and more stably than text-centric baselines, validated by ablation studies.
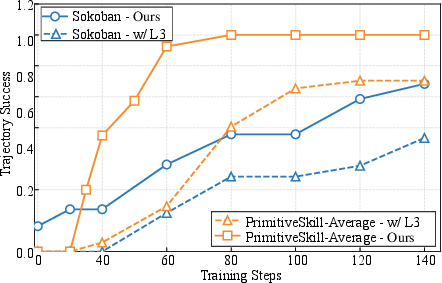
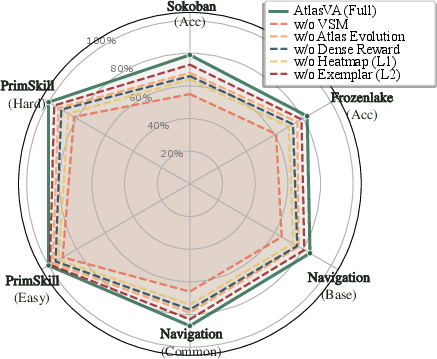
Figure 4: Left—AtlasVA achieves superior learning efficiency and convergence; Right—Component ablation reveals criticality of visual memory, atlas evolution, and reward shaping.
Ablation and Diagnostic Analyses
Component-wise ablations confirm all core elements are essential:
- Visual Skill Memory: Removing VSM results in severe regression; text-only memory fails to encode spatial constraints.
- Atlas Evolution: Disabling trajectory-driven updates (EMAs) restricts the agent to static heuristics—major degradation.
- Dense Reward Shaping: Sparse-only feedback leads to local optima and poor performance in long-horizon tasks.
Qualitative heatmap evolution shows rapid extraction of geometric priors, with danger zones and affinity paths emerging organically from environment interaction; exemplar pool capacity correlates directly with initial validation success spikes.
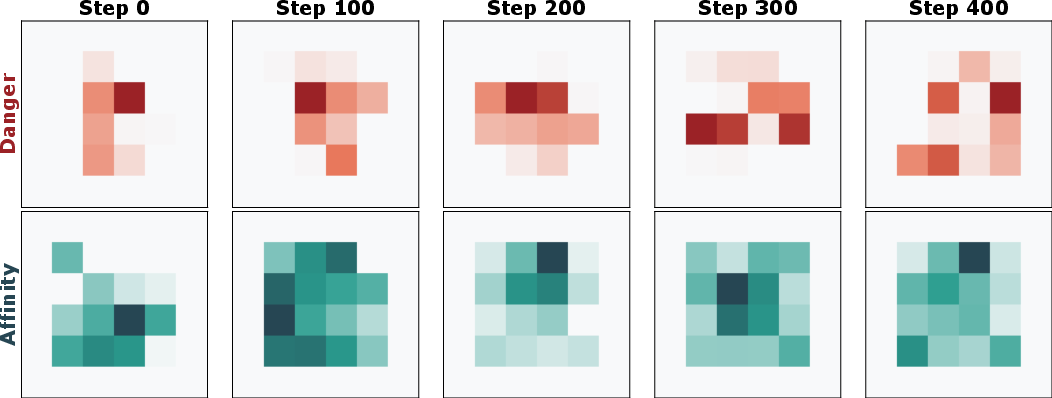
Figure 5: Heatmap evolution: Danger (red) and Affinity (green) maps progressively encode structural hazards and sub-goal paths.
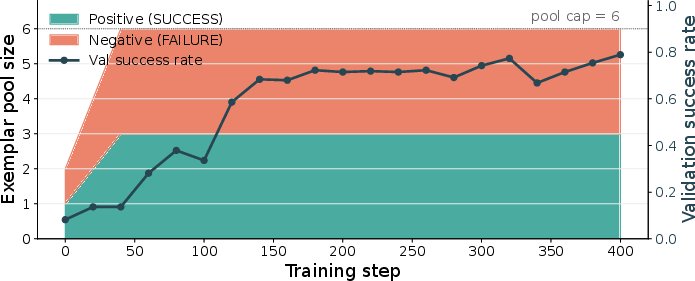
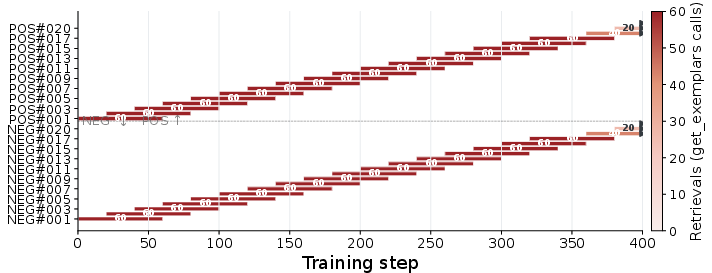
Figure 6: Exemplar pool: Visual context accumulation aligns with sharp rise in validation success.
Practical and Theoretical Implications
AtlasVA redefines memory-augmented RL for visual agents by eliminating the need for external teacher models and text-only heuristics. The closed-loop perception-optimization scheme, grounded entirely in visual modalities, produces dense, spatially precise feedback and significantly compresses sample complexity. Generalization to unseen layouts and robustness in continuous spatial domains emerge naturally from this visual memory paradigm.
There is clear evidence that visual skill memory and reward shaping can enable smaller agents to outperform much larger language-centric competitors, challenging current scaling laws and inviting novel architectures for embodied AI, GUI agents, and robotics.

Figure 7: Rollout comparison: AtlasVA (3B) versus Qwen2.5-VL-72B, visual memory enables robust spatial reasoning and successful completion of complex tasks.
Limitations and Future Directions
Current memory evolution assumes availability of privileged grid state during training and projects 3D manipulation tasks onto 2.5D visual priors. Extending to fully occluded, ego-centric 3D robotics requires perturbation-resistant spatial abstraction and tighter integration with continuous pixel-level RL. Future research may target autonomous world model evolution, unsupervised spatial skill distillation, and scaling visual memory for open-ended embodied environments.
Conclusion
AtlasVA delivers a teacher-free, visually grounded memory framework for VLM agents, enabling sample-efficient spatial reasoning and robust policy optimization. The system reliably outperforms larger models, leveraging native multimodal perception and dense reward feedback. This approach establishes new directions for efficient, generalizable AI agents in spatially complex tasks (2605.17933).