- The paper introduces a dual-anchor framework that fuses visual and textual prompts via gated cross-modal interactions to enhance semantic stability.
- It utilizes a confidence-aware optimization scheme that modulates anchor loss based on prediction entropy, significantly improving few-shot and base-to-novel transfer performance.
- Experimental results show BiomedAP outperforms prior models with up to 4.54% gain in strict few-shot settings and exhibits minimal degradation under prompt perturbations.
Introduction
BiomedAP proposes a parameter-efficient framework to address robustness limitations in biomedical vision-LLMs (VLMs) adapted for clinical diagnosis under few-shot and prompt-variant regimes. Contrary to prior approaches that treat visual and textual prompts with limited cross-modal interaction and rely on single, expert-crafted ('high anchor') textual prompts for alignment, BiomedAP combines gated cross-modal fusion and a dual-anchor constraint. The approach is designed to ensure semantic stability and improved transferability under diverse, noisy, or incomplete clinical descriptions.
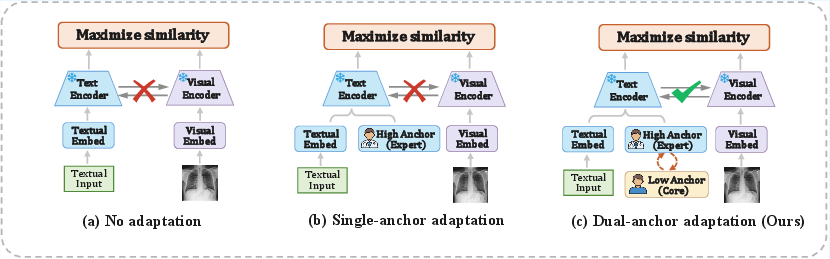
Figure 1: Schematic comparison of adaptation strategies highlighting (a) lack of adaptation, (b) single-anchor adaptation's fragility, and (c) BiomedAP's robust, semantic stability via dual-anchor alignment.
Methodology
Gated Cross-Modal Fusion
Central to the BiomedAP architecture is the Gated Cross-Modal Prompt Fusion (GCPF) mechanism. Fusion modules are strategically inserted into mid and late transformer layers of the frozen vision encoder to allow dynamic, layer-wise bidirectional exchange between visual and textual prompt representations. Multi-head cross-attention is adopted as the core operation, followed by gating mechanisms parameterized via a sigmoid-controlled residual to suppress semantically incongruent or noisy updates originating from the text branch. This ensures that visual features are only refined when textual evidence is consistent with observed clinical patterns, constituting an adaptive noise suppression mechanism.
Dual-Anchor Constraint
BiomedAP regularizes prompt learning with a Dual-Anchor Constraint (DAC) by anchoring the learned prompt feature for each class to both a high-quality expert textual centroid and a low-quality, vision-derived class prototype. The low anchor is computed as the normalized mean of frozen image encoder outputs across support samples for that class, thereby grounding the semantic adaptation firmly in visual core distributions, while the high anchor preserves medical specificity. The combined loss includes L1 regularization to ensure the prompt representation remains close to both anchor distributions.
Confidence-Aware Optimization
The supervision intensity of the anchor loss and knowledge distillation is modulated based on instance-level model confidence. Prediction entropy scales regularization: low confidence (high entropy) drives stronger constraint, mitigating overfitting to noisy or underspecified prompts. Cross-modal alignment loss further ensures that visual and textual branches converge towards a common subspace indicative of actual clinical relations.
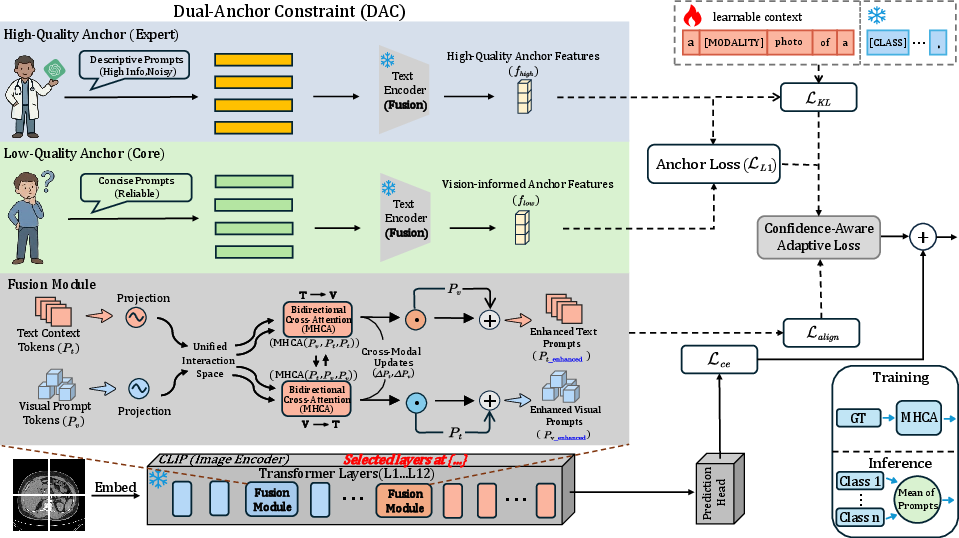
Figure 2: Overview of the BiomedAP framework, depicting gated bidirectional fusion and dual-anchor regularization within frozen VLM backbones.
Experimental Results
Few-Shot Adaptation and Base-to-Novel Transfer
Across eleven biomedical benchmarks, BiomedAP demonstrates significant improvements over parameter-efficient and prompt-learning baselines in strict few-shot settings (K∈{1,2,4,8,16}). For K=1, BiomedAP exceeds Biomed-DPT by 4.54% (achieving 63.57%), with the performance advantage stable across all shot settings (up to 75.09% at K=16). The gains transcend both base and novel classes—BiomedAP achieves base accuracy of 81.62%, novel accuracy of 78.42%, and a harmonic mean of 80.02%, attributing improvements to enhanced semantic stability with dual-anchor guidance.
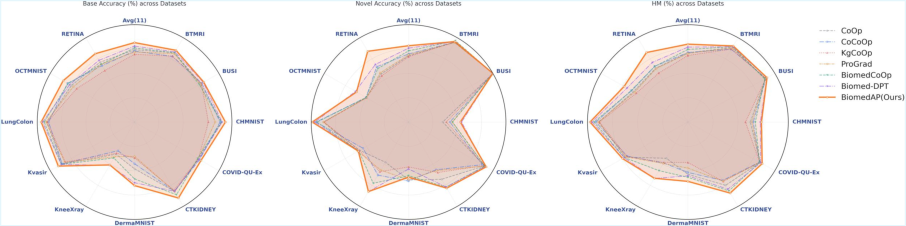
Figure 3: Base and novel class adaptation accuracy and harmonic mean (HM) across diverse medical image datasets, illustrating BiomedAP's superior transfer performance.
Robustness to Prompt Perturbations
BiomedAP maintains substantially more robust accuracy than prior state-of-the-art under prompt variations at inference time. With perturbations ranging from minimal prompts to domain-agnostic descriptions (even empty prompts), the performance degradation is limited to 2.1–4.1 percentage points—significantly lower than that observed in baselines. Even in the absence of textual context, BiomedAP achieves 73.81% versus Biomed-DPT’s 70.09%.
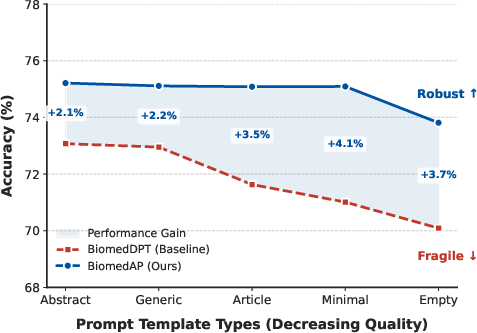
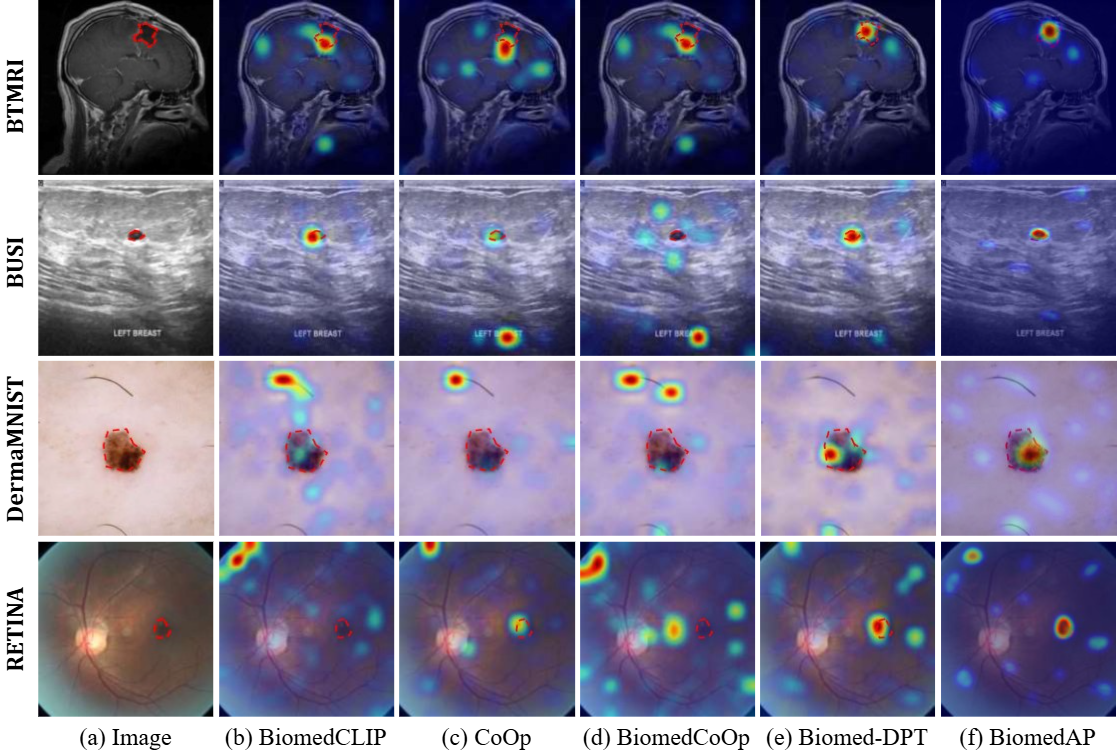
Figure 4: Comparative robustness of BiomedAP and Biomed-DPT under a spectrum of prompt variations at inference, emphasizing reduced performance sensitivity.
Ablation and Design Analysis
Ablations confirm that both GCPF and DAC yield additive improvements. The full system achieves a harmonic mean (HM) on transfer tasks of 80.02% versus 74.01% when both core components are removed. Key design choices—mid+late fusion (layers 5 & 8), mean-aggregation for label-free inference context, and sufficient prompt diversity—are critical to the observed accuracy benefits.
BiomedAP is further shown to benefit strictly from domain-aligned backbones; performance with BiomedCLIP initialization is drastically higher than with generalist CLIP or PMC-CLIP, supporting its requirement for biomedical pretraining.
Qualitative lesion localization assessments demonstrate that BiomedAP yields more compact, lesion-centered activation maps with improved suppression of irrelevant regions, indicating better visual grounding under variable textual conditions.
Implications and Future Directions
BiomedAP provides a reliable, parameter-efficient VLM adaptation framework for clinical diagnostic tasks characterized by prompt noise, heterogeneity, and sample scarcity. Its fusion-centric cross-modal learning paradigm, grounded by dual semantic anchors, addresses longstanding issues of prompt fragility and modality isolation encountered in foundational model deployment for medical imaging.
The implications include:
- Practical Deployment: Robustness to prompt variability is essential for real-world deployment, where clinical language is noisy and unstandardized. BiomedAP’s parameter-efficiency further supports integration into restricted-resource clinical settings.
- Cross-modal Grounding: The architecture demonstrates that intermediate cross-modal fusion should be a default for applications where semantic drift between modalities is consequential for decision-making (e.g., fine-grained lesion discrimination).
- Anchor-based Regularization: Enforcing prompt representations to remain close to dual semantic anchors could inform future work beyond biomedical VLMs—especially generalist models intended for specialized domains.
Potential extensions involve lightening the fusion module footprint for further efficiency, quantitative evaluation of lesion localization (e.g., via Dice coefficient), transfer to 3D/volumetric tasks, and exploration of dense prediction settings.
Conclusion
BiomedAP introduces a vision-informed dual-anchor strategy with gated cross-modal fusion, advancing robustness and transferability for medical VLMs facing heterogeneous text environments. Layer-wise visual-textual interaction combined with semantic anchor regularization produces state-of-the-art results in few-shot adaptation, base-to-novel transfer, and prompt perturbation robustness. This positions BiomedAP as a practical and theoretically motivated step forward in the reliable adaptation of biomedical vision-LLMs (2605.15736).