- The paper presents a unifying pipeline that transforms multivariate PHM time series into structured tabular data, enabling direct comparisons across model types.
- The paper demonstrates that Tabular Foundation Models achieve state-of-the-art performance in both prognostics and diagnostics with notable data efficiency and robustness to missing data.
- The paper illustrates that preserving temporal context through careful windowing is crucial for accurately capturing degradation patterns and improving health management predictions.
Unified and Data-Efficient Prognostics and Health Management with Tabular Foundation Models
Introduction
This work introduces a rigorous framework for leveraging Tabular Foundation Models (TFMs) for Prognostics and Health Management (PHM), focusing on heterogeneous, fragmented, and small-data industrial time series tasks. The authors formalize a unifying pipeline for transforming raw unit-level PHM signals into both sequence and tabular representations, which enables a direct, reproducible comparison of tabular foundation models (e.g., TabPFN, TabDPT) with deep sequence models (LSTM, transformer-based, CNN) and gradient-boosted trees (XGBoost) across a broad PHM benchmark.
The central thesis is that, by reframing multivariate time-series PHM problems as structured tabular completion tasks, TFMs can exploit large-scale synthetic/real pretraining and in-context inference to achieve robust, scalable, and data-efficient performance on both prognostics and diagnostics under practical constraints of missingness, label scarcity, and operational heterogeneity.
Unified Tabularization Pipeline for PHM
The authors propose a multi-stage pipeline, which (i) extracts temporally aligned features from raw condition-monitoring data, (ii) slices these features into overlapping/contiguous windows according to task semantics, and (iii) flattens them into tabular rows suitable for TFMs. This unified representation preserves diagnostic/prognostic target alignment, accommodates irregular sampling, and enables strict partitioning for leakage-free evaluation or in-context adaptation.
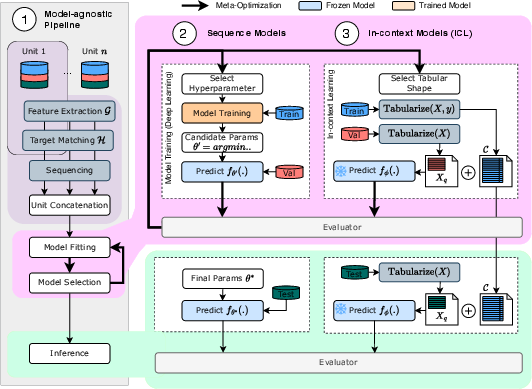
Figure 1: The pipeline transforms raw PHM signals into tabular feature--target windows, compatible with both sequence and tabular models, with strictly controlled validation/test protocols.
Key engineering contributions include explicit temporal alignment, agnostic feature/target transformations, support for both inter-unit and intra-unit splitting, and context-controlled in-context learning setups. This framework allows for invariant information content between sequence and tabular representations, isolating model from preprocessing or sampling effects.
Benchmarking Tabular Foundation Models
A comprehensive empirical study is conducted on six representative PHM benchmarks covering battery, bearing, turbofan engine, filtration system, hydraulic, and HVAC datasets. The evaluation pipeline enforces strict protocol unification: every model observes information-equivalent slices, with all pipeline parameters (normalization, alignment, tabularization) estimated exclusively from pre-partitioned training splits to eliminate leakage.
TFMs (TabPFN, TabDPT) operate in pure in-context learning mode (zero-shot, no parameter update) and are compared to deep sequence models (LSTM, CNN, PatchTST, Crossformer, Spacetimeformer, TiDE), XGBoost, and simple baselines (linear, exponential, MLP).
Main Empirical Findings
Cross-Task Robustness and Ranking
TFMs achieve the best or second-best average ranks on both normalized MAE (prognostics) and macro-F1 (diagnostics) across all tasks, outperforming or matching the best sequence models or XGBoost baselines. Notably, TabPFN and TabDPT provide robust, state-of-the-art performance without any task-specific retraining or architectural tuning, with strong performance especially in highly fragmented, low-data, or missingness scenarios.
Data-Efficiency and Subsampling Properties
TFMs, especially TabPFN, demonstrate pronounced sample efficiency. Strong results are achievable with as little as 1--10% of available context data, provided the context covers all relevant regimes/classes. Performance gains saturate quickly as context support increases, which highlights the strong inductive bias and generalized inference emerging from pretrained PFNs.
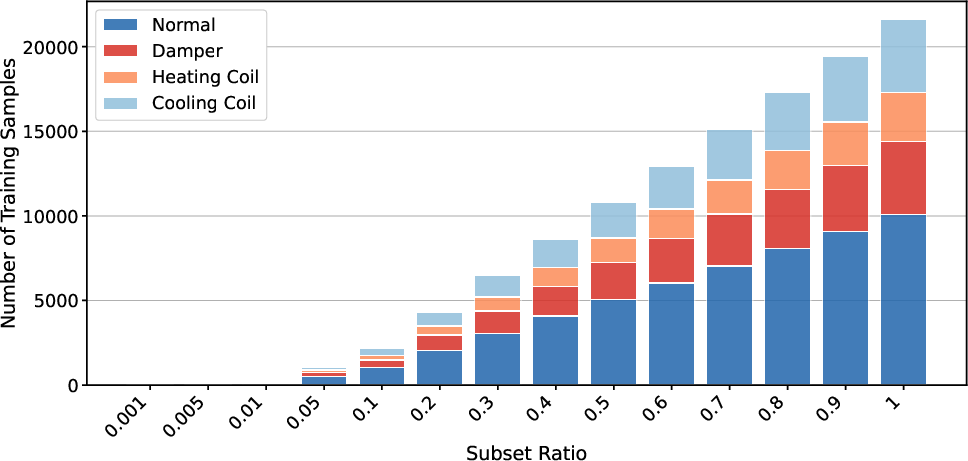
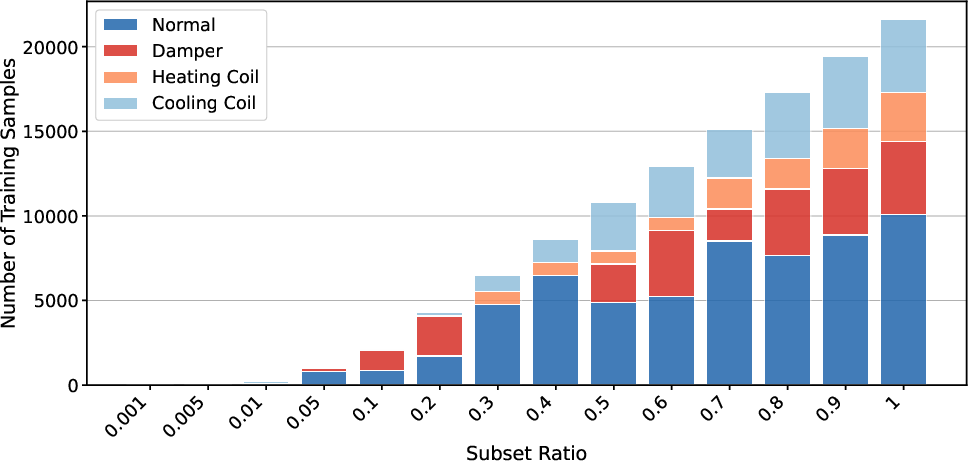
Figure 2: Model performance as a function of subsampled context size, illustrating the data-optimal regime for PFN-based models.
Blockwise (non-uniform) subsampling further reveals that context representativity is more crucial than context mass: non-representative but larger context sets yield lower accuracy than small yet diverse ones.
Temporal Structure Preservation
Increasing sequence window length improves TFM performance in datasets where degradation evolves with temporal context (e.g., PHME20, Unibo, XJTU-SY). TabPFN, which tokenizes cell-wise in the flat sensor-time grid, is able to extract temporal and causal dependencies even after flattening, while TabDPT (row-based) is less sensitive to extended context.
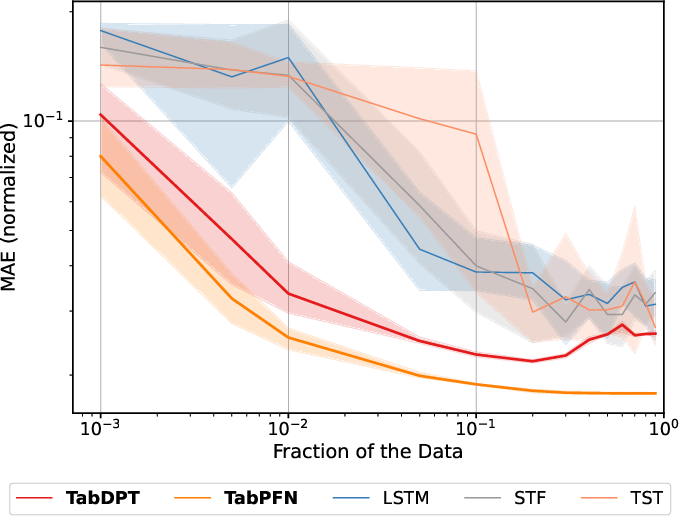
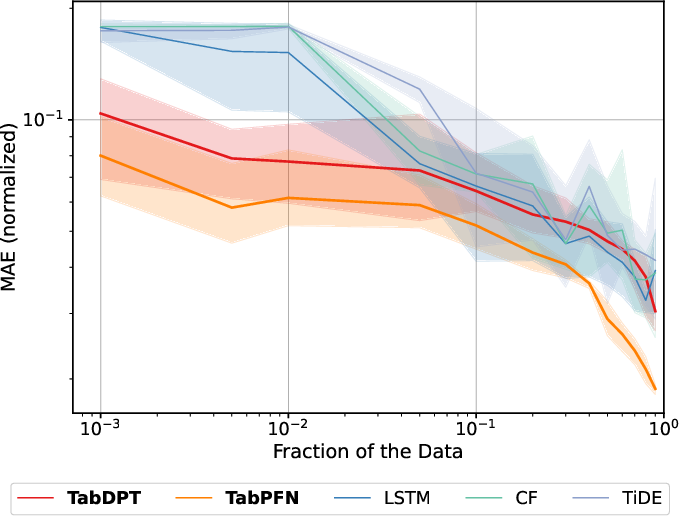
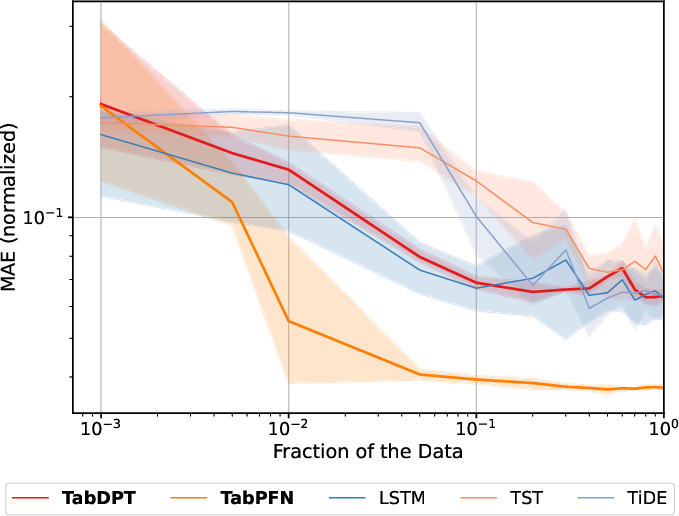
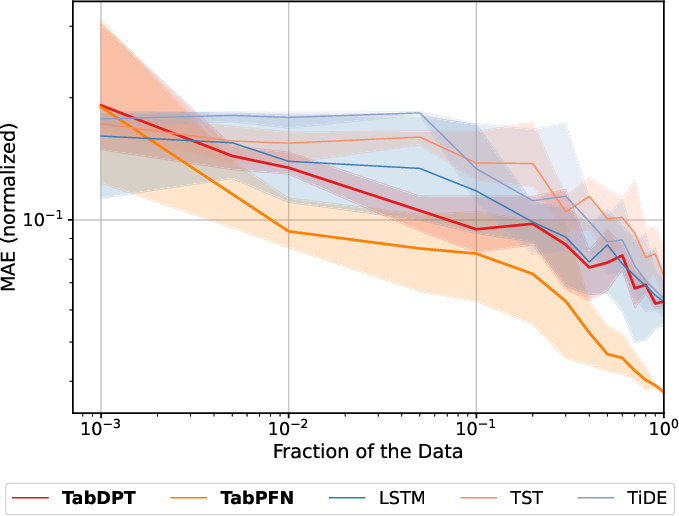
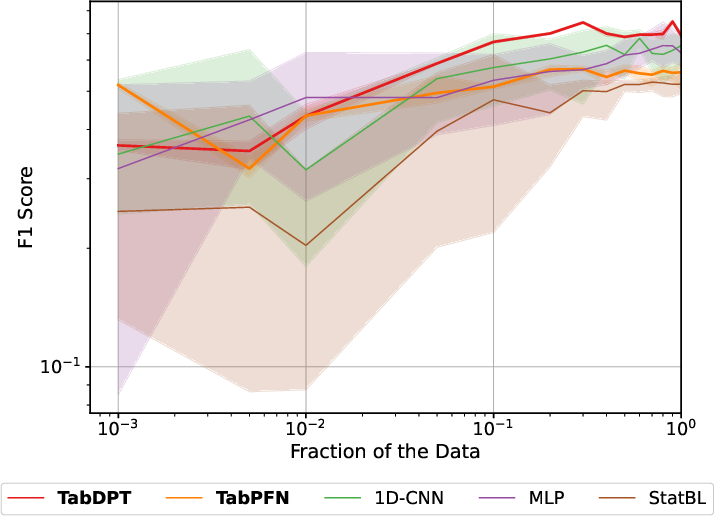
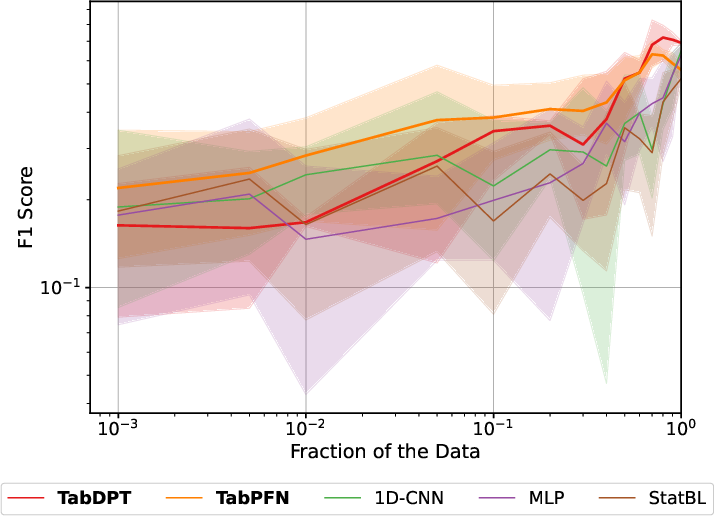
Figure 3: Effect of expanding lookback window (sequence length) on TabPFN and TabDPT normalized MAE.
For datasets dominated by regime variability or non-stationarity (e.g., N-CMAPSS), more context does not always help, reinforcing the need for distributionally matched context rather than pure temporal expansion.
Missing Data Handling
TFMs remain the top performers when evaluated on deliberately incomplete PHM signals. Classical imputation (e.g., LOCF) is often preferred over TabPFN's internal NaN-token mechanism for normalized MAE, suggesting dataset-dependent missingness representations.
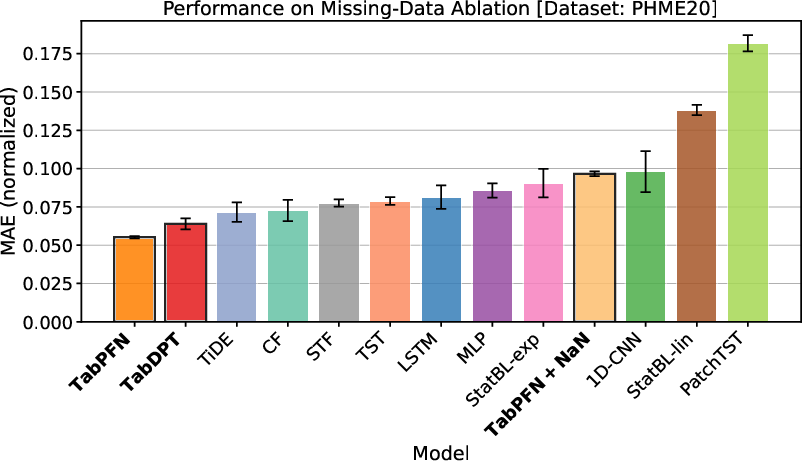
Figure 4: Evaluation of different imputation strategies for TabPFN on PHME20 normalized MAE.
Probabilistic and Calibration Properties
TabPFN inherently produces a predictive distribution, not just point estimates. Visualization of predictive quantile bands over holdout units in RUL regression reveals sharply concentrated, monotonic trajectories along the ground-truth run-to-failure progression, particularly when supplied with longer temporal windows.
Diagnostics: TFMs in Classification Tasks
TFMs extend their strong data-efficient performance to diagnostics/fault-classification regimes, again achieving the best aggregate ranks on Macro-F1/AUROC/Accuracy. Notably, tabular foundation models and XGBoost excel on hydraulic, HVAC, and concept-classification tasks, whereas transformer-based sequence models lag considerably in these settings.
Theoretical and Practical Implications
The study demonstrates that for fragmented, sparse, and operationally heterogeneous PHM workloads, TFMs decouple model selection from task and preprocessing choices, providing a general-purpose modeling paradigm that scales across diagnostics and prognostics regimes. This generality stems from both universal structural priors in PFN pretraining and the tabularization operator’s information preservation. The approach reduces hyperparameter search to tabular-shape selection (lookback length, context size), avoiding repeated resource-intensive retraining.
The framework also demonstrates that context-driven in-context inference is not only competitive but often superior, especially for industrial PHM scenarios typified by class imbalance and operational domain shift. The findings motivate further deployment of context-driven tabular FMs for industrial asset management, battery health, and rotational machinery, especially where labeled run-to-failure data is rare.
Practically, re-purposing the validation set into the context pool at inference time offers dual utility for model selection and generalization, a property seldom realized in conventional deep architectures.
Limitations and Future Directions
Several key open areas remain. The fidelity of the tabular representation is subject to the representativity of in-context support; coverage over rare regimes/faults is essential. TFMs are subject to inference-time complexity proportional to the context row number × tabular dimensionality; further work on per-variate or per-timestep compression and context selection is required.
Extending the methodology to agentic PHM system design, where LLMs/TFMs reason over preprocessing, method orchestration, and tool selection, is a promising path for scaling reproducible PHM. Integration with agentic tool selection, e.g., via modular PHM frameworks and agent-based orchestration (Theiler et al., 27 May 2026, Telyatnikov et al., 27 May 2026, Das et al., 2 Apr 2026), will be key to end-to-end industrial deployment.
Conclusion
This study establishes that Tabular Foundation Models, enabled by a principled tabularization framework, provide a reproducible, robust, and data-efficient baseline for PHM across diagnostics and prognostics under realistic industrial constraints. Their ability to learn from small, contextually rich samples, handle operational heterogeneity, and generalize without retraining makes them a compelling model class for the next generation of PHM systems. Further research into context selection optimization, integration with agentic toolchains, and expansion to larger/federated industrial settings is warranted.
References
- "Towards Unified and Data-Efficient Prognostics and Health Management with Tabular Foundation Models" (2606.05481)
- Benchmarking, methodology, and PHM context: (Telyatnikov et al., 27 May 2026, Theiler et al., 27 May 2026, Das et al., 2 Apr 2026)
- Prior-Fitted Networks and tabular FMs: [hollmanntabpfn], [hollmann2025accurate], [ma2024tabdpt], [quTabICL2025], [arbelEquiTabPFN2025]
- Tabular FMs for time series: [hooTabularFoundationModel2024], [caiExploreTimeSeries], [yeCloserLookTabPFN]
- Industrial PHM and foundation model evaluation: [zs2024machine], [finkPhysicsMachineLearning2026II], [dooley2024forecastpfn], [ansari2025chronos2], [wang2024tssurvey], [zhang_pdmbench_2025]