- The paper presents OmniTabBench, the largest diverse benchmark with 3,030 datasets to assess GBDTs, NNs, and TFMs for tabular prediction.
- It details a robust LLM-driven data pipeline and meta-feature analysis that quantifies model performance across various dataset characteristics.
- Results reveal no single dominant model, emphasizing context-dependent performance to guide practical algorithm selection.
OmniTabBench: Mapping the Empirical Frontiers of GBDTs, Neural Networks, and Foundation Models for Tabular Data
Introduction and Motivation
The efficacy of machine learning on tabular data has long centered on traditional tree-based models, with gradient boosted decision trees (GBDTs) recognized for robust performance. Recent trends, however, have seen deep neural networks (NNs) and tabular foundation models (TFMs) challenge this dominance, prompting renewed empirical investigations into their relative merits. Despite a proliferation of academic benchmarks, existing efforts have suffered from limited dataset scale and potential biases due to restricted domain diversity and inconsistent annotation of dataset characteristics.
"OmniTabBench: Mapping the Empirical Frontiers of GBDTs, Neural Networks, and Foundation Models for Tabular Data at Scale" (2604.06814) introduces OmniTabBench, the largest and most diverse benchmark for tabular prediction to date, incorporating 3,030 curated datasets from OpenML, UCI, and Kaggle. The benchmark's comprehensive coverage, industry categorizations, and rich meta-features enable a re-examination of longstanding questions regarding model superiority across learning paradigms, dataset types, and application domains.
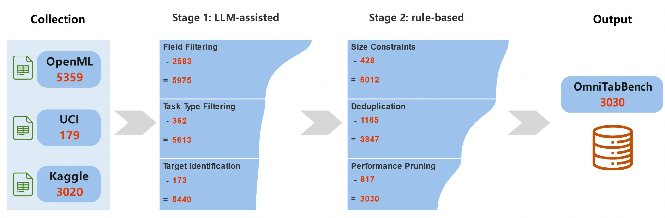
Figure 1: Workflow of constructing OmniTabBench, detailing data acquisition, LLM-driven screening, deduplication, and meta-feature annotation.
Construction of OmniTabBench
The workflow for OmniTabBench construction integrates datasets from major repositories, followed by rigorous automated filtering, LLM-based annotation, and deduplication protocols. The collection pipeline employs an LLM to extract and standardize key metadata such as task type, target column, and industry classification directly from dataset descriptions and attributes, enabling precise partitioning and application-specific benchmarking.
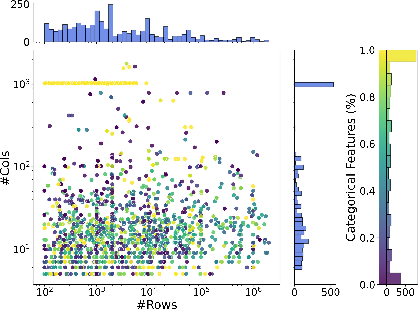
Figure 2: Overview of OmniTabBench visualizing dataset scale, feature dimensionality, and categorical composition.
Rule-based filtering further ensures data utility by enacting thresholds on size (rows and features), feasibility of prediction tasks, and deduplication through cryptographic fingerprints incorporating structural and distributional properties of datasets. Final curation removes trivial or infeasibly difficult tasks based on achieved scores of representative learners, resulting in a non-redundant set of 3,030 datasets with broad coverage.
Industry annotation—rare in existing benchmarks—is facilitated by LLMs, supporting fine-grained selection and analysis across application domains.
Figure 3: Categorization of OmniTabBench by industries, supporting sector-specific benchmarking.
Experimental Framework
A focused suite of SOTA models is benchmarked against OmniTabBench, covering all major paradigms:
- GBDTs: LightGBM, XGBoost, CatBoost
- NNs: vanilla MLP, RealMLP, ResNet, FT-Transformer
- Tabular Foundation Model: TabPFN (pretrained transformer)
Evaluation spans both classification and regression tasks, with protocol ensuring uniform preprocessing (standardized handling of missing/categorical/numerical values) and out-of-the-box configuration to assess model robustness absent hyperparameter tuning.
TabPFN, with context-length limitations tailored for small/medium-scale tasks, is assessed against an unconstrained subset of the corpus, more than an order of magnitude beyond its original real-world validation scope.
Empirical Comparison and Model Ranking Dynamics
A key investigation assesses how model rankings fluctuate as the scope of benchmark datasets increases. The authors demonstrate that conclusions drawn from limited evaluation corpora are highly unstable, evidenced by dramatic oscillations in model ranking under subsampling.
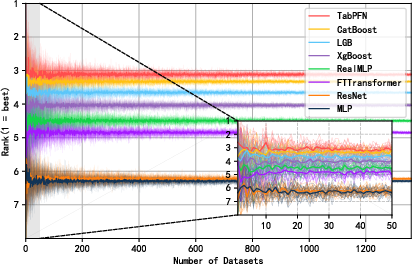
Figure 4: Rank of different models as the number of evaluation datasets increases, revealing instability in model ranking for small sample sizes.
On the fully sampled corpus, TabPFN achieves the best average performance, but GBDTs and NNs are each optimal on a sizable fraction of cases (31.6% GBDT, 33.9% NN, 34.5% TabPFN on the TabPFN-capable subset), affirming the continued absence of a dominant winner across paradigms.
Critical to the study is a decoupled meta-feature analysis—examining dataset characteristics one at a time, rather than as composite metrics. Categories analyzed include sample size, feature dimensionality, categorical value ratio, missingness, skewness, and kurtosis of features and targets.
NNs achieve superior performance in high-sample-size, high-categorical-ratio regimes, benefiting from richer embedding spaces and the flexibility of deep representation learning.
GBDTs, by contrast, display resilience to distributional skewness and heavy tails due to their ordinal split functions, excelling in datasets with pronounced irregularity.
TabPFN dominates on low-sample, low row-to-column scenarios with regular target distributions, leveraging in-context prior capabilities but exhibiting sensitivity to target distribution irregularity.
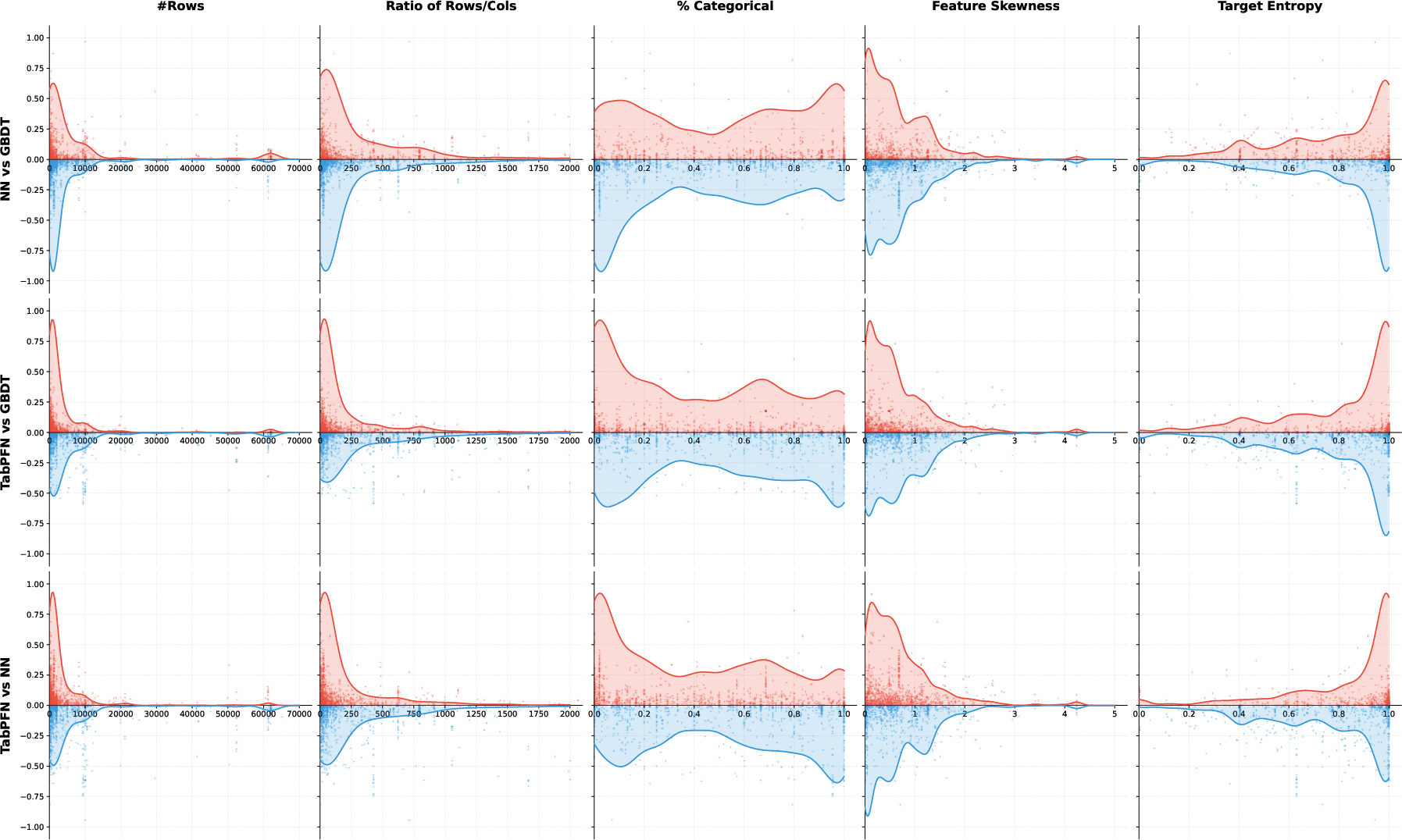
Figure 5: Distribution of performance gaps between different model pairs across varying metafeatures, showing the relationship between meta-properties and model efficacy.
Further pairwise breakdowns detail specific win/loss regions for each model category.
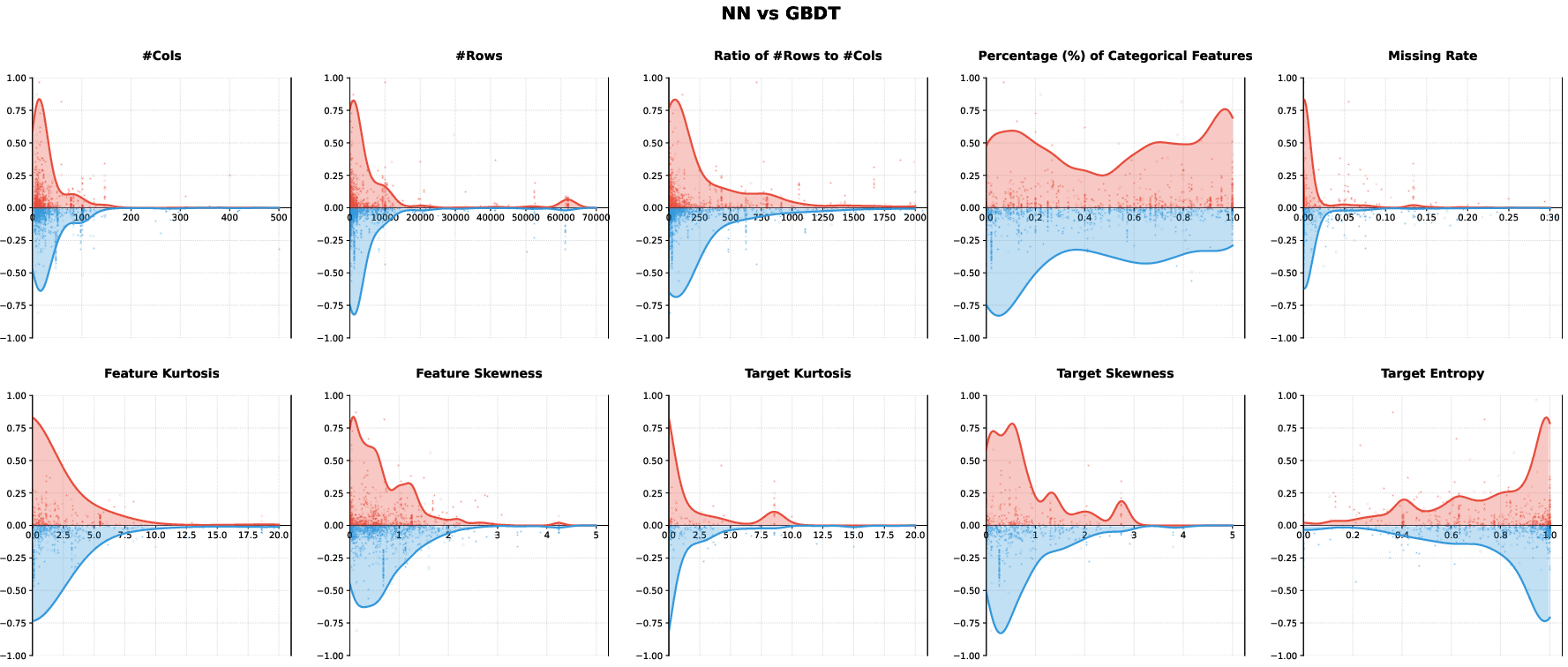
Figure 6: Performance gap distribution between NNs and GBDT across distinct meta-features, illustrating statistical conditions favoring each paradigm.
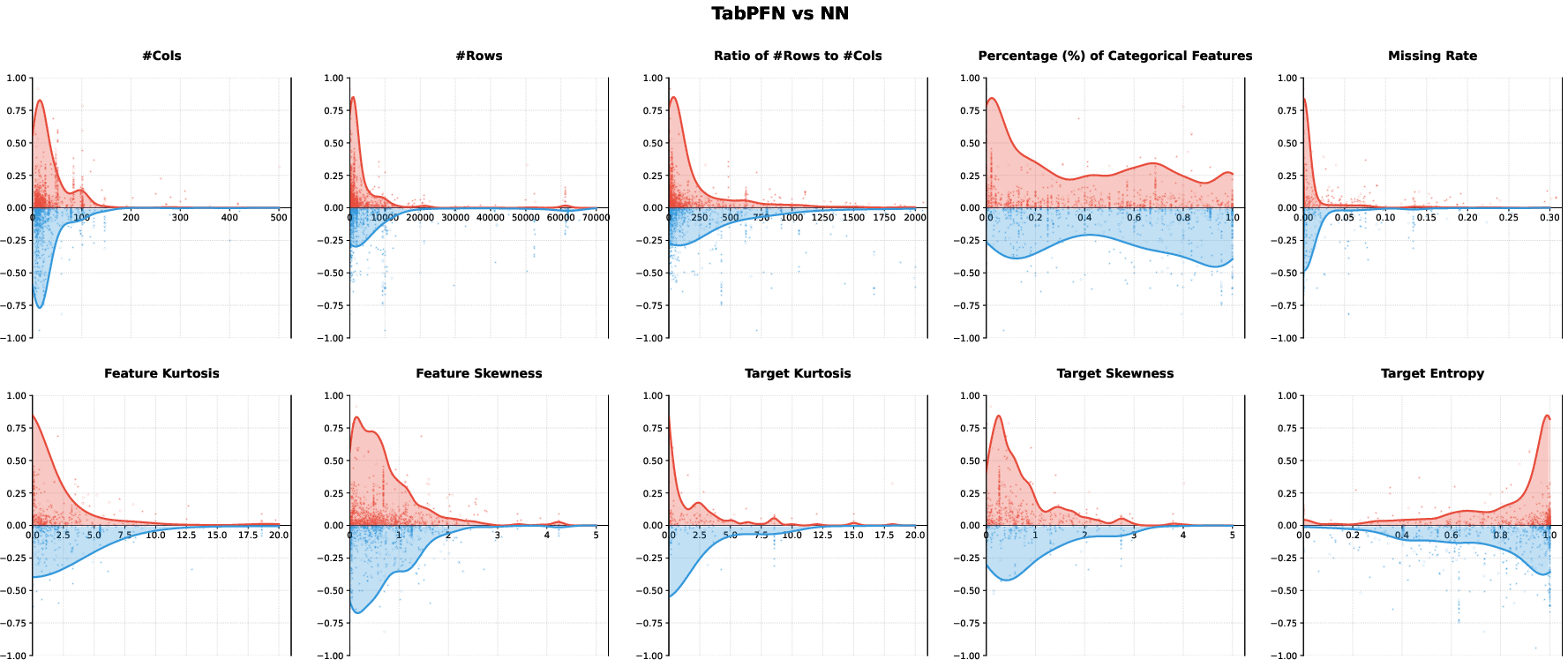
Figure 7: Performance gap distribution between TabPFN and NN.
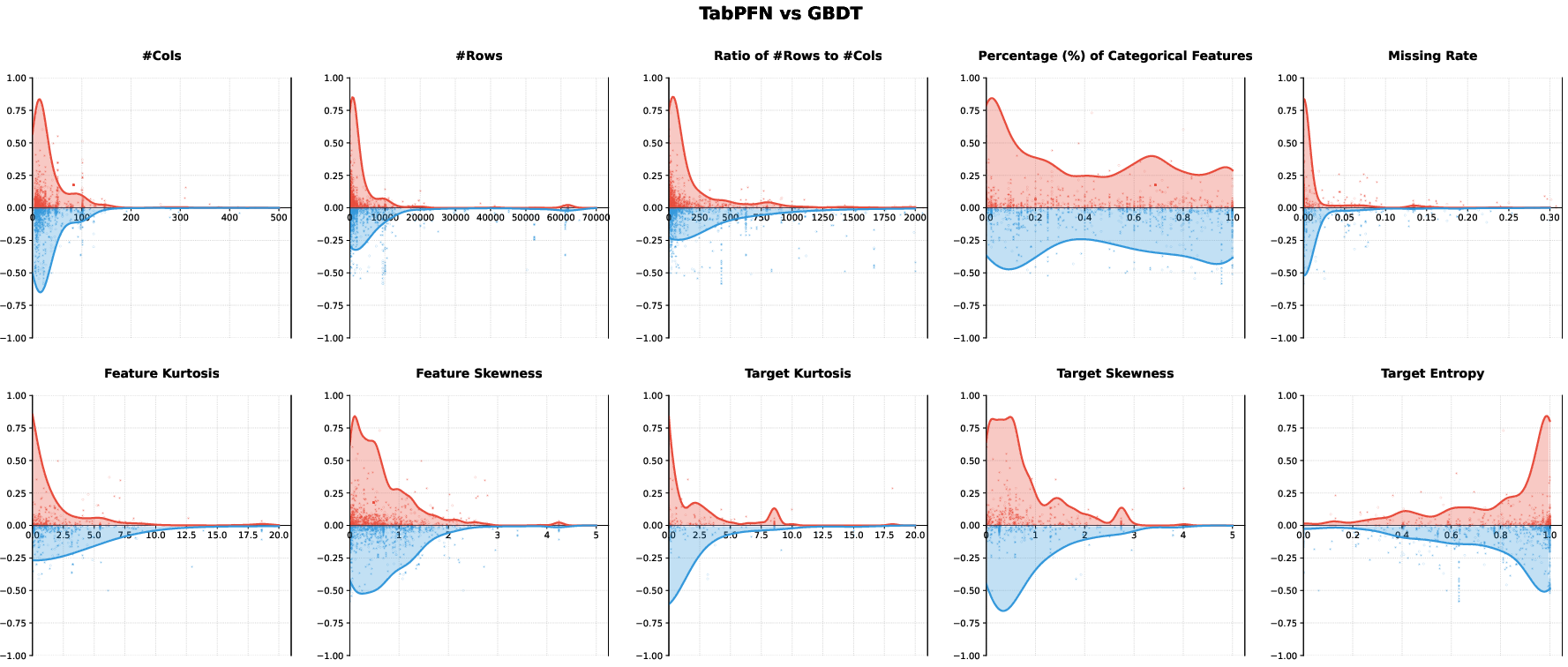
Figure 8: Performance gap distribution between TabPFN and GBDT.
Implications and Future Directions
The findings have several implications for theory and practice:
- No single paradigm dominates: Large-scale, unbiased benchmarks are required to draw robust conclusions regarding model selection for tabular prediction.
- Meta-feature-driven guidance: Practitioners can leverage dataset characteristics—sample size, categorical ratio, distributional statistics—to guide algorithm selection dynamically rather than defaulting to entrenched model choices.
- Benchmarking methodology: Comprehensive meta-annotation (facilitated by LLMs) and deduplication are necessary for mitigating bias and enabling meaningful comparison.
- TFMs' practical scope: While tabular foundation models like TabPFN show compelling results on small/medium regular datasets, their applicability on larger/irregular scenarios remains constrained, motivating further research into scaling and architectural generalization.
- Toward reproducible and generalizable tabular ML: OmniTabBench, with its scale and annotation, can serve as a canonical benchmarking resource, fostering standardized evaluation and method development in the community.
Potential directions for advancing tabular modeling include transformer-based architectures with extended context capacity, meta-learning mechanisms sensitive to dataset diagnostics, and systematic methods for synthesizing or augmenting minority domains in underrepresented industries or sample regimes.
Conclusion
OmniTabBench establishes a new empirical frontier for tabular data research, offering unparalleled dataset scale, diversity, industry annotation, and meta-feature transparency. Empirical results reassert the context-dependent nature of model superiority, providing actionable insights into when specific learning paradigms are preferred. The resource sets a new standard for future benchmarking in tabular ML and is poised to catalyze further innovation and reproducibility in the field.

