TabICLv2: A better, faster, scalable, and open tabular foundation model
Abstract: Tabular foundation models, such as TabPFNv2 and TabICL, have recently dethroned gradient-boosted trees at the top of predictive benchmarks, demonstrating the value of in-context learning for tabular data. We introduce TabICLv2, a new state-of-the-art foundation model for regression and classification built on three pillars: (1) a novel synthetic data generation engine designed for high pretraining diversity; (2) various architectural innovations, including a new scalable softmax in attention improving generalization to larger datasets without prohibitive long-sequence pretraining; and (3) optimized pretraining protocols, notably replacing AdamW with the Muon optimizer. On the TabArena and TALENT benchmarks, TabICLv2 without any tuning surpasses the performance of the current state of the art, RealTabPFN-2.5 (hyperparameter-tuned, ensembled, and fine-tuned on real data). With only moderate pretraining compute, TabICLv2 generalizes effectively to million-scale datasets under 50GB GPU memory while being markedly faster than RealTabPFN-2.5. We provide extensive ablation studies to quantify these contributions and commit to open research by first releasing inference code and model weights at https://github.com/soda-inria/tabicl, with synthetic data engine and pretraining code to follow.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
What is this paper about?
This paper introduces TabICLv2, a new AI model that works with tables of data (think spreadsheets). It learns patterns directly from the rows and columns it sees, without the usual long training process. The goal is to make a model that is more accurate, faster, and able to handle very large tables, and to release it openly so anyone can use or study it.
What are the main questions?
The authors set out to answer three simple questions:
- Can we build a tabular model that learns “in context” (from the table it sees) and still beats the best existing methods on standard tests?
- Can we make it faster and able to handle huge tables with many rows and columns?
- What design choices (architecture, training tricks, and data used for practice) matter most for performance?
How did the researchers build and train the model?
Learning from tables on the fly (in-context learning)
Most models are trained on big datasets first, then used later. TabICLv2 does something different: when you give it a table with training rows and a new test row, it figures out the answer in one pass (like looking at a cheat sheet and solving the problem right away). This is called in-context learning. It’s great for tabular data because many real-world tables are small or vary a lot.
New design ideas to keep focus on big tables
The model has several smart tweaks to improve accuracy and scale:
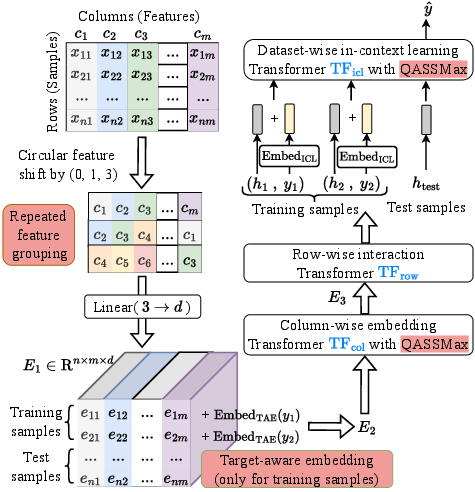
- Repeated feature grouping: Instead of treating each column totally separately, the model mixes columns into small groups in rotating patterns. That breaks “symmetries” where similar-looking columns might confuse the model, while still keeping detail from each column.
- Target-aware embedding: For training rows, the model adds information about the target (the correct answer) into every feature vector at the start. This helps the model connect inputs to outcomes early, which improves learning.
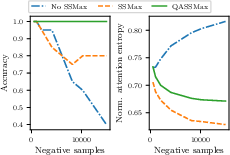
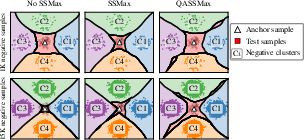
- Query-aware scalable softmax (QASSMax): Attention is how the model decides which rows matter. In very long tables, normal attention gets “washed out” (it spreads focus too thin across too many rows), a problem called attention fading. QASSMax fixes this by automatically sharpening attention as the number of rows grows, and by letting the model adjust that sharpening based on the specific query. Think of it like turning up the zoom when the page has tiny text, so you don’t miss the important parts.
Smarter pretraining and optimizer
Before using TabICLv2, the authors “pretrained” it on many synthetic (fake but diverse) datasets so it learns general rules about tables.
- Three training stages: They start with small tables, then gradually train on larger ones, so the model learns to handle big contexts step by step.
- Muon optimizer: Instead of the common AdamW optimizer, they use Muon, a different way of adjusting the model’s parameters during training. With the right settings, Muon let them use larger learning rates and helped the model train faster and more stably.
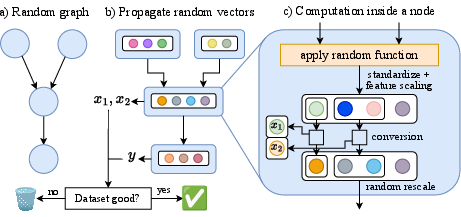
Making big, fake practice datasets (a synthetic prior)
A “prior” here means a recipe for generating lots of different practice tables. Their new prior builds random data using a graph of connected nodes where each node applies one of several functions (like a mini neural network, a tree ensemble, a Gaussian process, a linear or quadratic formula, etc.). This creates diverse patterns—smooth, blocky, noisy, and more—so the model learns to deal with many kinds of relationships.
They also filter out unhelpful practice sets (for example, when the features and target are independent or trivial), so training focuses on meaningful problems.
Faster and more memory-friendly inference
They add engineering tricks, like offloading some data to disk and computing only what’s necessary, so the model can run on very large tables (up to around a million rows and hundreds of columns) without running out of memory.
What did they find?
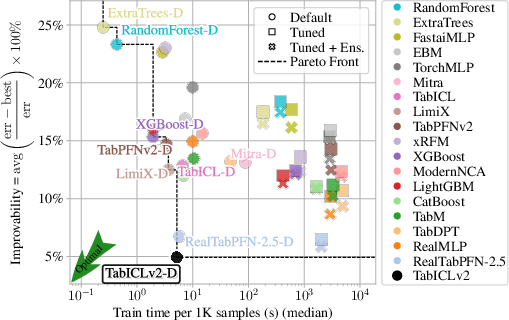
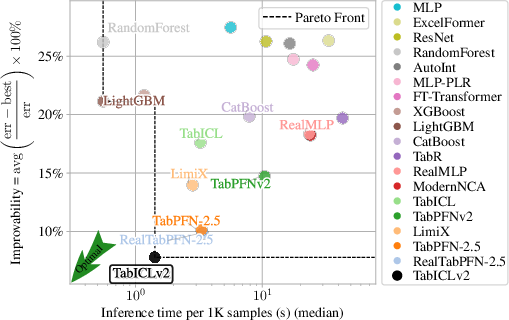
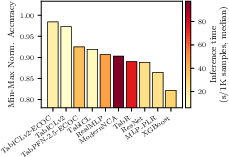
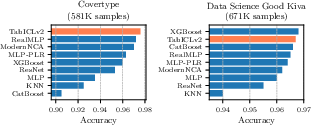
On two major benchmarks (TabArena and TALENT), TabICLv2:
- Achieves state-of-the-art accuracy among tabular foundation models, even without extra tuning.
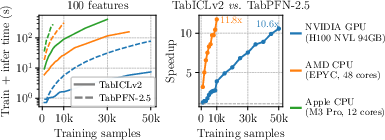
- Runs faster than a strong competitor (TabPFN-2.5), with growing speed advantages on larger tables (over 10× faster in some cases on GPUs and CPUs).
- Scales to very large datasets where other models fail or run out of memory.
- Handles tasks with more than 10 classes better than alternatives, thanks to a simple “mixed-radix” trick for multi-class classification.
- Improves regression by predicting many quantiles (like percentiles) rather than just a single number, giving both a point estimate and a useful uncertainty range.
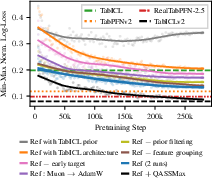
They also run ablation studies (turning features on/off) and find:
- The new synthetic data generator (prior) is the biggest driver of performance.
- Early target inclusion, QASSMax for attention, and the Muon optimizer each add strong gains.
- Data filtering and repeated feature grouping help too, but by smaller amounts.
Why does it matter?
- Better decisions from tables: Many fields rely on tabular data—healthcare, finance, sales, science. A model that is both accurate and fast can improve predictions and insights across the board.
- Fewer knobs to turn: Because TabICLv2 works well “out of the box,” teams spend less time on tuning and more time solving real problems.
- Handles big data directly: It can process huge tables without complicated tricks, which reduces engineering effort and cost.
- Open and reusable: The authors are releasing model weights and code. This helps researchers and practitioners learn from, extend, and trust the system.
- A foundation for more: Strong tabular models enable related tasks like causal analysis, generating synthetic data, uncertainty estimation, and simulation-based inference.
In short, TabICLv2 pushes tabular AI forward by making in-context learning more powerful, more scalable, and openly available.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a single, concrete list of what remains missing, uncertain, or unexplored in the paper, phrased to guide actionable future work:
- Lack of evaluation on leveraging column names and textual semantics: assess benefits and integration strategies (e.g., text encoders, schema encoders) for
TabICLv2, especially on semantically rich datasets. - Missing-value handling is rudimentary (mean imputation): quantify the gains from learned missingness mechanisms (e.g., missingness indicators, masked pretraining, learned imputation) and robustness to varying missingness mechanisms (MCAR/MAR/MNAR).
- Multi-output/structured targets are unsupported: extend to multi-output regression/classification and evaluate on benchmarks with correlated targets.
- Distribution shift and temporal drift robustness is untested: adapt priors or training (e.g., time-conditioned priors) and evaluate under controlled covariate/label shift, including comparisons to drift-resilient baselines.
- Probabilistic regression evaluation is limited: systematically assess calibration, coverage, and sharpness for the 999-quantile predictions on real benchmarks (e.g., CRPS, PICP, ACE), beyond toy validations.
- Quantile-to-distribution reconstruction choices are underexplored: compare sorting vs. isotonic regression and tail extrapolation strategies for predictive likelihoods/calibration and their runtime trade-offs.
- Many-class classification beyond ∼10–50 classes remains undercharacterized: stress-test
mixed-radix ensemblingon datasets with hundreds/thousands of classes under class imbalance and assess calibration and computational scaling. - Pretraining limited to ≤100 features: quantify generalization when inference uses hundreds/thousands of features; investigate pretraining with larger
mor curriculum strategies for feature count scaling. - Long-context generalization without long-sequence pretraining is only partially validated: characterize failure modes at ≥1M samples and the minimal pretraining context needed for stable performance scaling.
- Retrieval/chunking was not explored: compare native long-context ICL against retrieval-augmented or chunked ICL for >1M samples under strict memory/latency budgets.
- No distillation study: evaluate distillation of
TabICLv2into compact models (MLPs/trees) for edge deployment, measuring accuracy–latency–memory trade-offs. - QASSMax theory and alternatives are open: provide theoretical analysis of stability/consistency, compare to other scalable/temperature schemes (e.g., YaRN, ASEntmax, selective attention), and test sensitivity to gating MLP size and parameterization.
- Attention fading on real data: move beyond toy “needle-in-a-haystack” tests to quantify attention entropy/focus vs.
non real benchmarks and link to accuracy/ICL failure cases. - Interactions between QASSMax and training dynamics: study effects on optimization stability, gradient norms, and variance across seeds; assess compatibility and speed with FlashAttention kernels.
- Repeated feature grouping design remains heuristic: explore optimal group sizes/patterns for different
m, dependence structures, and small-medge cases; analyze representation collapse mitigation systematically. - Target-aware embedding side effects untested: probe for bias/calibration impacts, especially in few-shot/imbalanced regimes; compare to appending-target-column vs. per-feature injection.
- Prior design lacks component-wise attribution: ablate the new prior’s building blocks (random Cauchy graphs, eight function classes, converters, rescaling, node importance, correlated hyperparameters) to identify which elements drive generalization.
- Random Cauchy graph properties are unproven: characterize graph connectivity distributions, path lengths, and their impact on dependency structures and learning difficulty.
- Filtering’s side effects on diversity are unknown: quantify how dataset/graph filtering (based on ExtraTrees improvement and causal connectivity) biases the synthetic distribution and impacts robustness/OOD performance.
- Correlated hyperparameter sampling impact is unmeasured: test whether inducing repeated categorical cardinalities (and other correlations) improves or harms real-data transfer, especially for high-cardinality categorical features.
- Optimizer choice is underexplored: compare Muon to modern adaptive/second-order methods (e.g., Adafactor, Sophia, Shampoo) across stages; study why Muon helps and whether benefits persist at larger scales.
- Pretraining curriculum sensitivity is unclear: evaluate alternative stage schedules (context sizes, train/test splits, learning-rate policies) and their impact on small vs. large
nperformance. - Scaling laws are not established: map performance vs. pretraining steps/data/model size across priors to verify whether (and where) scaling laws hold or break.
- Fair runtime comparisons need standardization: re-benchmark all methods on matched hardware/software to remove confounds from mixed runtime sources (TabArena/TALENT vs. H100 measurements).
- Robustness and safety not assessed: test resistance to label noise, adversarial row/column perturbations, extreme outliers, and data contamination.
- Calibration for classification is unreported: evaluate ECE/Brier/log-loss calibration improvements with temperature scaling or post-hoc calibration.
- Categorical feature handling at extreme cardinalities is under-tested: benchmark on datasets with very high-cardinality categorical columns and varying encoders/preprocessors.
- Interpretability/explainability is not addressed: develop mechanisms (e.g., attention attribution over rows/columns, surrogate models) and evaluate their faithfulness/usefulness.
- Reproducibility is incomplete: synthetic data engine and pretraining code are not yet released; provide full pipelines to enable community verification and extensions.
- Real-data continued pretraining/fine-tuning synergy is unexplored: test whether combining the new prior with continued pretraining on real datasets (or task-specific fine-tuning) yields additive gains and how it affects generalization.
- Energy/throughput trade-offs of disk offloading are unquantified: profile wall time vs. I/O bandwidth and CPU/GPU utilization across storage media; identify bottlenecks for large
n, m. - Extension to multi-modal tables (text, images, time series) is unstudied: propose and evaluate architectural hooks for modality-specific embeddings within the
TabICLv2pipeline.
Glossary
- Ablation study: A systematic analysis that removes or modifies components to quantify their individual contributions to overall performance. "We conduct an ablation study to assess the impact of architectural, prior, and pretraining choices"
- Adaptive-Scalable Entmax (ASEntmax): A softmax alternative that adaptively scales attention based on context length and content to preserve sharpness. "Adaptive-Scalable Entmax (ASEntmax, \citealt{asentmax}) extends this with content-aware scaling "
- Attention fading: The tendency of softmax attention to flatten as context length grows, reducing focus on relevant tokens. "suffers from attention fading~\citep{velivckovic2024softmax,ssmax}: the softmax denominator increases as context length grows"
- Cautious weight decay: A regularization scheme that only decays weights when the update and parameter share the same sign to avoid hindering useful directions. "We adopt cautious weight decay~\citep{chen2025cautious} with parameter $0.01$, which applies decay only when the update and parameter have the same sign"
- Cosine learning rate schedule: A learning-rate decay strategy that follows a cosine curve over training. "and use a cosine learning rate schedule across all stages"
- Directed acyclic graph (DAG): A graph with directed edges and no cycles, often used to structure causal relationships. "We then sample a directed acyclic graph and random functions defining parentâchild relationships"
- Disk offloading: An inference optimization that moves intermediate data to disk to reduce memory usage. "We implement disk offloading (\Cref{sec:appendix:inference_optim:disk_offloading}), reducing requirements to under 24\,GB CPU and 50\,GB GPU"
- Error-correcting output codes (ECOC): A multiclass classification technique that decomposes classes into multiple binary problems using codewords. "TabICLv2 with both the error-correcting output codes (ECOC) wrapper from TabPFNv2 and our native mixed-radix ensembling substantially outperforms"
- ExtraTrees: An ensemble of extremely randomized decision trees used as a baseline and for dataset filtering. "we filter out datasets on which a simple ExtraTrees model cannot improve on a constant baseline according to a bootstrap test"
- FlashAttention: A memory- and compute-efficient attention algorithm optimized for GPUs. "requires specialized implementations incompatible with the softmax ecosystem, e.g., FlashAttention~\citep{FlashAttention}"
- Gaussian process (GP) functions: Functions sampled from a Gaussian process used to generate smooth, stochastic mappings in the synthetic prior. "(GP) Multivariate Gaussian process functions;"
- GELU activation: The Gaussian Error Linear Unit, a smooth nonlinearity used in neural networks. "are two-layer MLPs with 64 hidden neurons and GELU activation"
- Gradient clipping: A technique that limits the magnitude of gradients to stabilize training. "We also increase gradient clipping from $1$ to $10$ for stages 1 and 2"
- Hierarchical classification: A strategy that breaks multiclass prediction into a hierarchy of simpler tasks. "We use hierarchical classification~\citep{tabicl} at the ICL stage for more classes"
- Improvability: A benchmark metric measuring the relative error gap to the best method across datasets (lower is better). "Improvability (lower is better) measures the relative error gap to the best method, averaged across datasets"
- In-context learning (ICL): Performing prediction by conditioning on training examples within the model’s input, without gradient updates. "it hence performs in-context learning (ICL) without gradient updates"
- Inducing points: Auxiliary tokens used to aggregate and summarize input information efficiently in attention architectures. "where inducing points aggregate input information"
- Isotonic regression: A nonparametric method that fits a non-decreasing function to data, used to enforce monotonicity of quantiles. "by enforcing monotonicity via sorting (the default) or isotonic regression \citep{barlow1972isotonic,busing2022monotone}"
- Logsumexp: A smooth approximation to the maximum operation used for stable aggregation in log-space. "aggregate the results using sum, product, max, or logsumexp"
- Log-uniform: A sampling distribution where the logarithm of the variable is uniformly distributed, favoring multiplicative scale diversity. "datasets with 400--10,240 samples (log-uniform), 80\% for training, max learning rate 1e-4"
- Mixed-radix ensembling: A multiclass strategy that decomposes labels into digits with different bases (each ≤10) and ensembles predictions across digits. "we propose mixed-radix ensembling: for classes, we compute balanced bases "
- Muon optimizer: An alternative to AdamW that uses matrix-wise scaling and enables higher learning rates for faster convergence. "We use the Muon optimizer~\citep{muon} ... instead of AdamW"
- Pinball loss: The standard loss for quantile regression that penalizes over- and under-prediction asymmetrically based on the quantile level. "trained with pinball loss summed across all quantiles"
- Prior-data fitted networks (PFNs): Networks trained on synthetic priors to approximate Bayesian inference and enable ICL at test time. "Tabular foundation models (TFMs) based on Prior-data fitted networks (PFNs, \citealt{muller2021transformers}) emerged as a paradigm shift"
- Quantile regression: Predicting conditional quantiles of the target distribution rather than its mean. "we found that quantile regression outperforms MSE and the bin-based approach of TabPFNv2"
- Query-aware scalable softmax (QASSMax): A length- and query-sensitive temperature scaling of attention that mitigates attention fading at long contexts. "We propose query-aware scalable softmax (QASSMax), which rescales each query element as:"
- Random Cauchy graph: A graph generation mechanism with Cauchy-like connectivity to create diverse DAG structures in the prior. "we introduce a ``random Cauchy graph'' mechanism, which models different global and local node connectivities"
- Retrieval-based context selection: Selecting a subset of relevant in-context examples to improve scalability within compute budgets. "retrieval-based context selection to enhance compute-constrained scalability"
- Repeated feature grouping: Encoding strategy that groups each column with shifted neighbors multiple times to break symmetries and avoid collapse. "We propose repeated feature grouping, which places each feature into multiple groups via circular shifts"
- RoPE (Rotary Position Embedding): A positional encoding technique that rotates queries and keys by position-dependent angles. "YaRN~\citep{YaRN} scales temperature with context length for RoPE~\citep{RoPE} extension"
- Scalable Softmax (SSMax): A temperature scaling approach that multiplies attention logits by a learnable factor times log sequence length to preserve sharpness. "Scalable Softmax (SSMax, \citealt{ssmax}) scales attention logits by "
- Set transformer: A transformer architecture for permutation-invariant set inputs that uses inducing points for efficient pooling. "column-wise embedding applies a set transformer ~\citep{set-transformer} to each column"
- Structural causal models (SCMs): Causal generative models defined by a DAG and structural equations specifying how variables are produced. "TabPFN uses structural causal models (SCMs)"
- Temperature scaling: Adjusting the softmax temperature to control the peakedness of attention distributions. "We thus focus on a less invasive solution: temperature scaling"
- YaRN: A method that rescales attention to extend context length, originally designed for RoPE-based models. "YaRN~\citep{YaRN} scales temperature with context length for RoPE~\citep{RoPE} extension"
Practical Applications
Immediate Applications
The following applications can be deployed now using the released TabICLv2 model weights and inference code (https://github.com/soda-inria/tabicl), with minimal or no tuning.
- Credit risk scoring and fraud detection
- Sector: finance
- What: Out-of-the-box binary/multiclass classification for credit approval, default prediction, and transactional fraud scoring; uncertainty-aware decision thresholds via 999-quantile regression.
- Tools/workflows: Deploy a GPU/CPU scoring microservice; batch score customer tables with disk offloading; expose a “QuantilePredict” API to return prediction intervals alongside point estimates.
- Assumptions/dependencies: GPU recommended for large tables (>100K rows); for regulated settings, pair with post-hoc explainability (e.g., SHAP) or distill to trees; domain shift may warrant light fine-tuning.
- Patient risk stratification and outcome prediction
- Sector: healthcare
- What: Classification/regression for readmission, adverse event risk, length-of-stay, and resource allocation, with calibrated prediction intervals for clinical decision support.
- Tools/workflows: Integrate TabICLv2 scoring into hospital analytics; uncertainty-aware dashboards that show prediction intervals and tail risks; batch inference across EHR tables.
- Assumptions/dependencies: Handle missing values explicitly (current default is mean imputation); consider calibration/validation on local cohorts.
- Demand forecasting and inventory optimization
- Sector: retail/supply chain
- What: Quantile regression for SKU-level demand forecasts and service-level targeting; convert intervals to safety stock recommendations.
- Tools/workflows: ETL pipeline → TabICLv2 batch scorer → optimization layer (service-level targets from quantiles).
- Assumptions/dependencies: Seasonality and temporal dynamics are not explicitly modeled; pair with time-indexed features or hybrid pipelines.
- Product taxonomy, claims coding, and event classification with many classes
- Sector: e-commerce, insurance/health, AIOps
- What: High-cardinality classification via native mixed-radix ensembling or ECOC wrapper; improved accuracy on >10 classes at moderate runtime.
- Tools/workflows: Batch processing of catalog updates or ICD/SNOMED code assignment; telemetry event labeling in AIOps.
- Assumptions/dependencies: ECOC provides higher accuracy but ~3× slower; choose wrapper based on latency constraints.
- Predictive maintenance and anomaly detection on operational logs
- Sector: manufacturing/IoT/energy
- What: Failure probability estimation and anomaly flagging from tabular sensor summaries; uncertainty intervals to prioritize inspections.
- Tools/workflows: Stream features → micro-batched scoring service; route high-uncertainty cases to manual review.
- Assumptions/dependencies: For streaming or very large contexts, use micro-batching; ensure feature engineering captures temporal signals.
- Large-scale batch scoring for analytics teams
- Sector: software/data organizations
- What: Score millions of rows natively without retrieval/distillation; TabICLv2 scales under 50GB GPU with disk offloading.
- Tools/workflows: “Score-at-scale” jobs on H100/A100 or high-RAM CPU; integrate into Airflow/Prefect pipelines; use column/class shuffles for quick ensembles.
- Assumptions/dependencies: Fast storage for offloading; I/O bandwidth can be the bottleneck; verify hardware memory limits.
- Rapid baselining and AutoML integration
- Sector: cross-industry data science
- What: Use TabICLv2 as a strong baseline/first model in AutoML, drastically reducing tuning cycles while matching/surpassing tuned GBDTs.
- Tools/workflows: Add a “TabICLv2-first” step in model selection; fall back to tuned trees only when TabICLv2 underperforms; log normalized accuracy/improvability.
- Assumptions/dependencies: Some niche tabular distributions may benefit from domain-specific tuning or retrieval.
- Method education and reproducible research
- Sector: academia
- What: Teach tabular foundation models and attention scaling using the minimal implementation; reproduce the Pareto-front results on TALENT/TabArena.
- Tools/workflows: Course notebooks demonstrating QASSMax vs. standard softmax; ablation labs on optimizer, early target inclusion, feature grouping.
- Assumptions/dependencies: Synthetic data pretraining code for full replication is forthcoming; inference and weights are already open.
Long-Term Applications
The following applications are promising but require further research, scaling, or code releases (e.g., synthetic data engine and full pretraining pipeline).
- Causal inference, simulation-based inference, and generative tabular modeling
- Sector: healthcare, economics, policy, scientific computing
- What: Leverage TFM adaptations (causal PFN, simulation-based inference) to estimate treatment effects or generate realistic tables for scenario analysis.
- Tools/workflows: Domain-tailored priors; causal wrappers; simulation pipelines integrated with TabICLv2 row embeddings.
- Assumptions/dependencies: Requires open-sourced prior engine and downstream adaptation; careful validation and identifiability checks.
- Robustness to temporal drift and nonstationarity
- Sector: finance, retail, cybersecurity
- What: Drift-resilient variants (e.g., time-modulated priors) to maintain accuracy under shifting distributions.
- Tools/workflows: Time-aware priors; online recalibration; drift detectors feeding adaptive context.
- Assumptions/dependencies: Additional pretraining on drift-aware synthetic/real datasets; monitoring infrastructure.
- Semantics-aware tabular modeling with text
- Sector: healthcare, public sector, enterprise analytics
- What: Combine column-name and textual feature embeddings (LLMs) with TabICLv2’s scalability for mixed structured + text data.
- Tools/workflows: ConTextTab-style serialization; small text encoder fused with TabICLv2; hybrid feature store.
- Assumptions/dependencies: Engineering to keep latency/memory low; benchmark and tune for semantics gains.
- Multi-output regression and richer probabilistic predictions
- Sector: energy, operations research, insurance pricing
- What: Joint predictive distributions over multiple targets; prescriptive analytics using full uncertainty structure.
- Tools/workflows: Multivariate quantile outputs; copula or structured heads; decision optimization layers.
- Assumptions/dependencies: Model head redesign; calibration beyond toy datasets; suitable benchmarks.
- Privacy-preserving, federated, and domain-specific pretraining
- Sector: healthcare, finance, government
- What: Federated adaptation to local data while maintaining strong priors; secure scoring and governance.
- Tools/workflows: Federated fine-tuning; DP-aware pipelines; governance dashboards logging uncertainty and fairness.
- Assumptions/dependencies: Continued pretraining code; policy-compliant infra; interpretability tooling.
- Streaming and real-time long-context scoring at extreme scale
- Sector: ad tech, cybersecurity, AIOps
- What: Retrieval or chunked ICL to sustain sub-second latency with tens of millions of rows; sparse/multi-scale attention.
- Tools/workflows: Retrieval-based context selection; multi-scale sparse attention layers; incremental scoring services.
- Assumptions/dependencies: Further architectural work (e.g., Orion-MSP-like attention); high-performance serving.
- Explainability-first deployments and distillation
- Sector: regulated industries
- What: Distill TabICLv2 into compact MLPs/trees for line-of-business explainability; integrate uncertainty into explanations.
- Tools/workflows: Tree/MLP distillers; explanation APIs; interval-aware decision rules.
- Assumptions/dependencies: Distillation quality under domain shifts; explainability validation protocols.
- Customized synthetic priors for domain emulation
- Sector: any tabular-heavy domain
- What: Tailor the prior (graphs, functions, categorical cardinalities) to mirror domain structure (e.g., healthcare coding hierarchies, financial risk factors).
- Tools/workflows: “Prior Studio” that composes random functions/graphs; validation filters (bootstrap tests); domain-specific feature warping.
- Assumptions/dependencies: Release of the prior engine; avoidance of overfitting to validation sets; governance of synthetic realism.
- QASSMax adoption beyond tabular TFMs
- Sector: software tooling, foundation models
- What: Apply query-aware scalable softmax in LLMs/vision transformers to improve long-context generalization without abandoning softmax tooling.
- Tools/workflows: QASSMax layer libraries compatible with FlashAttention; per-head gating diagnostics; entropy monitoring.
- Assumptions/dependencies: Empirical validation across modalities; training stability; hardware-friendly implementations.
- Database-native and MLOps-integrated scoring
- Sector: enterprise data platforms
- What: Push-down inference into data warehouses (in-SQL/UDFs) or GPU databases; standardized CI/CD and monitoring for TFMs.
- Tools/workflows: Connectors to pandas/Polars/SQL; inference UDFs; model registries tracking calibration, latency, memory.
- Assumptions/dependencies: Engineering for memory offload and vectorization; storage bandwidth; ops maturity.
Collections
Sign up for free to add this paper to one or more collections.