- The paper introduces TabPFN-3, leveraging a synthetic SCM prior to pretrain on datasets up to 10^6 rows, achieving state-of-the-art performance.
- The paper details architectural innovations including row-chunked inference and KV-cache compression to reduce memory usage and boost scalability.
- The paper empirically demonstrates superior performance on benchmarks, outperforming gradient boosting pipelines and prior models in both accuracy and speed.
TabPFN-3: A Technical Assessment of Architectures and Scaling for Tabular Foundation Models
Introduction and Context
TabPFN-3 represents a significant advance in the design and scaling of tabular foundation models, optimizing both predictive performance and inference efficiency across a wide spectrum of tabular machine learning tasks. The approach leverages synthetic pretraining entirely via a Structural Causal Model (SCM) prior, scaling state-of-the-art (SOTA) in-context learning (ICL) transformer architectures to support datasets of up to 106 training rows. The methodology includes substantial modifications in the preprocessing pipeline, a reformulation of the inference bottlenecks through row-chunking and KV-cache compression, and an attention-based non-parametric decoder for multi-class prediction.
Architectural Advances and Synthetic Pretraining Pipeline
TabPFN-3 adopts a multi-stage architecture inspired by advances in both prior TabPFN versions and the TabICLv2 framework. The model reinstates full row-level ICL (eschewing alternating attention and per-cell processing from TabPFN-2.x) to enable efficient quadratic scaling in the number of samples. Architecturally, three main processing stages are employed: feature distribution embedding (column-wise with inducing-point attention), row-wise feature aggregation into fixed-width representations, and a final transformer-based ICL operating over these row embeddings. The addition of orthogonal class embedding initialization and an attention-based many-class retrieval decoder removes the fixed-head bottleneck, ensuring scalability and permutation equivariance over class labels.
TabPFN-3 is exclusively pretrained with synthetic datasets sampled from a broadened SCM prior. Innovations in the prior include more expressive graph sampling, expanded combinatorial functional mechanisms, richer treatment of categorical/spatial/temporal variables, and the inclusion of out-of-distribution and many-class handling. This is structurally visualized in:
Figure 1: Visualization of directed acyclic graphs underlying the SCM prior using novel graph sampling algorithms.

Figure 2: Visualization of diverse functional mechanisms generated by the combiner modules within the SCM prior.
The prior's design supports generalization to dataset regimes rarely covered by standard tabular benchmarks, including high class cardinality, temporal ordering, spatial correlations, and covariate shift through out-of-distribution sampling.
Inference Optimization and Scaling
TabPFN-3 introduces row-chunked inference to decouple peak memory usage from the overall row–column product, allowing the transformer ICL block to process million-row datasets with low wall-clock overhead. The model implements multi-query attention for KV-caching, yielding an 8× reduction in test-side KV-cache footprint, facilitating high-throughput batch prediction even at maximal context size.
Relevant performance/computation trade-offs are empirically demonstrated by Pareto analysis on benchmark datasets. TabPFN-3 strictly Pareto-dominates prior foundation models and classical GBT pipelines on joint accuracy and inference/training cost axes:
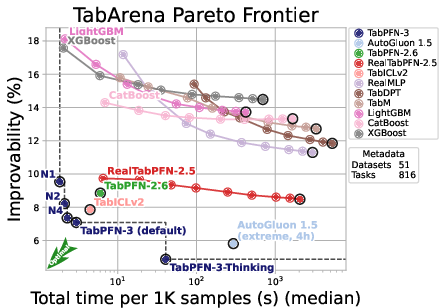
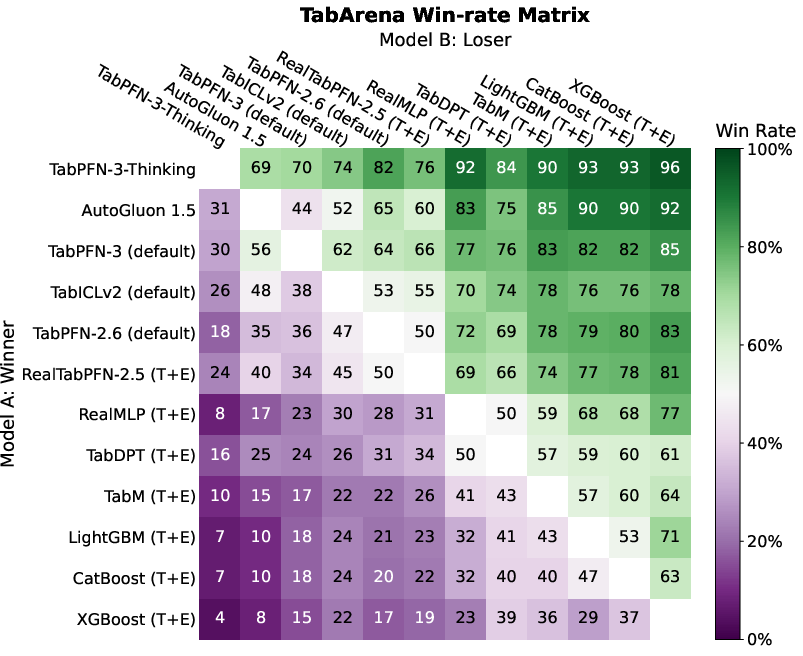
Figure 3: TabPFN-3 dominates the Pareto frontier on TabArena's largest datasets, demonstrating favorable compute-performance scaling.
Additionally, the model distills efficiently into dataset-specific MLP and tree-based surrogates, providing sub-millisecond CPU inference paths and preserving predictive fidelity for downstream regression/classification deployment.
Benchmarking and Empirical Results
Tabular Benchmarks: TabArena and TALENT
TabPFN-3 outperforms leading GBTs, prior TabPFN releases, AutoGluon-Tabular, TabICLv2, and SOTA neural baselines on the TabArena and TALENT leaderboards. The model achieves substantial Elo margins over the nearest tuned ensemble or AutoML competitor. The improvement is most prominent for the TabPFN-3-Plus API variant with test-time compute scaling, which also supports native handling of text features:
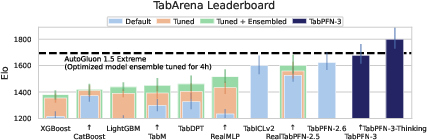
Figure 4: TabPFN-3 performance on the TabArena benchmark exceeds all other models in a single forward pass.
Figure 5: Pareto frontier on TabArena: TabPFN-3 and its variants are strictly non-dominated in terms of improvability versus total compute cost.
TabPFN-3 sustains its lead under diverse evaluation regimes: large-row classification/regression, high-dimensional settings, and many-class benchmarks. For high data-volume benchmarks (up to $1$M samples), TabPFN-3 achieves the top normalized scoring curves across increasing dataset sizes:
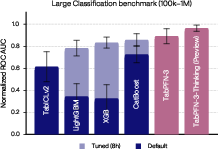
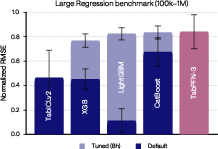
Figure 6: TabPFN-3 achieves state-of-the-art performance on benchmarks up to $1$M training rows and 200 features, outperforming both default and 8-hour-tuned GBTs.
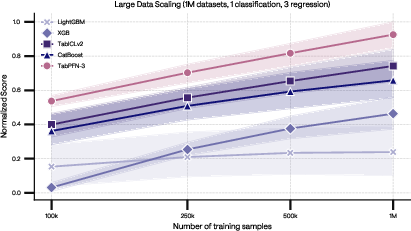
Figure 7: TabPFN-3 sustains SOTA normalized ROC-AUC and RMSE metrics across scaling regimes up to $1$M rows.
On synthetic many-class tasks, TabPFN-3 achieves a normalized ROC-AUC of $1.00$, far surpassing GBTs and prior foundation models:
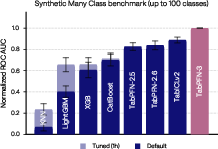
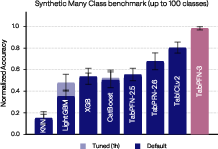
Figure 8: TabPFN-3 yields a normalized ROC-AUC (OvR) of $1.00$ on synthetic many-class benchmarks with up to 100 classes, decisively outperforming all baselines.
In the high-dimensional, low-sample regime (>1,000 features, <500 samples), TabPFN-3 ensembles attain the best normalized ROC-AUC:
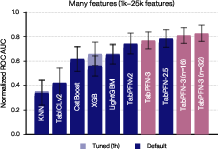
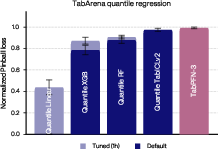
Figure 9: TabPFN-3 maintains robust generalization for high-dimensional, low-sample classification problems.
Text-Tabular and Multimodal Benchmarks
The Plus and Thinking Mode serves string-valued columns natively, learning cross-feature interactions between text, categorical, and numeric fields. TabPFN-3-Plus outperforms all text-aware and numerical-only baselines on challenging real-world text-tabular tasks:
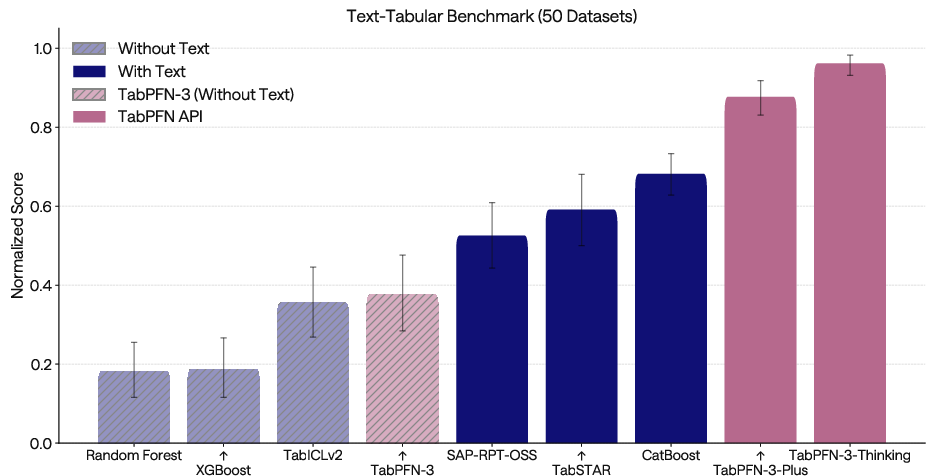
Figure 10: TabPFN-3-Plus and its variants exceed all text-aware and numeric-only baselines on the TabSTAR text-tabular collection.
Generalization: Relational, Time Series, and Causal Tasks
TabPFN-3 powers new SOTA foundation models in relational learning as validated by RelBenchV1 benchmarks:
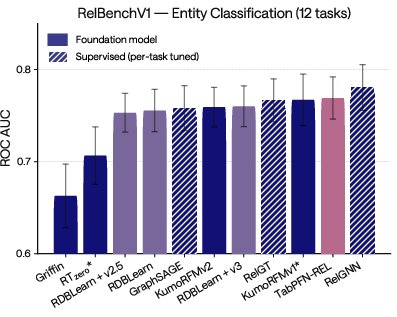
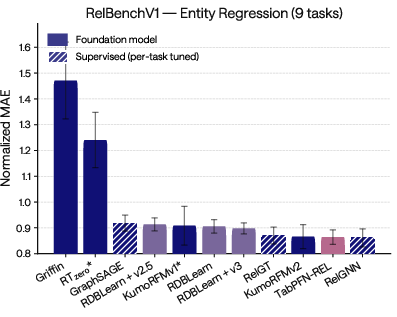
Figure 11: TabPFN-3 leads among foundation models for entity classification/regression on RelBenchV1.
Probabilistic time series forecasting with TabPFN-TS-3 places first or second among foundation models on fev-bench, despite only synthetic data pretraining.
Row Embedding Quality and Interpretability
TabPFN-3 generates semantically meaningful row embeddings, enabling clear cluster separation by class in low-dimensional projections:

Figure 12: PCA on TabPFN-3-derived row embeddings achieves clear class-separable clusters across data folds.
Furthermore, the speed up from reduced KV-cache and chunked inference enables accelerated SHAP-IQ and interaction computation, facilitating widespread interpretability.
Implications and Future Directions
TabPFN-3 demonstrates that large-scale synthetic pretraining combined with carefully designed architecture and inference pathways can Pareto-dominate longstanding production baselines in structured data analysis. The approach’s generalization across modalities (text, time, relational), robustness to high class cardinality, and practical deployment capabilities (distillation, efficient caching, minimal latency) set a new operational standard for tabular foundation models.
Important open theoretical questions remain regarding scaling laws of tabular pretraining, transferability to distributional shifts not covered by the SCM prior, and the integration of retrieval-augmented or real-data pretraining to further close gaps relative to fully supervised, domain-specific approaches in highly structured relational or temporal domains.
Incidentally, TabPFN-3’s architecture—particularly the attention-based retrieval head and flexible in-context aggregation—may inform future multimodal and retrieval-based learning in domains beyond tabular data, including genomics, health records, and scientific sensor arrays. Future AI systems for induction from low-sample, high-dimensional, or many-class physical data will likely build on these scaling and inference optimization insights.
Conclusion
TabPFN-3 marks a step-change in the scaling, generalization, and workhorse deployment properties of tabular foundation models. With its efficient, fully synthetic pretraining, adaptive inference optimizations, and support for text and multimodal extensions, it challenges the GBT paradigm on its own ground and opens directions for robust, interpretable, and efficient tabular machine learning. The model’s empirical dominance across public, internal, and specialized modalities substantiates the claim that carefully designed transformer-based PFNs can supplant tree ensembles and AutoML systems as the new SOTA default for tabular data tasks (2605.13986).