Realtime-VLA FLASH: Speculative Inference Framework for Diffusion-based VLAs
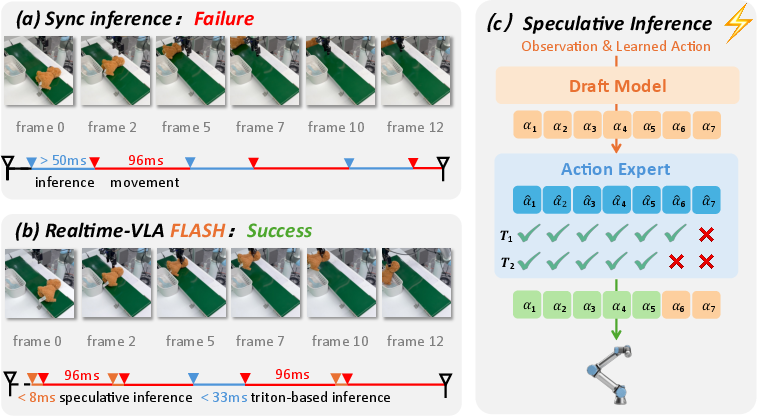
Abstract: Diffusion-based vision-language-action models (dVLAs) are promising for embodied intelligence but are fundamentally limited in real-time deployment by the high latency of full inference. We propose Realtime-VLA FLASH, a speculative inference framework that eliminates most full inference calls during replanning by introducing a lightweight draft model with parallel verification via the main model's Action Expert and a phase-aware fallback mechanism that reverts to the full inference pipeline when needed. This design enables low-latency, high-frequency replanning without sacrificing reliability. Experiments show that on LIBERO, FLASH largely preserves task performance by replacing many 58.0 ms full-inference rounds with speculative rounds as fast as 7.8 ms, lowering task-level average inference latency to 19.1 ms (3.04x speedup). We additionally demonstrate effectiveness on real-world conveyor-belt sorting, highlighting its practical impact for latency-critical embodied tasks.


Paper Prompts
Sign up for free to create and run prompts on this paper using GPT-5.
Top Community Prompts
Explain it Like I'm 14
Overview
This paper is about making robot brains that use vision and language much faster at deciding what to do next. The authors introduce a method called Realtime-VLA FLASH. It helps robots react in real time by letting a small, fast “draft” model guess the next actions, while a bigger, smarter model quickly checks those guesses. If the guess looks safe, the robot executes it right away. If not—or if the task is in a delicate phase—the robot switches back to the full, slower but very accurate process. This cuts waiting time a lot without losing reliability.
What questions does the paper try to answer?
- How can we reduce the delay (latency) in robots that use complex AI models, so they can replan and act fast in changing situations?
- Can we safely skip most of the long, full-thinking steps by using a quick guess-and-check method?
- How do we “check” guesses for models that work with smooth, continuous actions (not words or tokens), where there isn’t an obvious probability to compare?
How does the method work?
Think of a robot hand trying to grab a moving object on a conveyor belt. The world changes every moment, so the robot needs fresh, accurate actions quickly. Big models can decide well but are slow. FLASH combines speed with safety using a few ideas:
The problem in plain terms
- Robots often use a “vision-language-action” model (VLA): it looks at images, reads instructions, and outputs a sequence of future moves (an action chunk).
- These models are “diffusion/flow-matching” based, meaning they build the final actions step by step. That’s powerful but slow.
- Robots control motors many times per second, but the model can’t keep up, so decisions get stale—like following old GPS directions after the road has changed.
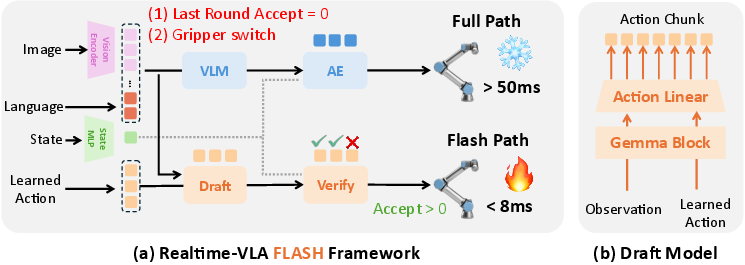
The main idea: draft fast, verify smart
- A small model makes a quick draft of the next actions (like a fast sketch).
- The big model doesn’t redo everything. Instead, it “spot-checks” the draft at a few smart points in parallel to see if it’s consistent with what the big model would conclude.
- If the draft looks good, the robot executes the longest safe prefix of that draft. If not, it falls back to the full slow path for a refresh.
Draft model (the “fast sketcher”)
- A lightweight network (much smaller than the main model) takes in the current camera views, the instruction, and the robot’s state, then predicts the whole next action chunk in one shot.
- It’s cheap to run, so the robot can propose new moves quickly.
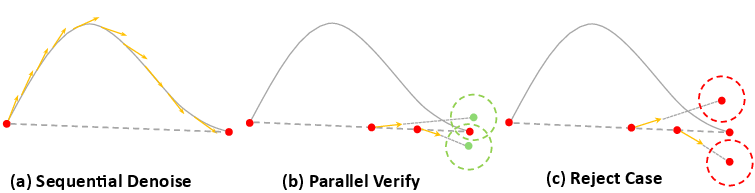
Parallel verification (the “spot checks”)
- The main model was trained with “flow matching,” which teaches it how to move from random noise to a good final action along a smooth path.
- To check a draft quickly, the system picks a few points along this path (imagine checkpoints on a route), asks the main model what the final action would be if we started from those points, and compares that to the draft.
- If the draft and the model’s reconstruction match closely at all these checkpoints, the draft is considered safe for a certain number of steps. The robot then executes that accepted prefix immediately.
Analogy: You don’t redraw the entire map to verify your route. You check a few landmarks to confirm you’re on track.
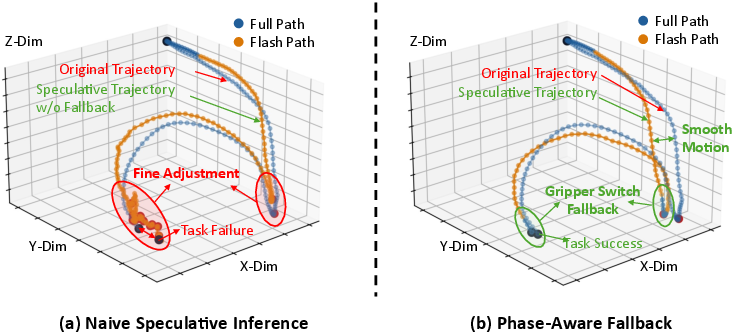
Phase-aware fallback (knowing when to be extra careful)
- Some moments need extra precision, like when the gripper is about to close or open. Small errors here can cause failure.
- The system watches for gripper “switches” (open/close). If a switch is coming up in the draft, it automatically switches back to the full, high-fidelity process to avoid mistakes.
What did they find?
In both simulation and the real world, FLASH made planning much faster while keeping performance high:
- In the LIBERO robot benchmark:
- Full rounds took about 58.0 ms. FLASH’s speculative rounds took as little as 7.8 ms.
- Overall average planning time dropped to 19.1 ms per round, a 3.04× speedup.
- Per-action latency dropped about 2.63×.
- Success rates stayed almost the same (only a tiny drop), meaning the robot stayed reliable.
- In real conveyor-belt sorting:
- The robot had to grab moving objects. With FLASH, it succeeded even at higher belt speeds (up to 15 m/min) where the slower methods failed.
- The main reason: faster planning meant the robot’s actions weren’t “stale,” so timing and positioning stayed correct.
Why this matters: For tasks where timing is critical—like catching moving items or making careful placements—lower latency means better reactions and higher success.
Why is this important?
- Faster, safer replanning lets robots handle more dynamic, real-world jobs: sorting on fast conveyors, picking objects on the fly, or adjusting a grip precisely.
- FLASH doesn’t replace existing models; it sits on top as a smart, efficient runtime. That means it can work alongside other speedups (like better kernels or quantization) for even bigger gains.
- The paper also shows a general way to do speculative inference for continuous actions—not just text. That’s useful for many robotics models that don’t use discrete tokens.
In short, Realtime-VLA FLASH gives robots a “fast sketch plus smart spot-check” brain. It cuts decision delays a lot while keeping reliability, making real-time robotic control more practical in the wild.
Knowledge Gaps
Knowledge gaps, limitations, and open questions
Below is a focused list of what remains missing, uncertain, or unexplored in the paper, phrased to inform concrete follow-up research.
- Acceptance criterion design: The verification relies on a fixed, heuristic distance threshold δ; there is no adaptive or learned rule that calibrates acceptance to task phase, state uncertainty, or observation drift.
- Verification timestep selection: The number and locations of verification timesteps are fixed and task-agnostic; no method is provided to choose or adapt online for better speed–accuracy trade-offs.
- Distance metric definition: The paper does not specify how rotation and translation distances are scaled or combined, nor whether per-axis or Mahalanobis metrics would reduce false (in)acceptance; metric learning is unexplored.
- Uncertainty calibration: Neither the draft nor Action Expert provides calibrated uncertainty estimates to gate acceptance; leveraging ensembles, dropout, or predictive variance for risk-aware acceptance is unaddressed.
- False acceptance/rejection characterization: There is no quantitative analysis of the rates and consequences of false acceptance/rejection under different tasks and phases, nor tools to diagnose when verification fails.
- KV cache staleness: FLASH reuses the visual KV cache across flash rounds without analyzing how observation drift degrades verification accuracy; criteria for cache time-to-live or refresh triggering remain unspecified.
- Noise choice in verification: Endpoint reconstruction uses a shared Gaussian noise ε but there is no study of sensitivity to ε, use of multiple ε samples, or adversarial/worst-case ε to reduce optimistic acceptance.
- Phase-aware fallback generality: Fallback uses gripper-switch heuristics, limiting applicability to tasks without binary grippers, with continuous contact phases, or with different effectors; learned phase detectors are not explored.
- Hybrid channel handling: The discrete gripper channel is only used for phase detection; correctness of discrete actions within accepted prefixes is not explicitly verified, leaving hybrid acceptance (continuous + discrete) underexplored.
- Long-horizon drift modeling: Periodic full-path refresh (PF) and gripper-triggered fallback are heuristic; there is no predictive model or controller for when drift will accumulate and how to optimally schedule refresh.
- Control stability and smoothness: Mixing flash and full-path actions may introduce jerks or oscillations; effects on trajectory smoothness, controller stability, and wear-and-tear are not measured or constrained.
- Safety and constraint compliance: Acceptance checks only action similarity, not kinematic limits, collision risk, or force constraints; integrating constraint-aware verification is left open.
- Applicability beyond flow matching: The approach is tailored to flow-matching dVLAs; extensions to DDPM-style diffusion, one-step distilled policies, or non-ODE action generators are not investigated.
- Draft model training and transfer: Drafts are trained via supervised regression to full-path outputs and per-suite; generalization to new tasks/domains/embodiments, online adaptation, and cross-suite transfer are untested.
- Perception compute reuse: Flash rounds still run the image encoder; strategies to cache or amortize perception (e.g., feature reuse, lower-rate frames, token pruning) in the flash path are unstudied.
- Hyperparameter sensitivity: Systematic sensitivity to chunk size , replan interval, δ, , PF frequency, and prefix acceptance rules is only partially ablated; principled tuning or auto-tuning is absent.
- Hardware and deployment scope: Results are limited to an RTX 4090D; performance on edge GPUs/CPUs, with strict power budgets, or under resource contention is not evaluated.
- Asynchronous integration: Experiments avoid asynchronous inference and real-time chunking; how FLASH composes with latency-hiding pipelines, schedulers, and multi-threaded control loops is unexplored.
- Real-world breadth and robustness: Real-world tests cover two objects and 10 trials/condition; robustness to broader object sets, lighting/occlusion changes, motion blur, and sensor noise is not quantified.
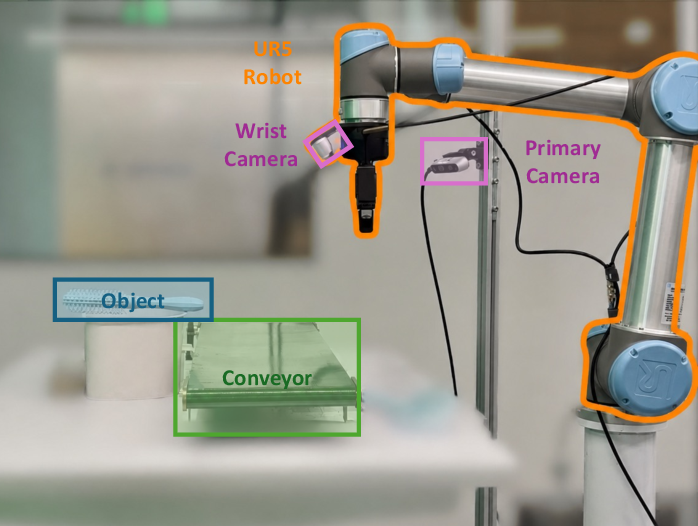
- Multi-arm/mobile settings: Only a single-arm UR5 is evaluated; behavior in bimanual, mobile manipulation, or highly dynamic, contact-rich tasks (e.g., tool use) remains unknown.
- Theoretical guarantees: There is no formal analysis that local flow consistency at intermediate timesteps implies endpoint or task-level correctness; bounds on acceptance error and safety under stale context are missing.
- Failure-mode taxonomy: Beyond a few qualitative examples, there is no systematic categorization of failure cases (e.g., verification under stale cache vs. phase misdetection) to guide targeted improvements.
- Compositional acceleration: Only partial combination with Triton is shown; how FLASH composes with quantization, pruning, TinyVLA/SmolVLA, or one-step distillation—and the joint Pareto frontier—is not mapped.
- Evaluation metrics: Besides success rate and latency, task quality metrics (precision, timing error, grasp pose error) and their correlation with speculative decisions are not reported.
Practical Applications
Overview
Realtime-VLA FLASH introduces a speculative inference framework for diffusion/flow-matching vision–language–action (dVLA) policies that replaces many expensive full-inference replanning rounds with a lightweight “flash path.” A small draft model proposes an action chunk; the main model’s Action Expert verifies it in parallel at selected flow-matching timesteps; the system executes the longest verified prefix and falls back to full inference when verification fails or when a phase-aware heuristic (e.g., gripper switch) indicates precision-critical motion. This yields large latency reductions (e.g., ~3.04× task-level speedup, speculative rounds as fast as 7.8 ms) while largely preserving success rates, and enables real-time manipulation such as conveyor-belt sorting up to 15 m/min.
Below are concrete, actionable applications derived from these findings, organized by deployment horizon and linked to relevant sectors, potential tools/products, and key dependencies.
Immediate Applications
These can be deployed now with existing dVLA policies, a trained FLASH draft model, and standard GPU inference (optionally with Triton kernels).
- Robotics — Manufacturing and Logistics (Industry)
- Use cases:
- Conveyor-belt sorting and pick-and-place at higher belt speeds without changing hardware.
- Bin picking and kitting where objects move or are perturbed during approach.
- Real-time part handoffs between stations in assembly lines.
- Potential tools/products/workflows:
- “FLASH Runtime” as a drop-in ROS 2 controller that manages flash-path execution, parallel verification, and phase-aware fallback for UR, FANUC, or ABB arms.
- A monitoring dashboard exposing flash-path rate, accepted prefix length, and fallback frequency as production KPIs.
- Integration with Triton-optimized kernels to maximize throughput on RTX/Datacenter GPUs.
- Assumptions/dependencies:
- Availability of a flow-matching/diffusion dVLA (e.g., π0-style) with Action Expert and a trained lightweight draft model per task family.
- Stable perception (multi-view RGB-D or equivalent) and calibrated robot frames.
- Thresholds for verification/fallback tuned to task dynamics; compute budget for GPU inference on-prem.
- Warehouse Automation and E-commerce Fulfillment (Industry)
- Use cases:
- Picking from moving totes/conveyors; dynamic order consolidation where items are in motion.
- Delicate or thin-object handling where timing errors are costly (e.g., cosmetics, blister packs).
- Potential tools/products/workflows:
- FLASH-enhanced manipulator controller integrated into WMS/OMS, exposing “speed vs. success” tuning knobs (acceptance threshold, verification timesteps).
- Fleet-level A/B testing of speedups vs. success rate impacts using FLASH metrics.
- Assumptions/dependencies:
- Sufficient training data for the target SKU set and camera layouts; minimal domain shift.
- On-site GPU acceleration; throughput monitored to adjust acceptance/fallback parameters.
- Recycling, Agriculture Sorting, and Food Processing (Industry)
- Use cases:
- Sorting irregular items on fast-moving belts (e.g., recycling streams, fruit grading).
- Grasping deformable items where small delays cause pose shifts.
- Potential tools/products/workflows:
- FLASH-enabled grasping pipelines with domain-specific gripper-phase signals (e.g., suction on/off).
- Assumptions/dependencies:
- Reliable detection of grasp/release phases (gripper switch heuristic or equivalent signal).
- Robustness to debris/occlusion in vision for stable draft proposals.
- Service and Hospitality Robots (Industry/Daily Life)
- Use cases:
- Reactive handovers and pick-ups from moving trays or carts (e.g., hotel, restaurant runners).
- Home assistant manipulators responding promptly to object motion (rolling items, pet interactions).
- Potential tools/products/workflows:
- Consumer-tier “FLASH Lite” builds combining quantized VLAs with FLASH for edge GPUs.
- Safety-aware fallback policies activated near humans based on phase signals.
- Assumptions/dependencies:
- Additional safety interlocks; careful threshold tuning to avoid over-aggressive speculative execution around humans.
- Edge compute capable of sustaining <20 ms average inference.
- Teleoperation Support and Human-in-the-Loop Robotics (Industry/Academia)
- Use cases:
- “Predict-then-verify” buffers between operator updates to reduce perceived latency.
- Smoother intervention when network delays cause stale commands.
- Potential tools/products/workflows:
- Operator UIs showing acceptance/fallback status and upcoming precision phases.
- Assumptions/dependencies:
- Low-latency comms; proper arbitration between human commands and speculative control.
- Academic Research Acceleration (Academia)
- Use cases:
- Faster on-robot experimentation for reactive tasks (LIBERO-like benchmarks, real-world labs).
- Ablation studies on acceptance thresholds, verification timesteps, and phase-aware heuristics.
- Potential tools/products/workflows:
- Open-source FLASH modules (draft model trainer, verifier kernels, runtime scheduler).
- VLA-Perf plugins reporting action-level latency and flash-path statistics for reproducible papers.
- Assumptions/dependencies:
- Access to π0-style policies and datasets; minimal code changes to insert the FLASH path.
- Inference Systems and MLOps for Robotics (Software)
- Use cases:
- Integration of speculative inference for flow-matching policies into inference engines.
- Continuous monitoring of latency/success trade-offs in production.
- Potential tools/products/workflows:
- Kubernetes/ROS 2 deployments with per-robot adaptive thresholds driven by online metrics.
- Exported KV caches and verifier microservices to co-locate with robot pods.
- Assumptions/dependencies:
- Triton or comparable kernel optimizations; telemetry hooks for acceptance/fallback events.
- Policy and Standards — Benchmarking and Procurement Guidance (Policy)
- Use cases:
- Immediate adoption of latency-aware reporting: task-level latency, per-action latency, flash-path rate, accepted prefix length, and speedup vs. full path.
- Procurement checklists requiring “phase-aware fallback” and verification metrics for robots deployed near people.
- Potential tools/products/workflows:
- Public test protocols for latency-critical manipulation (e.g., moving-target grasp tests).
- Assumptions/dependencies:
- Cross-vendor agreement on metrics; sharing non-sensitive runtime stats for certification.
Long-Term Applications
These require additional research, validation, scaling, or standardization (e.g., enhanced phase detectors, stronger safety guarantees, or edge deployment constraints).
- Healthcare and Assistive Robotics (Industry/Healthcare/Policy)
- Use cases:
- Assistive feeding and dressing where reactive precision is critical.
- Surgical or interventional robotics for instrument positioning (as a research precursor, not for clinical use).
- Potential tools/products/workflows:
- Learned phase detectors beyond gripper signals (e.g., contact onset, force thresholds) to trigger fallback.
- Formal monitors certifying acceptance/fallback decisions with traceability.
- Assumptions/dependencies:
- Regulatory compliance (IEC/ISO); extensive validation and fail-safes; formal verification of acceptance rules.
- Autonomous Mobile Manipulation in Dynamic Environments (Industry)
- Use cases:
- Robots on AMRs picking from moving totes; last-meter package handling on moving platforms.
- Outdoor logistics (airport baggage handling, parcel cross-docking).
- Potential tools/products/workflows:
- Multi-sensor phase detection (vision, force, proximity) and task-aware adaptive thresholds.
- Assumptions/dependencies:
- Robustness to lighting/weather variation; domain-adaptive draft models; reliable multi-robot coordination.
- Drones and Field Robots (Industry/Energy/Agriculture)
- Use cases:
- Aerial grasping or interception (e.g., catching moving objects, perching on moving targets).
- Reactive contact tasks for inspection/maintenance in plants (valve turning on moving platforms).
- Potential tools/products/workflows:
- “Speculative Controllers” for UAVs/UGVs with flow-matching action heads and FLASH verification.
- Assumptions/dependencies:
- Tight real-time OS constraints; low-latency state estimation; high-rate sensing; safety envelopes.
- Household General-Purpose Robots (Daily Life/Industry)
- Use cases:
- Fast, reactive manipulation for tidying, dish loading, handling fragile items that may shift.
- Potential tools/products/workflows:
- On-device FLASH with quantized VLAs (“TinyVLA + FLASH”) that runs on home-grade edge hardware.
- Assumptions/dependencies:
- Further compression/quantization; robust, self-calibrating perception; user-safe fallback logic.
- Advanced Inference Techniques and Tooling (Software/Academia)
- Use cases:
- Trajectory-adaptive verification thresholds learned from data instead of fixed heuristics.
- Generalizing speculative verification to non-flow-matching continuous models.
- Potential tools/products/workflows:
- FLASH 2.0 SDK with learned phase detectors, uncertainty-aware acceptance criteria, and automated hyperparameter tuning.
- Assumptions/dependencies:
- Large-scale training for phase classifiers; uncertainty estimation calibrated to task risk.
- Fleet-Level Optimization and Cloud Robotics (Industry/Software)
- Use cases:
- Centralized policies serving many robots with per-robot adaptive speculative schedules.
- Joint optimization of throughput, energy, and safety by adjusting flash/full ratios.
- Potential tools/products/workflows:
- Cloud dashboards for acceptance/fallback telemetry; policy updates that auto-tune verification timesteps (K) and τ-sets per task/site.
- Assumptions/dependencies:
- Reliable networking; privacy/security; robust rollout of updated thresholds without downtime.
- Cross-Domain Real-Time Generative Control (Software/Media/Games)
- Use cases:
- Real-time motion synthesis and avatar control in AR/VR with flow-based controllers.
- Game AI agents with fast, verified continuous-action proposals for smooth animation.
- Potential tools/products/workflows:
- Engine plugins (Unreal/Unity) exposing speculative control for character motions.
- Assumptions/dependencies:
- Availability of flow-matching policies for motion; adaptation of verification metrics to kinematics.
- Standards and Compliance for Speculative Runtime Safety (Policy/Industry)
- Use cases:
- Safety standards codifying acceptance/fallback logging, auditable thresholds, and “phase-aware” overrides for robots near people.
- Certification procedures that test robustness under increasing target motion speeds.
- Potential tools/products/workflows:
- Compliance toolkits that record per-trial flash-path usage, accepted prefix statistics, and incident-aligned fallbacks.
- Assumptions/dependencies:
- Industry consensus; shared datasets and testbeds for latency-critical tasks; alignment with existing robot safety norms.
- Low-Power Edge and CPU-Only Deployments (Industry/Software)
- Use cases:
- Affordable robots running on CPU-bound platforms in SMEs, schools, and homes.
- Potential tools/products/workflows:
- Co-design with TinyVLA/quantization/pruning: “Edge FLASH” using 1–4 bit weights and verifier kernels targeting NPUs.
- Assumptions/dependencies:
- Additional compression and kernel engineering; possibly reduced horizon or smaller action chunks to fit budgets.
Cross-Cutting Dependencies and Assumptions
- Model prerequisites: A flow-matching/diffusion dVLA with an Action Expert and a trained lightweight draft model per domain/task family.
- Runtime design: Reuse of KV cache from recent full-path rounds; careful selection of verification timesteps and distance thresholds; robust handling of gripper or equivalent phase signals.
- Hardware/software: GPU or accelerated edge hardware; optional Triton or similar kernel optimizations; ROS 2 or equivalent runtime integration.
- Safety and reliability: Task-specific threshold tuning; monitoring of acceptance/fallback rates; more stringent requirements in human-facing or regulated settings.
- Data and generalization: Sufficient demonstrations for draft training; domain adaptation for new environments; resilience to sensor noise and occlusions.
By combining speculative drafting, parallel verification, and phase-aware fallback, FLASH enables immediate gains in latency-critical manipulation and lays a foundation for broader adoption of real-time, continuous-action generative control across industries.
Glossary
- acceptance criterion: A rule or measure for deciding whether to accept drafted outputs during speculative inference. "the absence of explicit likelihoods leaves no natural acceptance criterion."
- Action Denoise: The multi-step denoising stage that integrates a learned flow field to generate actions. "a multi-step Action Denoise stage under the learned flow field."
- Action Expert: The action-generation module that uses the cached context to produce or verify action chunks. "the Action Expert, which predicts the action chunk by solving an observation-conditioned ODE"
- action chunk: A contiguous sequence of future low-level actions produced and executed in segments. "and predicts a future action chunk"
- action head: The final linear layer that maps hidden representations to continuous action outputs. "through a linear action head."
- action queries: Learned query tokens appended to the input that prompt the model to predict future actions in parallel. "We then append H learned action queries to the input sequence"
- action throughput: The rate at which actions are generated/executed by the policy. "improving action throughput by 2.63×"
- arithmetic intensity: The ratio of operations to memory traffic used in roofline performance analysis. "145.79 is the balanced arithmetic intensity point."
- autoregressive generation: Producing outputs sequentially where each step depends on previously generated outputs. "Speculative Inference accelerates autoregressive generation"
- autoregressive VLAs: Vision-language-action models that generate actions token-by-token in sequence. "and extended to autoregressive VLAs"
- blockwise attention mask: An attention pattern that partitions tokens into blocks (e.g., prefix, state, action) with structured connectivity. "We use a blockwise attention mask to make these slots compatible with the reused VLM architecture."
- compute-bound regime: A performance regime where latency is dominated by computation rather than memory bandwidth. "primarily in the compute-bound regime"
- conveyor-belt sorting: A real-world robotic task where objects on a moving belt must be detected, grasped, and placed. "real-world conveyor-belt sorting"
- denoising velocity field: The model-predicted instantaneous velocity guiding denoising toward clean actions. "the Action Expert predicts the instantaneous denoising velocity field"
- diffusion-based vision-language-action models (dVLAs): Policies that generate continuous actions via diffusion or flow matching conditioned on vision and language. "Diffusion-based vision-language-action models (dVLAs) are promising for embodied intelligence"
- distance threshold: A tolerance bound on discrepancy between drafted and verified actions used to accept prefixes. "checks an action-by-action distance threshold"
- executable prefix: The longest accepted initial segment of a drafted action chunk that passes verification. "producing a dynamically sized executable action prefix."
- fine-adjustment phases: Task segments requiring high-precision control (e.g., grasp/release), where small errors can cause failure. "In fine-adjustment phases such as gripper switching"
- flow-consistency-based parallel verification: A verification method that checks draft consistency with the learned flow at multiple timesteps in parallel. "flow-consistency-based parallel verification"
- flow matching: A generative training/inference approach that learns a velocity field along paths from noise to data. "flow matching provides exactly such a structure."
- flow-matching interpolation paths: Linear interpolations between noise and actions used to verify consistency under flow matching. "using flow-matching interpolation paths"
- Gaussian noise: The random initial state from which denoising begins in diffusion/flow-matching generation. "interpolate it with Gaussian noise"
- Gemma block: A transformer block from the Gemma architecture reused to build the lightweight draft model. "The draft model uses a single Gemma block"
- gripper channel: The discrete action channel controlling open/close states of the gripper. "the gripper channel represents discrete open and closed modes"
- gripper switches: Events where the gripper mode toggles (open/close), used as signals for precision-critical phases. "FLASH also uses gripper switches as heuristic signals of upcoming fine-adjustment phases"
- interpolation timesteps: Intermediate times along the interpolation between noise and actions used for verification. "interpolation timesteps are sampled along linear paths between Gaussian noise and target actions"
- KV Cache: The key-value attention cache produced by the VLM and reused by the Action Expert for efficient inference. "Perceptual context is passed from the VLM to the AE through the KV Cache."
- LIBERO: A benchmark suite of simulated robotic tasks for evaluating VLA policies. "Experiments show that on LIBERO, FLASH largely preserves task performance"
- LoRA: Low-Rank Adaptation, a parameter-efficient fine-tuning method for large models. "and fine-tune the policy with LoRA for 20k steps."
- memory-bound: A performance regime where latency is dominated by memory bandwidth rather than compute. "In contrast, Action Denoise is memory-bound"
- observation-conditioned ODE: An ordinary differential equation whose dynamics depend on the current observation/context to produce actions. "predicts the action chunk by solving an observation-conditioned ODE"
- ODE-defined velocity field: A velocity field specified by an ODE that is integrated to produce actions under flow matching. "integrating an ODE-defined velocity field"
- open-loop action chunking: Executing a preplanned chunk of actions without immediate feedback until the next replan. "open-loop action chunking"
- parallel verification: Concurrently evaluating multiple verification timesteps to check draft consistency without full denoising. "with parallel verification via the main model's Action Expert"
- phase-aware fallback: A policy of reverting to full inference when task phase indicates high precision is needed. "a phase-aware fallback mechanism that reverts to the full inference pipeline when needed."
- prefix KV Cache: The cached attention state built from the VLM prefix tokens reused across rounds. "construct a prefix KV Cache."
- replan window: The number of steps between replanning events used to normalize accepted prefix length. "accepted prefixes covering 69.7% of the replan window"
- replanning: Regenerating an action chunk after executing a prefix to adapt to updated observations. "each replanning round still requires the same expensive full inference pipeline."
- roofline analysis: A performance model relating compute, memory bandwidth, and arithmetic intensity to identify bottlenecks. "and summarize the results with a roofline analysis"
- rollout: A trajectory segment produced by executing the policy during task execution. "evidence that the rollout has entered a fine-adjustment phase."
- speculative inference: An acceleration method where a lightweight draft proposes outputs that are verified by the main model. "Speculative Inference aims to reduce repeated inference cost"
- stochastic reverse process: The probabilistic backward dynamics used in diffusion models for denoising. "the stochastic reverse process"
- token-level probabilities: Probabilities assigned to discrete tokens enabling verification/acceptance in autoregressive models. "through token-level probabilities."
- Triton optimization: Using Triton kernels/system optimizations to accelerate inference. "with Triton optimization, FLASH runs speculative rounds as fast as 7.8 ms"
- verification timesteps: Selected times within the denoising schedule where consistency checks are performed. "We therefore evaluate a small set of verification timesteps"
- vision-LLM (VLM): A transformer that processes multimodal text-image inputs to provide context for action generation. "a pre-trained vision-LLM (VLM) backbone"
- visual KV Cache: The VLM-produced cache over visual tokens reused for efficient action verification. "reuses the visual KV Cache produced by the most recent full-path round"
- VLM prefill: The step of processing the multimodal prefix in the VLM to build the KV cache before action generation. "VLM prefill to construct the visual KV Cache"
Collections
Sign up for free to add this paper to one or more collections.