Scaling Open-Ended Reasoning to Predict the Future
Abstract: High-stakes decision making involves reasoning under uncertainty about the future. In this work, we train LLMs to make predictions on open-ended forecasting questions. To scale up training data, we synthesize novel forecasting questions from global events reported in daily news, using a fully automated, careful curation recipe. We train the Qwen3 thinking models on our dataset, OpenForesight. To prevent leakage of future information during training and evaluation, we use an offline news corpus, both for data generation and retrieval in our forecasting system. Guided by a small validation set, we show the benefits of retrieval, and an improved reward function for reinforcement learning (RL). Once we obtain our final forecasting system, we perform held-out testing between May to August 2025. Our specialized model, OpenForecaster 8B, matches much larger proprietary models, with our training improving the accuracy, calibration, and consistency of predictions. We find calibration improvements from forecasting training generalize across popular benchmarks. We open-source all our models, code, and data to make research on LLM forecasting broadly accessible.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Explaining “Scaling Open-Ended Reasoning To Predict the Future” in Simple Terms
Overview: What is this paper about?
This paper is about teaching AI LLMs to make smart, realistic predictions about future events—like who might win an election, which company will make a big move, or where a summit will happen. The authors build a system called OpenForecaster that learns to forecast open-ended questions (not just yes/no), and they show how to train it safely and fairly using news articles—without “cheating” by looking up answers after the fact.
What questions were the researchers trying to answer?
The team focused on a few big questions:
- How can we train AI to make better, detailed predictions about the future, not just yes/no answers?
- How can we collect lots of good training data without waiting for people to write questions by hand?
- How do we avoid “future leaks” (accidentally giving the model info that wasn’t known at the time)?
- What training strategy makes the model both accurate and honest about its confidence?
How did they do it? (Methods in everyday language)
The researchers built a full pipeline to train and test forecasting models. Here’s how it worked, with simple explanations of the key ideas:
- Creating questions from news
- They took thousands of news articles and asked one AI model to write forecast questions like, “Who will be confirmed as the new prime minister of Country X by [date]?”
- Each question comes with a short answer (usually a name or place), a resolution date, and where to check the answer.
- Another AI model checked and cleaned the questions to make sure:
- They really ask about the future.
- The answer can be found later from a trusted source.
- The question doesn’t include hints that give away the answer (like directly naming the person in the question text).
- Avoiding “time travel” (no future info)
- The team only used a frozen, offline news archive (CCNews) that stores monthly snapshots of the news. This prevents the model from seeing later updates.
- When retrieving helpful articles for a question, they only allowed articles published at least one month before the question’s resolution date.
- Teaching the model to use evidence (retrieval)
- Before answering a question, the model is given a few short, relevant chunks of news it might not “remember” from its training. This is like giving a student a small stack of study notes that were available at the time.
- Training the model with rewards (reinforcement learning)
- Reinforcement learning (RL) is like giving points for good predictions.
- Two kinds of “points” (rewards) matter:
- Accuracy: Did the model’s answer match the real-world outcome?
- Calibration: Was the model honest about how sure it was?
- They used a scoring method (a version of the Brier score) that rewards being right and confidently right, and penalizes being wrong and overly confident.
- Their best approach combined both: reward for accuracy + reward for good calibration.
- Simple analogy: You get points for getting the answer right, and extra points if your confidence was appropriate. If you brag with 99% confidence and are wrong, you lose more points. If it’s a tough question and you say “I’m only 30% sure,” you’re not punished for being careful.
- Checking results fairly (testing)
- They trained on news up to April 2025 and only tested on questions that resolved from May to August 2025.
- They built a fresh test set from different news sources than training and manually verified quality.
- They also tested on an external benchmark (FutureX) and checked whether calibration improvements carried over to other tasks (like science and general knowledge questions).
Key terms explained:
- Open-ended question: You must write the answer (like a name), not pick A/B/C.
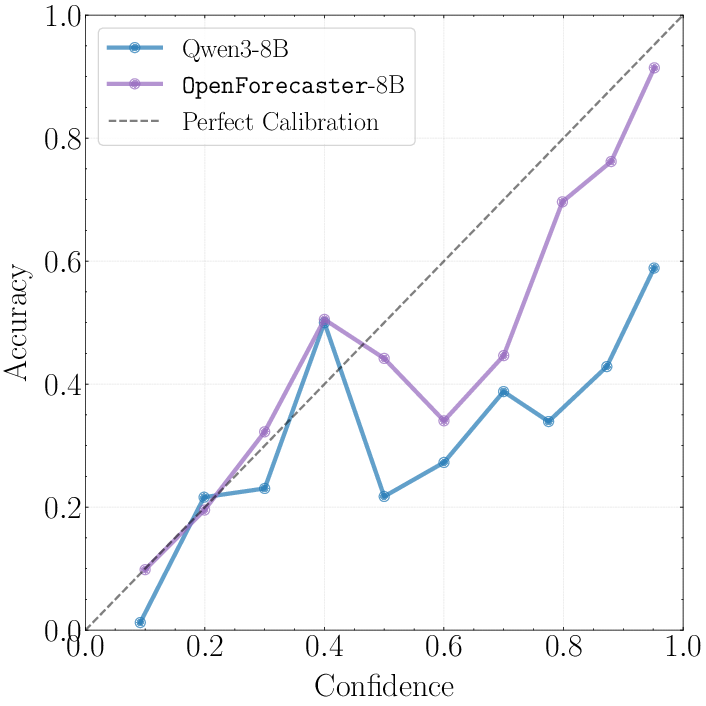
- Calibration: How well your confidence matches reality. If you say “70% sure” across many questions, about 70% should be right.
- Brier score: A way to score predictions that balances being right and being honest about confidence.
- Retrieval: Finding and attaching relevant, older news articles to help the model reason.
- Leakage: Accidentally using information that wasn’t known at the time of prediction.
- Knowledge cutoff: The last date of data the model saw during its base training.
What did they find, and why is it important?
- Training data made from news works—and scales
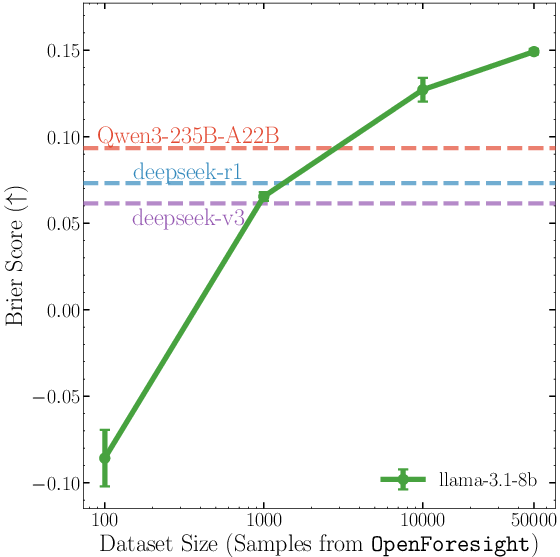
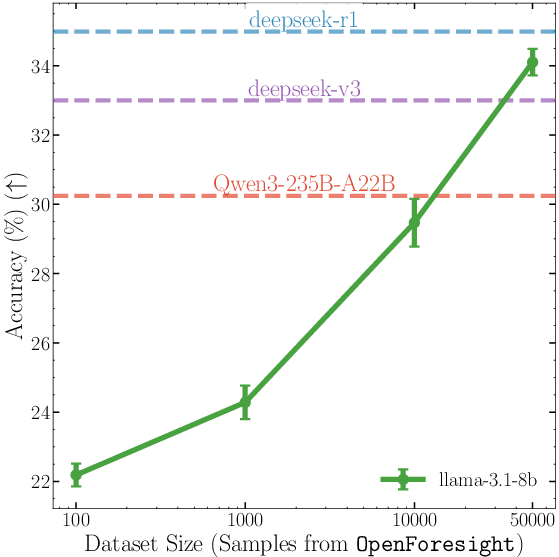
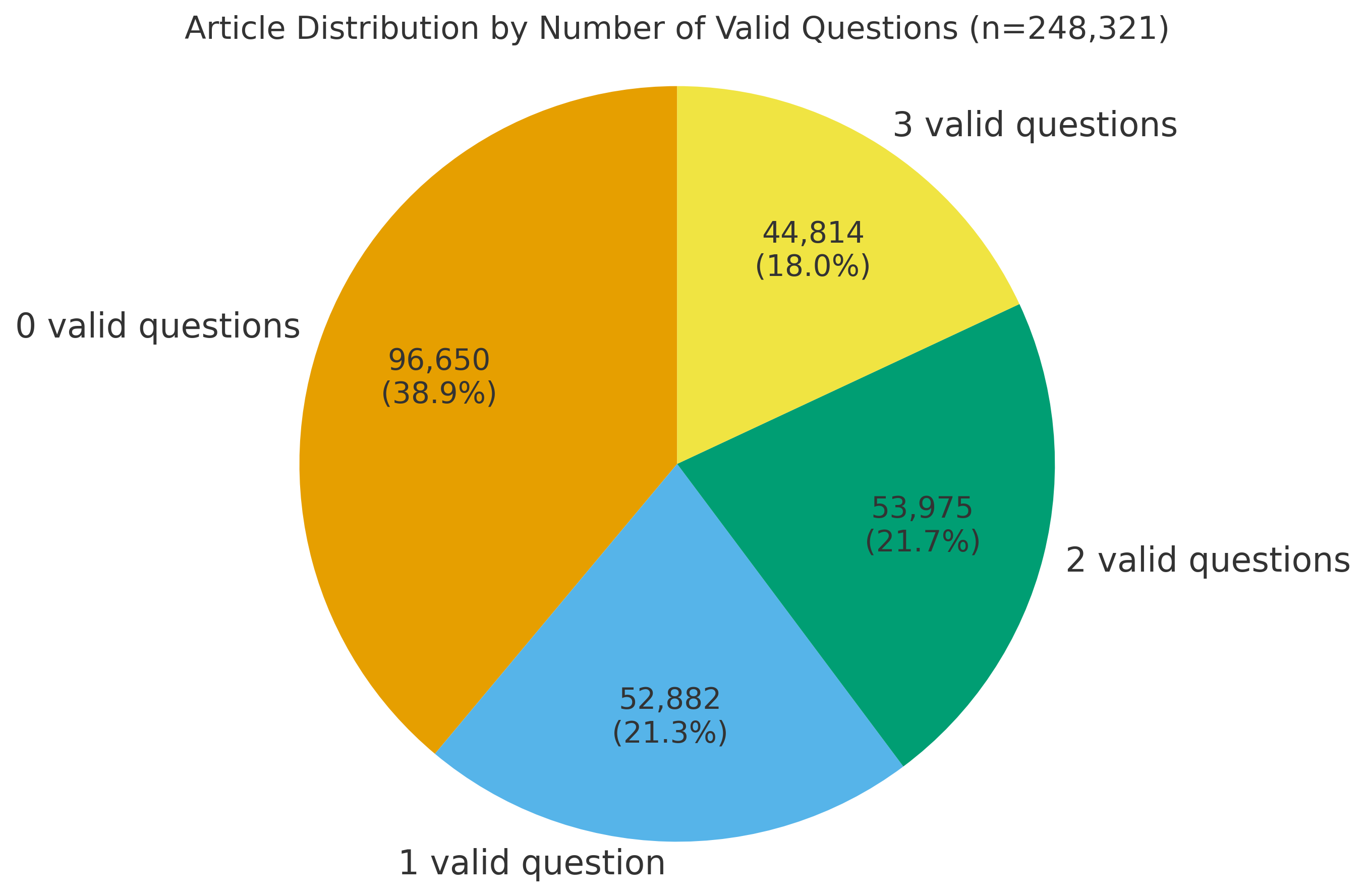
- They created a large dataset called OpenForesight (about 52,000 high-quality, open-ended forecasting questions).
- Carefully filtering out “leaky” or unclear questions made a big difference—bad or “spoiled” data could actually make the model worse.
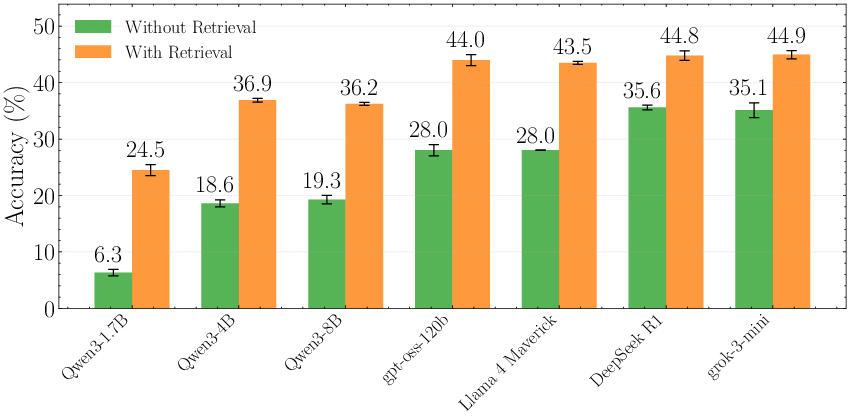
- Retrieval helps a lot
- Giving the model a handful of relevant news snippets (from the allowed time window) boosted accuracy noticeably across different models.
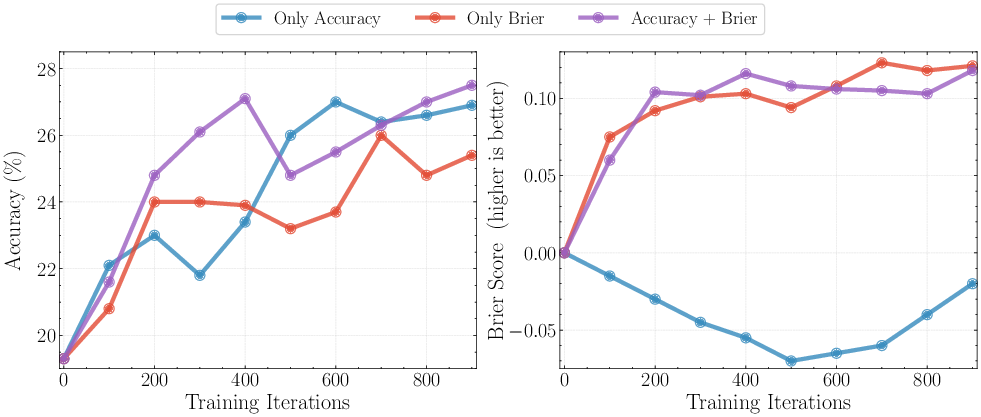
- The best reward design mixes accuracy + calibration
- Training with accuracy alone made the model overconfident (poor calibration).
- Training with calibration alone made the model too timid on hard questions.
- Combining them gave the best results—more correct answers and more honest confidence.
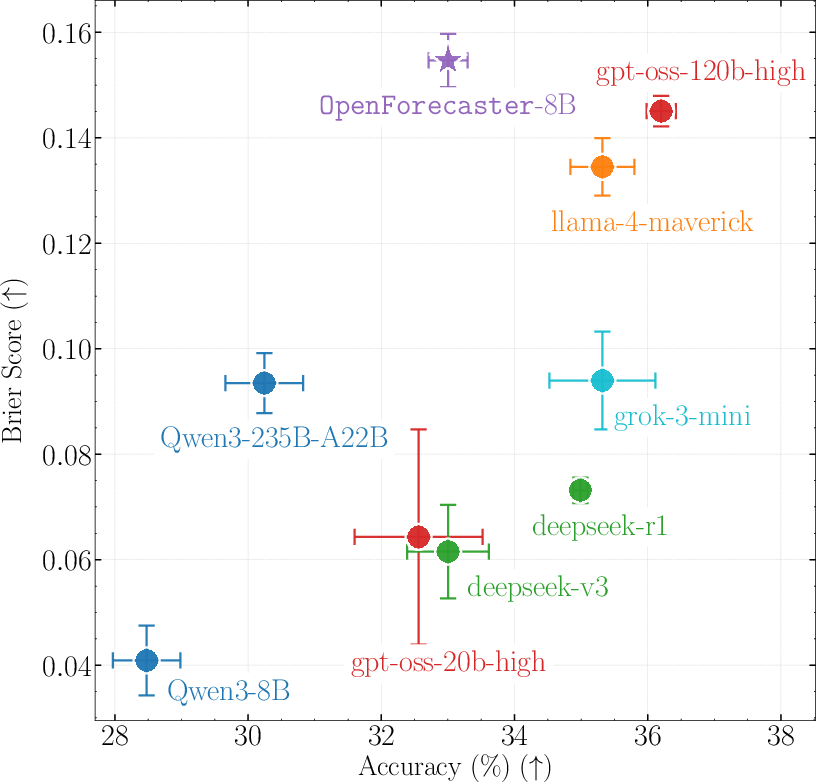
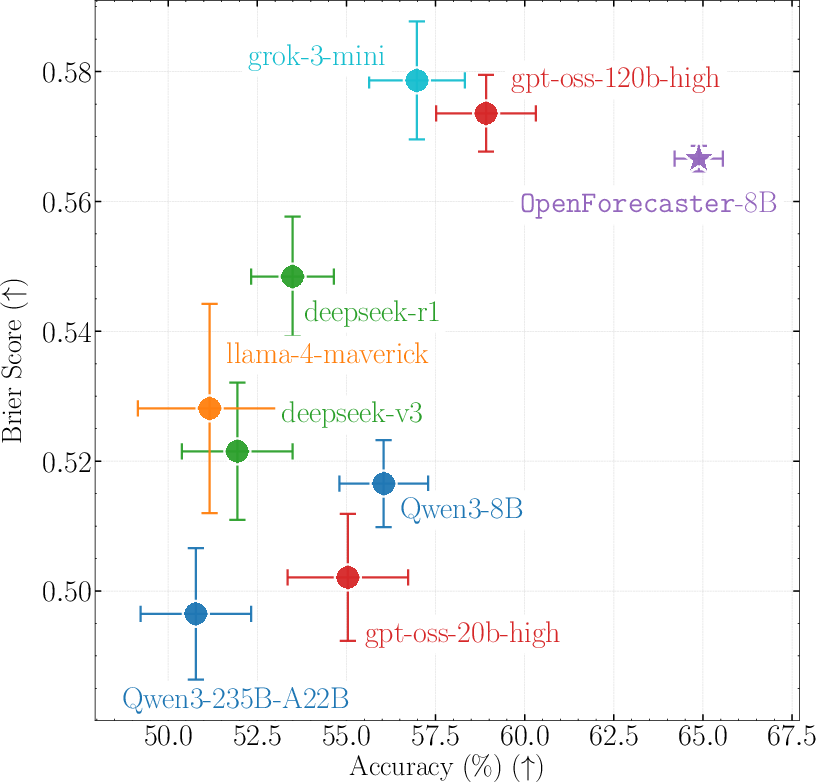
- Their 8B model competes with much larger models
- The specialized model, OpenForecaster 8B, matched or beat much bigger, proprietary models on key measures—especially on the combined score that matters for forecasting (Brier score).
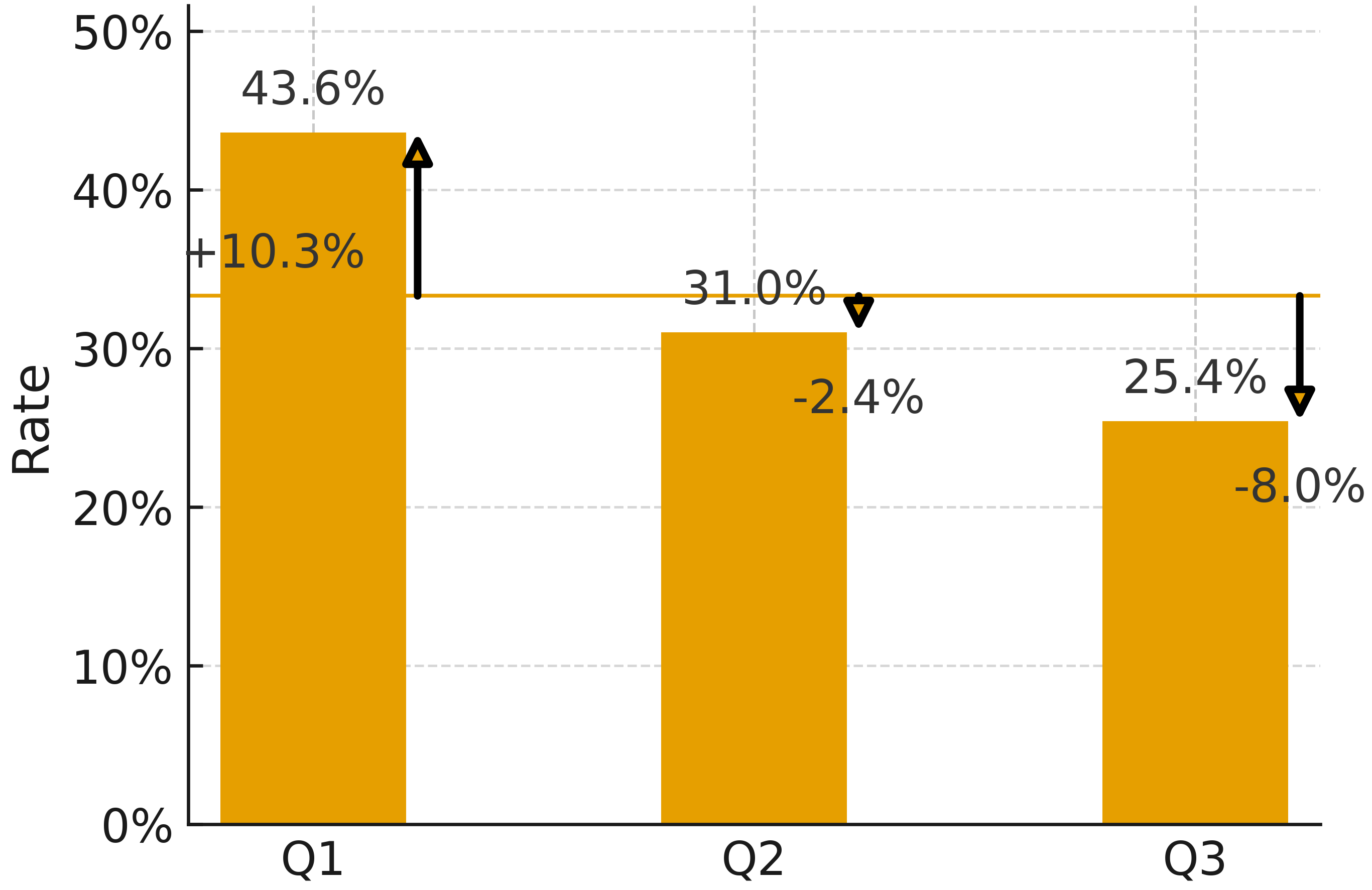
- It also made more consistent long-term predictions.
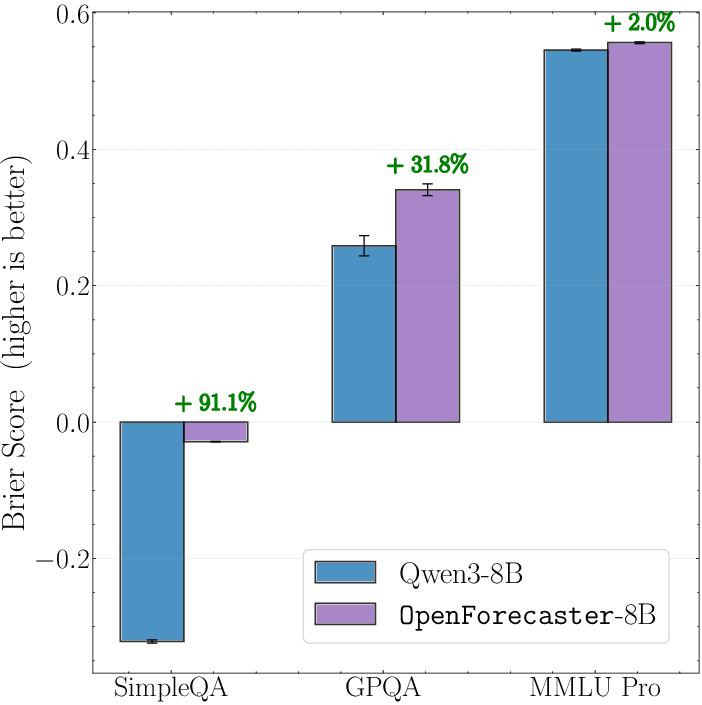
- Calibration improvements carry over
- After forecasting training, the model became better calibrated on other tough benchmarks too (like tricky science/fact questions), which means fewer “confidently wrong” answers.
What’s the bigger impact?
This work shows a practical way to build forecasting AIs that can:
- Make open-ended, realistic predictions about world events.
- Use recent, reliable information without cheating.
- Tell you how sure they are—and mean it.
Why this matters:
- Governments, companies, and scientists often need to make decisions under uncertainty. Better forecasts (and better honesty about confidence) can lead to smarter choices.
- The team released their code, data, and models publicly, which helps others build on this work and makes research more fair and transparent.
A few limitations to keep in mind:
- The questions are based on news, which can be biased or late to report some events (like science breakthroughs).
- The paper focuses on short answers (like names), not long essays or multi-step plans.
Still, this is a strong step toward AI systems that can think ahead in a careful, grounded way—and explain how sure they are while doing it.
Knowledge Gaps
Unresolved Gaps, Limitations, and Open Questions
Below is a focused list of what remains missing, uncertain, or unexplored, organized to help future researchers act on it.
Data and Question Generation
- Coverage bias from news-only sourcing: the training and test questions are drawn exclusively from English-language mainstream news, underrepresenting scientific, technical, local, and niche domains, as well as regions with less English news coverage; quantify topic/geography skew and develop methods to diversify sources (e.g., multilingual CCNews snapshots, preprints, policy docs, filings).
- Exclusion of numeric/continuous outcomes: the pipeline filters out numeric answers, leaving gaps in modeling quantities (prices, counts, dates). Explore proper scoring rules and answer matching for continuous targets and confidence intervals.
- Resolution-date reliability for training data: for training, resolution dates are heuristically set to min(model_proposed_date, article_publish_date), and no robust earliest-resolution-date reconciliation is performed. Measure and correct label noise from late reporting and misaligned resolution dates at scale.
- Leakage beyond exact string matches: the leakage editing step primarily removes direct answer strings, but not indirect cues (paraphrases, initials, images, or structured hints). Develop semantic leakage detectors (e.g., paraphrase/alias detection, NER-based masking) and quantify remaining leakage rates.
- Ground-truth validation for training answers: “ground-truth answers” are extracted from articles, but systematic verification that each event truly resolved as stated (against a source of truth) is not reported. Build automated cross-source resolution verification to reduce label noise and track disagreement.
- Generator–selector model drift: training questions are created with DeepSeek v3 and filtered with Llama-4-Maverick, while validation/test use stronger models (o4-mini-high, Grok with search). Analyze whether changing generators/selectors induces distribution shifts that affect generalization or selection bias.
- Limited scale of offline retrieval corpus: the 1M-article corpus and choice of 60 sources may miss key evidence. Evaluate retrieval recall/coverage per question and scale the corpus (with deduplication, multilingual expansion), plus measure the marginal benefit of additional sources.
Evaluation and Benchmarking
- Short time horizon and limited test set size: held-out testing focuses on May–Aug 2025 with 302 questions. Extend evaluations to broader windows, longer horizons (multi-month/year), and larger, category-balanced sets with resolution-date rigor.
- Lack of human baselines: no direct comparison to trained human forecasters or superforecasters on open-ended questions. Establish head-to-head evaluations to contextualize LLM performance.
- Ambiguity handling and multi-correct answers: the pipeline removes ambiguous questions, but real events often have multi-entity or multi-valid-answer outcomes (e.g., co-chairs, joint winners). Develop grading and scoring protocols for multi-correct or partially correct answers.
- Calibration metrics beyond adapted Brier: while adapted Brier and calibration curves are reported, expected calibration error (ECE), proper log scores, or class-conditional calibration analyses are not explored. Compare scoring rules and calibration diagnostics for open-ended settings.
- Robustness to conflicting/misinformation: retrieval may contain contradictory or erroneous reports. Evaluate robustness under conflicting evidence and misinformation, and introduce adjudication/reconciliation strategies.
- Category-level performance analysis: limited error analysis by topic (politics, science, corporate, sports). Provide stratified results to identify domains where models struggle and tailor improvements.
- Abstention and deferral policies: evaluation treats “Unknown” as incorrect and applies a simple probability threshold heuristic. Develop principled abstention/deferral scoring, including utility-aware decision rules and cost-sensitive evaluation.
Modeling and Training
- Single-guess probability modeling: models output one answer plus a single probability, which cannot represent uncertainty spread across multiple plausible candidates. Investigate top-k distributions, list predictions with normalized probabilities, and scoring rules for multi-hypothesis forecasts.
- Reward design trade-offs: the accuracy+Brier reward helps exploration, but the incentive compatibility for truthful probabilities under distribution shift remains unproven. Compare mixed rewards (e.g., log score, proper composite rules), and study their effects on exploration vs calibration.
- Outcome-only RL vs hybrid training: outcome-only GRPO may reinforce spurious patterns. Explore combining RL with supervised chains-of-thought (SFT), process-based feedback, DPO, or rationale-quality rewards to improve reasoning robustness.
- Impact on non-forecasting capabilities: while calibration generalizes to some benchmarks, broader capability drift (e.g., coding, math, safety) is untested. Conduct comprehensive post-training evaluations for catastrophic forgetting or unexpected trade-offs.
- Retrieval design ablations: chunk size (512), k=5, and Qwen embeddings are fixed with minimal ablation. Systematically vary chunking, retrievers (e.g., Contriever, ColBERT, cross-encoders), rerankers, and recency windows (1 week/1 month/3 months) to map accuracy/calibration trade-offs and leakage risk.
- Streaming updates and sequential forecasts: the system performs single-shot forecasts. Develop protocols and training/evaluation for iterative updating (Bayesian or learned), including time-series retrieval snapshots and learning to update beliefs.
- Long-form forecasts and grading: the paper explicitly excludes long-form forecasts due to unclear grading. Design grading frameworks (structured criteria, reference resolutions, rubric-based LLM+human hybrid grading) and proper scoring rules for multi-faceted narratives.
- Uncertainty representation and prompt sensitivity: mapping of textual prompts to numeric probabilities is under-specified. Ablate prompt designs, scaling laws for probability calibration, and instruction tuning for reliable numeric reporting.
Leakage, Contamination, and Cutoffs
- Base model cutoff uncertainty: Qwen3’s true training cutoff is unclear; the authors assume April 2025. Independently audit knowledge cutoffs and contamination risks, including post-cutoff knowledge present in weights, to ensure backtests remain clean.
- Static-snapshot fidelity: CCNews monthly snapshots can still contain updated content or incorrect timestamps. Quantify snapshot fidelity (update rates, timestamp correctness) and develop filters to exclude late-updated pages.
- Retrieval-window sufficiency: limiting retrieval to one month before resolution is heuristic. Systematically study leakage vs performance across different windows and adopt conservative, evidence-based policies.
Ethics, Safety, and Deployment
- Decision-making risks and misuse: the paper does not analyze how miscalibrated forecasts might mislead high-stakes decisions (policy, finance). Propose safety checks, uncertainty disclosures, and governance for use in consequential settings.
- Bias and fairness: forecasts on people/regions may reflect training biases (name transliteration, regional undercoverage). Audit demographic/geographic fairness, error disparities, and introduce mitigation strategies.
- Adversarial robustness: no study of adversarially crafted questions or poisoned articles. Evaluate and harden against adversarial inputs in retrieval and question phrasing.
Scaling and Systems
- Data scaling beyond ~52K: benefits of scaling are shown up to tens of thousands of samples but the saturation point and compute-efficiency trade-offs are unknown. Extend scaling studies (data size, compute budgets) to identify returns and diminishing gains.
- Infrastructure and latency: real-world forecasters need low-latency retrieval+generation. Characterize end-to-end latency, memory cost, and throughput, and explore systems optimizations (caching, incremental indexing).
These gaps define a concrete roadmap: improve dataset coverage and resolution rigor, enrich uncertainty modeling and scoring, broaden evaluation (human baselines, domains, horizons), deepen retrieval and reward ablations, and address safety, fairness, and deployment practicality.
Glossary
- Ablations: Systematic experiments that modify or remove components to assess their impact on performance. "We perform all ablations on a small validation set."
- Answer matching: Using a model or algorithm to judge whether a predicted short answer semantically matches the ground truth. "we use model-based answer matching"
- Arbitrage metrics: Consistency-based measures that detect contradictory probability assignments across related forecasts. "improving 44% on arbitrage metrics"
- Backtesting: Evaluating forecasting models on questions whose outcomes became known after the model’s training cutoff. "called backtesting"
- Bayesian updates: Rationally revising beliefs by incorporating new evidence according to Bayes’ rule. "make optimal Bayesian updates to its world model"
- Brier score: A proper scoring rule that measures the accuracy and calibration of probabilistic predictions. "Our Brier score is equivalent to the reward metric used by~\citet{damani2025beyond}."
- Calibration: The alignment between predicted probabilities and actual outcomes. "accuracy, calibration, and consistency of predictions."
- Calibration curve: A plot that compares predicted probabilities to observed frequencies to visualize calibration. "Calibration curve on our test set."
- Chain of thought (CoT): Step-by-step reasoning traces generated by a model to reach an answer. "by Supervised Finetuning (SFT) on chain of thought traces"
- CommonCrawl News (CCNews) corpus: A static archive of monthly snapshots of global news used to avoid data leakage. "the CommonCrawl News corpus, which provides static, monthly snapshots of global news."
- Consistency evaluations: Tests that assess whether a model’s forecasts remain coherent across time or related queries. "We also observe large improvements on consistency evaluations for long-term predictions"
- Consistency metrics: Quantitative measures that capture logical coherence of forecasts across related questions over time. "we measure consistency metrics on binary questions up to 2028"
- Dense retrieval: Embedding-based information retrieval that finds semantically relevant documents or chunks. "We use dense retrieval with the Qwen3-8B Embedding model"
- Distributional biases: Skews in data distributions that can mislead evaluation or training. "distributional biases of prediction market questions."
- Free-form responses: Open-ended textual answers not constrained to predefined categorical options. "for free-form responses"
- Group Relative Policy Optimization (GRPO): A reinforcement learning algorithm for LLMs that optimizes policies using outcome-based rewards. "Group Relative Policy Optimization (GRPO), an RL algorithm that only uses outcome rewards."
- Held-out test set: A dataset reserved and unseen during development for final, unbiased evaluation. "we report results on our held-out test set of open-ended forecasting questions"
- Judgemental forecasting: Forecasting based on human or natural-language judgments rather than strictly numerical time-series models. "also called judgemental forecasting"
- Knowledge cutoff: The latest date of information included in a model’s training data, after which events are unknown to the model. "the static knowledge cutoff of LLMs enables a unique opportunity:"
- Leakage (of future information): Unintended access to information about outcomes that should be unknown at prediction time. "To prevent leakage of future information during training and evaluation"
- Offline news corpus: A locally stored, time-stamped collection of articles used to avoid dynamic web updates that could leak answers. "we use an offline news corpus, both for data generation and retrieval in our forecasting system."
- Open-ended forecasting: Predicting outcomes where the answer space is not predefined and can be any short textual string. "open-ended forecasting questions"
- Open-weight models: Models whose weights are released for public use and inspection. "especially for open-weight models."
- Outcome-based reinforcement learning (RL): RL that relies on the final correctness of answers as the reward signal without intermediate supervision. "We train LLMs using outcome-based reinforcement learning on our dataset."
- Out-of-distribution benchmarks: Evaluations on tasks whose data distribution differs from that of training, testing generalization. "generalizes to multiple out of distribution benchmarks."
- Prediction markets: Platforms where participants trade contracts tied to event outcomes, producing aggregate probability forecasts. "Prediction markets provide a platform for online participants to register predictions"
- Proper scoring rule: A scoring function that incentivizes honest probability reporting by maximizing expected score at truthful beliefs. "They show this is a proper scoring rule"
- Resolution criteria: Formal rules specifying the source of truth, resolution date, and acceptable answer format for a forecasting question. "Resolution criteria: Fixes a source of truth, proposes a resolution date for the question, and the expected answer format."
- Semantic equivalence: Two textual answers expressing the same meaning despite surface differences. "using another LLM to test for semantic equivalence"
- Source of Truth: The authoritative reference used to judge the correctness of a forecasted outcome. "Source of Truth: Official announcement from the Verkhovna Rada (Ukraine's parliament) confirming the appointment, via parliamentary records or government press release."
- Supervised Finetuning (SFT): Training a model on labeled examples to refine its behavior for a specific task. "by Supervised Finetuning (SFT) on chain of thought traces"
- Time-series forecasting: Predicting numeric values over time based on historical sequences. "This differentiates it from both time-series forecasting, and prediction markets."
- Unknown unknowns: Unanticipated possibilities that are difficult to enumerate in advance. "unknown unknowns: possibilities not anticipated, and hard to enumerate."
Practical Applications
Practical Applications Derived from the Paper
Below, we group actionable applications of the paper’s findings and methods into two categories. Each item includes sectors, potential tools/products/workflows, and assumptions/dependencies that affect feasibility.
Immediate Applications
- Forecasting copilot for decision-makers — deploy a calibrated, retrieval-augmented assistant that provides open-ended forecasts (short answers plus probability) on near-term world events
- Sectors: policy (government, think tanks), finance (asset management, venture capital), corporate strategy (Fortune 500, SMEs), media
- Tools/products/workflows: OpenForecaster-8B; CCNews-based offline retrieval; accuracy + Brier reward–trained forecaster; forecasting dashboards with monthly backtests; governance workflows for review and sign-off
- Assumptions/dependencies: access to static, date-bounded news snapshots; domain coverage (news bias toward politics/business); human oversight for high-stakes use; legal compliance for data sources
- Calibration-as-a-service for existing LLM apps — fine-tune existing models on OpenForesight to improve confidence reporting and enable principled abstention
- Sectors: software (LLM platforms), enterprise AI, customer support, search/QA
- Tools/products/workflows: OpenForesight dataset; GRPO training with accuracy + Brier reward; application-level rules (e.g., “if p<0.1, respond ‘I do not know’”); A/B testing of hallucination reduction
- Assumptions/dependencies: compute for RL fine-tuning; compatibility with target model licenses; validation on domain-specific tasks
- Reproducible retrieval sandbox for forecasting research — standardize evaluations that avoid leakage using offline corpora and precise resolution windows
- Sectors: academia (ML/NLP, forecasting), AI evaluation labs, model providers
- Tools/products/workflows: CCNews snapshots; chunked dense retrieval (Qwen3-Embedding); date filters (≤1 month pre-resolution); open-source grading via answer matching
- Assumptions/dependencies: reliable timestamping; deduplication/coverage quality; shared evaluation protocols
- Internal corporate forecasting tournaments (open-ended) — run forecasting competitions on synthesized questions to train teams and benchmark human vs. model forecasters
- Sectors: corporate learning & development, risk offices, strategy units
- Tools/products/workflows: question-generation pipeline; Brier scoring; answer matching; leaderboards; incentive design
- Assumptions/dependencies: curated, context-relevant questions; well-defined resolution criteria; legal/privacy review
- Supply chain and compliance risk watchlists — generate short-answer forecasts for regulatory actions, leadership changes, sanctions, or policy shifts affecting suppliers and markets
- Sectors: manufacturing, logistics, pharma, energy, financial compliance
- Tools/products/workflows: retrieval from diverse news sources; entity-level alerts; probability thresholds; escalation workflows
- Assumptions/dependencies: regional news coverage; multilingual adaptation for global operations; periodic recalibration
- Investment research copilot (event-driven) — support analysts with open-ended predictions for corporate events (M&A targets, executive appointments, policy decisions) backed by retrieved evidence
- Sectors: finance (sell-side/buy-side research), PE/VC, corporate treasury
- Tools/products/workflows: forecaster integrated in research notes; document links and time-bounded retrieval; monthly calibration audits
- Assumptions/dependencies: firm policies for AI use; model guardrails; clear disclaimers; potential market impact concerns
- Editorial planning and newsroom tooling — guide topic selection and resource allocation with probability-weighted forecasts of upcoming events
- Sectors: media/journalism
- Tools/products/workflows: forecasting briefs; retrieval snapshots; assignment prioritization; post-resolution accuracy retrospectives
- Assumptions/dependencies: source diversity to mitigate bias; editorial standards; transparency about AI use
- Domain-specific forecasting training (energy, cybersecurity, education) — apply the reward design (accuracy + Brier) to domain corpora to improve calibrated event prediction
- Sectors: energy (policy/price actions), cybersecurity (breach disclosures), education (policy/curriculum changes)
- Tools/products/workflows: domain corpus creation with strict cutoff and leakage controls; RL training pipeline; domain evaluation suites
- Assumptions/dependencies: availability of dated, static corpora; subject-matter expert review; risk management
- Consistency auditing of long-term predictions — use consistency/arbitrage metrics to audit model forecasts on multi-year questions without retrieval
- Sectors: AI safety/governance, model providers, regulators
- Tools/products/workflows: consistency evaluation suite (frequentist/arbitrage metrics); periodic audits; reporting for model cards
- Assumptions/dependencies: standardized question sets; transparent evaluation artifacts; proper interpretation of metrics
- Forecast-ops data pipeline productization — package the paper’s question-generation, filtering, and leakage-fixing pipeline as a managed service/library
- Sectors: AI tooling vendors, enterprise data teams, research groups
- Tools/products/workflows: modular pipeline (generator + selector + leakage editor); policy-compliant news ingestion; CI/CD for dataset refreshes
- Assumptions/dependencies: licensing and robots.txt compliance; cost controls for generation; monitoring data quality
- Public-sector early alerts (non-sensitive OSINT) — generate short-answer forecasts for appointments, legislative votes, regulatory deadlines
- Sectors: local/national government, NGOs, international orgs
- Tools/products/workflows: forecaster-enabled briefings; resolution criteria tied to official sources; risk triage (“monitor vs. act” thresholds)
- Assumptions/dependencies: governance and accountability frameworks; broader coverage for non-English sources; ensure non-use on sensitive intel
- Personal decision support with calibrated abstention — everyday choices (e.g., travel disruptions, event confirmations) with probability and willingness to say “unknown”
- Sectors: consumer apps, personal productivity
- Tools/products/workflows: mobile companion; retrieval-limited forecasts; clear uncertainty communication
- Assumptions/dependencies: scope boundaries to avoid high-stakes domains; user education on probabilistic outputs
Long-Term Applications
- Real-time open-ended forecaster agent — continuously updates with versioned, provenance-tracked corpora; performs Bayesian-like updates; manages unknown unknowns with exploratory reasoning
- Sectors: cross-sector (policy, finance, enterprise), OSINT
- Tools/products/workflows: streaming ingestion with immutable snapshots; time-aware retrieval; ongoing RL updates; audit trails
- Assumptions/dependencies: scalable, compliant data infrastructure; robustness to shifting distributions; rigorous leak prevention
- Open-ended prediction markets augmented by LLMs — models propose candidate outcomes (not just binary) and calibrated probabilities; humans trade, critique, and refine
- Sectors: finance, civic tech, research communities
- Tools/products/workflows: market platforms supporting short-answer resolution; answer-matching adjudication; calibration leaderboards
- Assumptions/dependencies: legal/regulatory permissions; strong resolution governance; defenses against gaming/adversarial behavior
- Government early-warning systems (cross-lingual OSINT) — forecast geopolitical, regulatory, and public-sector appointments/actions for resource allocation
- Sectors: public policy, defense (non-classified), international development
- Tools/products/workflows: multilingual corpora; cross-source reconciliation; human-in-the-loop triage; red-teaming for failure modes
- Assumptions/dependencies: language/domain adaptation; fairness considerations; clear rules against sensitive/secret data use
- Strategic planning autopilots (“Forecast Ops”) — institutionalize calibrated, retrieval-augmented forecasting in quarterly/annual planning and scenario exercises
- Sectors: enterprise strategy, consulting
- Tools/products/workflows: scenario generation; probability-weighted roadmaps; risk heatmaps; post-mortem loops to retrain
- Assumptions/dependencies: executive buy-in; robust change management; evaluation to avoid anchoring or automation bias
- Autonomous research portfolio selection — forecast which research directions or grant proposals are most likely to yield breakthroughs or outcomes by specific dates
- Sectors: academia, R&D labs, funding agencies
- Tools/products/workflows: domain-specific datasets (journals, preprints, patents); calibrated forecaster; panel review integration
- Assumptions/dependencies: careful resolution criteria for scientific outcomes; avoid using leaked confirmations; ethics of influence on research agendas
- Public health policy forecasting (non-clinical) — predict administrative decisions (e.g., approvals, mandates) or logistics-related milestones
- Sectors: healthcare policy, public administration
- Tools/products/workflows: curated regulatory/news corpora; resolution via official announcements; dashboards for health agencies
- Assumptions/dependencies: strict scope boundaries (no clinical advice without evidentiary models); transparency and oversight
- Financial risk engines with calibrated event prediction — integrate event-forecast modules into enterprise risk models (e.g., policy changes, sanctions, leadership exits)
- Sectors: banking, insurance, corporate treasury
- Tools/products/workflows: model APIs for risk inputs; probability-to-loss mappings; stress testing across scenarios
- Assumptions/dependencies: regulatory compliance; auditability; careful handling of market-moving outputs
- Education system planning and accreditation forecasting — anticipate policy shifts, curriculum changes, accreditation decisions and timelines
- Sectors: education policy, universities, certification bodies
- Tools/products/workflows: education-specific corpora; periodic planning cycles; transparency reports
- Assumptions/dependencies: coverage of localized policy sources; adaptation to legal frameworks; stakeholder engagement
- Multi-modal forecasting expansion (text + tables/time-series) — combine the paper’s open-ended question approach with structured data for richer event prediction
- Sectors: energy (demand/supply + policy), climate-risk (events + measurements), logistics (operations + regulations)
- Tools/products/workflows: multi-modal retrieval; hybrid training objectives (Brier + domain metrics); answer matching across formats
- Assumptions/dependencies: reliable data integration; consistent timestamps; new evaluation protocols
- Standards for calibrated AI reporting — formally adopt Brier-based confidence reporting and abstention policies across AI products, with external audits
- Sectors: software platforms, AI governance, regulators
- Tools/products/workflows: calibration benchmarks; model cards with consistency metrics; third-party attestations
- Assumptions/dependencies: industry consensus; standardized scoring and resolution criteria; alignment with regulatory frameworks
Notes on Feasibility and Dependencies
- Avoiding leakage is central: use static, dated corpora (e.g., CCNews), enforce pre-resolution retrieval windows, and audit pipelines.
- Coverage biases in news mean forecasts skew toward reported domains; diversify sources (language, region, topic) for broader applicability.
- Open-ended grading depends on robust answer matching; adopt independent adjudication models and manual checks for sensitive deployments.
- RL training with accuracy + Brier improves both correctness and calibration; scaling data continues to help but requires compute and careful governance.
- Human-in-the-loop review remains necessary for high-stakes policy, financial, and public-sector use; treat outputs as decision support, not automated decisions.
Collections
Sign up for free to add this paper to one or more collections.