- The paper introduces a dual-modality framework that uses robust semantic text anchors and adaptive image anchors to improve view selection in test-time prompt tuning.
- It employs a joint alignment–confidence scoring strategy with a confidence-weighted ensemble that significantly boosts performance across multiple vision benchmarks.
- The proposed method overcomes the limitations of entropy-based filtering by providing semantically faithful, object-centric view selection with minimal computational overhead.
Dual-Modality Anchor-Guided Filtering for Test-time Prompt Tuning
Introduction
Test-Time Prompt Tuning (TPT) leverages unlabeled, augmented views during inference to adapt prompts in vision-LLMs (VLMs), notably improving domain generalization. However, TPT methods are fundamentally constrained by unreliable view selection, especially under distribution shift, due to the dominance of entropy-based filtering. Entropy, as a confidence proxy, suffers from miscalibration and tends to select uninformative, background-focused or irrelevant crops for adaptation, thus frequently resulting in misdirected prompt updates and degraded generalization. The paper "Dual-Modality Anchor-Guided Filtering for Test-time Prompt Tuning" (2604.12403) systematically addresses these deficiencies by introducing a dual-modality anchor framework to provide semantically-grounded, robust view selection and supervision signals for TPT, thereby achieving new state-of-the-art results across diverse vision benchmarks.
Motivation and Limitations of Existing View Selection
Prior TPT pipelines filter views using either straightforward entropy minimization or, more recently, a combination with visual similarity (cosine similarity to the source image). Under distribution shift, entropy can be poorly calibrated, leading to high-confidence but semantically erroneous selections. Similarity constraints, especially with standard data augmentation, reduce view diversity and often select non-informative views (Figure 1). This challenge is magnified by the fact that initial prompts in VLMs are frequently coarse (e.g., "a photo of a [CLASS]") and lack the granularity needed to delineate fine-grained object details.
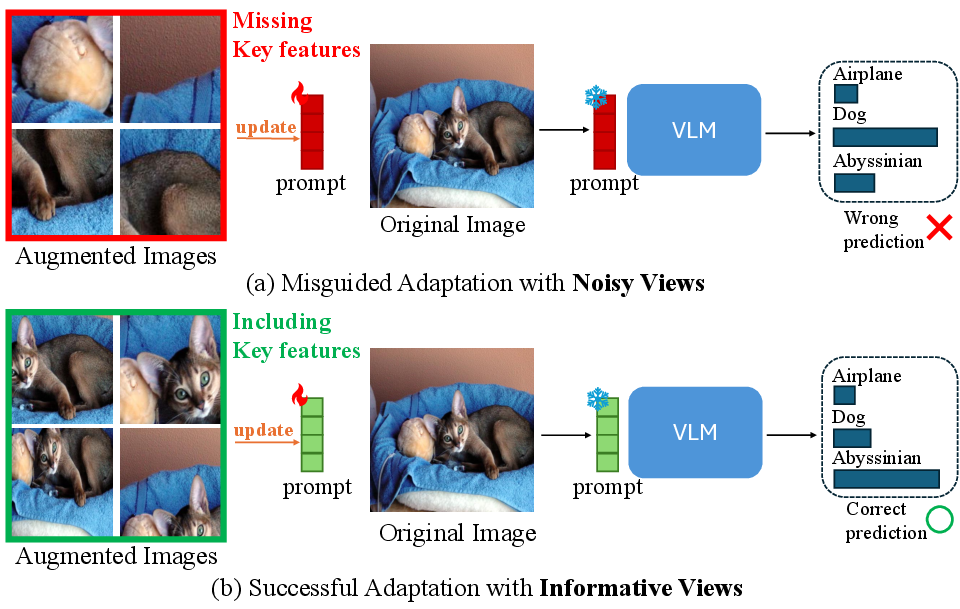
Figure 1: Prompt quality is highly sensitive to the semantic fidelity of selected views; noisy views lead to maladaptation, whereas informative views drive correct semantic alignment.
Dual-Modality Anchor Framework
The proposed framework decouples view selection and supervision into two synergistic modalities: a semantic text anchor and an adaptive image anchor.
Semantic Text Anchor Construction
Attribute-rich descriptions per class are generated via a LLM and encoded using the CLIP text encoder. Each augmented view is encoded via the CLIP image encoder. Text anchors synthesize these descriptions through alignment-weighted aggregation, emphasizing those most semantically aligned with the image views. For every test image, the process adaptively weights and aggregates textual attributes to produce class-semantics-sensitive anchors.
Adaptive Image Anchor Construction
The image anchor leverages an accumulative prototype bank, dynamically constructed from embeddings of previously selected, text-guided views. At test time, views passing text anchor filtering are aggregated class-wise to form robust image prototypes, capturing empirical data distributions and visual trends specific to the current domain shift.
Joint Alignment–Confidence Scoring and Filtering
For each view, a composite selection score is computed using a weighted sum of (i) alignment (cosine similarity with anchor features) and (ii) confidence (inverse normalized entropy). Views are filtered by either text or image anchor with respective alignment–confidence weights, and the final selection is the union of both filters (Figure 2).
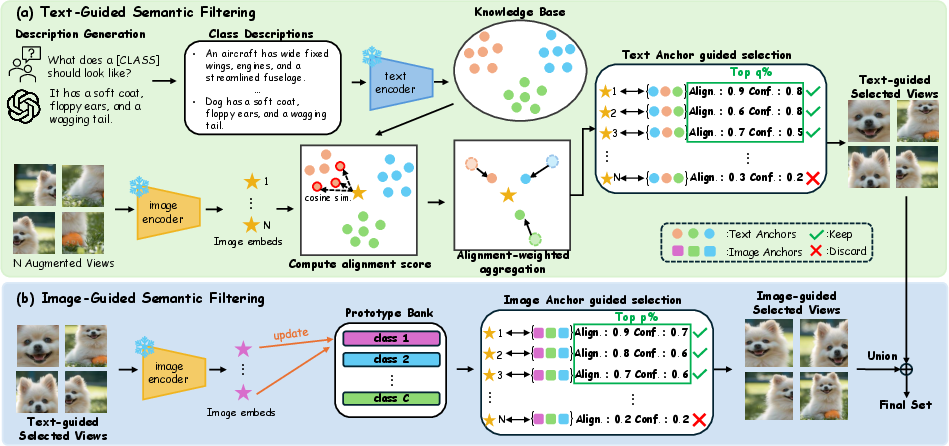
Figure 2: The dual-modality anchor framework combines alignment-weighted text anchors with adaptive image anchors, both driving robust, semantically aware view selection and ensemble prediction.
Confidence-Weighted Ensemble for Supervision
For each selected view, three similarity representations are produced using the base prompt, the text anchor, and the image anchor. Predictions from these heads are ensembled using confidence (maximum softmax probability) as weights, dynamically prioritizing predictive sources with highest reliability. A sharpened target distribution is derived from the ensemble for each image. Prompt optimization is conducted by minimizing the KL divergence between the ensemble and prompt-driven distributions, supplanting conventional entropy minimization and eliciting stable, de-biased updates.
Experimental Results and Empirical Analysis
The framework achieves statistically significant performance gains over strong baselines across 15 benchmarks, including ImageNet-A/R/V2/Sketch and 10 additional downstream datasets. For example, on ImageNet-R, the framework yields an improvement of +6.27% over the CLIP baseline and outperforms TPT by +3.68% in average accuracy, and DynaPrompt by +2.37%. Integrations with prompt tuning methods (CoOp, MaPLe) further enhance performance (+2.52–2.86% on OOD metrics).
Ablation studies confirm that each anchor modality (and their usage both as selection and prediction sources) cumulatively boosts accuracy. The alignment-weighted aggregation for text anchors further increases semantically meaningful selections, while proper weighting of alignment vs entropy in scoring is shown to be necessary for optimal filtering. The full dual-modality design (both filters, both ensemble heads) outperforms any single-modality configuration.
Qualitative analysis demonstrates that entropy-based or similarity-based filtering frequently select uninformative backgrounds or visually similar but irrelevant crops, whereas anchor-guided selection robustly recovers object-centric, semantically faithful views (Figure 3).
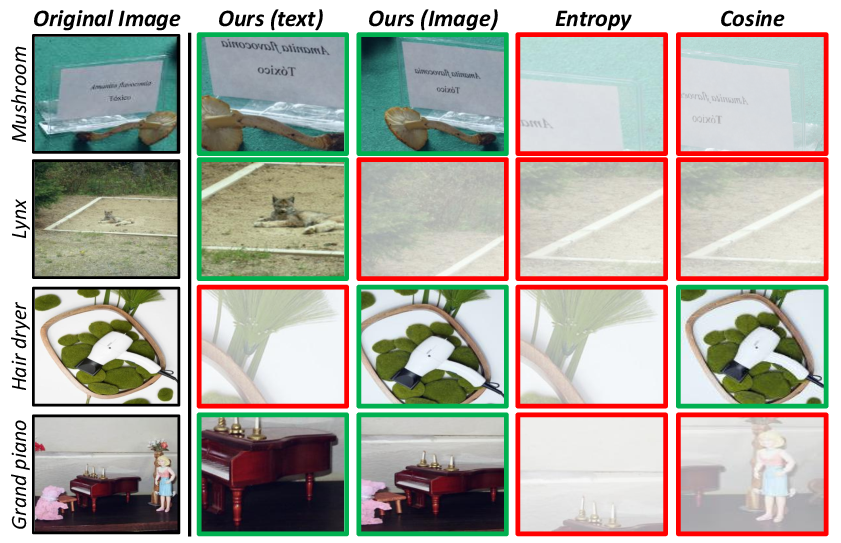
Figure 3: Visualizations show the superiority of anchor modalities in selecting views that genuinely contain target objects, in contrast to entropy/similarity-based selection strategies.
Theoretical and Practical Implications
The anchor-guided approach establishes that semantic alignment (via attribute-driven anchors) and adaptive visual prototypes (via dynamically updated class banks) are essential for robust view selection in TPT under distribution shift. This demonstrates the insufficiency of entropy as an uncertainty proxy and suggests that fine-grained semantic conditioning must be incorporated for effective adaptation. The decoupling of anchor modalities as both filters and predictive heads further suggests that multimodal fusion at both input and supervision stages dramatically enhances adaptation reliability.
Practically, this method is lightweight, modular, and introduces negligible computational overhead compared to existing TPT methods, being compatible with prevailing VLM backbones (e.g., CLIP ViT-B/16). It does not depend on computationally expensive augmentations (e.g., diffusion), making it broadly applicable.
Future Directions
Potential extensions include leveraging even richer context for anchor construction (e.g., multi-modal or video attributes), hierarchical anchor design for varied levels of semantic granularity, or integrating retrieval-augmented mechanisms to further bolster OOD robustness. There is also room for dynamic adaptation of alignment–confidence trade-off and exploration of fully unsupervised online anchor updating in streaming scenarios.
Conclusion
The dual-modality anchor-guided framework represents a significant methodological advancement in TPT for VLMs. By grounding view selection and supervision in both dense semantic and adaptive visual anchors, the proposed method robustly overcomes miscalibration and coarse granularity issues inherent in prior entropy-based selection. Its established efficacy across a wide spectrum of benchmarks points toward anchor-based conditioning as a foundational element for future adaptive prompt learning systems.