- The paper proposes SNLP, a method that uses structured surrogate Newton corrections to replace sequential layer execution with parallel updates.
- It introduces a SNLP-aware regularization framework and chunkwise layer fusion to stabilize and accelerate Transformer model inference.
- Empirical results on Nanochat models show perplexity improvements and up to 2.3× speedup, though challenges remain in scaling to larger models.
Structured Newton Layer Parallelism: Layer-Parallel Inference via Structured Newton Corrections
Motivation and Problem Statement
Contemporary autoregressive LLMs execute Transformer layers sequentially during inference, which introduces a significant depthwise latency bottleneck. Standard variants of model parallelism—tensor, pipeline, and kernel fusion—are incapable of eliminating this sequential dependency because the computation graph inherently enforces strict layerwise ordering for a fixed token context. This bottleneck intensifies as models scale in depth and is orthogonal to token-level optimizations (e.g., batching, KV caching, speculative decoding). The paper "SNLP: Layer-Parallel Inference via Structured Newton Corrections" (2605.17842) proposes to relax the sequential dependency along the depth axis, thus exposing new opportunities for parallelization in large Transformer models.
The central insight of SNLP is to reinterpret the full set of hidden states across all layers as a solution to a nonlinear residual equation:
Gl(h)=hl−fl(hl−1),∀l∈{1,…,L}
This transforms the classical left-to-right, layer-by-layer evaluation into a system whereby all layer outputs jointly comprise the zero set of a global residual—an analogy to solving nonlinear recurrences with Newton's method. The exact Newton formulation directly parallels DEER-style algorithms used in scan-based sequence parallelization, although directly materializing or even approximating the required Jacobian blocks is infeasible for high-dimensional Transformer layers.
SNLP: Structured Surrogate Newton Methods
SNLP circumvents the bottleneck of exact Jacobian computation by replacing true Jacobian matrices with architecture-induced structured surrogates. The framework splits the model into a prefix (evaluated sequentially for stability) and a suffix (processed in parallel). The generic update at solver iteration k is:
hl(k+1)=hl(k)+Al(k)(hl−1(k+1)−hl−1(k))
where Al(k) is a structured surrogate of the local layer Jacobian.
- Identity Newton (IDN): For standard residual architectures, Al(k)=I, yielding a trivial yet effective additive correction akin to a prefix-sum.
- Diagonal Newton (DiagN): Approximates the Jacobian with its diagonal, connecting to quasi-Newton recurrences; estimation via Hutchinson probes is possible but brings overhead and instability.
- HC Newton (HCN): For HC/mHC-style layers, the residual mixing matrix serves as the surrogate, introducing richer but still cheap cross-layer coupling.
The architectural and theoretical underpinnings are best illustrated in the main schematic.
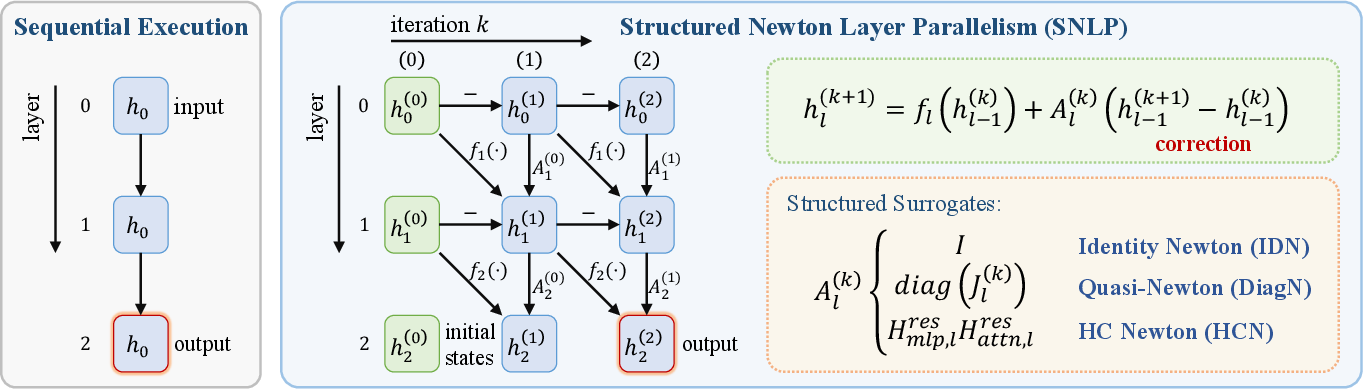
Figure 1: Structured Newton Layer Parallelism (SNLP) replaces sequential layer execution with iterative layer-parallel updates; updates leverage the block function fl and structured Newton surrogates Al(k).
SNLP-Aware Regularization: Training for Layer-Parallel Compatibility
Off-the-shelf sequential models exhibit dynamics incompatible with simple surrogates. To bridge this gap, SNLP introduces a regularizer during training: applying one or more SNLP iterations over layer suffixes and penalizing their difference from the sequential forward pass. This objective encourages the model to learn transformations with branch Jacobians well-approximated by the chosen surrogate, making finite-iteration SNLP not only stable but also accurate. Regularization pressure—especially on the non-residual branches of Transformer layers—implicitly enforces Lipschitz continuity and capacity partitioning: initial layers handle more of the complex, input-dependent processing, while deeper layers stabilize into correctable feature refinements.
Inference: Chunkwise Layer Fusion and Parallel Schemes
Beyond algorithmic speedup from surrogate Newton correction, SNLP further increases parallel execution via chunkwise layer fusion. Here, blocks of layers are grouped into wide, hardware-friendly fused operations, reducing the number of sequential steps to only that required for lightweight recurrence corrections. Chunking exposes a tradeoff: coarser chunks yield better throughput but increase bias due to more aggressive approximation of the sequential computation. In combination, SNLP and chunkwise execution realize practical wall-clock acceleration.
Empirical Results
The SNLP framework is evaluated on Nanochat-scale Transformers, spanning 0.5B and 3B parameters. Key empirical findings include:
- Perplexity Reductions: SNLP regularization reduces sequential PPL by 4.7%–23.4% against baselines.
- Quality-Throughput Tradeoffs: On a 0.5B Nanochat model, SNLP configurations achieve up to 2.3× speedup with a simultaneous 6.1% PPL improvement.
- Solver-Induced Inference Bias: Practical SNLP (with surrogates, fusion, and finite iterations) forms an inference routine distinct from strict sequential evaluation. It sometimes yields lower PPL, not merely matching sequential computation but outperforming it for some parameterizations.
- Model Sensitivity: Off-the-shelf pretrained models see little benefit without SNLP-aware finetuning; their dynamics are not compatible with the surrogate corrections.
- Scaling Limitations: At 3B+ scale, SNLP’s wall-clock speed advantages are not currently realized, reaching only numerical improvements but not practical acceleration without custom kernel or hardware support.
Analysis of Bias, Variance, and Depth Coupling
SNLP’s effectiveness is theoretically dissected on multiple axes:
- Variance Reduction: Surrogate corrections (especially IDN) remove compounding variance induced by evaluating deep non-residual branches on successively accumulated hidden states.
- Capacity Partitioning: Regularized models partition input-dependent computation toward prefix layers, making the suffix more stable and amenable to parallel correction.
- Bias/Approximation: Finite-iteration, surrogate-based SNLP introduces a bias distinct from the sequential path. When regularization minimizes sensitivity, this bias is small and outweighed by variance reduction.
Implications and Future Directions
The results carry both practical and theoretical implications for efficient LLM inference:
- Inference-Time Solver Design: The solver-induced bias concept suggests that inference is not solely a matter of accurately replicating training-time computation but can benefit from algorithmic reinterpretation.
- Training/Inference Co-Design: Model architectures and training procedures must be explicitly crafted for compatibility with highly parallel inference algorithms such as SNLP.
- Layer/Depth Parallelism: Achieving throughput gains on large models will require innovations not only in algorithmic scheduling but also in runtime, compiler, or hardware design (e.g., fused kernels, compute-in-memory).
- Model Scalability: Extending SNLP to larger models or off-the-shelf checkpoints may hinge on new regularizers, architecture modifications, or hybrid, dynamically-tuned surrogate choice.
Conclusion
This work demonstrates that strict layerwise sequential dependence in deep Transformer-based LLMs is not essential for high-quality inference. By reframing inference as structured surrogate Newton root-finding problems and regularizing models to be compatible with cheap, architecture-induced corrections, SNLP enables significant parallelization of layer execution. When fused with chunkwise grouping and hardware-aware strategies, this approach achieves substantial throughput improvements with frequent perplexity gains. However, universal applicability awaits deeper co-design of training objectives, model architectures, and inference runtimes. SNLP reframes low-level model execution as a tunable algorithmic degree of freedom in next-generation LLM systems.

