- The paper introduces a novel multilevel layer-parallel training strategy for transformers, reducing memory use and accelerating convergence.
- It leverages neural ODE formulations with MGRIT algorithms to enable simultaneous forward and backward propagation across layers.
- Experimental results show comparable accuracy to serial training while delivering significant speedups on multi-GPU setups.
Introduction
The paper "Layer-Parallel Training for Transformers" (2601.09026) explores an innovative methodology for training transformer models using a multilevel, layer-parallel approach. By formulating transformers as neural ODEs, the study employs a multilevel parallel-in-time (PiT) algorithm to enhance parallel acceleration during training, particularly focusing on the layer dimension. This approach is especially advantageous when dealing with deep networks characteristic of large foundational models. However, layer-parallel training introduces gradient biases, impacting convergence near minima. The paper proposes strategies to detect and address these biases while ensuring accelerated parallel training with accuracy equivalent to serial pre-training.
Methodology
The research introduces an MGRIT-based strategy exploiting parallelism over the layer dimension, targeting the challenge of inherent serialization in transformer models. Leveraging the formulation of transformers as neural ODEs, the study utilizes PiT methods for simultaneous forward and backward propagation across all layers. The layer-parallel approach, demonstrated with models like BERT, GPT2, and ViT, reveals substantial speedups and reduced memory overhead on multi-GPU setups.
The neural ODE formulation allows viewing the depth of networks as a time dimension, facilitating the use of MGRIT algorithms to handle discrete ODE operations iteratively across layers (Figure 1). This approach enhances potential speedup as network depth increases and introduces adaptive control mechanisms to manage inexact gradient evaluations effectively.
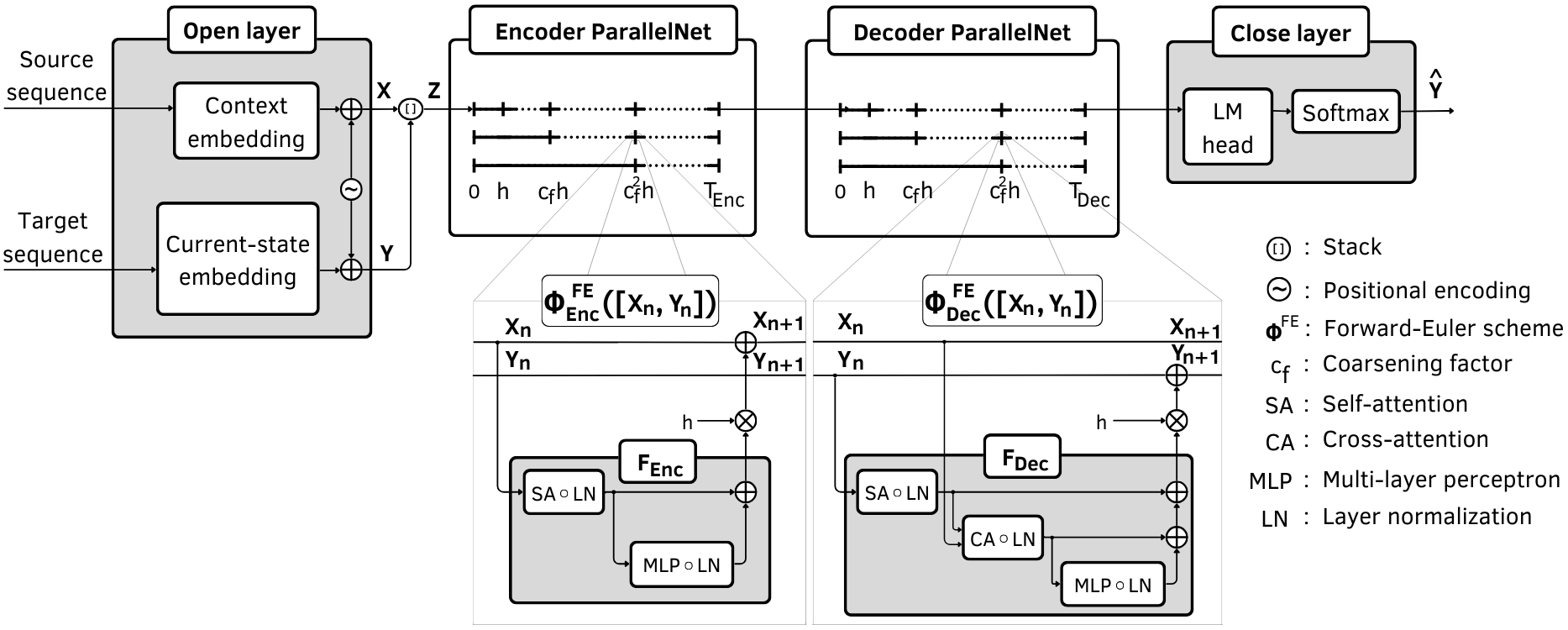
Figure 1: Layer-parallel transformer. The ParallelNet contains a time grid hierarchy with the coarsening rate denoted by cf. Experiments use a fine level time-step of h=1.
Experimental Results
Extensive numerical experiments confirm the efficacy of layer-parallel training in maintaining training accuracy despite the use of inexact gradients. Long-term validation accuracy for tasks such as morphological classification (MC) and machine translation (MT) demonstrates comparability to traditional sequential training methods (Figure 2).
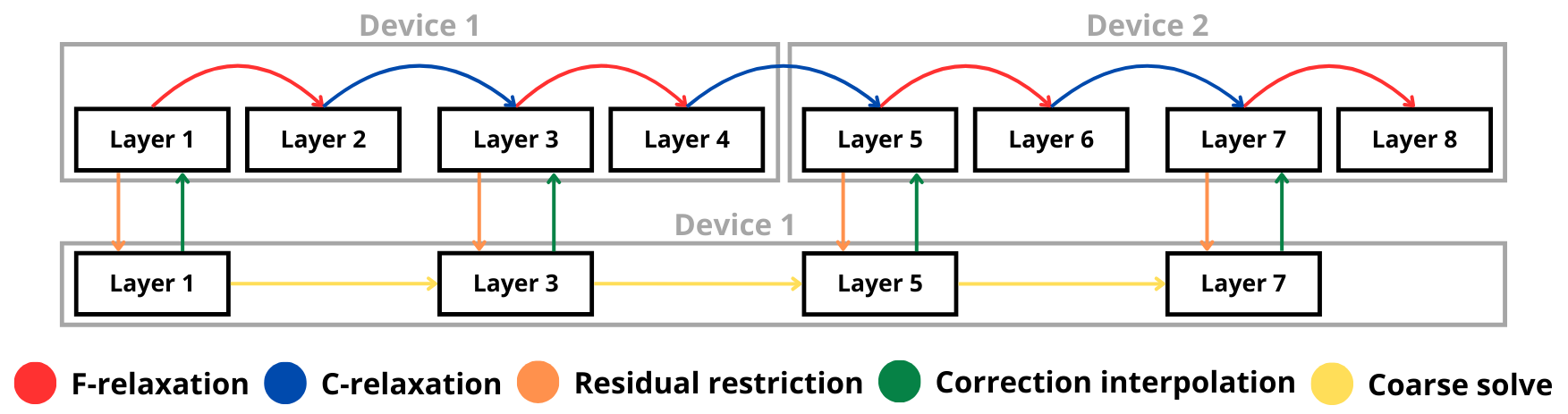
Figure 2: Two-level MGRIT pseudocode (left), MGRIT diagram with cf=2, L=2 on 2 devices (right).
The study further investigates the statistical biases of gradient error in inexact evaluations, suggesting a theoretical basis for switching to precise solutions as the optimization approaches minima. Adaptive strategies showcased in the convergence factor plots confirm the mitigation of divergence issues by switching from parallel to serial execution, ensuring high-performance outcomes without compromising training stability.
The scalability analysis reveals significant parallel speedups and improved memory distribution across GPUs. The results highlight the compatibility of layer-parallelism with other parallelization techniques like data parallelism and tensor parallelism, underscoring its potential to handle large memory demands and train extremely deep transformer architectures efficiently.
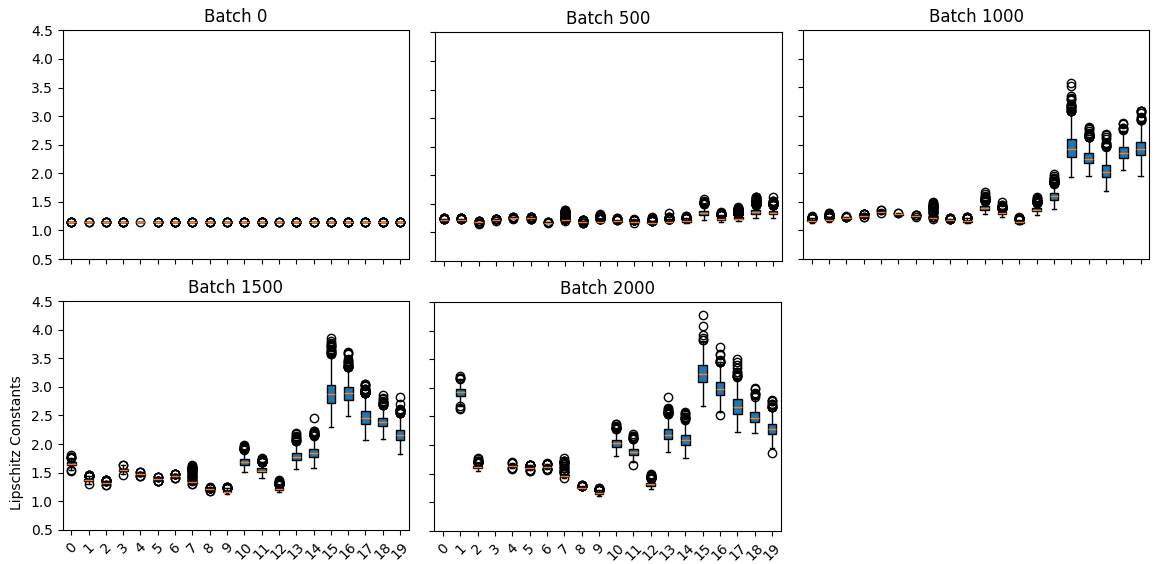
Figure 3: Plots illustrating the Lipschitz constants of each layer as one trains a GPT2-decoder network. Note that the last few layers are the first to change, followed by the initial transformer layer.
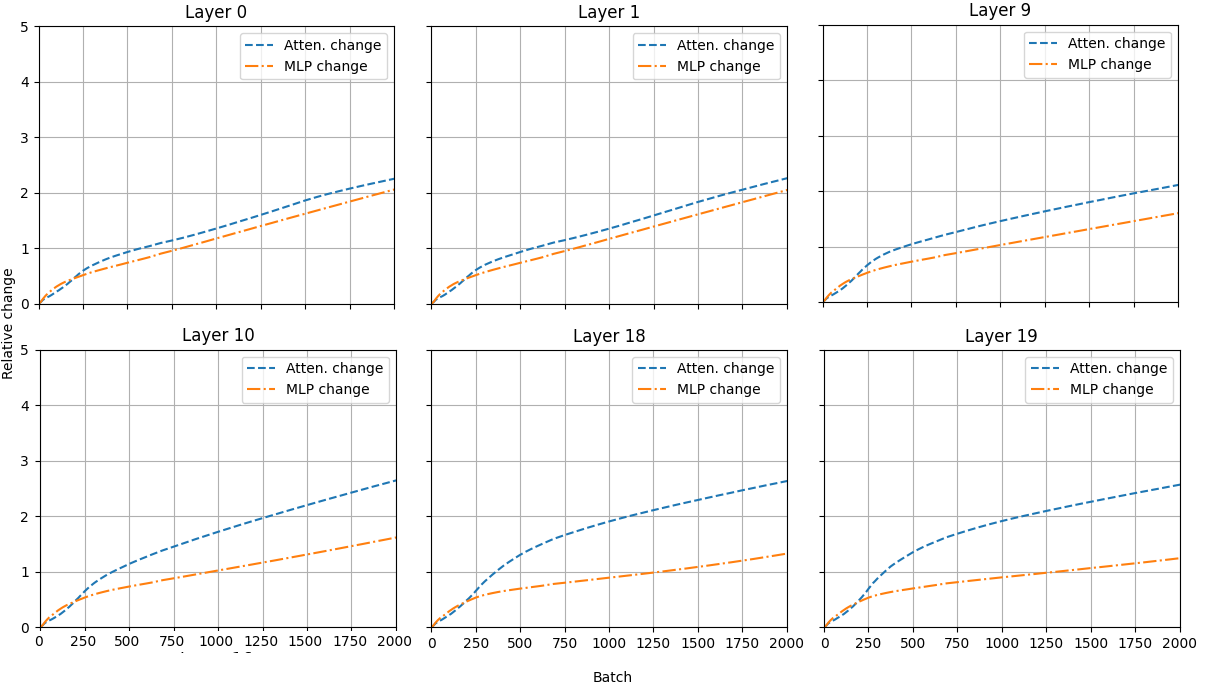
Figure 4: Plots illustrating the changes in relative weight values during the training of a GPT decoder-only network, with transformer weights broken down into attention and MLP components. While all layers clearly change, the impact on the Lipschitz constant is not direct.
Conclusion
The study presents a compelling case for adopting multilevel layer-parallel training methodologies in expanding the parallel scalability of transformers with increasing depth. The proposed approach mitigates gradient biases and preserves training accuracy while achieving significant parallel speedups. Future research directions may focus on refining MGRIT convergence and optimizing computational implementations to further exploit vectorization and reduce overheads, contributing to the efficient training of even larger-scale transformer models.