- The paper introduces an adaptive prompt bank with entropy-guided selection that improves generalization over static prompt methods.
- The methodology leverages LLM-derived attributes and composite loss functions to achieve significant gains, including a +15.1 accuracy boost in few-shot scenarios.
- The framework is computationally efficient with only ~30K additional parameters, delivering robust performance in base-to-new and OOD biomedical tasks.
BioVLM: Advancing Cross-Modality Generalization in Biomedical Vision-LLMs
Introduction
BioVLM introduces an adaptive and parameter-efficient approach for cross-modality generalization in biomedical vision-LLMs (VLMs), leveraging prompt learning with entropy-guided dynamic prompt selection rather than conventional parameter fine-tuning. The framework is motivated by the persistent challenges in biomedicine where even domain-adapted VLMs (e.g., BioMedCLIP, BioViL) exhibit poor generalization to unseen modalities, fine-grained categories, and clinical text distributions, especially under few-shot or distribution shift scenarios due to semantic noise and modality-specific artifacts. Prior prompt-based approaches, typified by CoOp and BioMedCoOp, are limited by static prompt sets and insufficient modeling of intra-modal and inter-class diversity. BioVLM addresses these gaps by introducing a learnable prompt bank, LLM-guided context distillation, and robust entropy-minimization selection, achieving a strong empirical performance boost on the MedMNIST+ suite.
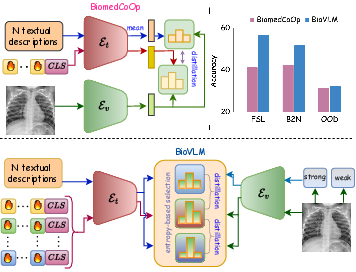
Figure 1: BioVLM overview—entropy-based prompt selection synergizes few-shot semantics with LLM knowledge and achieves substantial gains over BioMedCoOp across generalization settings.
Framework and Methodological Contributions
Adaptive Prompt Bank with LLM-Derived Attributes
BioVLM is instantiated on top of a frozen BioMedCLIP backbone, entailing both image and text encoders. For each class, a diverse bank of N learnable prompts is created. These prompts are initialized using contextualized attribute descriptions generated by LLMs (LLMs; GPT-4o and variants), with modality-specific prefixes and connecting structures to maximally encode clinically relevant, fine-grained class attributes. The prompts are independently learned for each attribute, facilitating specialization and robust semantic alignment.
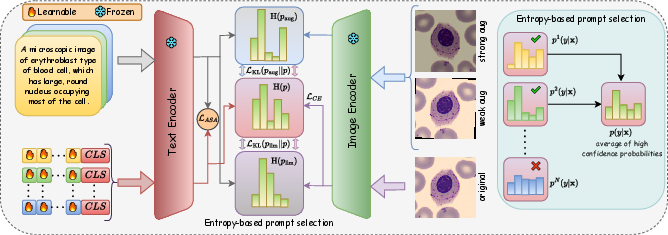
Figure 2: BioVLM’s architecture integrates a frozen image encoder and text encoder, with learnable, LLM-derived prompts and an entropy-based selection strategy for discriminative knowledge routing.
Entropy-Guided Prompt Selection
At inference, the model computes class-wise similarity scores for each prompt variant. Instead of averaging or selecting based on class confidence, BioVLM applies an entropy-based criterion: prompts with the lowest predictive entropy (highest confidence and least ambiguity) are selected adaptively per input, with the final decision based on the normalized ensemble over the filtered set. This approach provides dynamic adaptation to both data modality and intra-class heterogeneity, effectively coupling few-shot supervision and LLM priors while filtering noisy or redundant descriptions.
Attribute-Semantic and Distillation Losses
BioVLM’s learning objective combines classical cross-entropy loss with three additional regularizers: attribute-semantic alignment (maximizing cosine similarity between learnable and frozen LLM text features), low-entropy regularization (minimizing the entropy of both student and teacher distributions), and Kullback-Leibler distillation from LLM and augmented-view teachers. This composite risk minimization directly drives both the empirical error and model complexity (in the structural risk sense) down, supporting robust generalization.
Empirical Results and Analysis
Few-Shot and Base-to-New Generalization
On the MedMNIST+ benchmark, spanning 11 biomedical imaging datasets and multiple modalities, BioVLM provides substantial gains over prior prompt-learning and few-shot adaptation baselines. For the few-shot regime, BioVLM achieves an average accuracy of 56.51%, outperforming BioMedCoOp by +15.1 points and all PEFT (parameter-efficient fine-tuning) competitors by wide margins. Notably, on challenging datasets such as BloodMNIST and TissueMNIST, the improvement over CoOp exceeds 25 percentage points.
In base-to-new generalization, measuring transfer to unseen intra-modal categories, BioVLM leads with an average harmonic mean (HM) of 51.77%, consistently surpassing deep prompting baselines (e.g., MaPLe, TCP, PromptSRC) by 7–8 points. Performance improvements are most pronounced on datasets with substantial intra-class variation and ambiguous semantics, underlining the importance of both prompt diversity and dynamic selection.
Out-of-Distribution Generalization
For out-of-distribution (OOD) transfer—where training and test data are sampled from entirely different modalities or acquisition protocols—BioVLM achieves the highest average accuracy of 32.34%, slightly edging all prior prompt-based methods. While the performance gain in OOD settings is less dramatic than in few-shot or base-to-new scenarios (reflecting persistent domain shifts), BioVLM maintains robustness across structurally diverse domains, indicating improved representation stability and less overfit to training artifacts.
Ablation Studies
Prompt diversity and selection mechanism ablations indicate that increasing the number of learnable prompts improves generalization up to a saturation point (N=10), after which performance plateaus and may degrade due to noise. Entropy-based prompt selection surpasses all fixed aggregation strategies (e.g., Softmax, Mean, Top-k), confirming that model confidence filtering is crucial under domain or label shift.
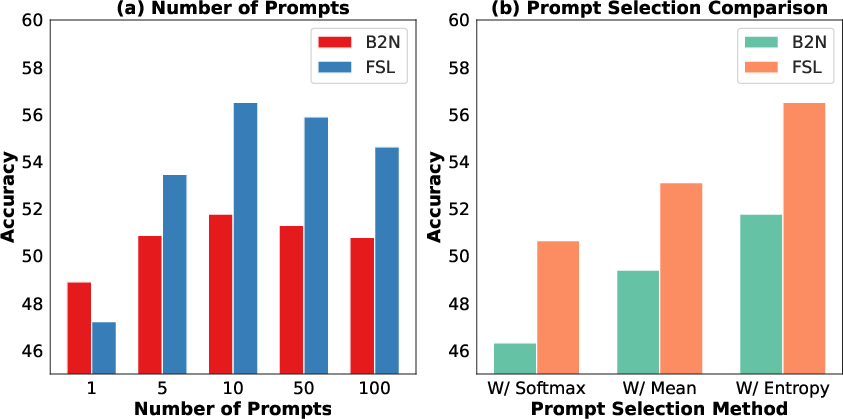
Figure 3: Model ablation for prompt number (a) and selection method (b); entropy-based selection and prompt diversity yield consistent gains.
Hyperparameter sensitivity analyses for loss weightings also confirm that all loss components contribute to strong generalization bounds, with attribute-semantic alignment and entropy losses being especially essential.
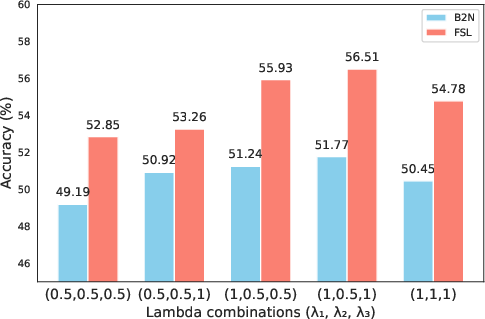
Figure 4: Ablation over loss weights λ1, λ2, λ3 shows both base-to-new and few-shot gains are robust to weighting scheme.
Qualitative Interpretability
t-SNE visualizations of prompt-driven class logits show clear improvement in class separation compared to previous prompt methods, reflecting better disentanglement in the joint image-language space and increased attribute utilization in the decision process.
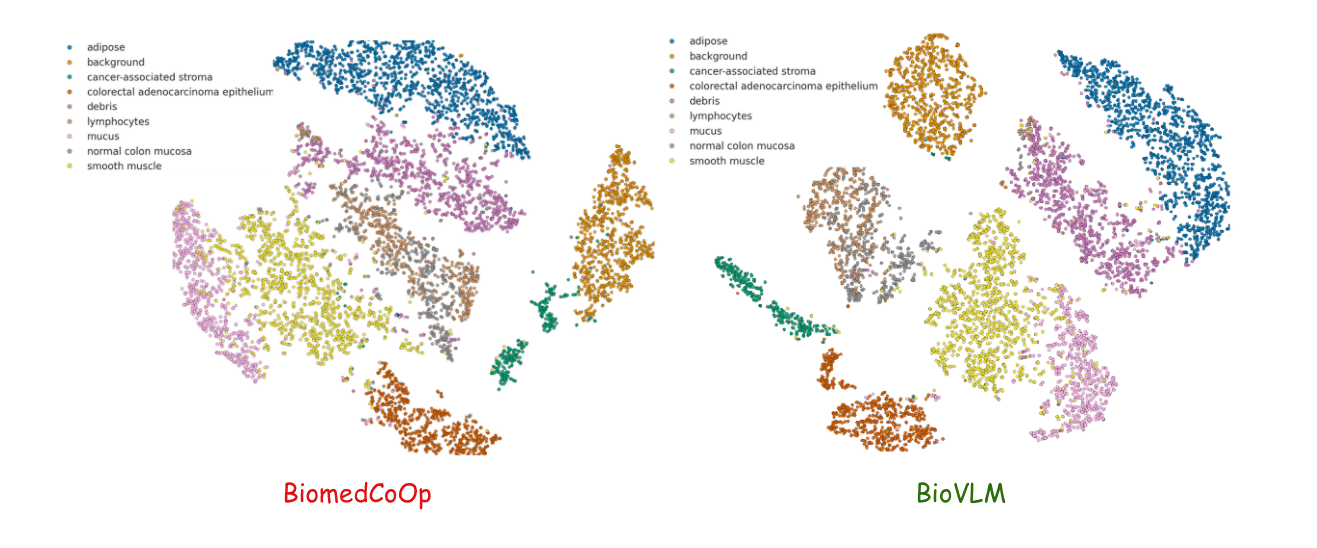
Figure 5: t-SNE shows BioVLM’s embedding yields superior class separation over BioMedCoOp on few-shot PathMNIST.
Computational Efficiency
BioVLM’s adaptation cost is marginal, with only ~30K additional prompt parameters—significantly fewer than deep tuning baselines (e.g., MaPLe with 5.3M parameters)—and inference is fully decoupled from LLMs, remaining lightweight and production-viable.
Implications and Future Directions
BioVLM’s innovations establish a strong baseline for robust biomedical generalization with minimal computational and annotation cost. The decoupling of backbone parameters and task adaptation via dynamic prompt routing positions the framework as readily extensible to large-scale, multi-modal, and federated clinical scenarios, where privacy/security constraints preclude full model sharing or updating.
Key theoretical implications include further evidence for the superiority of structured, data-driven prompt banks and dynamic prompt selection policies (entropy/uncertainty-based) over static or shallow prompt adaptation, particularly under heavy domain and label drift. In addition, the use of LLM-derived semantic attributes highlights the feasibility of employing synthetic or generatively-derived priors to mitigate annotation bottlenecks and sparse supervision regimes.
Several open research directions emerge: (1) automated or adversarial prompt refinement to further filter or generate highly discriminative context; (2) integrating domain-invariant representations or hierarchical anatomical priors to address residual OOD performance drops; (3) extending the architecture to 3D volumetric tasks and integrating with segmentation or detection pipelines for full workflow coverage. The modularity of BioVLM also lends itself to privacy-aware and communication-efficient federated settings.
Conclusion
BioVLM provides a new paradigm for domain-generalized biomedical vision-language modeling, replacing parameter-centric adaptation with entropy-routed, context-rich prompt learning and LLM-guided attribute distillation. The results demonstrate state-of-the-art performance in few-shot, base-to-new, and OOD tasks—with strong efficiency and practical deployment properties. The approach defines a promising direction for cross-modality transfer in clinical AI and foundation model research.
Reference:
BioVLM: Routing Prompts, Not Parameters, for Cross-Modality Generalization in Biomedical VLMs (2604.17629)