- The paper introduces VAMP, which efficiently tunes only a small set of prompt parameters to achieve effective multi-source few-shot domain adaptation.
- It combines loss functions like CSA, DDA, TCC, and TSD to align semantic and statistical distributions between diverse domains.
- Experimental results show average improvements of 3.2% and 1.6% on OfficeHome and DomainNet datasets, outperforming zero-shot CLIP and baseline methods.
Vision-aware Multimodal Prompt Tuning for Uploadable Multi-source Few-shot Domain Adaptation
Introduction
The paper introduces "Vision-aware Multimodal Prompt Tuning for Uploadable Multi-source Few-shot Domain Adaptation," emphasizing the need for efficient domain adaptation techniques on decentralized edge devices. Traditional Multi-Source Few-Shot Domain Adaptation (MFDA) techniques often demand substantial resources, limiting their deployment on low-resource devices. This paper proposes an Uploadable Multi-source Few-shot Domain Adaptation (UMFDA) schema to address these constraints and a vision-aware multimodal prompt tuning framework (VAMP).
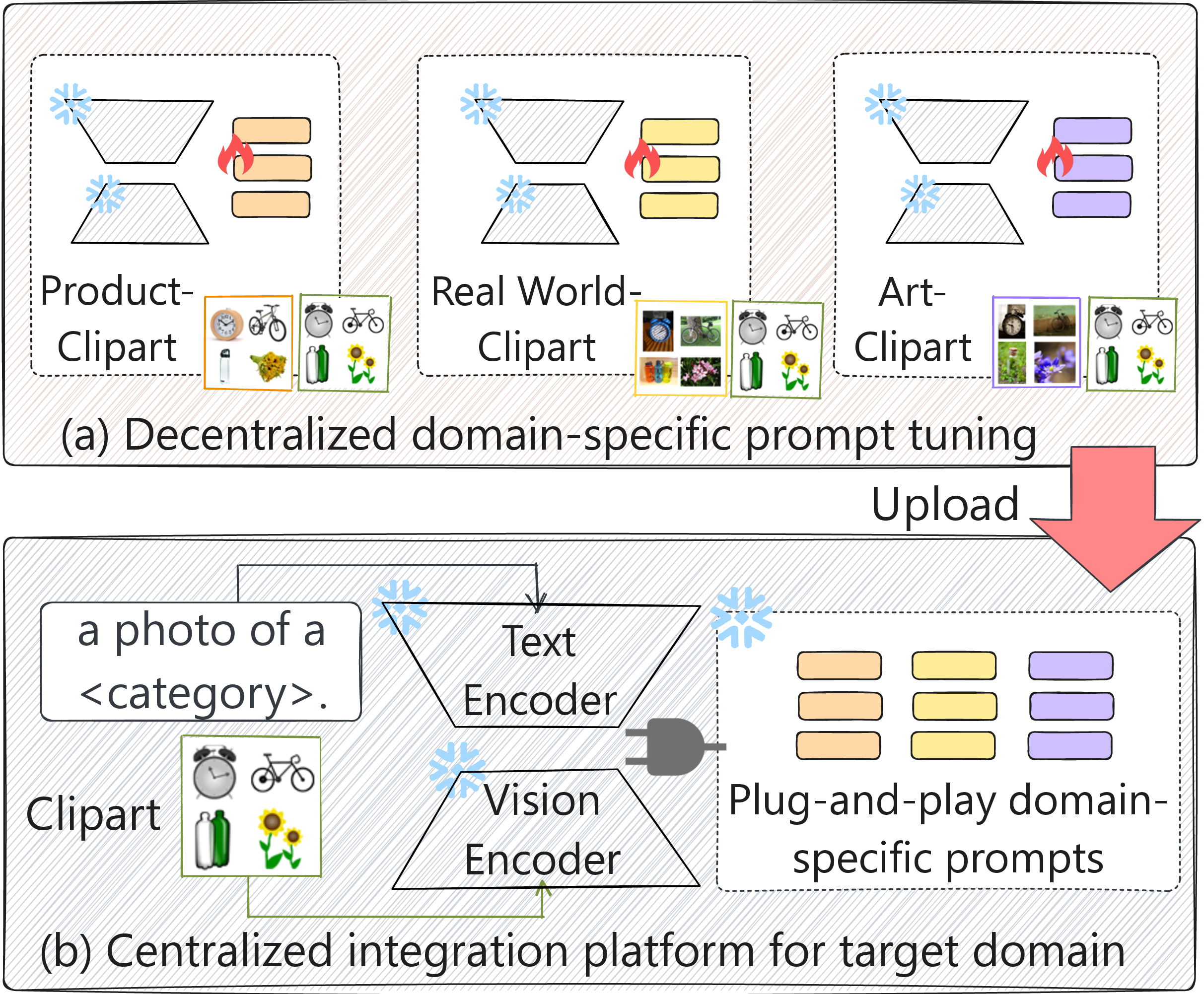
Figure 1: The illustration of uploadable multi-source few-shot domain adaptation (UMFDA) schema for decentralized edge learning.
Methodology
Vision-aware Multimodal Prompt Tuning Framework
The VAMP framework leverages vision-aware prompts to enhance existing Visual LLMs (VLMs) such as CLIP to adapt efficiently to new domains with minimal resources. This involves tuning a limited number of prompt parameters rather than the entire model, applying a plug-and-play strategy optimal for scenarios involving scarce labeled data. VAMP's design optimizes the vision and language encoders to manage domain-specific information, aligning the semantic space with these prompts.
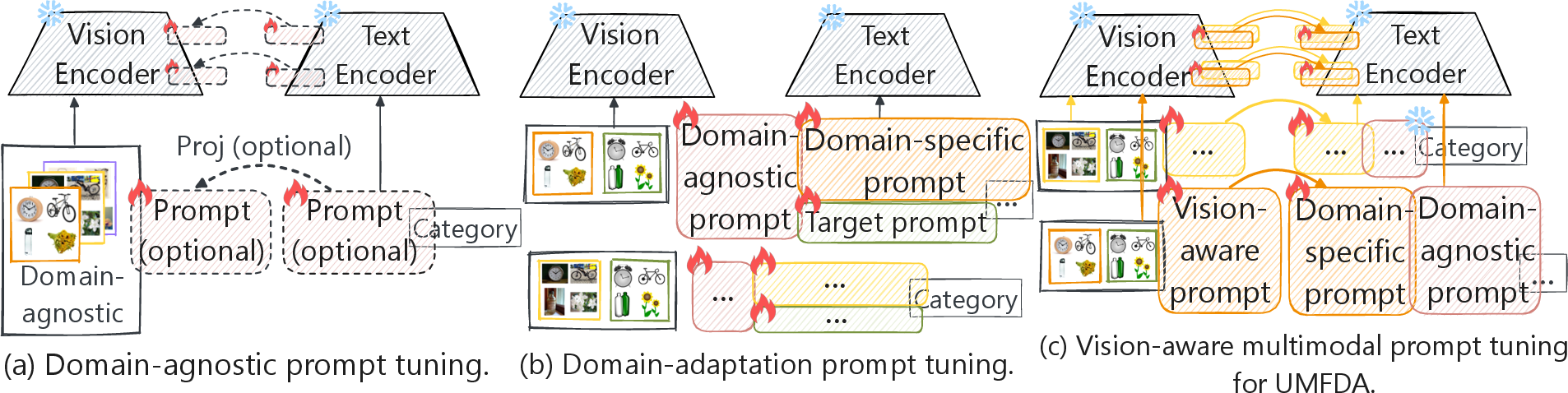
Figure 2: Summary of various prompt tuning technologies (best viewed in color).
Optimization Strategy
VAMP’s training involves several loss functions: Cross-modal Semantic Alignment (CSA), Domain Distribution Alignment (DDA), Text Classifier Consistency (TCC), and Text Semantic Diversity (TSD). CSA ensures semantic cohesion between the annotated and unannotated domains, DDA aligns the statistical distributions between domains, TCC reduces inter-model discrepancies, and TSD maintains semantic diversity across domain-specific prompts. This holistic optimization ensures effective domain adaptation with minimal computing overhead.
Experiments
VAMP was extensively tested on OfficeHome and DomainNet datasets. Compared to baselines and existing state-of-the-art prompt tuning methods, VAMP demonstrated a significant improvement in adapting to target domains. Zero-shot CLIP and traditional domain-agnostic prompt tuning methods functioned as comparative benchmarks.
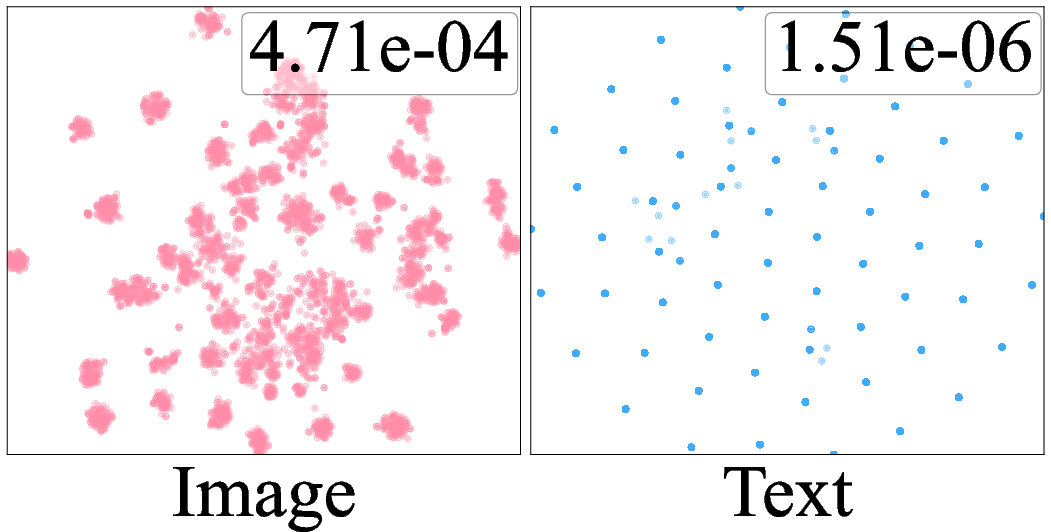
Figure 3: t-SNE visualization of the image and text features of target domain extracted by "Clipart-Real World" model of VAMP and DAPL.
Results
VAMP consistently outperformed traditional and prompt-based adaptation methods across multiple domain adaptation scenarios, showcasing an enhanced capacity to maintain semantic discriminability while aligning domain distributions. VAMP achieved an average improvement of 3.2% and 1.6% over zero-shot CLIP inference on the OfficeHome and DomainNet datasets, respectively. These results affirm VAMP's effectiveness, especially in decentralized settings where computing resources are limited. Attention map visualizations further demonstrated VAMP's superior focus on relevant image regions, emphasizing its strong feature discrimination and alignment capabilities.
Conclusion
The proposed VAMP framework provides a robust solution for deploying advanced machine learning models on resource-constrained devices, demonstrating substantial improvements over existing methods. By harnessing the potential of vision-aware prompts, VAMP establishes itself as a viable approach for achieving efficient domain adaptation in the field of decentralized edge computing. This work encourages further exploration into extending the VAMP framework's application across various domain adaptation tasks in constrained environments.