- The paper demonstrates that a row-wise attention-only model with gated stabilization and learnable registers achieves comparable performance to more complex TFMs.
- The adaptive early-exit mechanism enables per-instance dynamic computation, ensuring fast and efficient inference in latency-sensitive applications.
- Extensive benchmarking across diverse datasets validates TabSwift’s efficiency, robust accuracy, and scalability with minimal computational cost.
TabSwift: An Efficient Row-Wise Attention Foundation Model for Tabular Data
Context and Motivation
Tabular datasets, prevalent across domains such as healthcare, finance, and scientific research, have long favored tree-based methods (e.g., GBDTs) over deep learning architectures due to their robustness and performance on heterogeneous, small-to-medium data. The emergence of tabular foundation models (TFMs), notably Prior-Fitted Networks (PFNs), has shown that transformer-based models pre-trained on synthetic distributions can perform strong in-context learning (ICL) without test-time updates, particularly in the small data regime. However, progress in TFMs has led to increasingly complex, resource-intensive backbones, incorporating elaborate feature-wise modeling (e.g., alternating row/column attention), thus undermining their deployment in latency-sensitive scenarios.
TabSwift re-examines the original row-wise attention-only PFN backbone, investigating whether with proper stabilization and lightweight global context mechanisms, such minimalist designs can achieve comparable performance and significantly greater inference efficiency. The authors also address per-sample dynamic computation via adaptive early-exit, enabling anytime prediction—a key practical concern absent from much prior TFM literature.
Architectural Design
TabSwift retains the pure row-wise attention backbone pioneered by TabPFN, eschewing column-wise mixing to minimize computational complexity. It introduces two principal architectural enhancements:
- Gated Attention Stabilization: Integrates an element-wise multiplicative gate after self-attention output (SDPA-output gating, equivalent to the G1 design in transformer LLMs), introducing an input-dependent nonlinearity shown empirically to aid optimization and induce sparsity in attention updates.
- Learnable Register Tokens: Prepends a small, trainable set of slot tokens to the token sequence at every layer. These serve as latent, task-shared slots accumulating global, context-specific representations, facilitating cross-row aggregation in the absence of explicit column attention.
Row Tokenization and Input Handling: Each input instance is zero-padded or PCA-reduced to a fixed maximum feature dimension, normalized/encoded into a dmodel-dimensional embedding, and, for support examples, label information is embedded as well. Register tokens are prepended and all tokens are fed into a stack of transformer layers, each executing only row-wise attention across the entire prompt, maintaining quadratic cost in the context size (typically small for ICL).
Prediction Heads and Pretraining: Separate lightweight MLP heads serve classification and regression tasks, trained jointly under a unified synthetic task distribution, enabling a single checkpoint to handle both problem types.
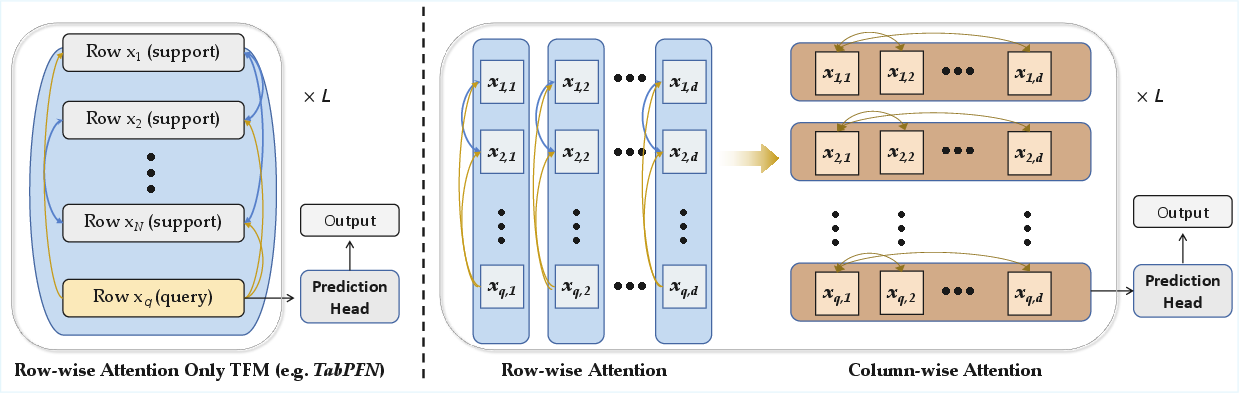
Figure 1: Schematic comparison of row-wise attention-only (TabSwift) versus alternating row/column attention patterns (TabPFN v2, TabICL), with the latter incurring higher per-layer computational cost.
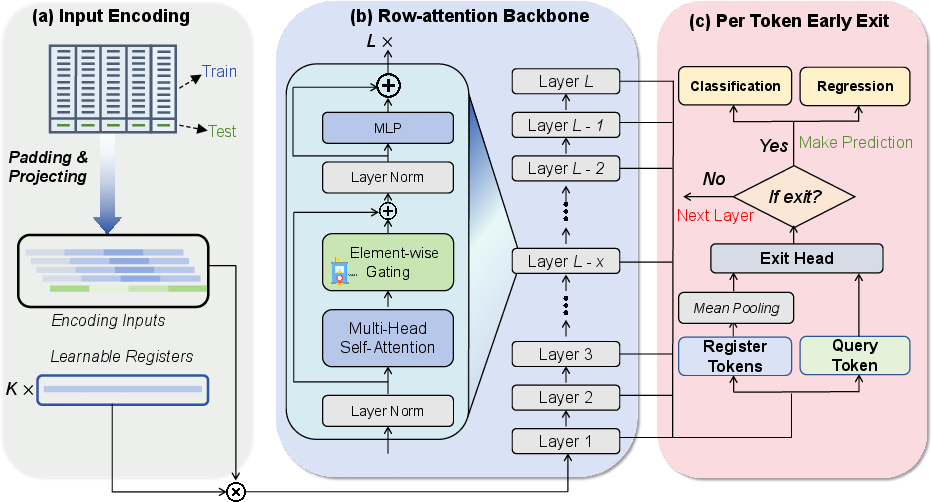
Figure 2: Overview of the TabSwift architecture: input encoding, row-wise transformer backbone with gated attention and registers, and adaptive per-sample early-exit mechanism.
Adaptive Early-Exit for Anytime Inference
Recognizing that not all queries require full-depth computation, TabSwift introduces a lightweight layer-wise early-exit mechanism. Auxiliary heads are attached to late transformer layers, each outputting both a task prediction and a reliability/confidence signal (exit score). At inference time, the model traverses layers sequentially and stops at the earliest exit whose score exceeds a tunable threshold τ. This policy is strictly per-query, not relying on batch or test-set statistics, making it directly applicable to real-world low-latency serving contexts.
The exit head optionally pools register tokens for improved context awareness, and is trained to directly predict correctness (classification) or error margin (regression) of the current prediction.
Main Results: Accuracy, Efficiency, and Trade-offs
Benchmarking: TabSwift was benchmarked on the TALENT suite, comprising 200+ classification and 100 regression datasets of diverse structure and scale, against classical ML methods (SVM, XGBoost, CatBoost), deep tabular models (MLP, NODE, TabNet), and state-of-the-art TFMs (TabPFN v2, TabICL, LimiX).
Performance–Efficiency Frontier: Across both classification and regression, TabSwift achieves a mean rank comparable to the strongest TFMs, and is not significantly different from the top performers by Wilcoxon–Holm statistical tests. This is achieved at a fraction of the inference cost; the accuracy–efficiency trade-off distinctly favors TabSwift. Empirically, with 16-model ensembles, it remains faster than TabPFN v2 and LimiX using only 4-model ensembles.

Figure 3: Performance, inference efficiency, and model size comparison on the TALENT benchmark. TabSwift achieves comparable average rank to state-of-the-art TFMs at markedly reduced inference cost and with a smaller model footprint.
Qualitative Analysis: PAMA analyses (percent-of-tasks-best) demonstrate that TabSwift achieves the best or tied-best result in a consistently large fraction of datasets, indicating that average performance is not driven by outliers but by robust modeling across a spectrum of real-world tables.
Ablations confirm that both gated attention and register tokens are necessary for achieving top accuracy and training stability in the minimalist backbone.
Adaptive Early-Exit Behavior: Early-exit yields clear accuracy–compute Pareto frontiers. The majority of samples can be predicted accurately at shallow layers, with only difficult/ambiguous cases requiring full-depth processing. Learned exit heads, especially when conditioned on register tokens, outperform entropy-based confidence heuristics.
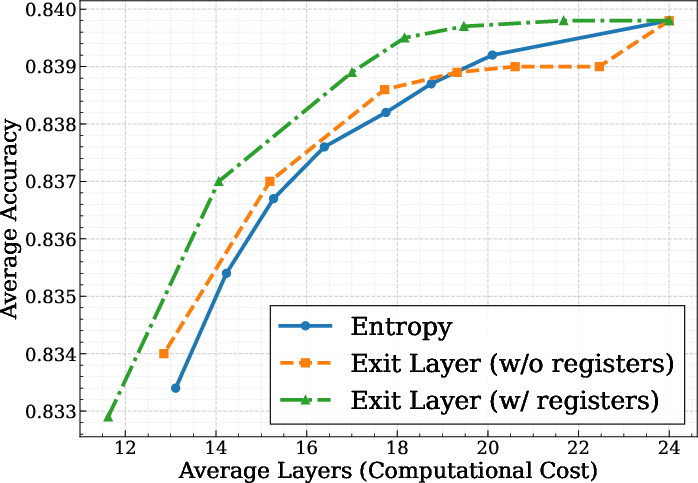
Figure 4: Average accuracy versus average executed layers as early-exit threshold τ varies, highlighting the accuracy-EFlayers tradeoff, and showing the benefit of register-conditioned exit heads.
Visualization of query embeddings shows that deeper exits correspond systematically to samples close to class boundaries, supporting the intuition that sample-wise difficulty is modulated by the learned exit head.
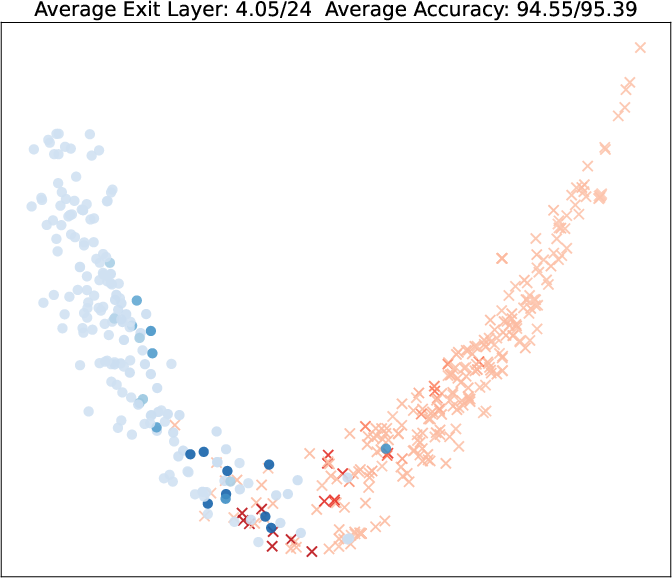
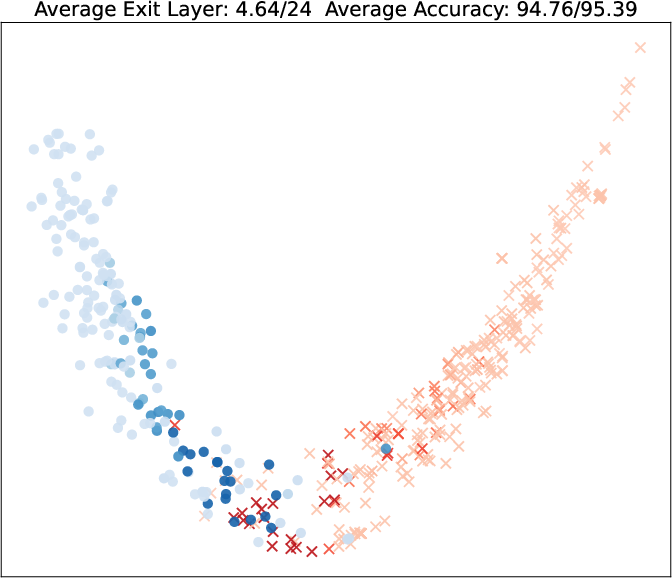
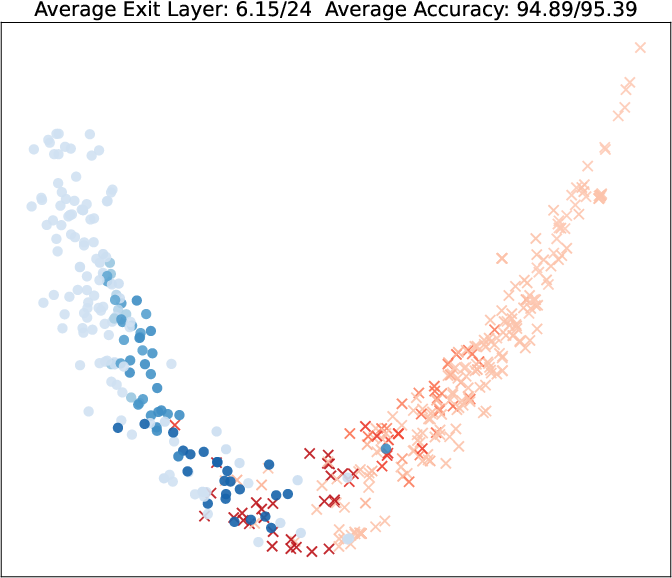
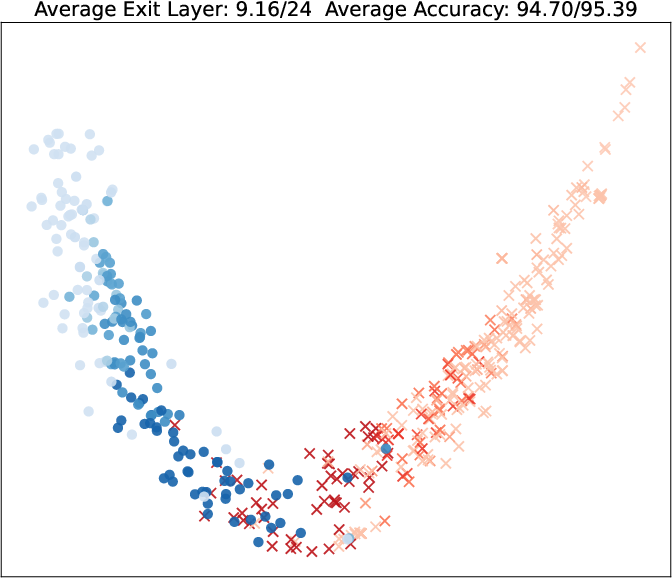
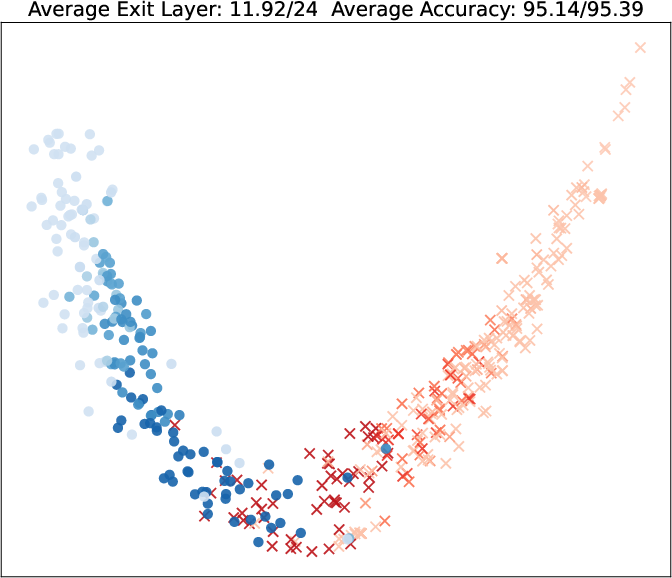
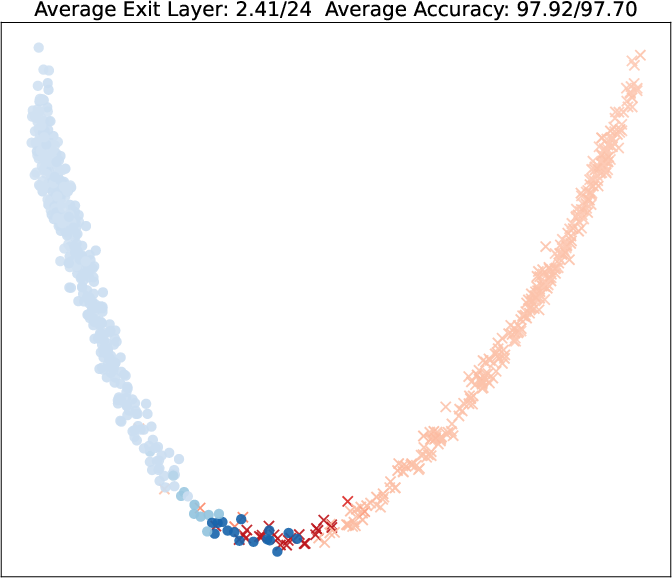
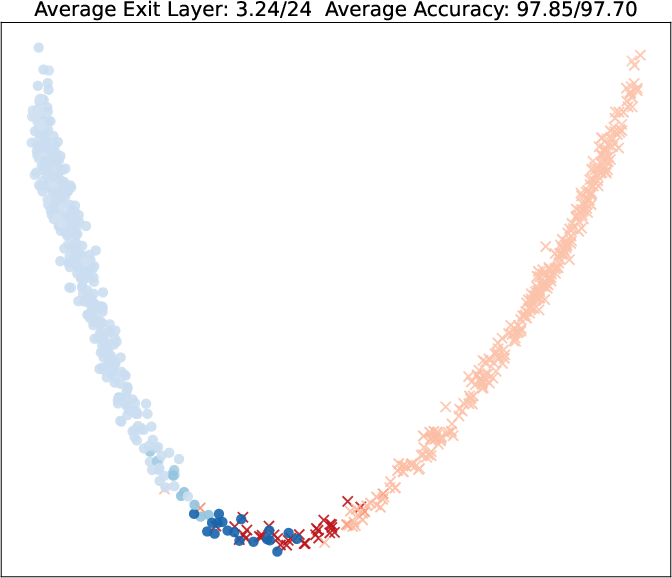
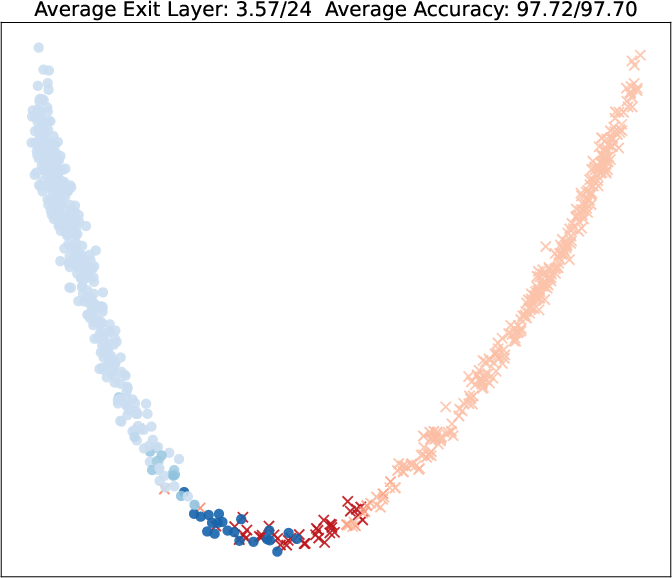
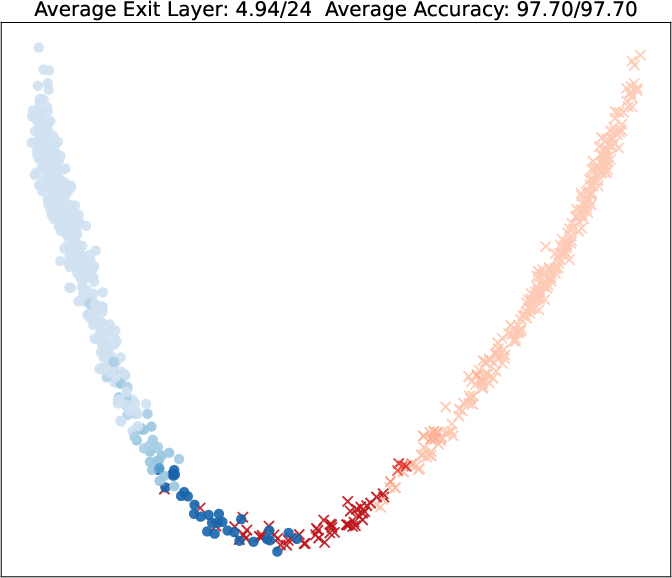
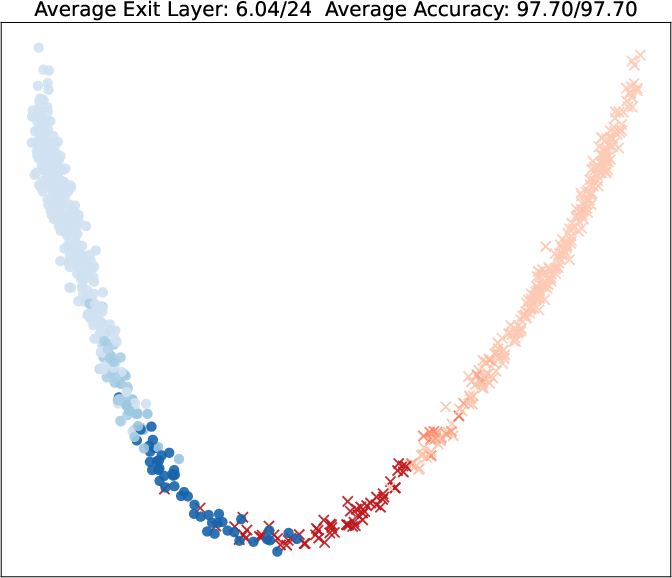
Figure 5: PCA projections of query embeddings on two binary datasets; color and opacity indicate predicted class and exit depth, respectively, as τ increases.
Inference time traces confirm TabSwift's consistently superior runtime, especially as dataset size and feature count grow.
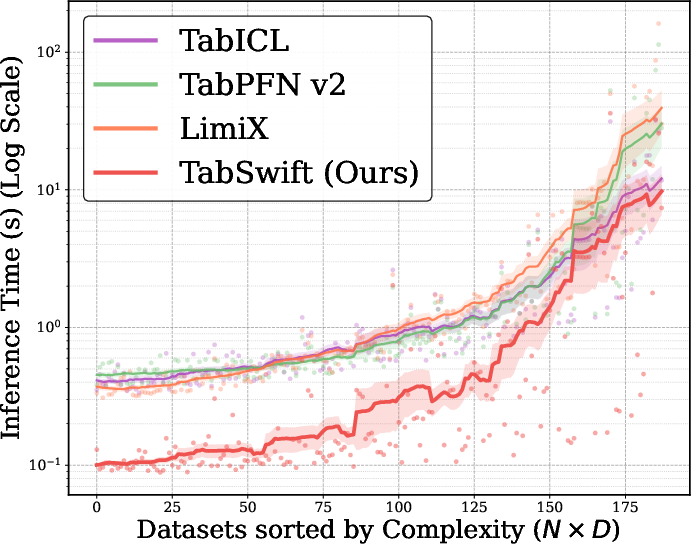
Figure 6: Inference time across TALENT datasets (log scale), sorted by dataset complexity. TabSwift maintains favorable scaling as N and d increase.
Limitations and Implications
TabSwift's architectural efficiency is inherently coupled to the quadratic scaling of row-wise attention, which may become prohibitive for very large support contexts (large-N regime). High-dimensional settings are handled via PCA pre-processing, which, while effective, is ad hoc and may limit performance when feature semantics are critical. Nonetheless, performance remains competitive up to the tested domain boundaries.
From a practical standpoint, TabSwift enables foundation-model-style deployment on tabular data with strict constraints on compute and latency, offering anytime inference and removing the need for extensive hyperparameter tuning or complex embedding engineering.
Theoretically, the strong performance of the minimalist row-only backbone—when enhanced by appropriate stabilization (gated attention) and global context (registers)—contradicts the intuition that explicit feature-wise modeling is always required for effective cross-task generalization in tables. The results suggest that per-instance and per-layer adaptation, if provided robust training signals and global context slots, can suffice for a broad class of table learning tasks.
Future Directions
- Scaling to Large-N: Exploration of more scalable attention mechanisms (e.g., linear attention, locality-sensitive hashing) or hybrid architectures for further efficiency gains.
- Improved Feature Encoding: Learning improved input encodings for mixed type, missing, or high-cardinality features without the reliance on PCA or zero-padding.
- Transfer to Even Broader Settings: Generalization to other structured data regimes—time-series, ranking, multi-label, or relational tables—is a promising avenue, given the unified backbone formulation.
- Automated Model Selection/Ensembling: The observed complementarity among diverse TFM backbones suggests that meta-learning strategies for automatic method selection or ensembling could further enhance tabular in-context learning.
Conclusion
TabSwift demonstrates that a minimally complex, row-wise attention-only transformer can, with simple gated attention and global registers, match or exceed the accuracy of more elaborate TFMs on both classification and regression, while offering a favorable computational footprint and true anytime inference via learned early-exit. These findings challenge prevailing assumptions about the necessity of heavyweight feature-wise modeling in TFMs for practical tabular ML and establish a new efficiency baseline for foundation model deployment in tabular analytics (2606.07345).