- The paper introduces a decoupled architecture that isolates data sampling from model updates, achieving up to 86% throughput gain over previous SOTA systems.
- It employs a four-thread asynchronous pipeline and dual-pool GPU VRAM management to optimize resource allocation and prevent hardware bottlenecks.
- Empirical results on π0.5 and OpenVLA-OFT workloads validate D-VLA's robust scalability and training stability in high-concurrency regimes.
D-VLA: Distributed Asynchronous RL for Vision-Language-Action Models
Introduction and Motivation
The development of Vision-Language-Action (VLA) models, which jointly perform multimodal perception, natural language grounding, and action generation, is a defining trend in embodied AI. While conventional training pipelines for such models typically emphasize supervised learning (e.g., behavior cloning or SFT), scaling embodied RL to billion- or trillion-parameter VLA architectures in high-fidelity environments is blocked by pronounced hardware and systems bottlenecks. The core contention arises from simultaneous demands for: (1) massive, high-frequency physics simulation and (2) high-throughput parameter updates and model inference—all competing for shared GPU and network resources.
Prior frameworks, such as RLinf-VLA and RL-VLA3, make incremental progress via hybrid resource allocation and asynchronous workflows. However, their system throughput is still often constraint-bound, particularly by interleaved synchronization of simulation and RL optimization steps. The D-VLA framework addresses these limitations via fundamental architectural innovations separating the frequency domains and resource profiles of simulation and optimization.
System Architecture: Plane Decoupling and Asynchronous "Swimlane" Execution
The D-VLA system introduces the concept of Plane Decoupling: it physically separates the high-throughput "Data Plane" (environment sampling and rollout collection) from the lower-frequency "Weight Control Plane" (model update and distribution). This isolation is operationalized via a four-thread asynchronous pipeline (the "Swimlane" model), allowing independent and concurrent execution of sampling, inference, optimization, and parameter broadcasting.
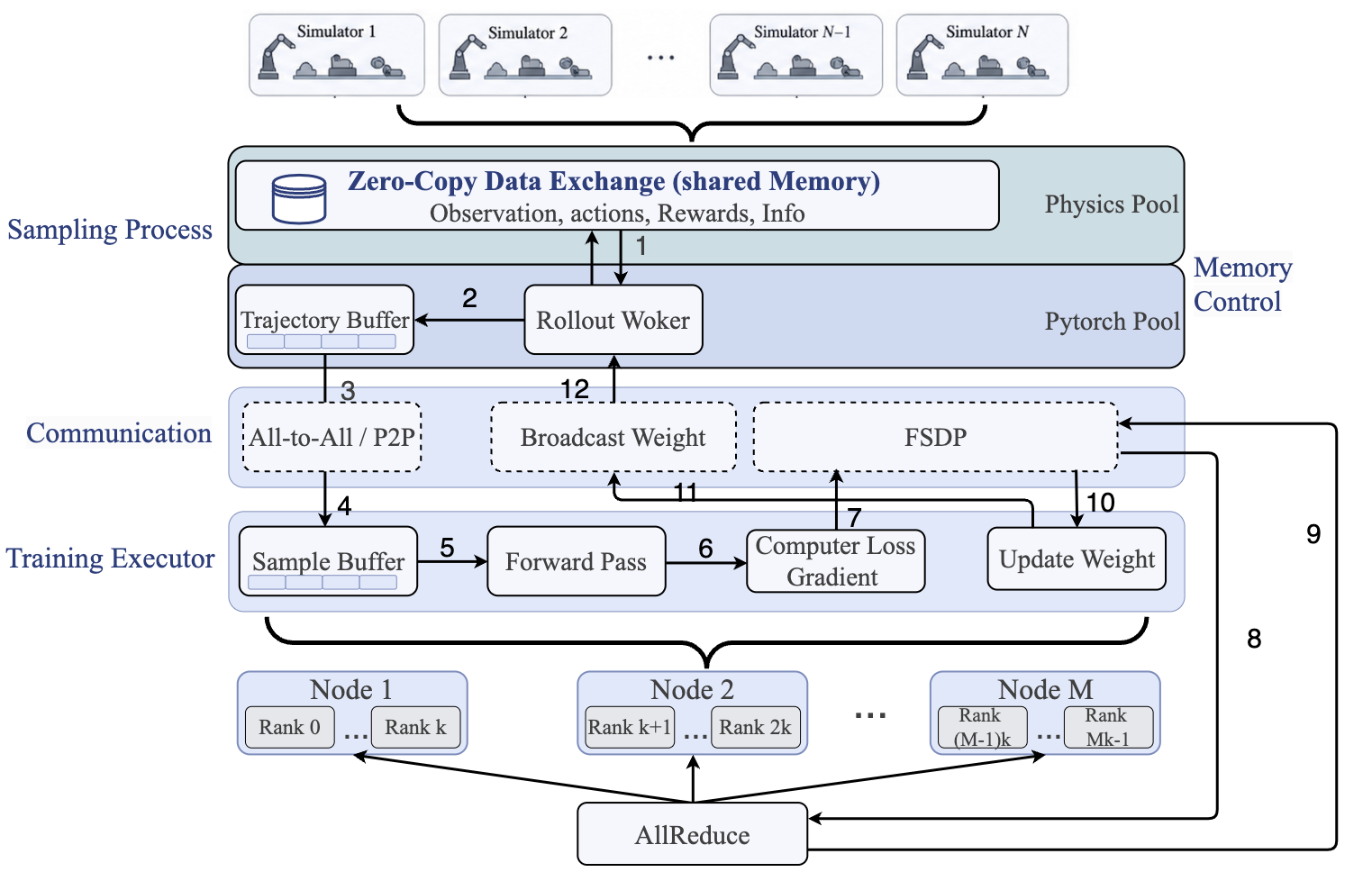
Figure 1: The D-VLA pipeline physically isolates high-frequency data sampling from low-frequency weight control, using dedicated GPU pools and asynchronous communication channels for maximal concurrency.
The D-VLA resource manager supports hybrid hardware partitioning strategies: environments and rollout modules may be colocated to optimize memory sharing, while actor/inference modules are isolated to avoid kernel-level interference. Flexible deployment enables both zero-copy local exchange and bandwidth-optimized pipeline communication for massively parallel simulation.
A key design feature is dual-pool GPU VRAM management—a distinct allocation for physics engine buffers versus model parameter/gradient storage—to eliminate fragmentation and avoid stalls from non-deterministic environment processes. Inter-component communication leverages topology-aware collective libraries for intra-node efficiency and falls back to CPU-based NCCL/Gloo primitives for inter-node synchronization, with all weight control decoupled from compute-intensive CUDA streams.
Experimental Evaluation and Empirical Results
D-VLA is validated on canonical VLA workloads (diffusion-based π0.5 and Transformer-based OpenVLA-OFT) within the ManiSkill GPU-parallelized simulation suite. System throughput, defined as environment transitions per unit time (equivalent to action inference rate under fixed chunking), is the central metric.
Comparative analysis against RLinf-VLA and RL-VLA3 across colocated, disaggregated, and hybrid orchestration demonstrates pronounced throughput gains:
- For π0.5 at a 3:1 environment-to-actor GPU partitioning, throughput of 237.0 steps/s is observed—an 86.26% increase over RLinf-co.
- In the OpenVLA-OFT regime, D-VLA achieves 156.0 steps/s, outpacing RLinf-co and RL-VLA3 by 44.4%.
The architectural asymmetries underlying system bottlenecks are made transparent by detailed latency breakdown. In π0.5, near-optimal balance between rollout and actor modules enables mutual masking and maximal pipeline utilization. For OpenVLA-OFT, resource imbalance emerges when the actor module's computational weight dominates, but adaptive rebalancing restores throughput symmetry.
Multi-node scaling experiments (16 GPUs) confirm that D-VLA maintains efficient throughput and latency even in high-concurrency regimes, exploiting InfiniBand-backed asynchronous data and weight transfers to prevent inter-node communication from limiting overall speedup.
Robustness, Scalability, and Bottleneck Characterization
Scalability evaluations with π0.5 across environment counts from 384 to 3,072 reveal a non-linear throughput curve: rapid initial gains followed by a plateau and then modest decline as hardware saturation is approached. Notably, peak throughput (379 steps/s) is observed near 768 environments. At higher scales, bandwidth and compute limits of GPUs preclude further gains despite theoretical pipeline parallelism.
The implementation of explicit memory pools and the physical partitioning of compute tasks play a critical role in preventing environment-induced memory exhaustion, a frequent cause of instability in prior frameworks. The asynchronous architecture maintains strict temporal alignment between simulation and optimization, a requirement for efficient masking and duty cycle maximization at scale.
Training stability and convergence are maintained: D-VLA reaches success rates on par with synchronous and semi-asynchronous baselines, confirming that the system-level innovations can accelerate RL learning without degrading final policy performance.
Practical and Theoretical Implications
Practically, D-VLA’s architectural decoupling resolves long-standing resource contention between environment simulation and model optimization in distributed RL for VLA models. This enables stable hardware utilization and linear scaling to trillion-parameter agents and thousands of CPU/GPU environments—a prerequisite for training generalist embodied AI agents in lifelike simulation suites.
Theoretically, the results highlight the intertwined relationship between data and weight synchronization planes in multi-modal RL architectures. Optimal throughput is contingent on dynamically matching the compute and communication cycles of both simulation and RL components, pointing to the need for runtime-adaptive scheduling and automated resource partitioning algorithms.
Prospective upgrades entail the extension of D-VLA orchestration mechanisms to multi-agent, cross-hardware, and sim-to-real transfer scenarios. Additionally, dynamic, load-sensitive scheduling to maintain pipeline symmetry at exascale deployment is an open area for further research.
Conclusion
D-VLA introduces a fundamentally decoupled, high-concurrency distributed RL framework for Vision-Language-Action modeling. Through explicit architectural separation, advanced VRAM management, and asynchronous multi-threaded scheduling, it achieves up to 86% higher throughput over SOTA RL baselines on billion-scale VLA models, all without compromising convergence properties. Its design principles systematically address the major scaling bottlenecks preventing robust, efficient RL in modern embodied AI, laying the foundation for future developments in scalable generalist agent training.