- The paper introduces a novel two-stage framework combining ReSim and Dyna-GRPO to enhance AI agents' simulation-derived reasoning and decision-making.
- ReSim constructs structured search trees from actual interactions, enabling more accurate predictions and improved task planning in complex environments.
- Dyna-GRPO iteratively refines policies using real rollouts and reward feedback, leading to superior performance in long-horizon and planning-intensive tasks.
Dyna-Mind: Learning to Simulate from Experience for Better AI Agents
Introduction
"Dyna-Mind: Learning to Simulate from Experience for Better AI Agents" proposes an innovative framework aimed at enhancing the reasoning and decision-making capabilities of AI agents in complex environments. The framework is motivated by insights from human cognition that emphasize the importance of mental simulations for effective planning and action selection. The paper highlights the limitations of current AI models in long-horizon tasks and introduces a two-stage training framework that explicitly incorporates simulation into the reasoning processes of AI agents.
Dyna-Mind Framework
The core contribution of Dyna-Mind lies in its two-stage training methodology:
- Reasoning with Simulations (ReSim): In the first stage, ReSim employs a structured approach to train agents using expanded search trees built from real experiences. This method allows the AI to ground its reasoning in actual world dynamics and anticipate future states. The simulation traces generated through ReSim leverage structured reasoning from these search trees, thus enabling better task planning and execution.
- Dyna-GRPO: In the second stage, the paper introduces Dyna-GRPO, an advanced reinforcement learning (RL) technique. This approach strengthens the agent's simulation and decision-making abilities by utilizing both outcome rewards and intermediate states as feedback during real rollouts. Dyna-GRPO iteratively improves policy and world model simulations, optimizing the agent's performance in planning-intensive tasks.
The integration of ReSim and Dyna-GRPO establishes a comprehensive framework for improving simulation-derived reasoning in AI agents, addressing current deficiencies in complex task environments.
Empirical Evaluation
The framework was evaluated using two synthetic benchmarks, Sokoban and ALFWorld, as well as the realistic AndroidWorld benchmark. Key findings include:
- Enhanced Simulation Ability: ReSim significantly improved the simulation abilities of AI agents, as demonstrated by superior task completion rates in both Sokoban and ALFWorld. By directly learning from real-world interactions, the agent's reasoning took into account more accurate representations of world dynamics.
- Improvement through Dyna-GRPO: The addition of Dyna-GRPO further bolstered the agent's competencies, particularly in long-horizon and planning-intensive tasks. The iterative policy refinement through real and simulated rollouts proved effective in yielding better long-term task execution strategies.

Figure 1: ReSim integrates simulation into reasoning by using expanded search trees built through real environment interactions.
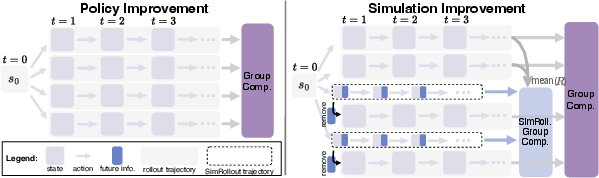
Figure 2: Dyna-GRPO iterates between policy improvement and world model improvement, optimized by GRPO.
Implications and Future Work
The results underline the crucial role of simulation in AI reasoning and planning. By embedding simulation within the framework of AI agents, there is a marked improvement in their ability to navigate and perform complex tasks that require strategic foresight and adaptability.
Advancing toward more interactive and adaptable AI agents, future work could explore enhancing the framework's scalability to broader domains and refining the integration of diverse environmental dynamics. Furthermore, extending this framework to incorporate additional sensory inputs and interaction modalities could further enhance agent performance in multifaceted applications.
Conclusion
Dyna-Mind represents a significant step forward in aligning AI agent capabilities with the intricacies of real-world environments. By leveraging robust simulation strategies within a structured training methodology, the framework offers a comprehensive approach to enhancing AI reasoning and planning capabilities, paving the way for the next generation of autonomous agents.