FutureSim: Replaying World Events to Evaluate Adaptive Agents
Abstract: AI agents are being increasingly deployed in dynamic, open-ended environments that require adapting to new information as it arrives. To efficiently measure this capability for realistic use-cases, we propose building grounded simulations that replay real-world events in the order they occurred. We build FutureSim, where agents forecast world events beyond their knowledge cutoff while interacting with a chronological replay of the world: real news articles arriving and questions resolving over the simulated period. We evaluate frontier agents in their native harness, testing their ability to predict world events over a three-month period from January to March 2026. FutureSim reveals a clear separation in their capabilities, with the best agent's accuracy being 25%, and many having worse Brier skill score than making no prediction at all. Through careful ablations, we show how FutureSim offers a realistic setting to study emerging research directions like long-horizon test-time adaptation, search, memory, and reasoning about uncertainty. Overall, we hope our benchmark design paves the way to measure AI progress on open-ended adaptation spanning long time-horizons in the real world.
Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
FutureSim: Replaying World Events to Evaluate Adaptive Agents — A Simple Explanation
What is this paper about?
The paper introduces FutureSim, a realistic “time machine” for testing AI agents. It replays real news and events day by day, so AI systems have to keep up, search for new information, and update their predictions about the future—just like a human forecaster would.
What questions are the researchers trying to answer?
- Can AI agents adapt over many weeks or months as new information arrives?
- How well can they forecast real-world events after their knowledge cutoff (the date after which the AI hasn’t seen any data during training)?
- Which skills help most with long-term forecasting: good search, good memory, smart updating, or more compute time?
- How do different agent setups (called “harnesses”) change performance?
- Can multiple agents working in the same environment influence each other in useful ways?
How does FutureSim work?
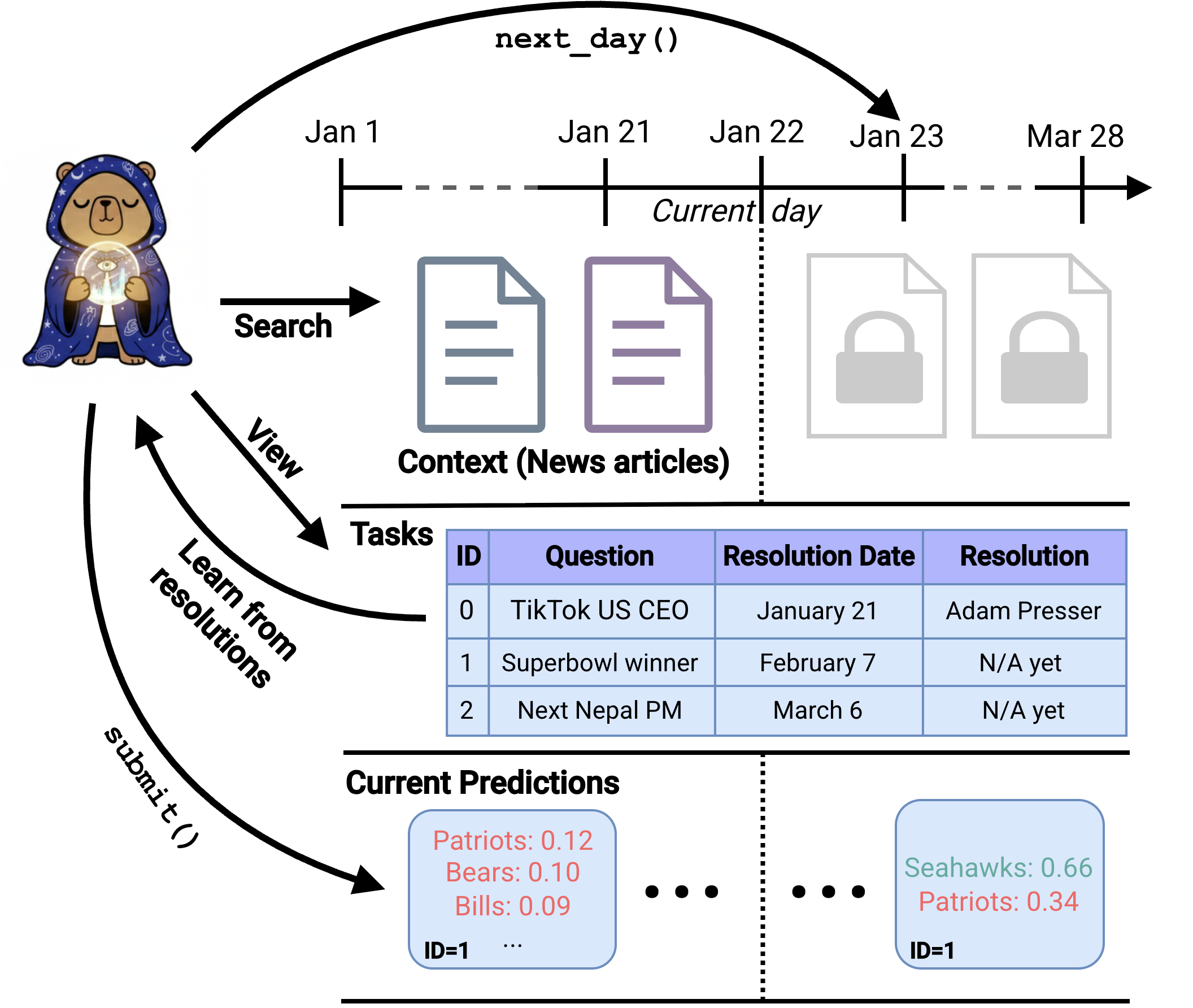
Think of FutureSim like a season-long sports league for AI forecasters. Each “day” in the simulation equals a real calendar day. New articles arrive, some questions get resolved, and the AI must decide what to predict next.
Here’s the setup in everyday terms:
- The world replay:
- The environment uses timestamped news articles (from Common Crawl News) that are guaranteed to be from that date. No peeking into the future.
- The simulation runs over 90 days (Jan–Mar 2026 in the study), adding new articles daily.
- The forecasting questions:
- Questions are created from real news (for example: “Who will win the election in X?” or “Will this policy pass?”).
- Unlike multiple choice, the AI must invent its own set of possible outcomes and assign probabilities to them (for example: 60% candidate A, 30% candidate B, 10% runoff).
- When the real-world outcome happens, the question “resolves,” and the AI gets feedback.
- What the AI can do:
- submit_forecast(question_id, outcomes): update its probabilities for a question.
- next_day(): move to the next day, get new articles, and see which questions resolved.
- How predictions are scored:
- Accuracy: Was the most likely outcome the AI named actually correct?
- Brier Skill Score (BSS): A score that rewards well-calibrated probabilities. If you say 70% and it happens, that’s better than always saying 100%.
- Higher is better. About 1 is perfect, 0 is like not predicting at all, and negative means your probabilities are worse than doing nothing.
- Guardrails and fairness:
- The AI is “sandboxed,” meaning it can only read articles up to the current date—no web browsing or sneaking info from the future.
- A separate LLM acts as a “judge” to check if the AI’s predicted outcome text matches the real answer.
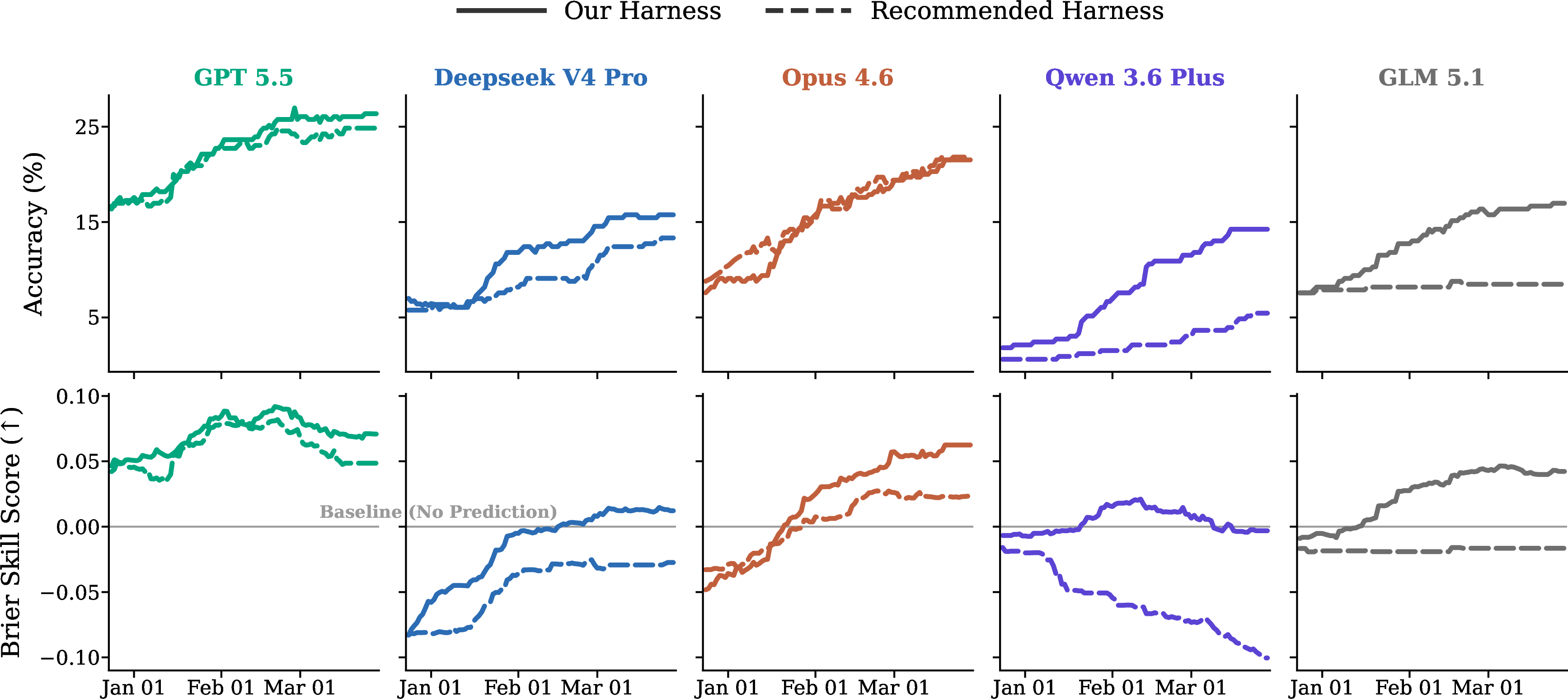
- Agent “harness” (the setup and tools the AI uses):
- Models run with their recommended coding/agent tools (like Codex or Claude Code).
- The authors also built a stronger custom harness with helpful features:
- Clear forecasting guidelines and prompts
- A memory system (to remember past findings and lessons)
- Better search over the news
- Structured updates day by day
What did they find?
Here are the main results, explained simply:
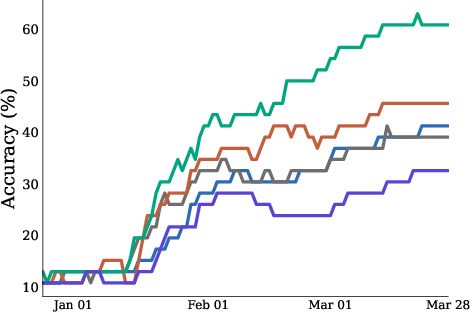
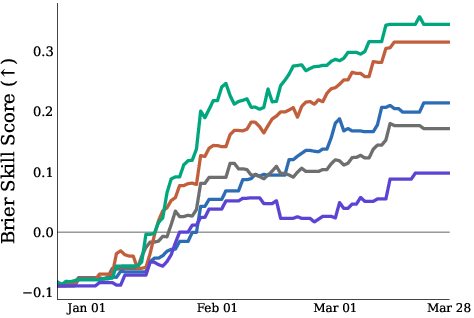
- Different AIs performed quite differently:
- GPT 5.5 was the best overall, with the highest accuracy (about 25%) and the best Brier Skill Score.
- Some open-weight models (models you can download and run yourself) had negative Brier Skill Scores—meaning their probability estimates were worse than not predicting.
- Everyone improved over time—but not enough:
- Most models got better as more news arrived.
- However, many struggled with “test-time adaptation” (updating earlier predictions when new info appears). They often got stuck on their first guesses and didn’t adjust enough.
- Memory helps:
- Turning off the memory system made all tested models worse. Memory stored useful summaries, feedback from resolved questions, and prevented “drift” (forgetting good priors and overreacting to weak evidence).
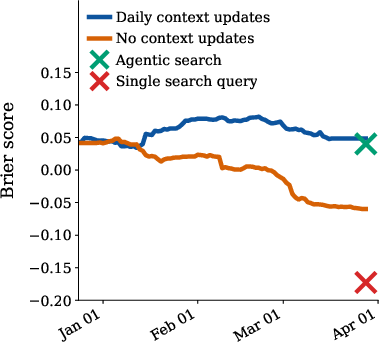
- Search matters—a lot:
- Actively searching the evolving news every day greatly boosted accuracy compared to not updating the context or doing just a single simple search.
- Forecasting requires creative, multi-step searches over time, not just retrieving one article.
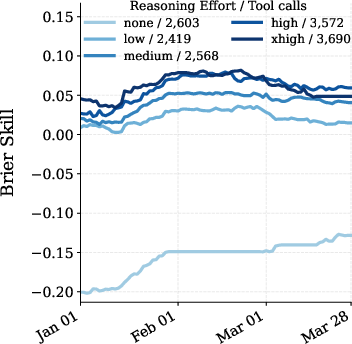
- More compute (more careful thinking) helps:
- Giving the AI more “reasoning effort” (more tool calls, longer analysis) improved accuracy.
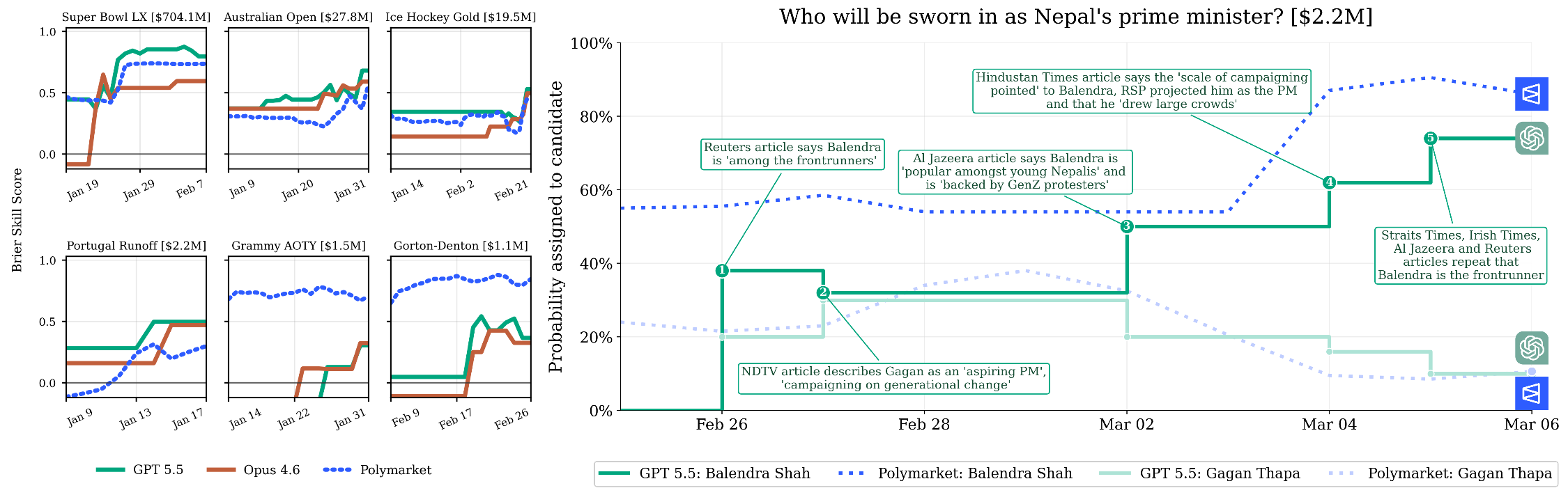
- Comparing to human markets:
- On some public prediction markets (like Polymarket), GPT 5.5’s updates sometimes matched or even led the crowd’s movement, suggesting real-world value.
- On other questions, it lagged or underperformed—especially where human preferences or social info mattered and the news corpus was missing fresh signals (like social media).
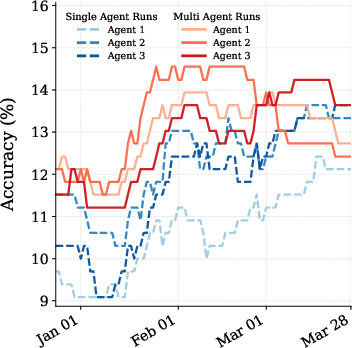
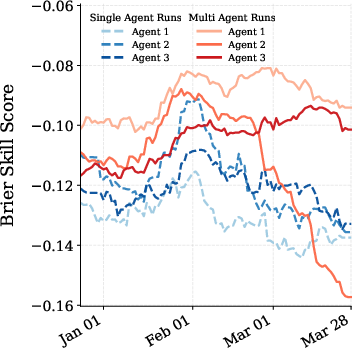
- Multi-agent behavior:
- When multiple agents ran together and could see the group’s aggregate prediction, their forecasts moved toward agreement over time.
- This hints at how crowds of agents might interact and converge—similar to how human prediction markets work.
Why is this important?
- Realistic, long-term testing: Many AI benchmarks are short puzzles. FutureSim checks whether agents can handle the messy, changing real world over months.
- Safer, reproducible science: Because it replays past events, anyone can rerun the same test later. It’s not dependent on live markets or unstable APIs.
- A testbed for key skills:
- Long-horizon adaptation (learning and updating over weeks)
- Memory management
- Strategic, multi-step search
- Calibration under uncertainty (probabilities that make sense)
- Harness design (how to set up tools and prompts)
- Multi-agent interaction
What could this change in the future?
- Better adaptive agents: FutureSim can guide the creation of AI that updates its beliefs reliably, stays calibrated, and handles long sequences of changing information.
- Practical forecasting help: If agents keep improving here, they could assist journalists, analysts, governments, and companies with up-to-date, well-calibrated predictions.
- Research platform: Because the environment is flexible and uses minimal rules, researchers can swap in new questions, new document sources, new memory systems, or new agent designs—and directly measure what works.
In short, FutureSim is like a realistic training league for AI forecasters. It shows that today’s top models can track the news and improve, but still have clear weaknesses in long-term adaptation, memory use, and calibration. The benchmark gives the community a fair, repeatable way to fix those gaps and build agents that can truly keep up with the real world.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a concise list of what remains missing, uncertain, or unexplored in the paper, phrased to enable concrete follow-up work.
- Data coverage and bias
- Reliance on a single primary source for question generation (Al Jazeera) risks topical, geographic, and stylistic bias; evaluate multi-source, multilingual curation and quantify shifts in topic distribution and difficulty when diversifying sources.
- The search corpus (CCNews) omits high-signal, fast-moving channels (e.g., social media, official press wires, SEC filings); measure performance gains and leakage risks when adding dated, high-frequency streams and structured datasets.
- Assess language and regional coverage (141 sources) and add cross-lingual retrieval/evaluation to reduce English-centric bias.
- Temporal integrity and knowledge-cutoff verification
- Establish auditable procedures to verify and certify model knowledge cutoffs (especially for closed models) and detect pretraining contamination with post-cutoff content.
- Quantify the robustness of “reliably dated” article snapshots (CCNews) to retroactive edits, backdating, and deduplication artifacts; add integrity checks and falsification tests.
- Question quality and resolution ground truth
- Provide systematic human audits for ambiguity, leakage, and difficulty calibration of automatically generated questions; release inter-annotator agreement and error taxonomies.
- Many real events resolve fuzzily; develop and test principled protocols for ambiguous/partial resolutions and late corrections (with timelines, appeals, and provenance).
- Current horizon is short (3 months). Explore longer horizons (6–24 months) and mixed cadences (hourly/daily/weekly) to probe different adaptation regimes.
- Evaluation metrics and scoring design
- The proposed “Brier Skill Score” variant differs from the standard “skill score” definition; benchmark against standard Brier/time-weighted/Bayesian updating scores and release proofs/empirics on propriety, calibration, and incentive compatibility.
- Current scoring emphasizes final forecasts; add timeliness-aware scoring (e.g., time-weighted Brier, log score over trajectories) and explicit penalties/rewards for update latency and volatility.
- Limit of ≤5 outcomes per question is an efficiency-driven constraint; study how this cap affects calibration/sharpness and explore scalable answer matching that supports larger outcome sets.
- Report full calibration diagnostics (reliability diagrams, ECE, resolution/sharpness) and per-topic/per-horizon breakdowns; quantify overconfidence and anchoring at fine granularity.
- Answer matching reliability and robustness
- Scoring depends on an LLM answer matcher (DeepSeek v3.2); quantify matcher error rates, adversarial susceptibility (e.g., gaming with outcome phrasing), and cross-matcher variability; release matched/unmatched pairs and adjudication guidelines.
- Evaluate non-LLM or hybrid matching (symbolic normalization, ontology mapping) and ensemble adjudication to reduce single-matcher bias.
- Stress-test matcher against near-synonyms, granularity mismatches, and negations; publish a public “matcher challenge” set.
- Fairness and comparability across agents/harnesses
- Models are evaluated in heterogeneous, model-native code harnesses with differing tool ecosystems and prompts; create a standardized, capability-matched harness to isolate model capability from orchestration quality.
- Normalize or cap tool calls/tokens to support cost- and compute-fair comparisons; report cost-adjusted leaderboards and performance–compute scaling laws with uncertainty intervals.
- Provide statistical significance (CIs, hypothesis tests) over seeds ≥3; quantify between-run variance and sensitivity to retrieval nondeterminism.
- Search and retrieval methodology
- Current retrieval uses a hybrid semantic/keyword search with fixed chunking (5 × 512 tokens) and Qwen3 embeddings; benchmark a spectrum of time-aware, multi-hop, iterative, and reasoning-aware retrieval methods and embeddings.
- Provide gold document sets per question (when feasible) to measure recall/precision of retrieval independently of forecasting performance.
- Evaluate the impact of evolving corpus freshness: quantify lag vs markets and add “freshness” or recency priors; explore rolling indices and streaming RAG.
- Memory and state management
- The file-based memory can induce self-conditioning and error cementing; investigate memory governance (confidence tagging, decay, consolidation, counterfactual tracking) and interventions to mitigate anchoring/drift.
- Compare alternative memory architectures (episodic vs semantic, vector stores, hierarchical summaries, tool-augmented notebooks) under the same compute budget.
- Measure how memory policies trade off stability vs adaptability across long horizons and topic shifts.
- Test-time adaptation mechanisms
- Agents under-adapt from poor initial forecasts; develop and evaluate principled de-anchoring strategies (e.g., counter-updating, Bayesian reweighting, uncertainty-aware re-initialization, TTT/TTA).
- Explore lightweight online learning (test-time training on resolutions, kNN adapters, retrieval-augmented gradient updates) with safety/overfit controls.
- Establish upper bounds by “oracle sequential access” ablations and quantify the gap to full-information, question-at-T–1 performance across models.
- Multi-agent dynamics and information aggregation
- Current multi-agent setup uses only an aggregate prediction signal; explore richer interaction protocols (debate, critique markets, auction-based aggregation, peer prediction) and measure effects on diversity, convergence, and accuracy.
- Define metrics for information contribution (marginal value, diversity, mutual information) and incentives that reward non-redundant yet accurate signals.
- Study robustness to herding, collusion, echo chambers, and strategic manipulation; test aggregation rules (log-odds averaging, extremizing, proper scoring for peers).
- External validity and human baselines
- Comparisons to Polymarket are limited and confounded by corpus freshness and market microstructure; design synchronized, preregistered comparisons with timestamp-aligned evidence sets.
- Collect human expert and superforecaster baselines on the same questions with identical information constraints; analyze where agents outperform/underperform and why.
- Safety, misuse, and ethical considerations
- The benchmark highlights potential for profitable trading; analyze dual-use implications, market manipulation risks, and disclosure policies for model forecasts.
- Assess exposure to harmful or misleading content in the news corpus and the system’s resilience to prompt injection and content-based attacks within retrieved documents.
- Reproducibility, versioning, and releases
- Closed-model versions and toolchains evolve; provide containers, model fingerprints, retrieval snapshots, and deterministic seeds to ensure long-term reproducibility.
- Publish full datasets (questions, resolutions, retrieval indices), harness code, and scoring scripts with versioned releases; add audit trails for question provenance and resolution evidence.
- Scope and extensibility of the environment
- The environment is purely predictive; propose extensions to decision-making domains where agent actions affect outcomes with carefully controlled counterfactual simulators.
- Add domains beyond general news (science forecasts, earnings, elections, conflict risk, climate/weather) and structured benchmarks to test specialized reasoning.
- Vary time-step granularity (intra-day to monthly), introduce event bursts, and test robustness to distribution shifts and “quiet” periods.
- Interface and action space design
- Only two actions are available (
submit_forecast,next_day); evaluate richer action spaces (e.g., evidence curation, hypothesis registration, intermediate claims with verification) and their impact on performance and interpretability. - Introduce explicit budgeting and scheduling tasks (time/compute allocation across questions) and measure planning efficiency.
- Only two actions are available (
- Leaderboard and analysis transparency
- Provide per-question performance breakdowns, topic-wise leaderboards, and error galleries to enable targeted method development.
- Release ablation templates and evaluation harnesses for search-only, memory-only, adaptation-only settings to standardize component-wise comparisons.
Practical Applications
Immediate Applications
Below are concrete, deployable uses that can be built now on top of the paper’s methods, data curation approach, and evaluation environment.
- AI vendor selection and model governance for adaptive agents (software, finance, healthcare, enterprise)
- What: Use FutureSim-style chronological replays to compare vendor models and internal agents on long-horizon adaptation, calibration, and overconfidence (Brier Skill Score dashboards; top-1 vs calibration trade-offs).
- Tools/products/workflows: “Adaptive Agent Scorecard” service; Brier Skill Score API; Answer-Matching Grader service; repro harness suite with sandboxed tool use and offline, reliably dated news corpora.
- Assumptions/dependencies: Access to timestamped corpora (e.g., CCNews snapshots); reproducible model versions; consistent answer-matching prompts; sufficient test-time compute budgets.
- “ForecastOps” pipelines for risk and strategy teams (finance, supply chain, energy, tech, media)
- What: Continuous probabilistic forecasts on world events with daily updates, memory, and search over evolving corpora to inform risk registers, hedging, and scenario planning (e.g., elections, regulatory shifts, supply disruptions).
- Tools/products/workflows: Agentic search over LanceDB/semantic+keyword retrieval; per-question memory; scheduled next_day() updates; calibration monitoring; alerting when Brier Skill Score or divergence from human aggregates crosses thresholds.
- Assumptions/dependencies: Grounded, dated content; domain-relevant question sets; human review for high-stakes decisions; careful sandboxing to prevent leakage.
- Newsroom and OSINT augmentation with calibrated probabilities (media, defense/intelligence, NGOs)
- What: Attach well-calibrated probabilities and evolving rationales to developing stories (e.g., leadership changes, ceasefires, court rulings), improving editorial planning and OSINT triage.
- Tools/products/workflows: Editorial dashboard showing forecasts per story with search provenance, memory of updates, and resolution outcomes; integration with internal archives rather than the public web.
- Assumptions/dependencies: Legal use of news content; date fidelity; humans-in-the-loop to vet rationales; controlled access to avoid future info leakage.
- Pre-deployment harness and toolchain evaluation (software engineering, MLOps)
- What: A/B test orchestration choices (coding harness vs task-specific harness), memory policies, search settings, and reasoning effort to improve adaptation without changing base models.
- Tools/products/workflows: Harness experimentation suite (context compaction feedback, structured memory, per-question memory, forced update phases); cost-performance curves for “reasoning effort.”
- Assumptions/dependencies: Stable compute budgets; agent tool access (file I/O, shell, local search); version-controlled harnesses to ensure reproducibility.
- Retrieval and dynamic search benchmarking for evolving corpora (IR, enterprise search)
- What: Evaluate retrievers and query planning under sequential, uncertain evidence (agentic multi-hop search vs single-query baselines).
- Tools/products/workflows: Side-by-side retriever bake-offs; ReasonIR-style training and diagnostics; “agentic search” playbooks for dynamic evidence.
- Assumptions/dependencies: High-quality, deduplicated, timestamped corpora; semantic embeddings and keyword indexes; latency budgets for multi-step retrieval.
- Education and training in forecasting and uncertainty (education, public sector)
- What: Course modules and workshops where students/operators update forecasts daily, learn calibration, and analyze overconfidence and anchoring.
- Tools/products/workflows: Classroom FutureSim instances; Brier Skill Score labs; memory and search exercises; comparison to human aggregates (e.g., Polymarket) where available.
- Assumptions/dependencies: Curated, age-appropriate datasets; assessment rubrics; privacy-safe deployments.
- Quant/product research on cost-effective inference scaling (finance, software)
- What: Use FutureSim to determine ROI of test-time compute (reasoning effort, tool-call budgets) for forecasting tasks; establish guidelines for when “more thinking” pays off.
- Tools/products/workflows: Budgeted inference policies; autoscaling of effort by event difficulty; post-hoc calibration layers.
- Assumptions/dependencies: Transparent cost tracking; stable model APIs; ability to control reasoning effort.
- Multi-agent ensemble diagnostics (finance, product, research)
- What: Run “agent committees” with aggregation and peer scoring to measure convergence/diversity, replacing ad-hoc ensembling heuristics.
- Tools/products/workflows: Prediction aggregation services; TV-distance drift monitors; peer-score incentives for diversity.
- Assumptions/dependencies: Careful prompt design to avoid herding; aggregation rules tuned to task; shared view of accessible context.
- Safety and reliability auditing for overconfidence, memory drift, and anchoring (AI safety, compliance)
- What: Detect harmful patterns (e.g., self-conditioning on prior rationales, persistent anchoring to bad priors, overconfident wrong answers).
- Tools/products/workflows: Audit reports with traces; “confidence guardrails” that throttle or flag updates; memory hygiene policies.
- Assumptions/dependencies: Full trace logging; answer-matching reliability; governance acceptance of calibration-based gating.
- Domain transfer with timestamped corpora (legal, enterprise, scientific literature)
- What: Replay domain-specific timelines (e.g., regulatory filings, earnings reports, court dockets, arXiv) to assess domain-adaptation and forecastability.
- Tools/products/workflows: Domain question curation (Curating-the-Future recipe); domain retriever tuning; domain-specific resolution/answer-matching prompts.
- Assumptions/dependencies: Access to reliably dated, licensable corpora; clear resolution criteria; SME oversight.
Long-Term Applications
The following opportunities likely require further research, scaling, data partnerships, or methodological advances before robust deployment.
- Live ForecastOps integrated with proprietary and real-time feeds (enterprise, finance, policy)
- What: Continuous, production-grade forecasting systems that fuse news, social media, filings, sensors, and internal telemetry with test-time training to adapt on the fly.
- Tools/products/workflows: Streaming retrieval; on-the-job learning via test-time training/continued pretraining; automated resolution ingestion; human-in-the-loop adjudication.
- Assumptions/dependencies: Access to high-freshness, licensed streams (including social media); reliable real-time dating; robust guardrails against performative feedback loops.
- Regulatory standards for adaptive AI evaluation and procurement (policy, governance)
- What: Formalize “long-horizon adaptation tests” (e.g., FutureSim-like) as part of AI compliance, reporting calibration, overconfidence rates, memory safety, and adaptation from poor priors.
- Tools/products/workflows: “Adaptive Maturity Model” benchmarks; third-party evaluation services; standardized calibration metrics and reporting templates.
- Assumptions/dependencies: Policy consensus; sector-specific test suites; secure sandboxes for sensitive models.
- Decision support and early warning systems with calibrated forecasts (public sector, NGOs, energy)
- What: Early alerts for geopolitical risk, humanitarian crises, grid incidents, or supply chain disruptions with probability trajectories and provenance.
- Tools/products/workflows: Event-specific simulators (conflict, migration, extreme weather); escalation playbooks tied to probability thresholds; fusion with satellite/IoT data.
- Assumptions/dependencies: High-quality domain data and resolution pipelines; careful treatment of performative effects; ethical deployment and oversight.
- Domain-specific “world replays” beyond news (healthcare, cybersecurity, robotics, science)
- What: Chronological simulations for clinical trial milestones and FDA decisions; CVE disclosures and exploits; field robot incident logs; reproducibility and discovery events in science.
- Tools/products/workflows: Domain curation pipelines; domain answer-matching taxonomies; stakeholder-in-the-loop resolution; sector-tuned memory/search tools.
- Assumptions/dependencies: Access to dated, auditable domain corpora; domain validators; sensitive data governance.
- Multi-agent markets and governance primitives (finance, Web3, enterprise decision making)
- What: Structured markets/committees of agents that produce, trade, and reconcile forecasts with incentives for diversity and calibration.
- Tools/products/workflows: Mechanism design for peer/peerless scoring; aggregation policy learning; dispute resolution protocols; guardrails vs collusion/herding.
- Assumptions/dependencies: Regulatory clarity for AI agents in markets; robust evaluation of manipulation risk; resilient aggregation infrastructure.
- Self-improving agent harnesses and memory architectures (software R&D)
- What: AutoHarness/autoresearch systems that iteratively refine prompts, tools, memory schemas, and search strategies to close the observed adaptation gap.
- Tools/products/workflows: Meta-optimization loops; memory versioning/garbage collection; anchoring detection and correction; uncertainty-aware search planners.
- Assumptions/dependencies: Large-scale, long-horizon experiment infrastructure; careful evaluation to avoid overfitting; availability of diverse replays.
- Advanced retrieval for dynamic, uncertain evidence (IR, ML)
- What: Retrievers that jointly reason about temporal evolution, uncertainty, and conflicting sources; active retrieval that adapts queries to forecast needs.
- Tools/products/workflows: Temporal retriever training (ReasonIR variants); Bayesian retrieval policies; provenance- and conflict-aware ranking; multi-day evidence synthesis.
- Assumptions/dependencies: Training data with temporal structure; evaluation suites with evolving corpora; compute budgets for iterative retrieval.
- Personal “news-to-forecast” assistants with transparent uncertainty (consumer, prosumer)
- What: Daily briefings that attach calibrated probabilities and rationale to events relevant to a user’s context (travel, investments, civic engagement), with learning from outcomes.
- Tools/products/workflows: Preference-conditioned question selection; local memory and privacy-preserving logs; opt-in sharing to community aggregates.
- Assumptions/dependencies: UX for communicating uncertainty; privacy and consent; expectation management and disclaimers.
- AI safety gates that stress-test overconfidence and anchoring before deployment (cross-sector)
- What: Preflight “adaptation gauntlets” that verify an agent can recover from bad priors, avoid self-conditioning traps, and maintain calibration under shifting context.
- Tools/products/workflows: Adversarial initializations; counter-anchoring prompts; memory ablations; automated audits tied to release decisions.
- Assumptions/dependencies: Rich libraries of failure-inducing replays; standardized accept/reject criteria; integration with CI/CD for AI systems.
- Economic research and policy experiments on performativity and information design (academia, regulators)
- What: Use controlled replays to study when predictions remain non-performative vs become performative, informing market design and disclosure policies.
- Tools/products/workflows: Hybrid labs combining replay and small live trials; measurement of feedback loops; interventions on information timing and framing.
- Assumptions/dependencies: Careful causal designs; ethics approvals; partnerships with platforms and agencies.
In both categories, a recurring constraint is the need for reliably timestamped, licensable corpora; robust answer matching for free-form outcomes; sandboxing to prevent future information leakage; and sufficient compute and orchestration quality to realize the intended gains in long-horizon adaptation.
Glossary
- Ablation: A controlled removal or modification of components to isolate their effect on performance. "Through careful ablations, we show how \ offers a realistic setting to study emerging research directions like long-horizon test-time adaptation, search, memory, and reasoning about uncertainty."
- Agent harness: The orchestration of tools, code, and prompts that structure how a model interacts with an environment. "We evaluate all models in their recommended harness at maximum reasoning effort over 3 seeds."
- Agentic search: Iterative, self-directed information seeking where the agent plans and refines queries to gather evidence. "we ablate full agentic search over the evolving corpus in the simulation in two key ways"
- Answer matching: An evaluation method that uses a LLM to determine if a free-form predicted outcome matches the ground truth. "We use LLM-based answer matching to check if an outcome o matches the ground-truth y_q."
- Brier score (multi-category): A generalization of the Brier score measuring the mean squared error between a probability distribution over multiple outcomes and the realized outcome. "adapting the existing multi-category Brier score"
- Brier Skill Score (BSS): A skill-normalized measure of probabilistic accuracy (higher is better), comparing forecasts to a baseline and rewarding calibrated, accurate probabilities. "we define Brier Skill Score to incorporate that by adapting the existing multi-category Brier score"
- Calibration: The alignment between predicted probabilities and actual frequencies of events. "Qwen3.6 Plus even deteriorates in calibration in its recommended OpenCode harness."
- Common Crawl News (CCNews): A corpus of reliably dated news article snapshots used as time-stamped context for evaluation. "We use Common Crawl News as it provides reliably dated snapshots of news articles"
- Context window: The fixed-size token span a LLM can attend to at once; managing it may require compaction or summarization. "12.4M tokens spanning multiple sequential context window compactions in a single run"
- Deduplicated snapshot: A dataset preprocessed to remove duplicate items, improving retrieval quality and efficiency. "The search corpus is a deduplicated snapshot of CCNews containing 7.36M articles"
- Frontier models: The most capable, cutting-edge AI models available at a given time. "open-weight frontier models have a negative Brier skill score"
- Ground-truth: The actual, verified outcome used to score predictions. "obtain ground-truth feedback on some questions"
- Hybrid semantic + keyword search: A retrieval approach combining embedding-based semantic matching with exact keyword matching. "we provide access to a hybrid semantic + keyword search tool over the news corpus"
- Inference-time memory: External memory written and retrieved during inference to persist information across long horizons. "we find models clearly benefit from inference-time memory."
- Knowledge cutoff: The latest point in time reflected in a model’s training data, beyond which it lacks built-in knowledge. "predict world events beyond the underlying LLM's knowledge cutoff."
- LanceDB: A vector database used to power semantic retrieval over embeddings. "implemented using LanceDB"
- Long-horizon: Spanning extended periods and requiring sustained adaptation and memory over many steps. "adapt over a long-horizon in dynamic environments"
- Multi-agent (dynamics): The study of interactions among multiple agents that influence each other’s behavior and predictions. "we hope \ supports multi-agent research, such as improvements from self-play"
- Peer score: A scoring mechanism that evaluates an agent relative to other agents’ predictions. "This is despite prompting agents that they will be graded on the peer score, which incentivizes distinct informative predictions from the crowd aggregate."
- Prediction markets: Markets where participants trade contracts tied to outcomes, producing crowd-aggregated probabilistic forecasts. "evaluate agents through live trading on prediction markets like Kalshi and Polymarket."
- Proper scoring rule: A scoring function that incentivizes honest probability reporting by being maximized when forecasts reflect true beliefs. "we prove that this is a proper scoring rule."
- Sandbox (agent sandboxing): An isolated execution environment that restricts access to prevent information leakage or unintended side effects. "we carefully sandbox agents"
- Search corpus: The collection of documents available for retrieval during the task. "The search corpus is a deduplicated snapshot of CCNews"
- Self-conditioning: A model behavior where it conditions on or over-trusts its own prior outputs or rationales, potentially causing overconfidence. "Across models, we observe instances of ``self-conditioning''"
- Semantic search: Retrieval based on vector embeddings that capture meaning rather than exact token matches. "a single semantic search query using the question title"
- Test-time adaptation: Updating predictions or strategies during deployment as new information arrives, without retraining the base model. "long-horizon test-time adaptation"
- Test-time compute: The computational budget and processing used during inference (e.g., more reasoning steps or tool calls). "scaling test-time compute can provide beneficial gains in performance"
- Top-1 accuracy: The fraction of cases where the single most probable predicted outcome matches the realized outcome. "with GPT 5.5 performing the best in both top-1 accuracy and Brier skill score."
- TV distance (Total variation distance): A metric of dissimilarity between probability distributions, often used to compare forecasts. "We provide details on aggregate prediction, peer score and TV distance computation in ~\Cref{app:multiagentaggtv}."
Collections
Sign up for free to add this paper to one or more collections.

